import mathimport randomcla_all_num = 0cla_num = {}cla_tag_num = {}landa = 0.6# 拉普拉斯修正值def train(taglist, cla): # 训练,每次插入一条数据 # 插入分类 global cla_all_num cla_all_num += 1 if cla in cla_num: # 是否已存在该分类 cla_num[cla] += 1 else: cla_num[cla] = 1 if cla not in cla_tag_num: cla_tag_num[cla] = {} # 创建每个分类的标签字典 # 插入标签 tmp_tags = cla_tag_num[cla] # 浅拷贝,用作别名 for tag in taglist: if tag in tmp_tags: tmp_tags[tag] += 1 else: tmp_tags[tag] = 1
def P_C(cla): # 计算分类 cla 的先验概率 return cla_num[cla] / cla_all_num def P_W_C( tag, cla): # 计算分类 cla 中标签 tag 的后验概率 tmp_tags = cla_tag_num[cla] # 浅拷贝,用作别名 if tag not in cla_tag_num[cla]: return landa / (cla_num[cla] + len(tmp_tags) * landa) # 拉普拉斯修正 return (tmp_tags[tag] + landa) / (cla_num[cla] + len(tmp_tags) * landa)
def test( test_tags): # 测试 res = '' #结果 res_P = None for cla in cla_num.keys(): log_P_W_C = 0 for tag in test_tags: log_P_W_C += math.log(P_W_C(tag, cla),2) tmp_P = log_P_W_C + math.log(P_C(cla),2) # P(w|Ci) * P(Ci) if res_P is None: res = cla res_P = tmp_P if tmp_P > res_P: res = cla res_P = tmp_P return res,res_Pdef create_MarriageData(): p0=['青绿','乌黑','浅白'] p1=['蜷缩','稍蜷','硬挺'] p2=['浊响','沉闷','清脆'] p3=['清晰','稍糊','模糊'] p4=['凹陷','稍凹','平坦'] p5=['硬滑','软粘'] dataset = []#创建样本 dataset.append(random.choice(p0))#每个样本随机选择长相 dataset.append(random.choice(p1))#同理,随机选择性格 dataset.append(random.choice(p2))#同理 dataset.append(random.choice(p3))#同理 dataset.append(random.choice(p4))#同理 dataset.append(random.choice(p5))#同理 print("随机产生西瓜为:",dataset) return dataset
def beyesi(): # 训练模型 data=[ ['青绿','蜷缩','浊响','清晰','凹陷','硬滑','是'], ['乌黑','蜷缩','沉闷','清晰','凹陷','硬滑','是'], ['乌黑','蜷缩','浊响','清晰','凹陷','硬滑','是'], ['青绿','蜷缩','沉闷','清晰','凹陷','硬滑','是'], ['浅白','蜷缩','浊响','清晰','凹陷','硬滑','是'], ['青绿','稍蜷','浊响','清晰','稍凹','软粘','是'], ['乌黑','稍蜷','浊响','稍糊','稍凹','软粘','是'], ['乌黑','稍蜷','浊响','清晰','稍凹','硬滑','是'], ['乌黑','稍蜷','沉闷','稍糊','稍凹','硬滑','否'], ['青绿','硬挺','清脆','清晰','平坦','软粘','否'], ['浅白','硬挺','清脆','模糊','平坦','硬滑','否'], ['浅白','蜷缩','浊响','模糊','平坦','软粘','否'], ['浅白','稍蜷','浊响','稍糊','凹陷','硬滑','否'], ['浅白','稍蜷','沉闷','稍糊','凹陷','硬滑','否'], ['乌黑','稍蜷','沉闷','稍糊','稍凹','软粘','否'], ['浅白','蜷缩','浊响','模糊','平坦','硬滑','否'], ['青绿','蜷缩','沉闷','稍糊','稍凹','硬滑','否']] for x in data: train(x[0:6],x[-1])# 测试模型 #for x in data: # print('测试结果:', test(x[0:6]))if __name__ == '__main__': beyesi() #创建朴素贝叶斯分类 #单例测试模型 testcs=['青绿','蜷缩','浊响','清晰','凹陷','硬滑'] print("单例测试为:",testcs) print('测试结果:', test(testcs)) #随机测试模型 for i in range(1,20): print('测试结果:', test(create_MarriageData()))

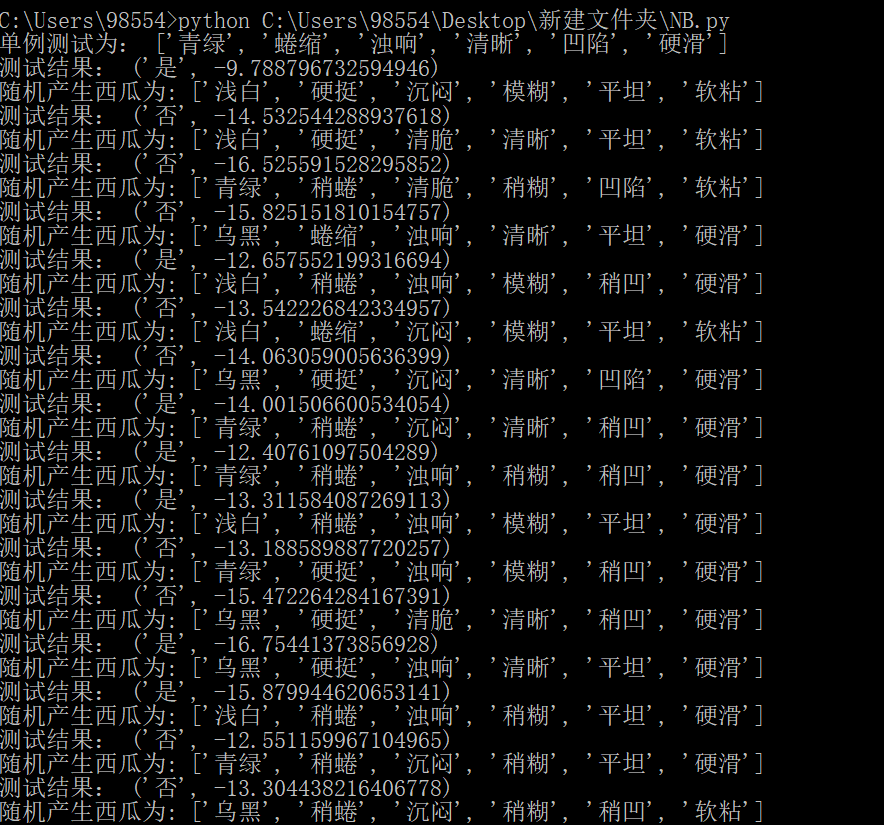










评论