字典树之旅 01. 开篇

简介
字典树(Trie),又称为前缀树(prefix tree),用于从集合中定位特定键的树数据结构。
Trie 是“检索”的英文单词 retrieval 的一部分,名称最早由 E. Fredkin [1] 提出,其发音同“try”。
注:名词解释原文见参考资料 [^2]
想象一下我们用字典查找单词的过程:
譬如,我们要找 “abandon” 这个单词(键),首先找第一个字符 a,定位到 a 所在页码,然后是通过第二个字符 b,定位到 ab 所在的页或行……最后定位完成,找到完整的单词 “abandon”,然后我们就可以查看单词对应的解释(值)了。
Trie 指的就是类似这样的一种检索行为,至于是用数组、二叉查找树或又是其它一些数据结构去模拟,只是不同的实现策略而已。
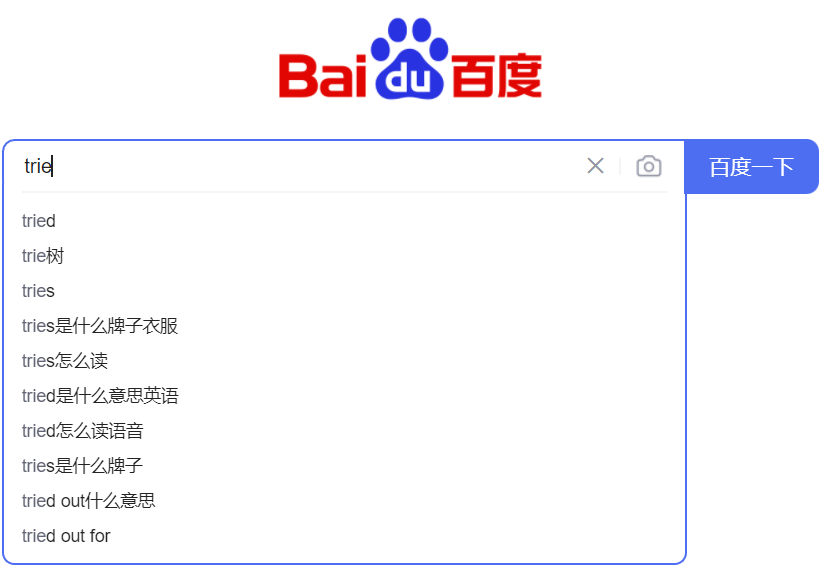
常见的应用场景如搜索引擎的输入框:输入“trie”,会列出以“trie”为前缀的搜索推荐信息。
此外,还有诸如词典分词、词频统计、拼写检查、数据压缩、倒排索引、字符串排序、关键字过滤……等等应用场景,由于其应用广泛,所以涌现出大量相关的优化算法和数据结构,各种优化,各种变体。
因此,这是一种非常有意思的数据结构,其进化史就是一个脑洞大开的过程。
家族
我在学习过程中有两大困扰:
谁提出了这种数据结构或算法?是对哪种数据结构或算法的改进?为什么要提出新的数据结构和优化算法?其解决了什么问题?其付出的代价是什么?
为什么定义这个名词?该名词代表的含义和主要思想是什么?该名词从诞生到现在含义是否已经有变化?为什么多个名词指代的都是同一种数据结构?
作为一个喜欢穷根究底的人,当然希望能够了解其演变思想和改进过程,将知识片段转化成知识体系,因此边查资料边思考,整理了如下字典树演化图:
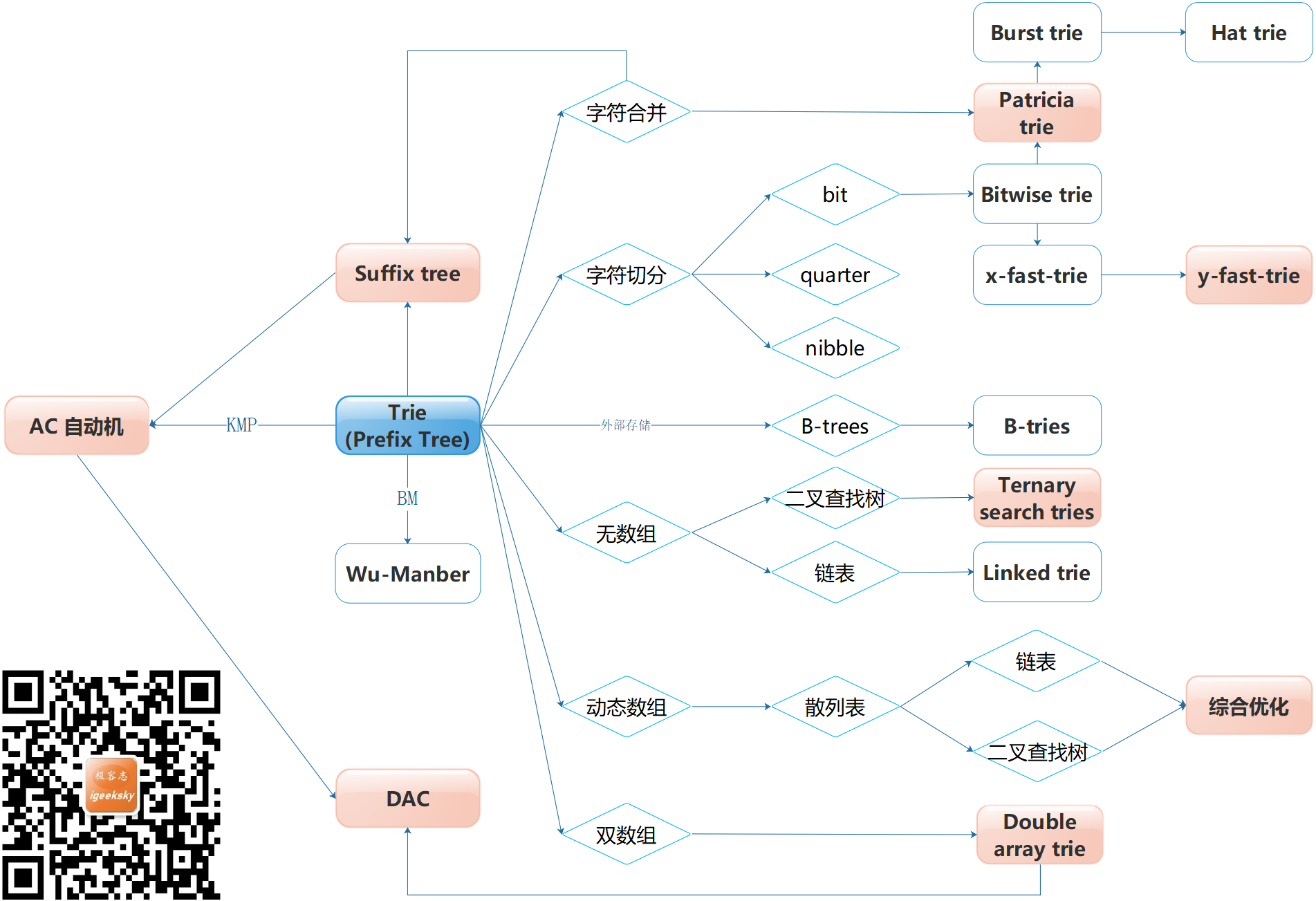
注:红色部分是我计划实现的数据结构。
提纲
图 2 只是基本脉络,我计划从字典树的标准实现开始,一步步去探索优化策略和实现各种变体,行文过程中再进一步详述各个数据结构或算法之间的联系和演变。大致提纲如下,这貌似是一个浩大的工程,希望我能完成😀
Patricia Trie
Ternary search trie
Trie 的综合优化
Suffix tree
单模式匹配之 KMP
AC 自动机
Double array trie
DAC
单模式匹配之 BM
Wu-Manber
B-trie
最后,希望我的文章能对读者有一些帮助,也希望朋友们能给我建议和反馈。总之,相互学习!共同进步!
代码仓库
文章相关代码在这两个仓库:
实验性代码:https://github.com/patricklaux/perfect-code
生产级代码:https://github.com/patricklaux/xtool
参考资料
[1]: Fredkin, E. . "Trie memory." Communications of the Acm 3(1960).
[2]: Donald E. Knuth. "The Art of Computer Programming. Volume III: Sorting and Searching." Addison-Wesley(1973):492-512
版权声明: 本文为 InfoQ 作者【极客志】的原创文章。
原文链接:【http://xie.infoq.cn/article/8cd42881c9914736c1ca2badc】。文章转载请联系作者。

佳人与代码,皆不可辜负也 2018.07.19 加入
对机器学习感兴趣的程序员,关注自然语言处理领域,关注互联网软件架构









评论