
干货!这份阿里 P8 大佬纯手打总结 Kafka 学习笔记, 真是 yyds

前言
Kafka 是由 Linkedin 公司开发的,它是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。
Kafka 性能卓越,单机写入 TPS 约在百万条/秒,最大的优点,就是吞吐量高。时效达到 ms 级,可用性非常高,同时也是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用消费者采用 Pull 方式获取消息, 消息有序, 通过控制能够保证所有消息被消费且仅被消费一次;有优秀的第三方 Kafka Web 管理界面 Kafka-Manager;现在日志领域比较成熟,被非常多的公司和多个开源项目使用;现在,各大互联网企业都会遇到数据量激增,数据复杂度增加以及数据变化速率变快等问题,Kafka 在处理这些问题上有较好的效果,所以 Kafka 儿乎成为了每-位大数据架构师,Java 架构师的标配。因此深度掌握 Kafka 是一项非常重要的能力。前段时间有位朋友面试时被问到了为什么要使用 Kafka,在哪种场景下需要使用 JMS,结果一脸问号。工作几年来,接触了 Kafka,Elasticsearch 等等,居然没想过为什么要用这些眼花缭乱的消息系统,各种数据库。脑海中一直萦绕着面试官问的好几个问题,看似简单,却给不出一个系统性的答复。
Kafka 为什么这么快?
如何对 Kafka 集群进行调优?
Kafka 的高性能网络架构是如何设计的?
Kafka 集群资源如何评估?
为了帮助大家在这个金九银十能够冲刺成功,今天在这为大家分享阿里 p8 大佬总结的一份 Kafka 核心知识大全(非电子书,纯手打!!),知识点详细,图文结合,非常适合在学习 Kafka 的朋友!
话不多说,咱们先来看看大致学习路线
Kafka 学习思路导图
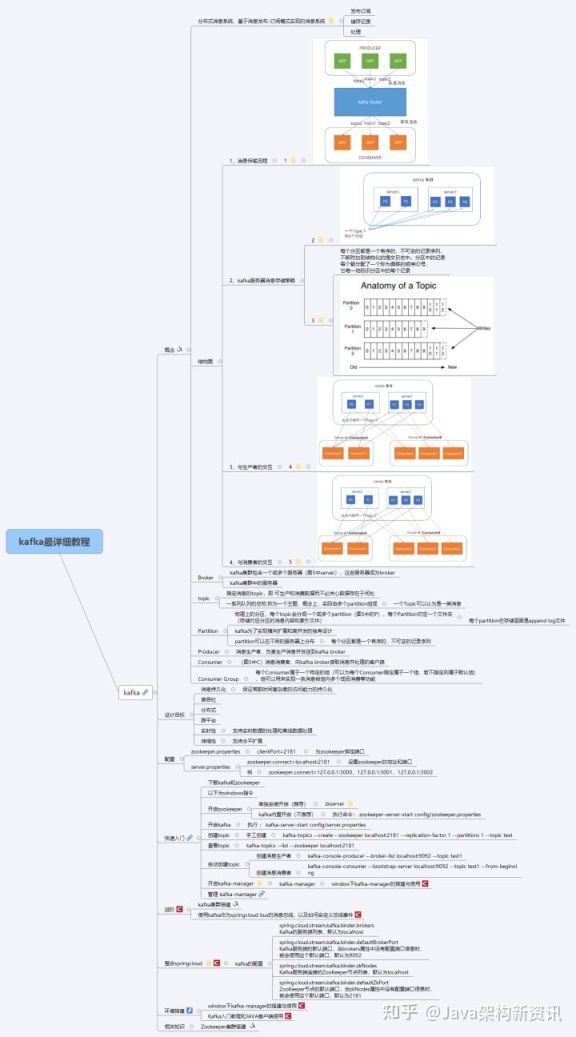
第一到三部分
一、Kafka 入门
二、为什么选择 Kafka
三、Kafka 的安装、管理和配置


第四到第六部分
Kafka 的集群
第一个 Kafka 程序
Kafka 的生产者

第七到第九部分
Kafka 的消费者
深入理解 Kafka
可靠的数据传递


第十到第十部分
Spring 和 Kafka 的整合
SpringBoot 和 Kafka 的整合
Kafka 实战之削峰填谷
数据管道和流式处理

总结
以上就是这篇文章的全部内容啦!
小编后续还会为大家持续更新新的内容,如果大家觉得小编这篇文章还不错的话,请大家转发关注+收藏哦!
Ps:由于本份资料内容实在太多,受平台发文限制,无法将全部目录展示出来。下文仅展示部分内容,需要阅读学习完整版的小伙伴请添加小助理 vx:bjmsb9923 即可免费领取

不定期更新Java开发工具及Java面试干货技巧 2021.12.12 加入
Java后端工程师,十年大厂经验。具有扎实的Java、JEE基础知识。熟悉Spring、SpringMVC、Struts MyBatisHibernate等JEE常用框架。








评论