广角 - 聊聊 Underlay
估计大家也发现了,我喜欢在推文里面附上大量的图,这些图有些是我自己画的,有些是我平时看各种资料时收藏的。在推文里引用图时,我尽量从官网下载,如果是书籍里的图,我会标明图的来源。
我一贯坚持一个观点:一图胜千言,晦涩冗长的技术文字可以用精致的图片完美地展现。据说人脑对图像的加工记忆能力大约是文字的 1000 倍,甭管它是真是假,我们对图片的敏感度和好感确实是远大于文字的,我们的脑袋可以长久地记住图片所包含的内容,却对大片的文字读过即忘。
我写设计文档的时候也会画图。文字总是抽象的,而图却是具象的。文学作品不适宜配过量的图,因为那样会限制读者对文字的想象力,每个人心中都有一个林黛玉才是美好的。但和文学作品不同,传递技术信息时,用图的方式可以更好地确保大家的理解是一致的且能达到事半功倍的效果,准确传递是首要目标。有三本我看过的书在这方面堪称典范:W.Richard Stevens《UNIX 环境高级编程》、Marko Lukša《Kubernetes In Action》还有刘超《趣谈网络协议》。
连着两周聊 Cilium,今天我们换个话题,聊聊容器网络的 Underlay 模式,换个口味,毕竟总吃一道菜容易没胃口。今天这篇是广角篇,你一定猜到了,下一篇是微距篇。
三大模式回顾
之前,二哥发过一篇推文“特洛伊木马-图解VXLAN容器网络通信方案”,当时主要聊的内容是容器网络方案中的一种,即通过 VXLAN 的方式将容器间的网络拓扑压扁,摊平,形成一个所谓 flat netowrk。其实 VXLAN 只是实现“扁平网络”这个目标的众多方式之一。将这些方式稍加归纳整理,我们大致可以将它们分为以下三种模式:
Overlay 模式
这是最自由、开箱即用的方案。特点是方便、易用、自由。但自由是有代价的,与主机间通信效率相比,它的传输性能会有 20-30%左右的下降。
性能损耗花在了什么地方呢?一个是隧道所带来的解/封装损耗,另一个是进出 Pod 的 traffic 要穿越两次网络栈(进两次,出也是两次)。解/封装的代价显而易见,而两次网络栈的穿越却很容易让人忽略。
如图 1 所示,Pod traffic 在 Pod network namespace 和 Node 的 network namespace 分别会被处理一次,如果 Node 的 network namespace 里有大量的 iptables rule 的话,会出现较长的处理时间。图 1 中用红色标示出了"iptables overhead",意思是这部分是额外的工作量,言下之意是其实这部分工作量可以去掉,Cilium 正是基于 eBPF 跳过了这些 overhead,从而实现了明显的性能提升。
这种模式可供选择的实现有 Flannel VXLAN,Calico IPIP 等。
主机间路由模式
这里所谓的主机是指组成 K8s 集群的 Node。主机间路由其实是将各个 Node 当成了边界路由器,每个 Node 是一个 AS(Autonomous System),这很好理解,毕竟 Linux 是自带路由功能的。虽然容器网络和宿主机网络是两个平行的网络,但容器间通信可以直接通过宿主机网络路由。这个时候它俩的关系其实很像电信、联通这些网络运营商和阿里云、腾讯云这些云平台之间的关系,它们各自独立运营宽带网络(若干 AS 组成),但是电信联通会转发来自云平台的流量,对于运营商来说,它被称为 Transit AS。
这种模式优势非常明显:性能高,和主机间通信相比,容器间通信大概有 10%左右的性能损耗,当然和 Overlay 模式一样,主机间路由同样会出现图 1 中所示的两次穿越网络栈的问题。
这种模式的缺点也非常明显:不是你想要就可以,因为它需要用到 BGP 协议,如果你使用的是云平台托管的容器服务,你几乎没有插手使用 BGP 的机会。
这种模式可供选择的实现有 Flannel host-gw,Calico BGP 等。
Underlay 模式
Underlay 这个词和 Overlay 相反,一下一上。这个模式特指让容器和宿主机处于同一网络,两者拥有相同的地位的网络方案。
主机间路由模式算是 Underlay 模式的一个特殊场景。但主机路由模式其实还是将宿主机网络和容器网络进行了主客之分。主场和地盘是宿主机的,只是允许容器网络的流量自由进出罢了。这就像孙权想要去益州的话,得经过荆州,但刘备认为那只是为友情干杯,给他借道而已,他自己才是荆州的主人,最靓的那个仔。
但 Underlay 模式却彻底抹去了地盘之争。这块地是大家的,大家生而平等,谁都可以自由进出。最重要的是没有任何性能损耗。
阿里云、GKE、AWS、Azure 均提供了这种模式。这篇和下一篇重点聊聊这种模式。
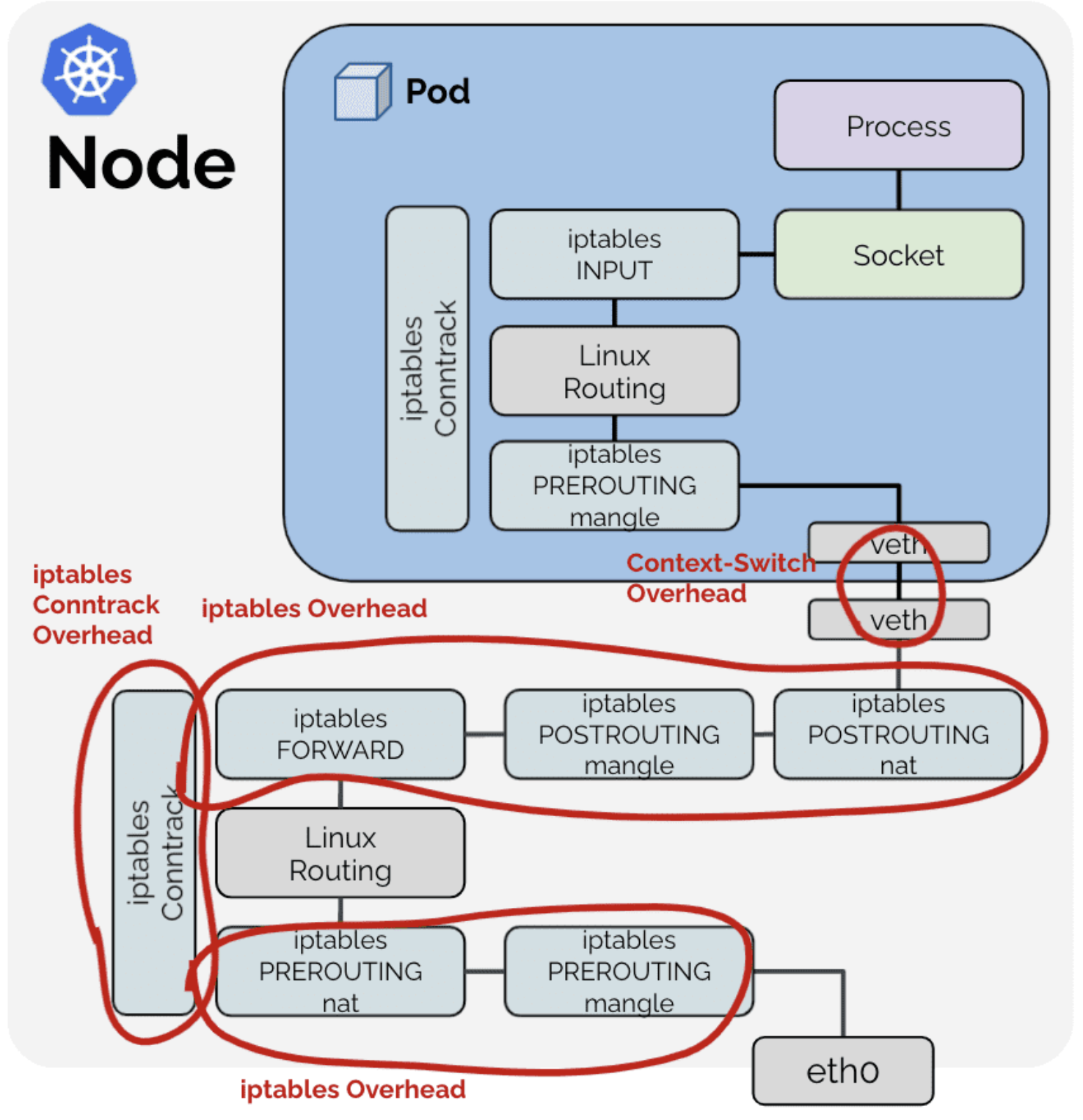
图 1:进出 Pod 的 traffic 穿越两次网络栈
“扁平-K8s网络模型漫谈”这篇推文从 10000 英尺的高空俯瞰了宿主机网络和容器网络的关系,给有需要的人。
广角
用广角镜头拍摄的画面,在突出中央主体和前景的同时,还具有广泛的背景。本文要聊的中央主体和前景当然是下图中的 Pod 和虚拟机所组成的 Underlay 模式网络,但只关注它们是不够的,因为我们需要结合更多的背景来了解它们之间的关系。所以图 2 中我加入了更多的背景:Open vSwitch,VPC,接入交换机,汇聚交换机等等。
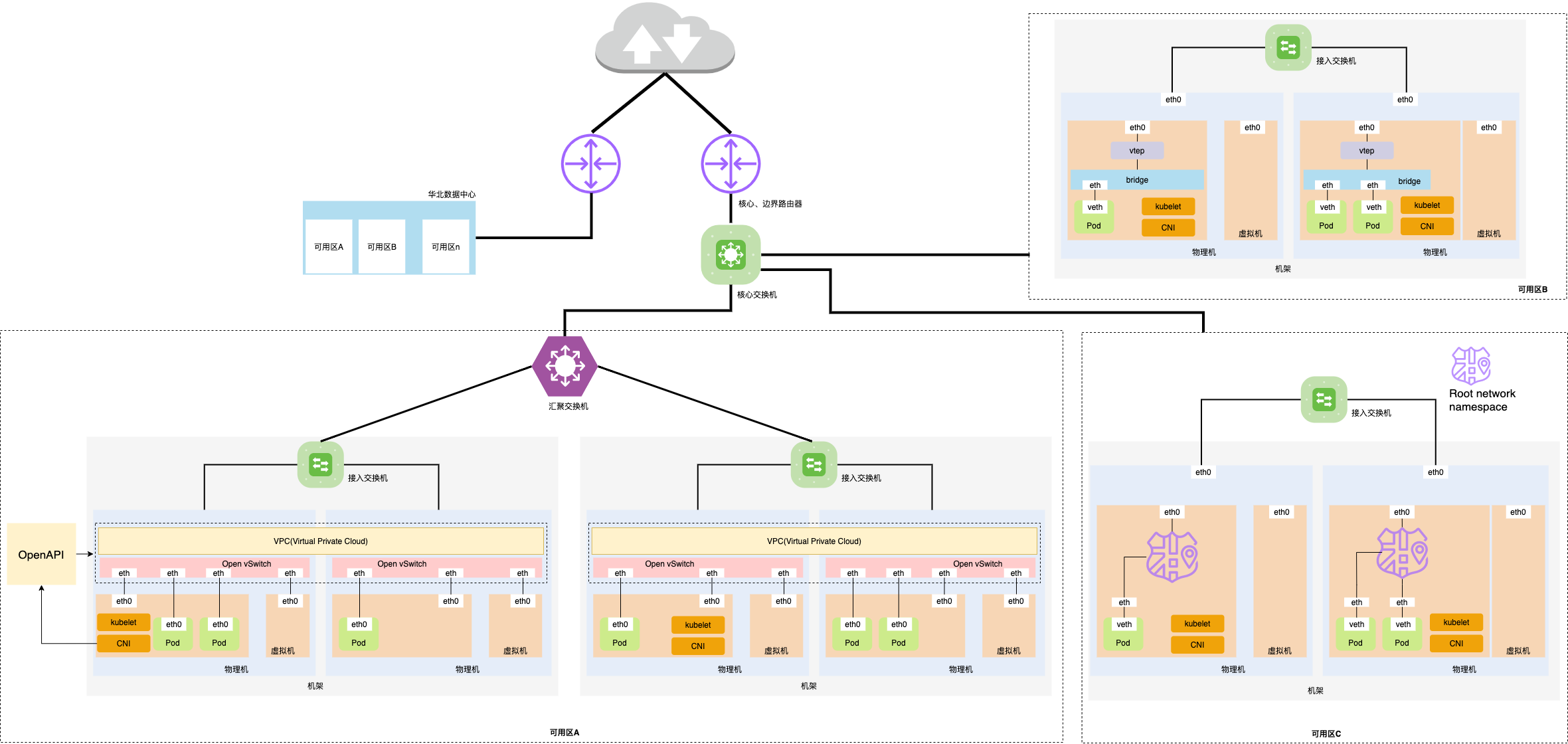
图 2:Underlay 模式广角图
图 2 首先画出了一个数据中心主要的设备。进出物理机的流量会通过接入交换机、汇聚交换机和核心路由器。二哥是一个注重细节的人,你会发现连接不同等级的网络设备之间的线宽是不一样的,线越宽越代表它承载的流量越大,也意味着离骨干网越近。
同一个机架上的物理机通过接入交换机互联,而不同机架上的物理机则通过汇聚交换机互通。如果你愿意买个更广的镜头,会发现汇聚交换机用来连接一个可用区里所有的物理机,而核心交换机则连接了更多的可用区。
边界路由器限定了这个数据中心的边界,在它之外便是电信联通所运营的互联网,当然边界路由器会和多家运营商互联,此时它被称为 Multihomed AS。边界路由器通过 BGP 协议,将自己数据中心里面的外网 IP 借助运营商的网络向外广播,告知全世界:我们在这里。
不同的数据中心则通过 VPN 相连。
细心的你一定发现了在可用区 A 和可用区 B 里,Pod,虚拟机和物理机这三者之间,网络连接方面有很大的不同。可用区 A 里面用到了 Open vSwitch,而可用区 B 里面没有。另外在可用区 B 里,Pod 的网络设备名我特意改成了 veth。不同的可用区在二层是否互通没有统一的做法。不通的话,可以避免网络广播风暴、二层环路等问题,通的话可以实现大二层,都在一个广播域里,方便横向扩展以满足日益增长的东西流量。
这样的不同对进出 Pod 的 traffic 会有什么样子的影响呢?请期待微距篇。
以上就是本文的全部内容。码字不易,更多内容请关注二哥的微信公众号。您的举手之劳是对二哥莫大的鼓励。感谢有你!

版权声明: 本文为 InfoQ 作者【Lance】的原创文章。
原文链接:【http://xie.infoq.cn/article/e81300a0acd38904c999d3447】。文章转载请联系作者。

码海茫茫 2018.03.18 加入
软件行业从业多年,焊过电路、干过驱动、写过内核的代码、砌过业务的砖,人生转角处偶遇云原生。









评论