扁平 -K8s 网络模型漫谈
一篇文章围绕一张图,讲述一个主题。今天聊聊 K8s 的网络模型。
网络是 K8s 的核心部分,但想要理解它是如何工作的却有点难度。
K8s 定义了一个网络模型,目的是给 Pod,service 等使用者提供一个简单、一致的网络视图和使用体验,对它们屏蔽宿主机环境的网络拓扑的同时,也屏蔽网络模型实现上的细节。
本文尝试从 K8s 网络模型角度,以鸟瞰视角瞧瞧 K8s 典型的各种网络通信方案。既然是鸟瞰图,就不要在乎细节。多年搬砖、掉坑、爬坑的经验告诉我,无论是游历一个新地方还是学一个新东西,首要的是抓大放小。这倒不是说细节不重要,只是带着全局的思维研究一个东西时,不容易迷路也不容易掉入细节的深井。天平的左边是全局,右边是细节,在全局和细节之间,我们最终会找到一个平衡点,但现在让我们从把天平偏向左边开始。
K8s 网络模型
简单来说,Kubernetes 引入的网络模型提出了下列基本要求。只要满足了这些要求,即可成为一个 K8s 网络方案供应商。
每个 Pod 都有自己单独的 IP 地址
Pod 内部的所有容器共享 Pod 的 IP 地址且可以相互自由通信
一个 Node 上的容器可以使用 IP 地址和其它 Node 上面的容器通信,且不需要通过 NAT
注意:这里只是说 Pods 之间跨 Node 通信时不可以用 NAT,但是 Pod 访问其它实体比如 google.com 时可以使用 NAT
如果 Pod 使用宿主机网络环境,那么跨 Node 的容器间可以使用 IP 地址进行通信,且不需要通过 NAT
像 Linux 这种可以直接让 Pod 使用宿主机网络环境的平台,跨 Node 的容器间间通信也不可以通过 NAT
一个 Node 上面的 agent(比如 system daemon, kubelet 等)可以使用 IP 地址和位于该 Node 上面的所有容器通信,且不需要通过 NAT
Pod 之间容器通信所涉及到的隔离问题通过 Network policy 解决
这种类型的网络模型也被称作为"扁平网络"。下图展示了这样的扁平网络。同时它也画出了宿主机环境既可能是二层互通的也可能是三层可达的这样一个事实。
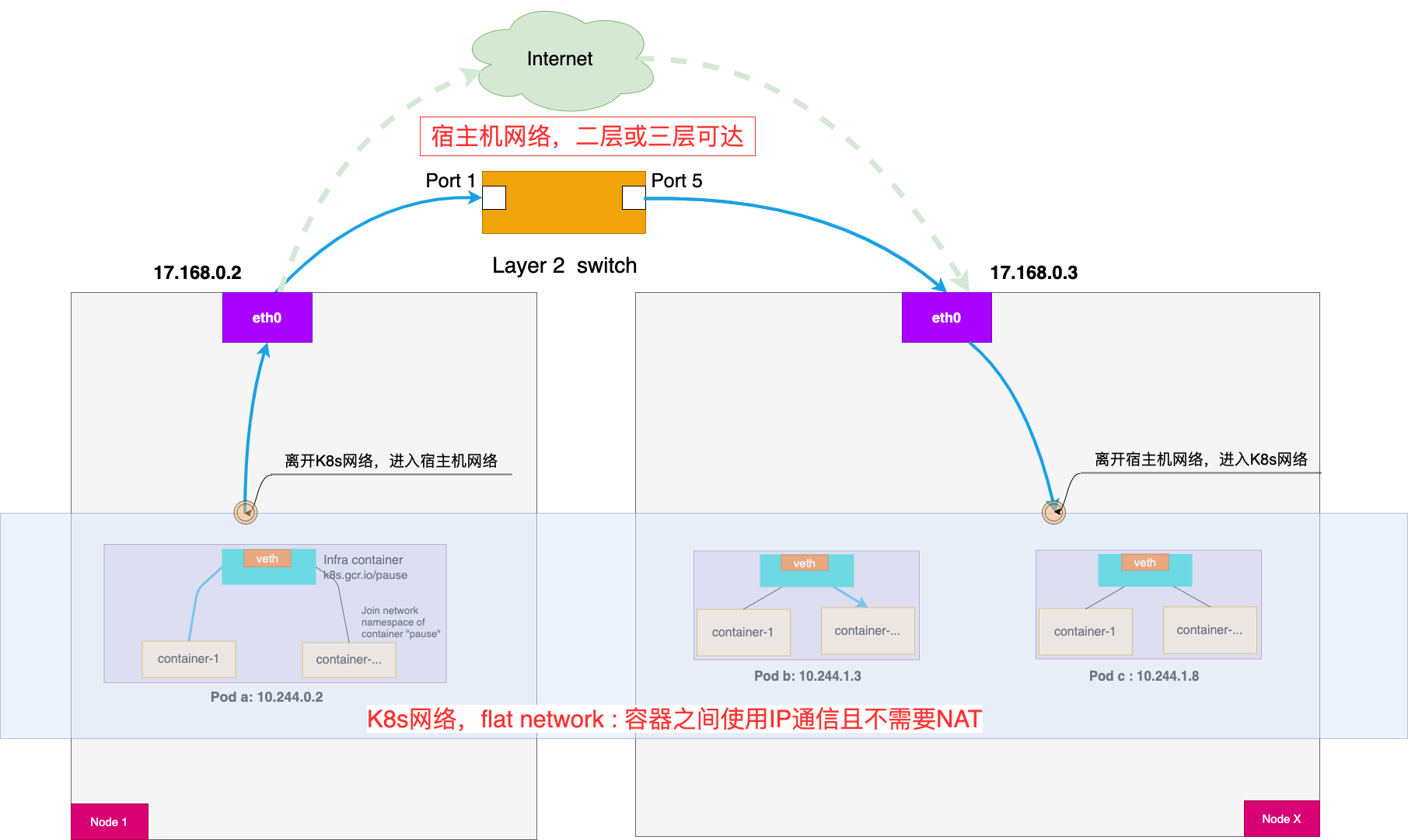
图:K8s 扁平网络模型
我们来细品这些要求。容器之间可以通过 IP 通信,且不能 NAT,至少说明以下两点:
不能 NAT 意味着 Pod 自己看自己的 IP 和别人(宿主机上面的 agent 或者其它 Pod)看到自己的 IP 是一样的,对,一眼看穿、看懂对方的那种。而与此对应的是,如有 NAT 在捣鬼的话,当企业内部的机器访问躲在 Nginx 后面的服务时,二者相互看不清对方的本来面目。
容器之间 IP 互通,也就间接要求了宿主机之间是三层可达的。为什么呢?如果是宿主机环境是二层网络,那么天生就是三层可达的,但如果二层不通的话,就需要三层可达,不然从一个 Pod 发出的数据不是被憋死在宿主机上面了吗?对于在阿里云或腾讯云上租借 VM 作为 Node 来搭建 K8s 集群这样一个典型的使用场景来讲,更方便的姿势是直接将这些租借的 VM 置于同一个 subnet。
Pod 可以被当成是有独立、唯一 IP 地址的 VM 或者主机。此时 Pod 内的容器就很像 VM 或主机上的进程,它们都跑在相同的 network namespace 里面且共享同一个 IP 地址。当需要把运营环境从 VM 或主机迁移到 Kubernetes 时,采用这个模型会使得迁移前后,无论是 RD 还是 OP 对网络部分的理解相对一致,平滑地过度而不至于出现剧烈的变化。
另外,因为 K8s 网络隔离是通过 network policy 完成的,而不是基于网络拓扑,这样便于理解和维护。
可以看到 K8s 网络模型只是要求了容器间可以直接用 IP 地址自由地通信,但并没有强制要求 Pod IP 在 K8s 网络边界之外也可以路由。是的,K8s 说"我只要扁平,剩下的我不管"。说到"K8s 网络边界"也就引出了一个重要的概念:K8s 网络和宿主机网络。
宿主机网络:组成 K8s 集群的各个 Node 之间在没有安装 K8s 前就已经存在的网络拓扑。比如通过 subnet 将所有的 Node 放到一个 LAN 里面,或通过 VLAN 将其分属不同的子网但三层可通信,甚至让它们分布在同一个 Region 但不同的 Zone 里面。
K8s 网络:特点是扁平化,可以直接使用宿主机网络,也可以在每个 Node 上以一个 bridge 为网关管理该 Node 上的所有 Pod。
K8s 网络和宿主机网络之间是有明显的边界存在的,当容器在跨 Node 间通信时,traffic 会在这两个环境间来回穿梭跳跃。当我们审视 K8s 集群相关的 traffic 时,比较好的方式是提醒自己:traffic 目前在什么位置?是在 K8s 网络内部还是已经流出 K8s 网络到了宿主机网络环境?如果我们把出入 K8s 集群的 traffic(以太帧)看成是导弹,把 K8s 网络看成大气层,而把宿主机网络看成太空的话,那么这个以太帧的流动轨迹就和德国火箭科学家桑格尔提出的再入弹跳式弹道有点类似。
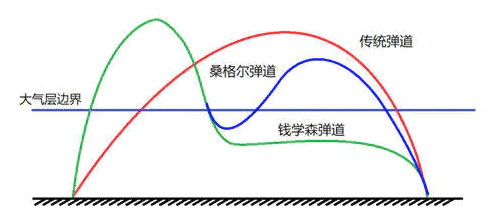
图:钱学森—桑格尔弹道
一般会将宿主机网络称为 Underyling network,在其之上的 K8s 网络方案虽然看起来变化多端,但实现方式无外乎以下几种模式:
Overlay networks 模式
直接路由 Pod IP 模式
Underlay 模式
CNI
在 CNI 标准出来之前的两个月,Docker 公司主持起草了一个叫 CNM(Container Network Model)规范。但与 CNI 的开放性相比,Docker 坚持 CNM 只能基于 Docker 来设计,可对于 K8s 而言,Docker 只是它编排大业里面可选择的众多容器引擎之一而已,因而容器网络作为 K8s 最基础也是最重要的部分绝不可能绑定在 Docker 身上。于是 K8s 在经过一番研究以及挣扎之后,毅然决定放弃 CNM,自立 CNI。
我们今天依旧可以重温 Kubernetes Network SIG 的 Leader、Google 的工程师蒂姆·霍金(Tim Hockin)于 2016 年所写的文章:为何 K8s 不使用 CNM https://kubernetes.io/blog/2016/01/why-kubernetes-doesnt-use-libnetwork/。行文中充满了所提 Feature Request 被 Docker 工程师无情拒绝时的无耐。其中提到一个非常有意思的细节:很多提交给 Docker 的问题,都被 Docker RD 以"working as intended"为由关闭。
时至今日,回望来时路,在当时弃 CNM 而扶持 CNI 是一件挺冒险的事情,但如今再看 CNCF landscape "Cloud Native Network"部分,看看那众多支持 CNI 的网络方案,用"百花齐放"和"百家争鸣"来形容绝不为过。

图:CNCF landscape "Cloud Native Network"
典型的 CNI 实现方案
K8s 内建了一个 kubenet,它可以支持一些基本的网络连接。但更普遍的使用方式是用第三方的网络方案。只要它满足 CNI(Container Network Interface) 规范就可以以插件的方式在 K8s 环境使用。
CNI 插件的种类多种多样,但关键的功能不外乎以下两个:
网络插件,主要负责将 Pod 插入到 K8s 网络或从 K8s 网络删除。
IP 地址管理(IPAM, IP Address Management)插件,主要负责为 Pod 分配 IP 地址,并在 Pod 被销毁的时候回收 IP。
相较于传统的 on-premise 自购服务器部署服务或者云 VM 形式部署方式,以 Pod 为单位的部署方式使得微服务的横向扩展(scale out)、横向收缩(scale in)的程度空前剧烈,这就要求 IPAM 插件能够快速地响应 Pod 的这些变化。
顺便说一句,也正因为变化如此动荡、如此剧烈,使得传统的基于静态 IP 来配置安全策略的方法显得略为力不从心。
由于 CNI 的开放性和网络模式的简单性,可供选择的网络方案看起来多种多样,下面是几种在业界颇为流行的实现:
Flannel VXLAN
Flannel host-gw
Calico IP in IP
Calib BGP
我们从 K8s 网络的 traffic 离开宿主机时对宿主机环境二层、三层网络连通要求和是否需要封包两种角度来分别看看这几种实现。
我做了一个表格,方便你对比查看。

要求宿主机二层连通的方案
如果宿主机环境二层是通的,比如所有的宿主机都在同一个局域网内,则表示主机之间通信直接通过二层交换机转发数据包即可。
Flannel host-gw 方案,属于"直接路由 Pod IP"模式。它虽然是三层网络方案,但要求集群宿主机之间是必须是二层连通的。这看起来比较奇怪,其实非常好理解。这个方案得以正常工作的核心,是为每个容器的 IP 地址,找到它所对应的“下一跳”的网关。 既然它将目标宿主机设为网关,那么要求网关和本机在二层是可达的也就显得不是那么奇怪了。
BGP 的全称是 Border Gateway Protocol,即:边界网关协议。Calico BGP 方案实际上将集群里的所有 Node,都当作是边界路由器来处理,且在 Calico 看来,每个 Node 都是一个自制系统(AS)的网关。这些 Node 一起组成了一个全连通的网络,互相之间通过 BGP 协议交换路由规则。
这些 Node 之间理所当然应该是三层可达的。但是实际转发 workload traffic 的时候,出现了一个问题,下面这条路由规则里的下一跳地址是 17.168.0.3,可是如果它对应的 Node X 跟 Node 1 却根本不在一个子网里,则没办法通过二层网络把 IP 包发送到下一跳地址。
10.244.1.3/24 via 17.168.0.3 eth0
这就是为什么 Calico BGP 方案也要求二层是连通的。
说到这里,说个题外话:我们需要区分目的 IP 和 next-hop IP 的区别。
目的 IP 是数据包的最终目的地,在整个数据包传输过程中它是不会改变的。
而 next-hop IP 则随着数据包在 internet 上被网络设备中继时不断地修改,具体而言每个网路设备的路由规则会通过 next-hop IP 来决定网络包的 dest MAC 地址,也即目前数据包在我手上,下一个我要转交的那个人。
类似地,Flannel VXLAN 也要求二层连通。
作为一般规则,当 K8s 网络的 traffic 离开宿主机时,如果下一跳或者网关是集群主机的 IP 地址,也即 dest MAC 是集群主机的 MAC 地址时,就需要宿主机环境二层是能直接连通的。
要求宿主机三层可达的方案
宿主机环境二层不连通,但三层是可达的,是另一个常见的场景,比如宿主机分别分布在不通的 VLAN,主机之间通过三层交换机(路由器)转发数据包通信。
Calico IP in IP 方案只需要宿主机环境三层可达即可。
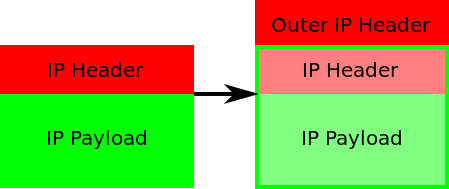
图:IP in IP 封包(图片选自https://en.wikipedia.org/wiki/IP_in_IP)
作为一般规则,当 K8s 网络的 traffic 离开宿主机时,如果下一跳或者网关不是集群主机的 IP 地址,就不需要二层连通,此时只要三层 IP 可达即可把以太帧路由到终点。
Flannel host-gw 方案和 Calico BGP 方案均要求三层可达。
Overlay networks 模式
对于 K8s 来说,使用 Overlay network 方案有下面的三大好处:
在 Node 间传递 pod 之间的网络流量时不用关心 underlying network 是什么
不用关心通信双方的 Pod 分别在哪个 Node 上
underlying network 也不需要关心 Pod 的 IP 地址
但这个世界上没有绝对的好事,Overlay networks 虽然用得很舒服,但它涉及到封包(Encapsulation),性能损失大概 20%-30%。
作为一般规则,当 K8s 网络的 traffic 途径宿主机网络中的路由器时不可以被正常路由的话,就需要考虑封包。典型的封包方案有 VXLAN 和 IP-in-IP 两种。
Flannel VXLAN 使用的即为下图所示的 VXLAN 封包,也叫做 Layer 2 over UDP。
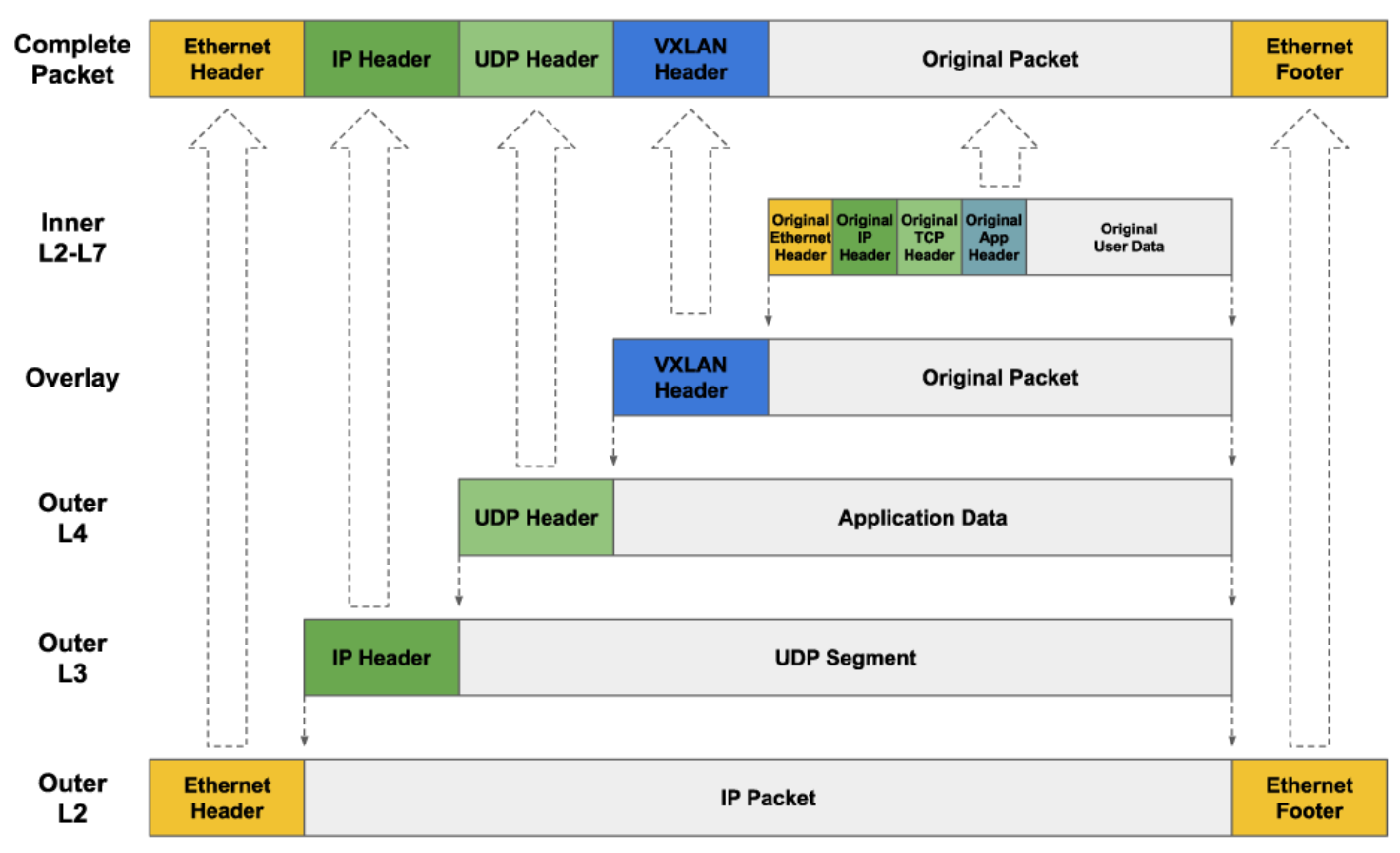
图:VXLAN 封包
Calico IP in IP 封包示意图如前文所示。也叫做 IP payload in outer IP package。
直接路由 Pod IP 模式
作为一般规则,如果 K8s 网络的 traffic 途径宿主机网络中的路由器可以被正常路由的话,就可以采用直接路由 Pod IP 方案。
Flannel host-gw 和 Calico BGP 使用了这种模式,这种模式不需要将 K8s 网络的 traffic 封包,与 VXLAN 和 IP in IP 相比,性能损失大概只有 10%。
以上就是本文的全部内容。码字不易,喜欢本文的话请帮忙关注二哥的微信公众号。您的举手之劳是对二哥莫大的鼓励。感谢有你!

版权声明: 本文为 InfoQ 作者【Lance】的原创文章。
原文链接:【http://xie.infoq.cn/article/9179d85921467d5deca05b35b】。文章转载请联系作者。

还未添加个人签名 2018.03.18 加入
还未添加个人简介









评论