模块五作业
作业要求
基于模块 5 第 6 课的微博实战案例,分析“微博评论”这个核心场景的业务特性,然后设计其高性能高可用计算架构,包括但不限于如下内容:
1. 计算性能预估(不需要考虑存储性能);
2. 非热点事件时的高性能计算架构,需要考虑是否要拆分独立的服务;
3. 热点事件时的高可用计算架构
估算步骤
【用户量】
依据模块 5 第 6 课所使用的数据:日活 2.24 亿
【关键行为】
1. 写评论
2. 看评论
用户行为建模和性能估算
【写评论】
绝大部分写评论的对象会是大 V 和明星的微博,或者自己的亲戚朋友的微博,而大 V 和明星的微博一发出来,短时间对这个微博的评论会比较高。
依模块 5 第 6 课的每天微博的发送量约为 2.5 亿条,假设当中只有 50%有评论,而每一个有评论的微博大约有 10 个评论,每天的评论大约有 12.5 亿。
依模块 5 第 6 课看微博的时间,都集中在早上 8:00~9:00 点,中午 12:00~13:00,晚上 20:00~22:00,这个时间点和写评论基本重合,这几个时间段写评论总量占比为 60%,则这 4 个小时的平均写评论的 TPS 计算如下:12.5 亿 * 60% / (4 * 3600) ≈ 50K/s。
【看评论】
基本上这里和看微博的情况相似,流量一般也集中在看大 V 和明星微博的人,每次看微博的时候也会显示相关评论,因此依据模块 5 第 6 课的计算,在早上 8:00~9:00 点,中午 12:00~13:00,晚上 20:00~22:00,
看评论的平均 QPS 和看微博的一样:250 亿 * 60% / (4*3600) = 1000K/s
写评论高性能计算架构设计
【写评论】
【业务特性分析】
写评论是一个典型的写操作,因此不能用缓存,可以用负载均衡。
【架构分析】
用户量过亿,应该要用多级负载均衡架构,覆盖 DNS -> F5 -> Nginx -> 网关的多级负载均衡。
【架构设计】
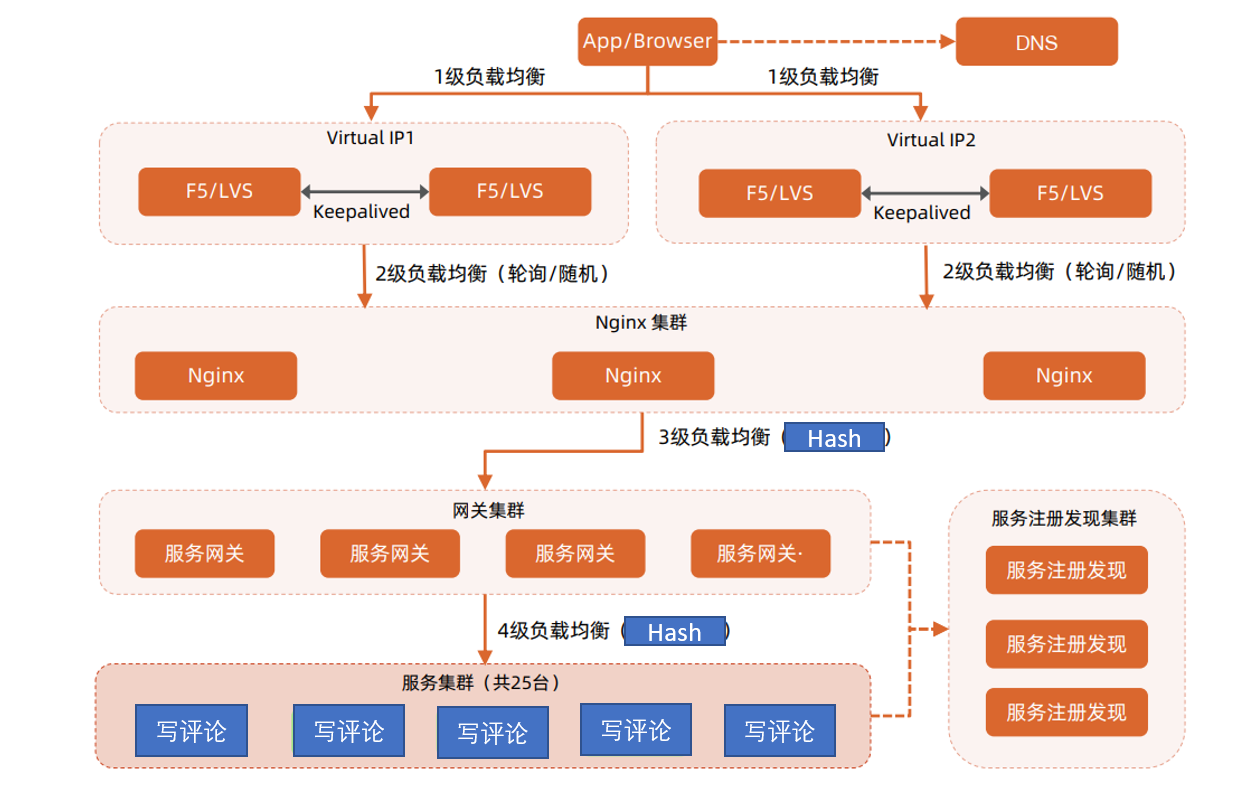
1. 负载均衡算法选择 Hash 算法,这是因为如果将同一个微博的评论集中处理,应该可以提高性能。
由于写评论对实时要求不高,也就是从发评论到评论的显示可以用一定的延迟,我们可以使用写缓冲,慢慢处理。假设,我们可以缓冲当中的 80%请求,那么服务器集群只需要处理 TPS 10K/s。
由于写评论和写微博的处理步骤差不多,因此按照一个服务每秒处理 500 来估算,完成 10K/s 的 TPS,需要 20 台服务器,加上一定的预留量,25 台服务器差不多了。
写评论多级负载均衡架构
看评论
【业务特性分析】
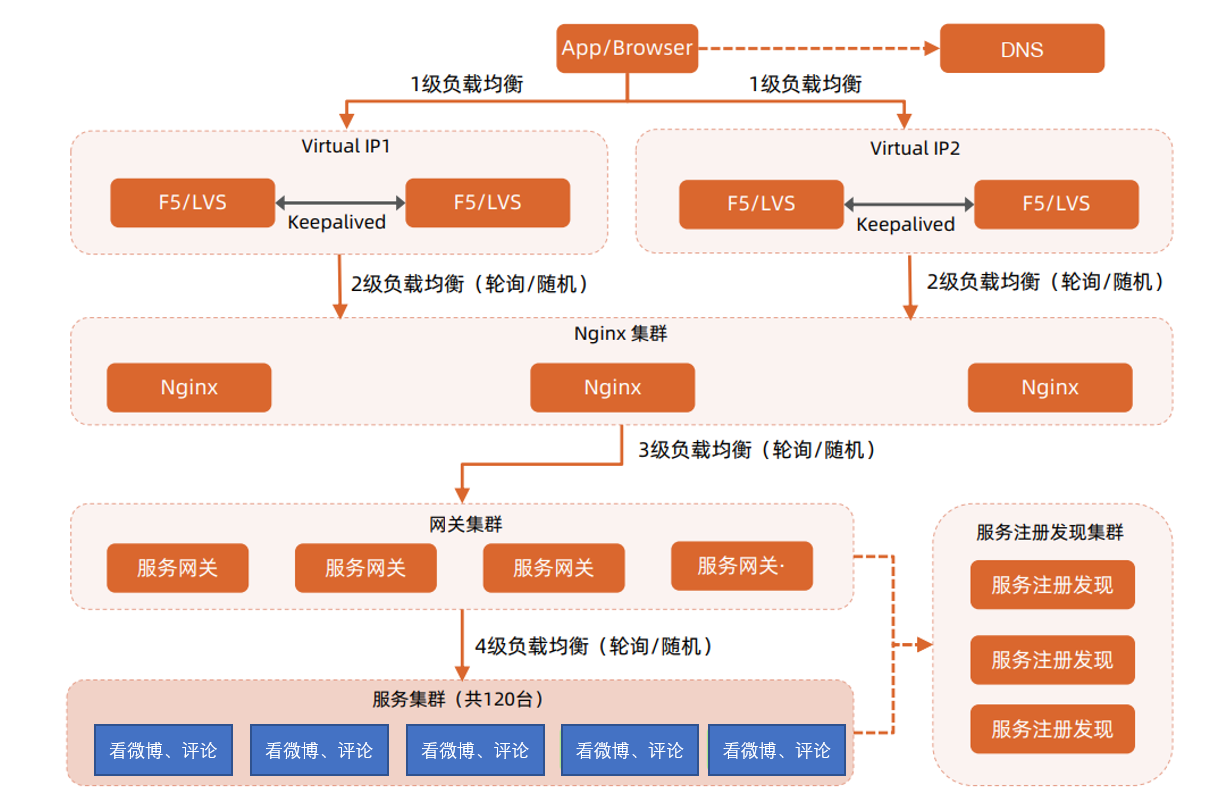
由于评论通常和微博一起显现,也就是说看微博请求时,一般也是显示相关评论的,所以可以和看微博的场景捆绑在一起。
【架构分析和架构设计】
这里我们不用再另外搭建新的架构,就是使用【看微博】的架构就可以了。
数量为 120 台。
看评论的多级负载均衡架构 (就是使用看微博的架构)
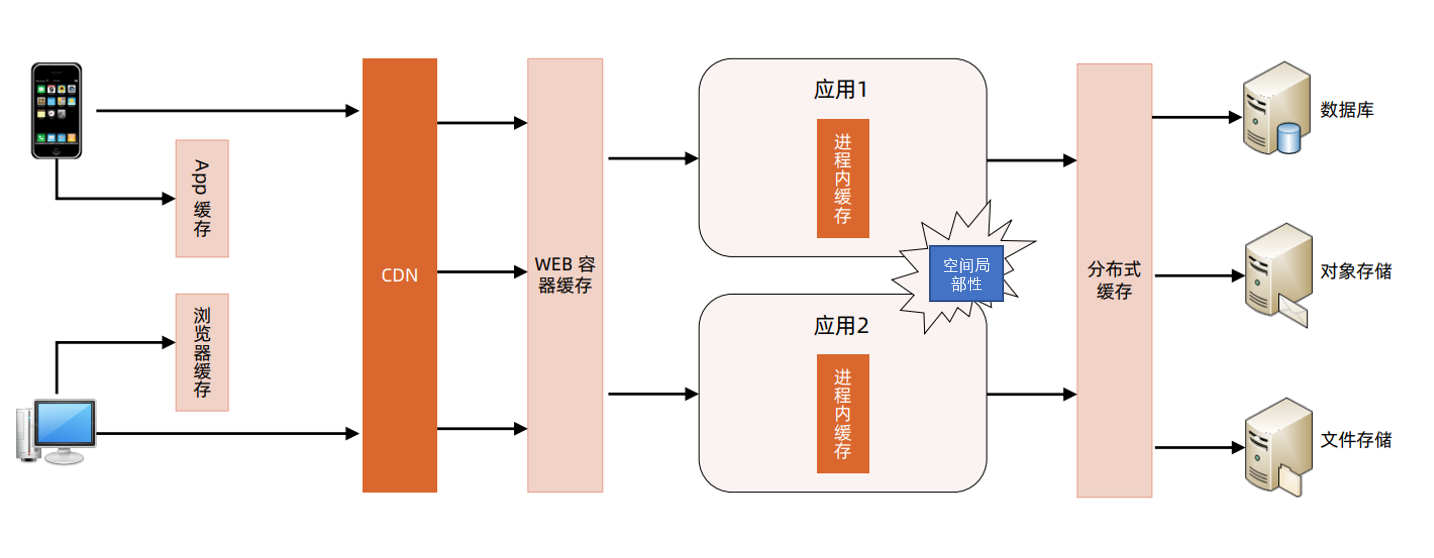
看评论的的多级缓存架构
这里我们也是使用看微博的多级缓存架构,也会使用进程内缓存,这是因为同一个微博的评论会一起显示,有空间局部性。
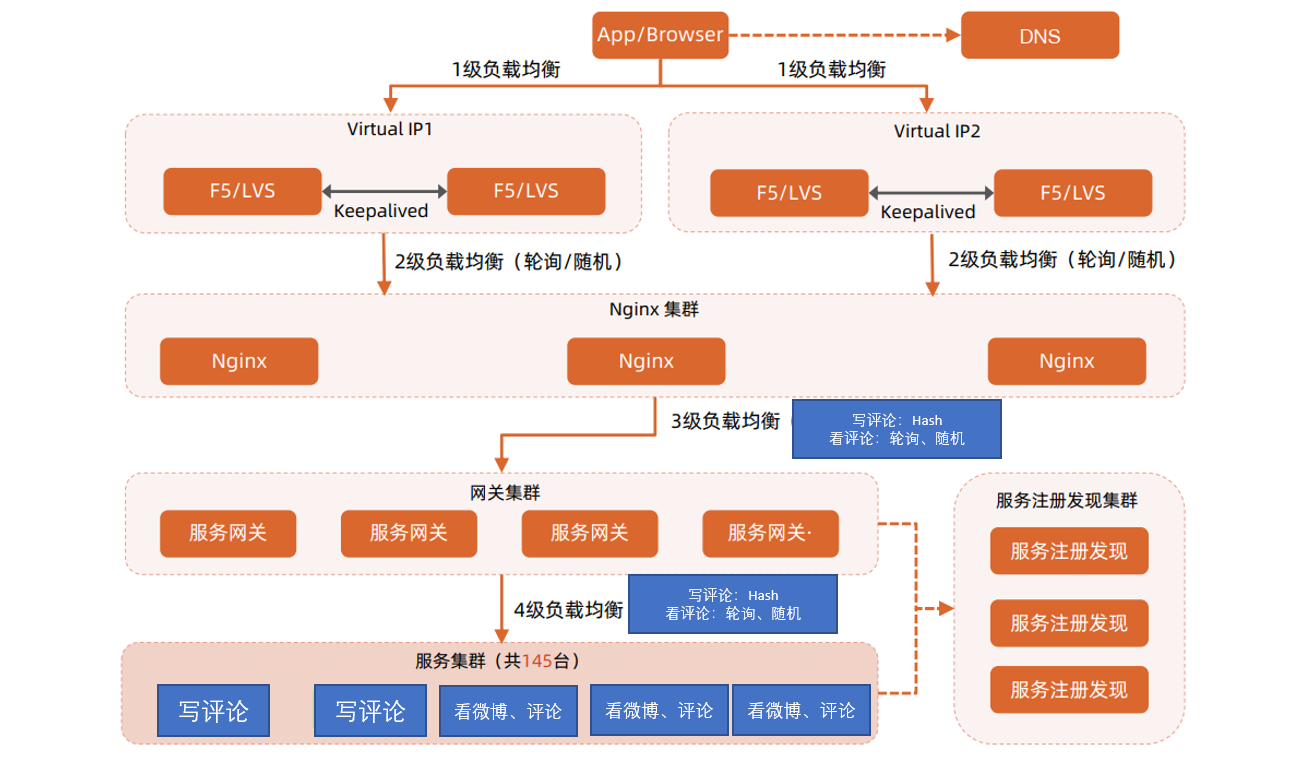
微博评论高性能计算方案- 整体架构设计
任务分配: 双机房,三机房
任务分解:将写评论和看评论拆分到不同业务,但是把看评论和看微博放在同一个业务。
微博评论多级负载均衡整体架构
微博评论多级缓存整体架构
微博评论热点事件计算高可用架构分析
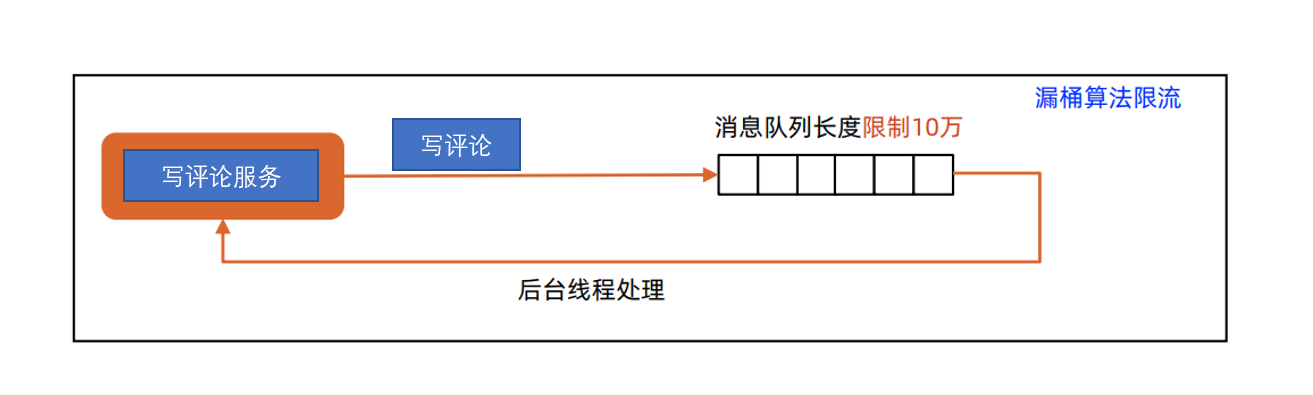
1. 写评论
当出现一个热点微博时,相关的写评论也会突然飙升,由于丢失评论会对用户造成的代价比较好,使用“漏桶算法-写缓冲”,尽量不丢失评论。
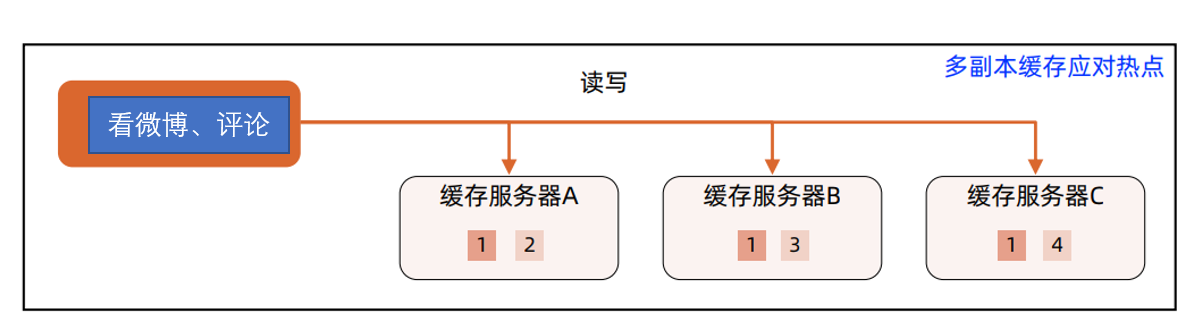
2. 看评论
看评论和看微博一样很明显,热点事件微博存在缓存热点问题,可以考虑“多副本缓存”,由于原有的缓存架构已经采用了“应用内的缓存,总体上来看,缓存热点问题其实不一定很突出,简单来说,看评论不需要另外搭建新的架构,使用看微博的架构就可以了。
微博评论热点事件计算高可用架构示意图

还未添加个人签名 2020.10.16 加入
还未添加个人简介









评论