
【函数式编程实战】(六) Stream 高并发实战

前言:
📫 作者简介:小明 java 问道之路,专注于研究计算机底层,就职于金融公司后端高级工程师,擅长交易领域的高安全/可用/并发/性能的设计和架构📫
🏆 Java 领域优质创作者、阿里云专家博主、华为云享专家🏆
🔥 如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主哦
本文导读
我们上讲看 Stream 接口提供大量 API 可以方便的处理元素,这讲 Stream 高并发(并发、并行、多线程)、ForkJoin 线程池框架的实战
一、并行流(parallelStream、parallel、sequential)
并行流就是把一个内容拆分成多个数据块来执行,用不同的线程分别处理每个数据块的流
parallelStream、.parallel()都可以将流转换成并行流,.parallel()的粒度更小。要注意的是顺序流( .stream) 调用 parallel 方法不意味本身有什么实际变化,它内部设置了一个 boolean,表示调用 parallel 之后的操作都是并行的
对并行流调用后可以使用 .sequential() 变成顺序流。
并行流 不是一定并行,多线程中保证原子操作会有对象的可变状态,当多个线程共享对象时,共享的可变状态会不断被线程锁住,会影响并行流和并行计算
所以我们是否可以使用并行流需要避免共享变量,而且当较小的数据量的时候并行处理的开销不一定会小于计算开销,同时集合的数据结构也会对并行流有影响,ArrayList 拆分的开销,要小于 LinkedList(前者底层是数组可以直接在内存拆分,后者底层是链表,内存不连续需要遍历拆分,ArrayList、HashSet、TreeSet 可拆分性好,LinkedList 可拆分性极差)
二、Fork/Jion 框架
并行流的背后的原理是 java7 里面的分支/合并框架,分支/合并框架的目的就是以递归的方式,将数据块(任务)并行的拆分成更小的数据块,然后将每个子任务合并成整体,ExecutorService 接口的实现,ExecutorService 把子任务分配给线程池 ForkJionPool 中的工作线程。
要把任务提交到这个 ForkJionPool 线程池,必须创建 RecursiveTask 的实现类,要定义 RecursiveTask 只需要实现他的抽象方法 compute
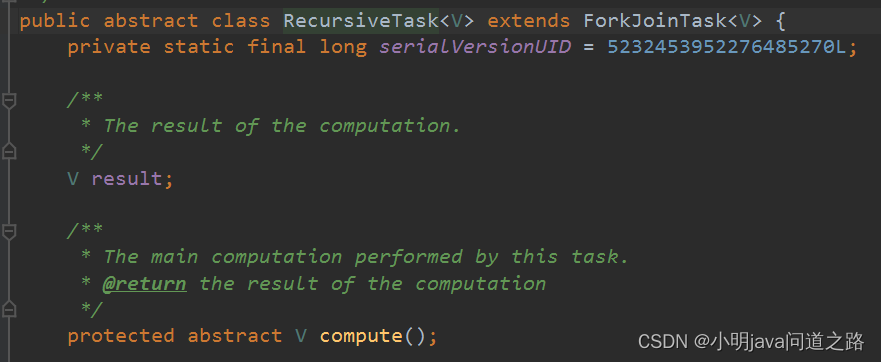
创建一个 ForkJoinTask,并把对象传给我们自定义的 ForkJoinCalculator,创建一个 ForkJoinPool 并把任务传递给他的调用方法 invoke,返回值就是 ForkJoinCalculator 定义的结果
扩展 RecursiveTask,穿件 ForkJoin 框架,创建起始位置和终止位置,实现 compute 方法,实现 fork、join 金额累加
Fork/Jion 框架还有几个框架需要注意的,对于一个任务调用 join 方法,会阻塞调用方,直到出任务结果;不应该在 RecursiveTask 里面实现 ForkJoinPool 应该使用 compute 或 fork 方法;compute 实现需要中断方法并且这里面实现比较困难需要多加练习。
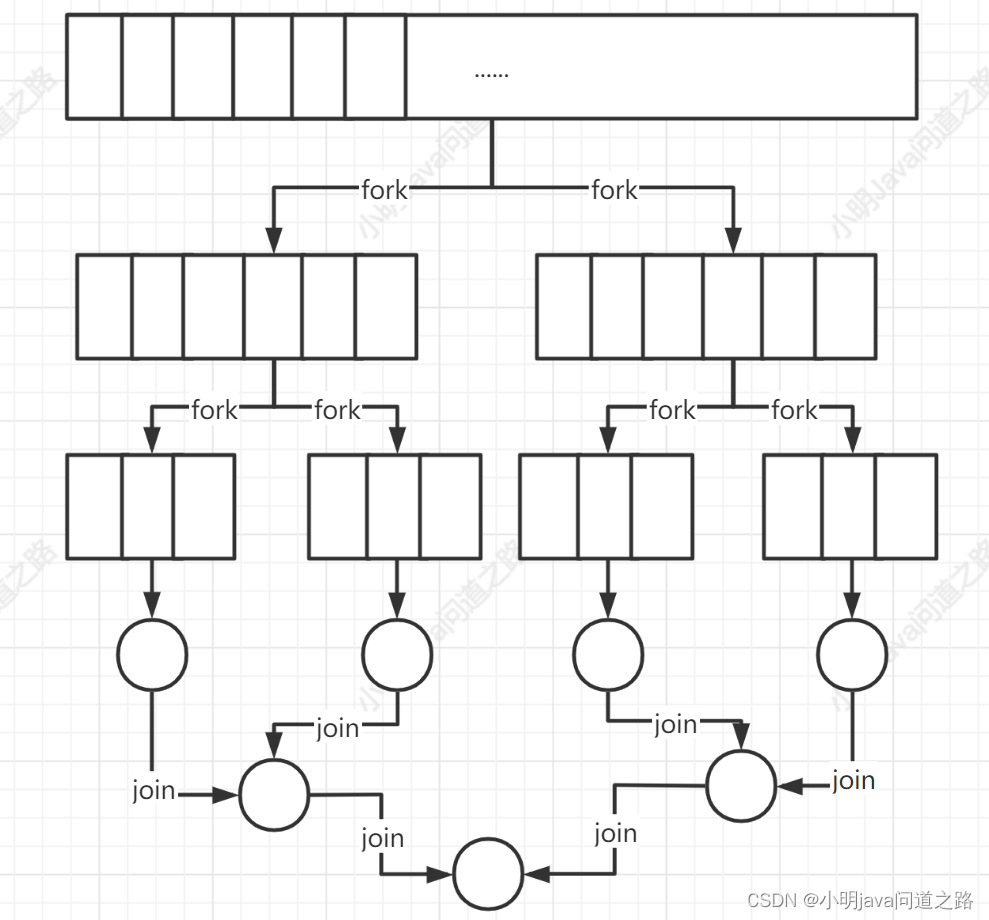
工作窃取,在实际工作中任务差不多被平均分配到 ForkJoinPool 的所有线程,每个线程都为分配给线程的任务保存一个 双向 LinkedQueue(双向链式队列),每个人物完成就会从队列的头取一个在进行执行,但是某些线程执行可能过快,此时这个线程会从其他线程的 队列尾,取走一个任务执行,这也是 Fork/Jion 框架能有高性能的原因
总结
本文讲解 Stream 高并发(并发、并行、多线程)、ForkJoin 线程池框架的实战
版权声明: 本文为 InfoQ 作者【小明Java问道之路】的原创文章。
原文链接:【http://xie.infoq.cn/article/a9ba4024615d1ff586a52ac51】。文章转载请联系作者。

物有本末,事有终始。知所先后,则近道矣 2020.03.20 加入
🏆CSDNJava领域优质创作者/阿里云专家博主/华为云享专家 📫就职某大型金融互联网公司后端高级工程师 👍专注于研究计算机底层/Java/架构/设计模式/算法









评论