
如果只有一周时间,怎么快速提升线上系统的稳定性?
01 我们需要快速见效
我们都知道系统稳定性是一个非常庞大的工程,不仅贯穿需求,研发,变更,运行,运维等全生命周期所有阶段,又涉及组织形式、运维机制、人员分工、操作规范、研发流程、设计原则、系统架构等全方位立体式保障。市面上已有很多资料全面介绍相关的理论体系和最佳实践,我们也都会尝试建设相应的运维保障体系。然而,完整的运维保障体系头绪太多,非常容易陷入看起来很热闹但实质上没效果的尴尬陷阱,尤其是如果线上系统稳定性压力非常大的时候,这个矛盾就会非常突出。那么,有什么办法能够迅速上手、快速见效并逐步形成完整立体的稳定性保障体系呢?在总结过往几年的实践经验基础之上,本文希望给出一条实操性强,可立即开展工作并在一周之内见效的稳定性保障体系演进之路。
02 系统稳定性归因分析
作为一个数据流,首先我们把过往直接或间接接触的上百个大大小小的生产事故按事故根因(事故根因是笔者使用的类别,大家也可以根据自己的情况做相应的调整)进行了分类统计,结果如下:
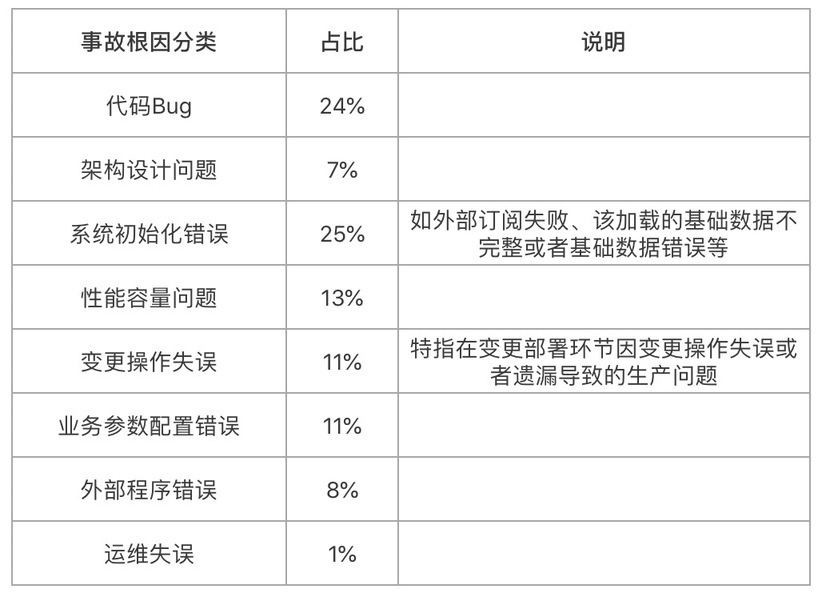
以上数据至少告诉我们以下两点:
1. 生产事故跟架构设计、代码开发、上线变更、业务配置、运维操作以及外部依赖等研发运维全生命周期都相关。这算是一句废话,因为地球人都知道。
2. 架构代码问题(代码 Bug+架构设计)约占 31%,还有约 69%的事故是程序编码出来之后到实际运行过程之间产生的,与架构代码本身关系不大。
这就有点意思了,对程序员来讲显而易见的架构代码改进只可以解决小一半的问题,而且我们都知道架构代码改进并非一朝一夕能完成,很多改进尤其是代码 Bug 修改都是 Case By Case 的。也就是说,架构代码改进固然重要,但它既不能解决大部分问题,又不能“快速提升”系统稳定性。因此,除了程序员们一直都在做的架构代码改进之外,我们还应该重点关注剩余的 69%问题。
03 如何快速提升系统稳定性
问题找到了,我们来看看应该从哪里入手。基于“实操性强,可立即开展工作又效果不错”的目标,我们假设对系统研发上线运行全生命周期各个阶段进行改进,从“改进效果”,“实施难度”,“生效效率”等三个维度对各个阶段的改进工作进行如下分析对比。
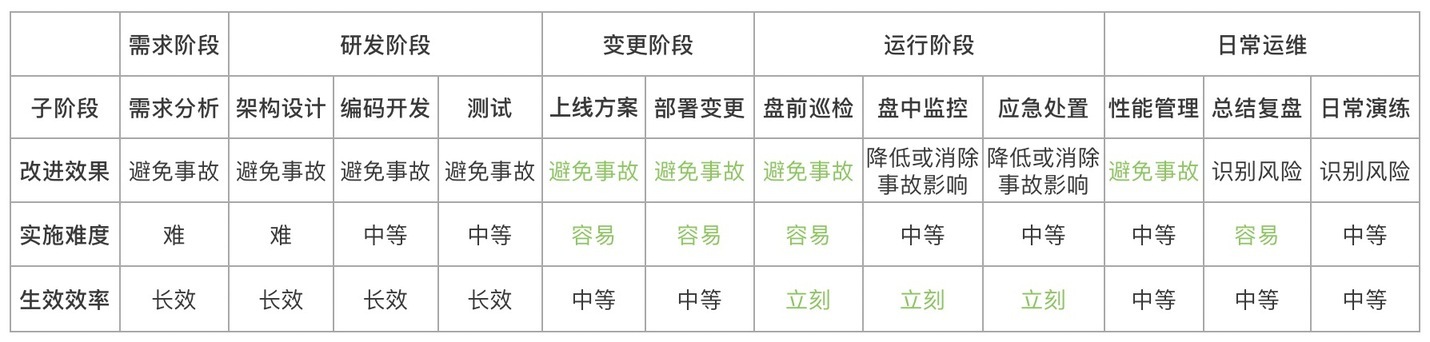
首选:系统初始化巡检与监控
总结到这里,本文所提问题的首选答案已经揭晓。既能避免事故又能立刻开展工作且容易实施的改进阶段非“系统初始化”环节莫属,可以说现在开工明天就可以见效。再结合前边的实际案例统计,“系统初始化”,“业务参数配置错误”以及“外部程序错误”总共 44%的问题似乎都有可能通过“系统初始化”来避免。以上只是理论分析结果,为了验证这一点,我们还是来从既往的事故中来找一些数据支撑。
首先,我们按实际发现阶段和理论最早可发现阶段对过往的所有生产问题进行了分类统计。
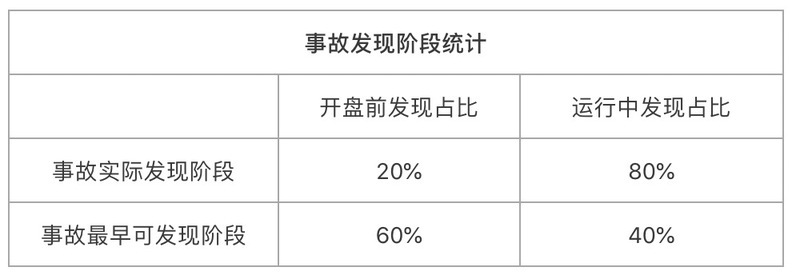
上表意味着,系统初始化阶段确实可以发现一半以上(60%)的问题,但是实际上却只有理论分析的 1/3(20%)问题是在初始化阶段发现的,还有 2/3 的问题没有被发现,这又是什么原因呢?为了回答这个问题,我们进一步对这 2/3 的事故进行分类如下。
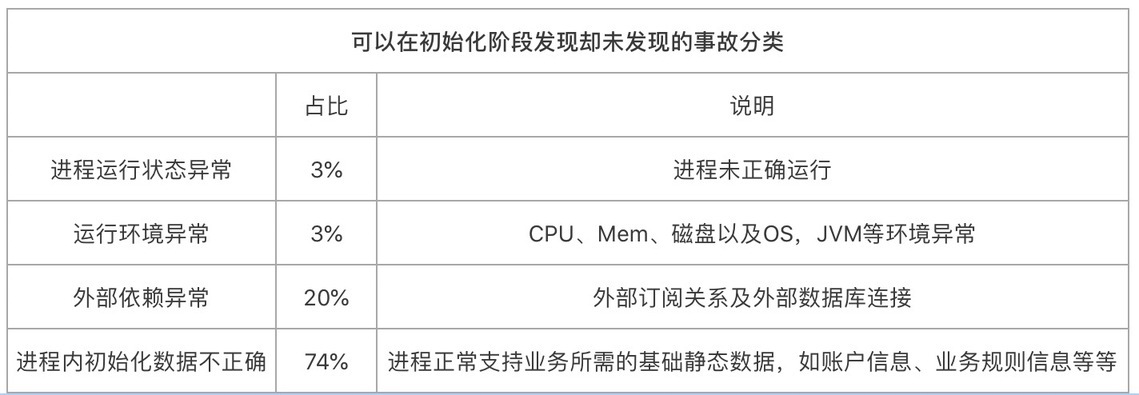
也就是说,绝大部分(占比 94%)可以在系统初始化阶段发现却未发现的事故都是因为系统要正常服务所依赖的外部数据、外部订阅关系以及进程内部自身的数据或状态初始化不正确导致,而这些问题想要在系统初始化阶段发现,必须深入到业务级检查与监控,这正是很多情况下缺失或者做得不够的地方。
初始化巡检三板斧
事实上,系统运行监控与系统初始化阶段对系统健康状态的检查需要做的事情几乎一致,只是发生阶段不一样,越早发现问题越容易避免生产事故。但我们发现真正做好这一点的系统少之又少,盖其原因就是缺少正确指引,没有形成标准化操作。为了能帮助大家快速查缺补漏,实现初始化检查 &监控效果最大化,笔者所在的团队经过长期实践总结出“初始化巡检三板斧”,这样的三板斧同样可以用于检验系统监控的完整度,其具体内容如下:
程序运行状态检查与监控。一般指程序启停状态,以及程序所处运行环境的基本状态。这是系统正常提供服务最基本的底线,现在基本所有运维人员盘前巡检都会覆盖此类内容,但还需要重点建设可靠的自动化巡检,避免对人过度依赖,若因人为失误或遗漏造成此类巡检失败从而引起生产问题,那影响将会极其恶劣。
程序外部依赖检查与监控。一般指程序依赖的外部连接、订阅关系和依赖数据是否正确。与“程序运行状态”类似,大部分运维人员已覆盖此类检查,但还是需要关注自动化程度,避免失误或遗漏。
程序内基础数据检查与监控。这就是上边说的最容易忽略但又最容易引发生产事故的环节,很多运维巡检都未包含此类检查,但是实施起来其实并不难,只需要运维、研发、架构现在坐在一起,花两个小时梳理一遍之后即可立刻着手实施,完成之后能够大幅度降低生产事故发生率。而且需要梳理的内容也有章可循,只要从以下几点入手基本可以完整覆盖:
系统为了正常提供服务,有哪些基础配置信息是必需的?
系统为了正常提供服务,有哪些静态数据是必需的?
系统为了正常提供服务,除以上两点及业务逻辑代码以外,还有哪些关键假设?
上述三点,都可以通过初始化检查与监控的方式判断其合法性和准确性,如果不满足要求,第一时间 Fail,第一时间修复,即可避免大部分问题遗漏到生产运行环节。
第二选择:上线变更改进
如果你的系统已经迈过了上述阶段,系统初始化检查与监控已经做得很好,那么虽然无法立即生效,但实施相对容易并且能较快生效避免事故的则是可以优先考虑的改进环节。也即上线方案环节和部署变更环节,这两个环节实施起来相对容易,可有效避免下一次变更带来的生产问题。
上线方案环节。在大型分布式系统中,上线方案的重要性再怎么强调都不为过。尤其是针对比较大的变更,需要充分协调变更系统的上下游,结合灰度发布等机制逐步推进,尽最大限度避免 Big Bang 似的变更是降低变更引起事故比例的不二选择。笔者所在团队通过对较大上线变更的方案做大范围评审来达到这一目标,而评审本身其实也有非常多可以讨论的点,但这不在本文讨论的范围,就不展开讨论了。
部署变更环节。该环节改进可以有效降低因部署变更操作不当带来的生产问题,DevOps 持续交付理念已非常成熟,也有非常多的最佳实践。关键还是实施时要找准自身系统目前是否存在类似的问题,根据问题有针对性的实施为宜。
第三优先级:总结复盘
总结复盘在任何时候都可以立即开展,虽然无法直接改变系统稳定性,但是基于总结复盘可以找出非常多可以立即实施并生效的改进措施,间接提升系统稳定性。其实,本文也是建立在总结复盘的基础之上形成的。而关于“总结复盘”,也有一定的方法论指导我们如何更好的开展,这一点已在“如何通过灵魂复盘大幅降低生产事故”中详细描述,有兴趣的可以参考,此处不再详述。
其实,正如文中所列的“各阶段改进效果对比分析”表格所示,能做的改进非常多。比如日常演练可以提前发现系统的问题并制定切实可行的应急预案和应急手段,使得不可避免的问题在运行中发生时可以最大程度消除或者避免对业务带来的影响。但是限于篇幅,本文就抛砖引玉,讨论到这里。
04 从最合适自己的改进环节入手
最后值得一提的是,提升系统稳定性,减少生产事故是一个需要所有人从各个维度努力的持续性,系统性的工程。不同系统所处的稳定性阶段不一样,生产事故各类根因占比也不一样,但整体的分析方式和演进路线应该大同小异。本文通过对历史数据进行分析总结,找出了一条针对自身系统的路线清晰,容易上手,又能快速见效的演进之路。根据二八原则,这条路通过两分努力快速实现八成效果,为系统研发和运维团队赢得更多信任和时间去逐步实施更完整更长久的改进。
因此,每个人都可以根据历史事故归纳分析,对自己系统的稳定性状态做一次快速的诊断,然后根据诊断结果,参考文中所列的“各阶段改进效果对比分析”表格,选择最合适的阶段优先介入改进并逐步扩散到其他阶段,这也符合敏捷迭代的思想。
版权声明: 本文为 InfoQ 作者【绵竹的竹】的原创文章。
原文链接:【http://xie.infoq.cn/article/8576bfa5d2352436a67dbffc0】。文章转载请联系作者。

绵竹的竹 2017.08.15 加入
还未添加个人简介









评论