【得物技术】统一 OLAP 查询平台之语义层
背景:数据开发过程中,如果对分析指标理解有偏差将直接导致整个数据链路的返工,如何以最小代价应对分析指标的合理变动?同时,面对海量数据分析如何提高查询性能?这些问题都可以通过统一 OLAP 查询平台来解决。
一、数据从需求到加工过程中痛点
从下图 1-1 看出数据开发的一般过程:
由业务方提出各种指标的分析需求。
产品和应用讨论分析指标,并拉上数仓和业务一起确认指标。
数仓理解指标,并开始数据加工。首先,从 ODS 层开始对数据进行抽取、清洗、加工。其次,在 DW 层进行建模及简单指标计算。最后,输出结果表到 ADS 层。
应用开发的同学理解指标并完成最终业务逻辑的 SQL。
业务方开始使用。
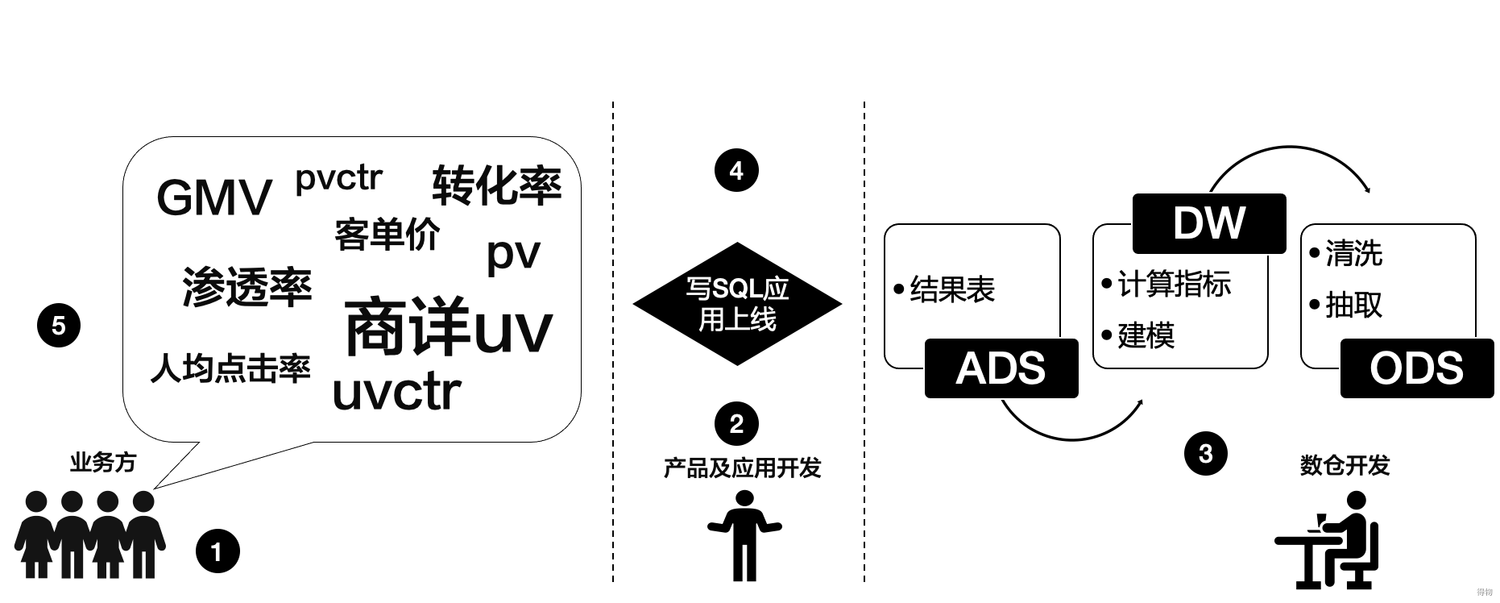
图 1-1 数据开发一般过程*
1.1 痛点 1:数据链路依赖性导致波动性
数据加工链路的每一层都是上层依赖下层,如果某一层逻辑发生了改变,都会引起整个数据链路开发逻辑的波动。特别是,当数据量超大时,这种波动的开销会被放大,变得非常昂贵。期望能最小代价的吸收指标逻辑的合理波动。
1.2 痛点 2: 所有链路上人员都要理解指标含义
从数据开发的链路来看,所有相关人员都必须理解指标逻辑才能把工作进行下去。对于应用开发的同学他们本该只专注与前后端应用的开发,怎么完善用户体验,怎么实现高并发,怎么做缓存等等,而不是花精力来维护 SQL。且维护的 SQL 里充满了复杂的指标定义,如果多处使用到还要再 COPY/PASTE 一下,时间长了实在难以维护。
1.3 痛点 3: 查询模式呆板
数据一旦写入 ADS 层,因为上层应用直接绑定目标表进行查询,当目标表数据规模随着时间积累变得很大时,查询性能不能保证,优化手段实在有限。
二、统一语义层解决痛点
统一语义层的本意是利用语义实现更广泛的对业务数据理解的一致性,避免理解误差。
2.1 多视角解决理解上的偏差
统一语层对不同用户展示不同视角:
对业务、分析师、应用层只展示维度名称,指标名称。最简单情况应用或分析师通过托拉拽即可实现数据分析。
对建模、数仓开发人员展现具体数据表的视角,比如,SUM(sales)具体指标逻辑的定义、维度信息、分区等信息。
2.2 通过语义逻辑缓冲合理指标逻辑变化
从数据加工链路中可以看到,当指标发生了变化,会引起整个链路的波动。因为所有应用开发都是硬绑定具体业务逻辑 SQL,没有任何缓冲地带,一旦指标逻辑有变化,要么在应用源码里改,要么在数据加工链路上改,不管在哪改,都会引起额外的开销。
相比之下,语义层具备维护指标逻辑的能力,对外只暴露指标名,内部可以缓冲一定范围的逻辑改变。比如:某个指标需要加个判断条件(case when)或者需要加减乘除等运算,都可以通过修改语义层指标逻辑来完成,从而保证了上游的应用及下游的数仓数据链路加工的稳定。
2.3 通过语义层优化 SQL
从图 2-1 左边图示可以看出,统一语义层是一个 json 描述文件,定义了模型的名字,表示适用什么场景。维度的范围及指标的定义信息。应用只需要知道模型名、指标名、维度名就可以分析了,如图 2-1 右边图示所示,根据语义层写出简洁的 SQL。

图 2-1 统一语义层表示*
图 2-2 展示了应用了语义层后,SQL 的优化情况。SQL 不仅简洁了,如果某些指标在应用的多个模块出现只需要用指标名即可,而不用去维护指标逻辑。语义层维护指标逻辑,一旦指标逻辑发生了改变,应用层引用的指标立即生效。

图 2-2 实战统一语义层 SQL 优化*
2.4 通过语义层选择最优查询对象
前面说过,现有开发模式是应用直接绑定 ADS 结果表作为查询对象,性能完全取决于结果表的大小及表结构。如果通过语义层来查询,因为绑定的是语义模型,并没有绑定具体查询对象。所以,真正查询时可以根据具体 SQL 选择最优查询对象来回答查询,从而实现查询性能的最优化,具体做法将在下次 BLOG 的统一 OLAP 查询平台引擎部分给大家分享。
三、总结
综上所述,统一语义层提供一种可能让需求方和开发方都能从自己熟悉的领域来理解指标含义,从而避免了理解的误差。此外,语义层具备一定逻辑缓冲能力,吸收指标逻辑合理的变化。最后,语义层提供灵活可选查询对象的能力,为进一步优化查询性能做了准备。
文|飞狐
关注得物技术,携手走向技术的云端
版权声明: 本文为 InfoQ 作者【得物技术】的原创文章。
原文链接:【http://xie.infoq.cn/article/6d6bfdff198d095f66b63dc20】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

得物APP技术部 2019.11.13 加入
关注微信公众号「得物技术」









评论