
Shuttle + Alluxio 加速内存 Shuffle 起飞

00 前言
Shuttle[1] 是 OPPO 大数据团队开源的高可用高性能的 Spark Remote Shuffle Service,文章[2]中详细介绍了 Shuttle 的架构和设计理念。Shuttle 在设计之初选用分布式文件系统作为存储 Shuffle 数据的基座,灵活利用多种分布式存储的优势。同时,将存储计算剥离,不依赖本地存储介质,方便云上部署。
基于磁盘存储的 Remote Shuffle 已经解决磁盘碎片读写问题,但小规模作业的 Shuffle 性能提升仍不明显。那么 Shuffle 还有哪些潜力可挖 ?我们观察到,线上计算集群物理内存真实利用率普遍偏低,能否利用闲置内存加速 Shuffle 过程?Shuttle 可以灵活匹配分布式文件系统,找一款兼顾内存和磁盘的分布式存储文件系统即可。经过调研,我们选择的解决方案是:Shuttle + Alluxio[3],充分利用闲置内存,加速 Shuffle 计算。
01 为什么是 Alluxio
当前的服务器内存配置都比较高,但在大数据 Shuffle 场景下,单机内存还是太少,尤其对数据量大的任务来说,往往显得捉襟见肘。如果能将各个机器的内存整合起来,上千台机器的内存统一调度,将大大扩展内存计算的场景。
Alluxio 目前已经成为业界比较受欢迎的分布式内存缓存/文件系统,在大数据计算和 AI 领域都有广泛的应用。
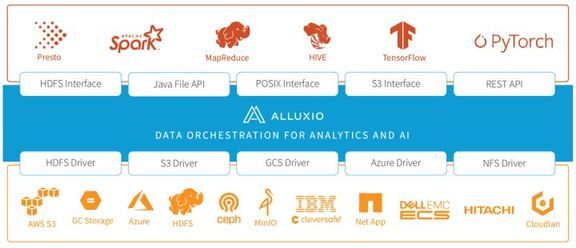
如上图所示,Alluxio 上层支持多种计算引擎,包括数据分析和 AI 领域;下层支持多种存储,包括分布式文件和对象存储。Alluxio 很好的弥补了计算引擎和底层存储的中间地带:对分布式内存的管理。我们选择 Alluxio 作为 Shuffle 场景的内存缓存系统,主要考虑的是 Alluxio 以下的优势:
智能多层缓存[4]:利用内存是我们对性能的考量,当内存不够的时候,数据保存在哪里?这一点决定了系统的稳定性。Alluxio 的数据管理不局限在内存上,当内存不够,Alluxio 可以将数据落盘(SSD/HDD,我们内部版本实现)。这是我们选择 Alluxio 最重要的原因,用内存加速,但不能完全把数据的稳定性交给内存。
本地读写优势:分布式存储跟本地存储在读写效率上对比往往有差距,尤其是在大并发场景下。我们在使用 HDFS 承接 Shuffle 数据时发现,HDFS 多个文件同时读写,每个文件会用两个线程来处理(DataStreamer 和 ResponseProcessor),分别处理数据写入和 DataNode 的响应。ShuffleWorker 单机同时打开文件个数可达上万,对 CPU 造成比较大的压力。
另外,HDFS 在读写本地数据时,通过 127.0.0.1 回环地址读写,虽然不会走网卡,数据还是会走完其他的网络读写流程,在本地读写的时候并没有明显的性能提升。
Alluxio 读写文件的线程采用 NIO 的线程池模型,本地直接读写内存或者磁盘文件。这两个点对比 HDFS 这种分布式文件系统,在大量文件读写的场景 CPU 消耗更低。同时,本地直接读写内存或者磁盘效率更高,ShuffleWork 和 Alluxio 的 worker 部署在同一台机器上,性能优势更明显。
通用性:Alluxio 已经广泛应用在大数据存算和机器学习训练加速,主要场景有多存储统一命名空间[5],对 SQL 查询和机器学习加速[6][7][8]。Alluxio 有良好的通用性,线上大规模部署 Alluxio 后,不仅能在 shuffle 场景下有加速效果,在 Ad-hoc 查询以及机器学习等都可以充分利用 Alluxio 带来的好处。
02 Alluxio 性能优化
作为一款流行的分布式 Cache 系统,Alluxio 在小数据量读写场景下有着良好性能表现。但在大规模的数据读写场景,Alluxio 的性能表现有些差强人意。我们在一台配置 80 core cpu,384G memory,24 块 HDD 磁盘的物理机器,单机压测 Alluxio 1000 并发读写的性能,优化前的性能数据如 表 1 第三列所示。
测试结果显示,Alluxio 在大规模数据读写场景下,存在两个问题:
1、Worker/Client 内存溢出
2、磁盘读写速度太慢
分析原因如下:
1、Alluxio 使用 Grpc 通信,Grpc 线程模型层级过多,数据在多个线程池之间多次拷贝
2、数据使用 Pb 消息序列化,不能利用堆外内存的零拷贝优势
3、Grpc 对底层的 Netty 的直接内存控制不够灵活,导致直接内存 OOM
优化方案:
针对上面分析的问题,我们对 Alluxio 的读写数据底层通信模型进行了优化,主要优化点:
1、线程模型优化
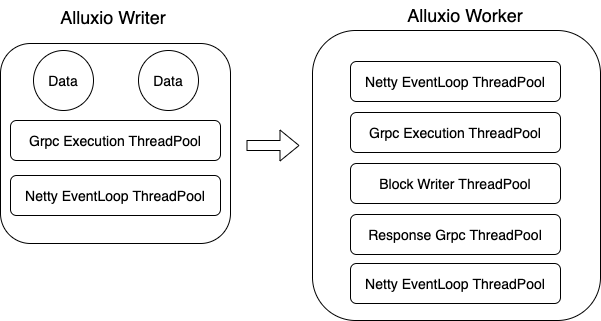
如图 2 所示,一个数据块从 Writer 到最终写入完成,经历的线程池多达 7 组,整个过程过于冗余。所以,我们第一步先优化线程模型:
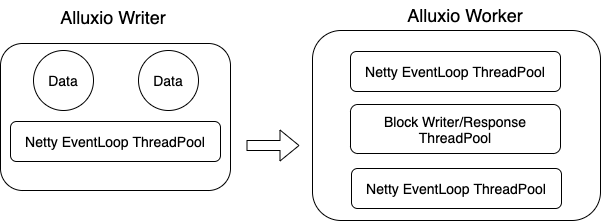
优化后的线程模型,一个数据块最终写入完成,只需经历 4 组线程池。降低数据在线程池之间的流转复制,对性能的提升非常直观。
同时,我们使用定制化的线程池模型代替 java 原生线程池,将同一个文件的读写绑定到同一个线程处理,取代使用锁保障对一个文件的读写操作,降低线程之间抢占锁带来的性能消耗。
2、数据序列化优化
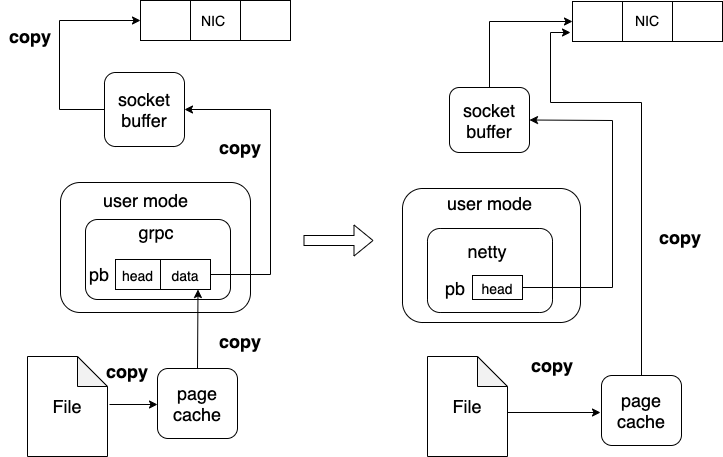
当前 Alluxio 数据传输序列化用的是 protobuf 格式,元数据和数据均包含在 pb 消息体内,这样带来两个问题:
a. 数据本身放到 pb 消息体内,序列化反序列化对 CPU 消耗比较大
b. 数据需要从堆外内存拷贝到堆内 Pb 消息体,不能利用 "零拷贝"发送数据的优势
3、其他优化点
a. 使用缓存+FileChannel 替代 MMap 读写本地磁盘数据,主要原因是 Alluxio 使用 MMap 需要频繁申请堆外内存,开销比较大。
b. 打开 Linux Native 预读,提升读数据性能
c. 远程读写数据根据内存使用流控,Client 端和 Alluxio Woker 端的读写数据匹配,降低 OOM 风险
优化效果
我们直接看优化前后的对比数据:
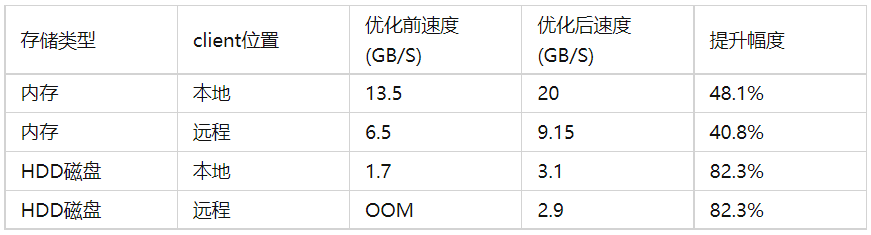
注:速度为读写数据速度算数平均值
经过优化后,Alluxio 内存和磁盘读写性能均有大幅的提升,已经满足在 Shuffle 这种大规模读写的场景下的性能需求,下面我们介绍一下 Alluxio 对 Shuffle 的性能提升。
03 Alluxio 加速 Shuttle 起飞
Shuttle[2]已经基于 HDFS,CubeFS 等以磁盘存储介质的分布式文件系统的 Remote Shuffle,显著提升了 shuffle 的性能和稳定性。显著我们使用 Alluxio 作为 Shuttle 的底层缓存数据的底座,性能再次飞升。我们先介绍一下整体架构:
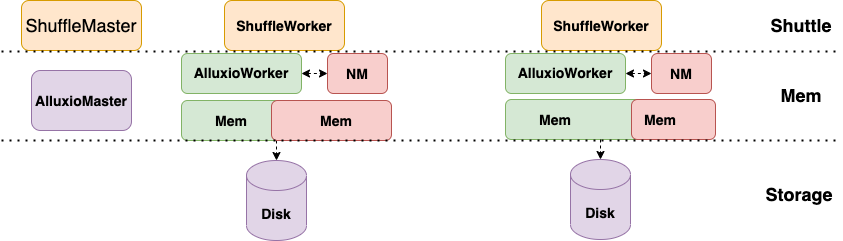
ShuffleWorker 与 AlluxioWorker 部署到线上计算节点,可以利用起来线上集群计算节点空闲内存。ShuffleWorker 接受到数据将数据交付 AlluxioWorker,内存如果不够用,AlluxioWorker 自身有主动将内存数据落盘的机制(自研功能)。为保障 Alluxio 对内存的使用不影响本机上的计算任务对内存的需求。我们设计了以下两个机制:
动态管理内存:
为了保障不影响线上任务正常运行,我们在 NodeManager 中新增 MemManager 模块,AlluxioWorker 中新增 MemDumper 模块,用来协调拉起的 container 的内存使用与 Alluxio 缓存使用的内存的分配比例。当 container 占用的内存水位逐步升高但是未达到 container 申请内存的上限,MemManager 会通知本机上 AlluxioWorker 的 MemDumper 释放一定的内存,MemDumper 会将挑选部分数据刷到磁盘,释放内存。
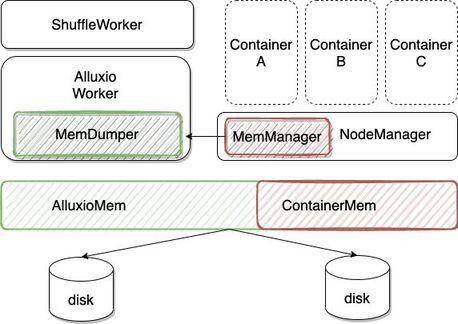
其实在这种方式下,Alluxio 是在“偷”用线上计算资源的内存在用。这一点是基于我们观察线上计算集群的物理内存使用率普遍偏低的背景下做这样的设计。如果 Alluxio 集群是独立部署,内存独占,可以不用考虑这么多。
Shuffle 数据分级:
前面讲述的是 Alluxio 和 NodeManager 协调内存的使用,在 Shuttle 与 Alluxio 之间,我们对不同的作业的数据存储也做了区分。简而言之,内存是稀缺资源,虽然我们将大量闲置内存统一管理起来了,但也不能完全覆盖线上所有作业使用内存做 Shuffle。所以,我们根据线上作业优先级区分使用内存的量,尽量保障高优先级和小作业的数据使用内存 Shuffle。
具体策略:作业 Partition 文件可用内存量跟作业优先级成正比,优先级越高,单个 Partition 文件可用内存越多。这样,既能保障高优先级作业尽量用内存,又能保障足够小的作业使用内存。我们的线上作业分为 9 级,最低一级的作业每个 Partition 可用内存为 64M,每升一级,可用内存增加 32M,如图 7 所示。
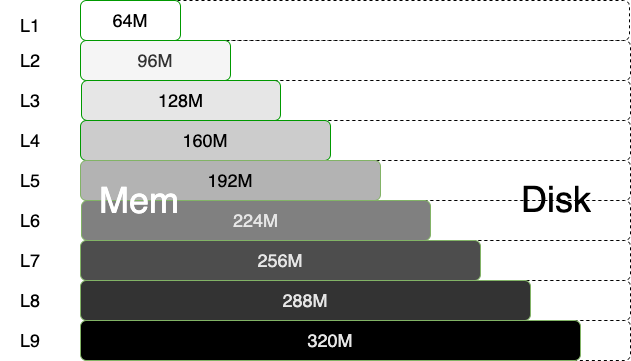
如果分区文件超过可用内存大小,剩余的数据量会使用磁盘存储,如图 7 所示,深色区域数据存储在内存,白色区域数据存储在磁盘。
04 测试结果
上面介绍了各种优化策略,我们看一下最终 Alluxio 结合 Shuttle 对任务的计算性能提升多少,我们仍然选用 TeraSort 作为对比 Benchmark。不仅对比与 HDFS 磁盘存储的性能,同时也会跟之前对比过的 EMR-RSS 一起做对比。
测试环境同[2]文中测试环境,同样多次测试取平均值对比,时间单位:分钟;测试结果数据见表 2:
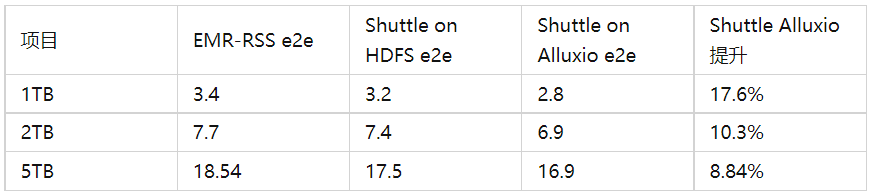
随着数据量增长,Alluxio 的性能提升幅度有所下降,这主要是因为内存不能覆盖所有 Shuffle 数据,会有部分数据溢写到磁盘。数据规模越小,性能提升反会更明显。
我们之所以跟 EMR-RSS 对比,主要是因为文章[9]中 EMR-RSS 已经跟其他的 RSS 做过对比,同时,我们在文中[2]中也是跟 EMR-RSS 做的对比。所以,这里延续之前的测试对比实验,不过,这里主要对比的是基于 Alluxio 的性能提升。
05 展望
我们将线上内存统一管理起来,后续可以更多的利用内存加速存储和计算效率。扩展更多的引擎利用内存:Trino,Flink 等,扩展更多的场景,比如:Broadcast 数据,物化视图中间计算结果缓存等。
附录
[1] Shuttle GitHub:
https://github.com/oppo-bigdata/shuttle
[2] Shuttle:
高可用 高性能 Spark Remote Shuffle Service https://mp.weixin.qq.com/s/FMvKGvVYcxNG4dNOFQlF0g
[3] Alluxio GitHub:
https://github.com/Alluxio/alluxio
[4] Alluxio 概览:
https://docs.alluxio.io/os/user/stable/cn/Overview.html
[5] Alluxio 统一命名空间:
https://docs.alluxio.io/os/user/stable/cn/core-services/Unified-Namespace.html
[6] Alluxio 助力 Uber 实现 Presto 加速:
https://mp.weixin.qq.com/s/ICFASUDYPzkb3nRLGxcGxg
[7] InfoWorld 文章丨将数据编排技术用于 AI 模型训练:
https://mp.weixin.qq.com/s/N8SIszTIMCtM4AhRB_9ajg
[8] 【Alluxio&大型电商】加速优化唯品会亿级数据服务平台:
https://www.modb.pro/db/332728
[9] 阿里云 EMR Remote Shuffle Service 在小米的实践:
https://mp.weixin.qq.com/s/xdBmKkKL4nW7EEFnMDxXYQ
作者简介
David Fu OPPO 大数据计算平台架构师
负责大数据计算平台技术演进设计开发,曾供职于阿里云,去哪儿网大数据平台,拥有 10 年大数据架构,开发经验
Jack Xu OPPO 高级数据平台工程师
目前就职于 OPPO 数据架构团队,主要负责 Spark 计算引擎和 Shuttle 的开发,拥有丰富大数据架构和开发经验
想要获取更多有趣有料的【活动信息】【技术文章】【大咖观点】,请关注[Alluxio智库]:

版权声明: 本文为 InfoQ 作者【Alluxio】的原创文章。
原文链接:【http://xie.infoq.cn/article/624f9abd393b025e10dbbf64e】。文章转载请联系作者。

还未添加个人签名 2022.01.04 加入
Alluxio是全球首个面向基于云原生数据分析和人工智能的开源的资料编排技术!能够在跨集群、跨区域、跨国家的任何云中将数据更紧密地编排接近数据分析和AI/ML应用程序,从而向上层应用提供内存速度的数据访问。








评论