VEGA:诺亚 AutoML 高性能开源算法集简介
摘要:VEGA 是华为诺亚方舟实验室自研的全流程 AutoML 算法集合,提供架构搜索、超参优化、数据增强、模型压缩等全流程机器学习自动化基础能力。
本文分享自华为云社区《VEGA:诺亚AutoML高性能开源算法集简介》,作者: kourei。
VEGA 是华为诺亚方舟实验室自研的全流程 AutoML 算法集合,提供架构搜索、超参优化、数据增强、模型压缩等全流程机器学习自动化基础能力。目前集成的算法大多数已经合入了华为 DaVinci 全栈 AI 解决方案 CANN+ MindSpore 中,一些简单的测试表明相比 GPU 具备相当大的优势,预计下个版本 Vega 会提供对 DaVinci 的支持。
作为针对研究人员和算法工程师量身定制的自动机器学习工具,VEGA 在 2019 年 12 月在华为内源发布,支撑起了诺亚内部多个团队(计算视觉、推荐搜索和 AI 基础研究)的自动化机器学习算法的研究,在相关的 AI 顶会上(CVPR/ICCV/ECCV/AAAI/ICLR/NIPS)产出 20+算法。以下是本次开源的代表性 AutoML 算法简介:
自动化网络架构搜索(NAS)
基于硬件约束的高效分类网络搜索方案(CARS)
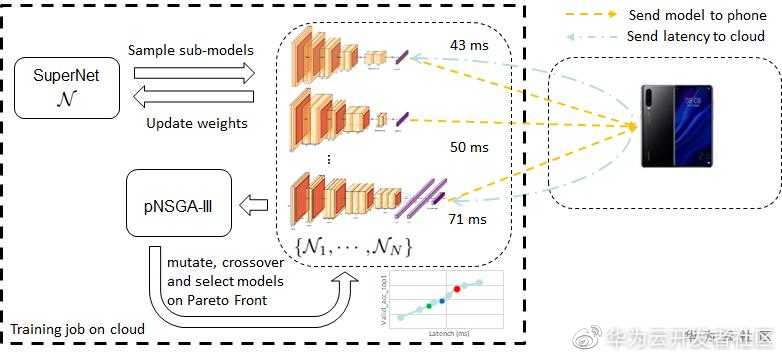
在不同的应用场景中,计算资源约束条件有所不同,因此对于搜索的结果自然的有着差异化的结果需求。此外,尽管基于进化算法的 NAS 方法取得了不错的性能,但是每代样本需要重头训练来进行评估,极大影响了搜索效率。本文考虑了现有方法的不足,提出一种基于连续进化的多目标高效神经网络结构搜索方法(CARS)。CARS 维护一个最优模型解集,并用解集中的模型来更新超网络中的参数。在每次进化算法产生下一代种群的过程中,网络的参数可以直接从超网络中继承,有效提高了进化效率。CARS 一次搜索即可获得一系列不同大小和精度的模型,供用户根据实际应用中的资源约束来挑选相应的模型。相关工作发表在 CVPR2020: https://arxiv.org/abs/1909.04977 。
轻量级超分网络结构搜索(ESR-EA)
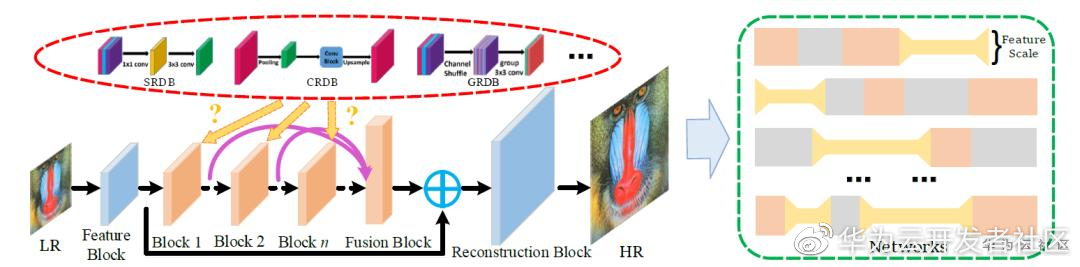
诺亚提出了一种轻量级超分网络结构搜索算法,从通道、卷积和特征尺度三个角度出发构建高效的超分网络基本模块。该算法以高效模块为基础,以模型的参数量、计算量和模型精度为目标,使用多目标优化进化算法搜索轻量级超分网络结构。该算法可以从通道、卷积和特征尺度三个角度对超分网络的冗余进行全面压缩。实验表明,在同等参数量或者计算量的情况下,该算法搜索到的轻量级超分网络(ESRN)在标准测试集(Set5,Set14,B100,Urban100)上取得了比手工设计的网络结构(CARN 等)更好的效果。除此之外,该算法也可以在确保算法精度的前提下降低计算量,满足移动设备的时延和功耗约束。相关论文发表在 AAAI 2020: https://www.aaai.org/Papers/AAAI/2020GB/AAAI-SongD.4016.pdf 。
端到端的检测网络架构搜索方案(SM-NAS)
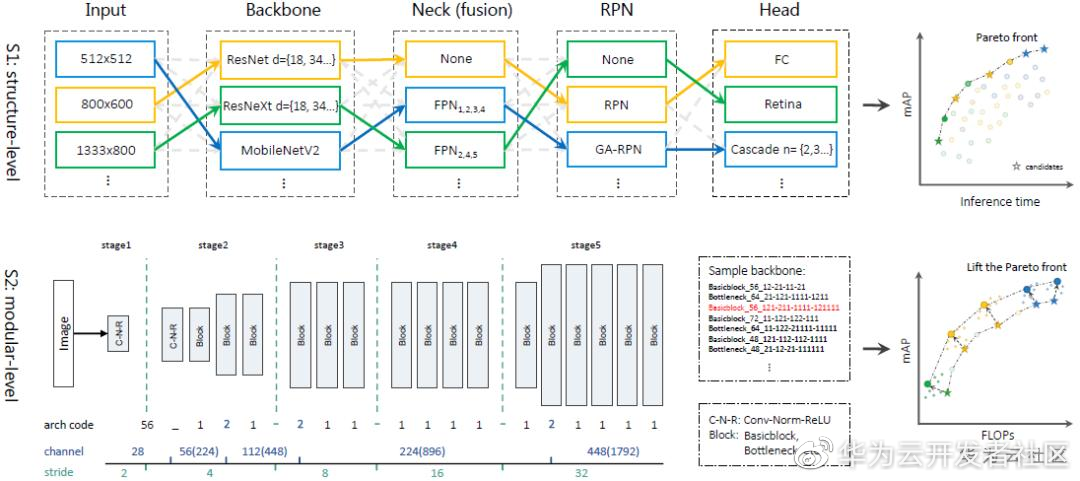
现有的目标检测模型可以被解耦成几个主要部分:骨干(Backbone),特征融合网络(Neck),RPN 和以及 RCNN 头部。每个部分可能有不同的模块与结构设计,如何权衡不同组合的计算成本和精确度是一个重要问题。现有的目标检测 NAS 方法(NAS-FPN, DetNas 等)仅专注于搜索单个模块的更好设计,如骨干网络或特征融合网络,而忽略了对系统整体的考量。为了解决这个问题,在本文中我们提出了一种两阶段从结构化到模块化的神经网络搜索策略,名为 Structural-to-Modular NAS(SM-NAS)。具体而言,结构化阶段进行模型架构的粗搜索,确定针对当前任务的最优模型架构 (如使用单阶段检测器还是双阶段检测器,使用何种类型的 backbone 等),以及与之匹配的输入图像尺寸大小;模块化搜索阶段则对 backbone 模块进行细致的结构调优,进一步提高模型性能。。在搜索策略上,我们采用了演化算法,并同时考虑了模型效率与模型性能双重最优,使用 non-dominate sorting 构建 Pareto front,来获得一系列在多目标上同时达到最优的网络结构。此外,我们探索了一种有效的训练策略,使得网络在没有 imagenet pretrain 的情况下能够达到比有 pretrain 更快的收敛速度,从而更加快速、准确地评估任意 backbone 的性能。在 COCO 数据集上,我们搜索得到的模型在速度与精度上均大幅度领先传统的目标检测架构,例如我们的 E2 模型比 Faster-RCNN 速度提高一倍,mAP 达到 40%(提升 1%);我们的 E5 模型与 MaskRCNN 的速度相似,mAP 能够达到 46%(提升 6%)。相关工作发表在 AAAI2020: https://arxiv.org/abs/1911.09929 。
高效的检测网络骨干架构搜索方案(SP-NAS)
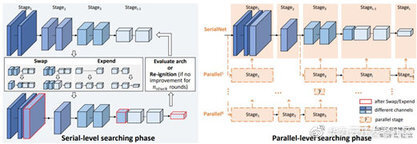
我们使用神经网络结构搜索(NAS)技术自动设计针对特定于任务的主干网络,以弥合分类任务和检测任务之间的差距(domain gap)。常见的深度学习物体检测器通常会使用一个针对 ImageNet 分类任务设计和训练的骨干网络。现有算法 DetNAS 将搜索检测主干网络的问题变为预先训练一个权重共享的超级网络,以此来选择最佳的子网络结构。但是,此预先定好的超级网络无法反映所采样子结构的实际性能等级,并且搜索空间很小。我们希望通过 NAS 算法设计一个灵活且面向任务的检测主干网:提出了一个名为 SP-NAS 的两阶段搜索算法(串行到并行的搜索)。具体来说,串行搜索阶段旨在通过“交换,扩展,重点火”的搜索算法在特征层次结构中高效找到具有最佳感受野比例和输出通道的串行序列;然后,并行搜索阶段会自动搜索并将几个子结构以及先前生成的主干网络组装到一个更强大的并行结构的主干网络中。我们在多个检测数据集上验证了 SP-NAS 的效果,搜索得到的架构可达到 SOTA 结果,即在 EuroCityPersons 的公开的行人检测排行榜上达到第一名的顶级性能(LAMR:0.042);在准确度和速度方面都优于 DetNAS 和 AutoFPN。相关工作发表在 CVPR2020: https://openaccess.thecvf.com/content_CVPR_2020/papers/Jiang_SP-NAS_Serial-to-Parallel_Backbone_Search_for_Object_Detection_CVPR_2020_paper.pdf 。
自动化训练(AutoTrain)
超越谷歌的训练正则化方法(Disout)
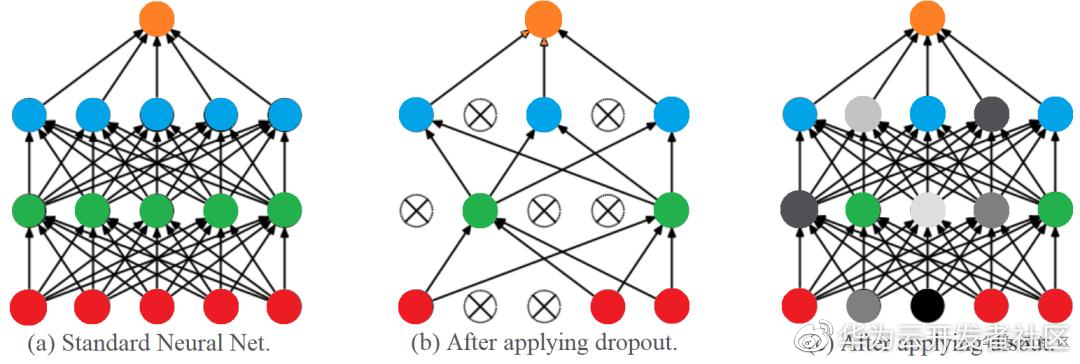
为了从给定的数据集中提取重要的特征,深度神经网络通常包含大量可训练的参数。一方面,大量的可训练参数增强了深度网络的性能。另一方面,它们带来了过拟合的问题。为此,基于 Dropout 的方法在训练阶段会禁用输出特征图中的某些元素,以减少神经元间的共适应。尽管这些方法可以增强所得模型的泛化能力,但是基于是否丢弃元素的 Dropout 并不是最佳的解。因此,我们研究了与深度神经网络的中间层有关的经验 Rademacher 复杂度,并提出了一种用于解决上述问题的特征扰动方法(Disout)。在训练时,通过探索泛化误差上界将特征图中随机选择的元素替换为特定值。实验证明,在多个图像数据集,我们提出的特征图扰动方法具有更高的测试准确率。相关工作发表在 AAAI 2020: https://arxiv.org/abs/2002.11022 。
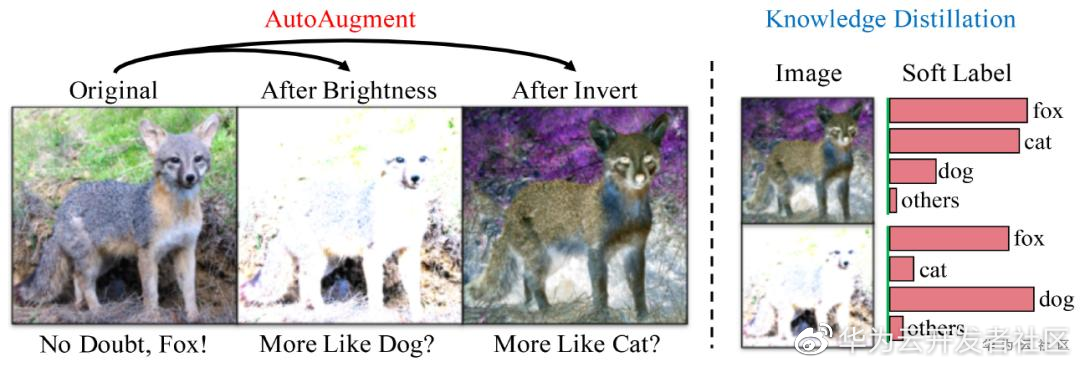
利用知识蒸馏抑制自动数据扩增的噪声(KD+AA)
本算法心思想是希望解决自动数据扩增(AA)方法自身的一些劣势。AA 是对整个数据集去搜索最佳数据增强策略的,尽管从全局来看 AA 能够让数据变得更加差异化,让最终模型性能变得更好;但是 AA 是相对粗糙的,并不是对单张图像做优化的,因此相对而言会有一定的防线。在数据增强强度比较大的时候,容易对某些图像带来语义混淆的问题(即由于过度消去具有判别力的信息而导致图像语义发生变化。这就是我们说的语义混淆。显然在模型训练的时候,我们再拿之前的狐狸标签来做约束指导是不合适。为了解决这个问题,我们使用知识蒸馏(KD)方法,通过一个预训练好的模型来生成软标签,该标签就可以指导经过 AA 的图像他的标签最好应该是什么。这个算法简单而有效,在与大模型结合后,在 ImageNet 上取得了当前最优性能 85.8%。相关论文发表于 ECCV 2020: https://arxiv.org/abs/2003.11342v1 。
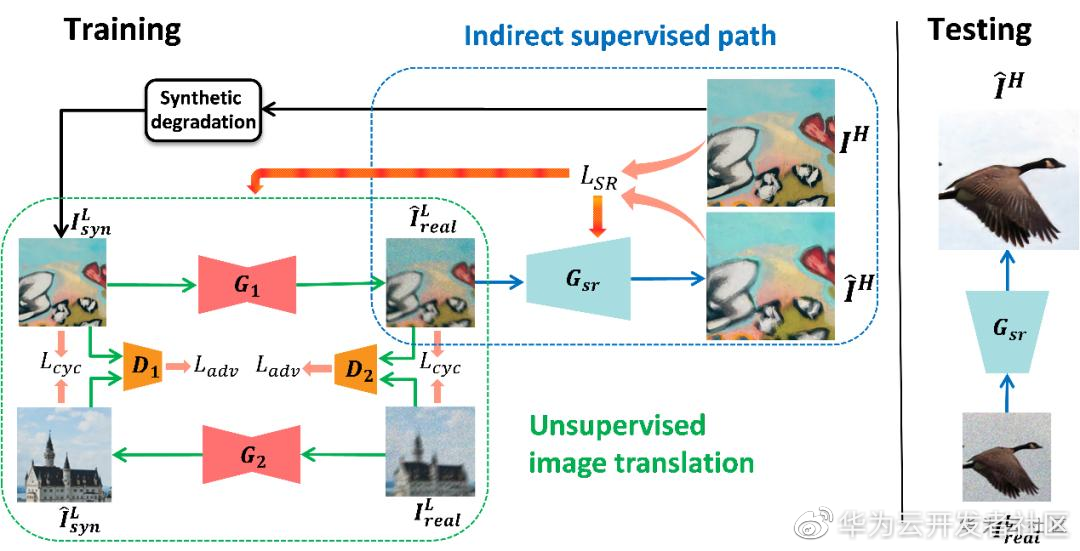
自动化数据生成(AutoData)
基于生成模型的低成本图像增强数据获取方案(CylceSR)
在特定的图像增强任务(以超分为例)中,由于很难在现实场景里获取到成对的数据,因此学术界大多采用合成的成对数据进行算法研究,然而通过合成数据获得到的算法模型往往在现实场景中表现并不好,为了解决上述问题,我们提出了一种新颖的算法:该算法以合成低质图像为桥梁,通过无监督图像转换完成合成图像域到真实场景图像域的转换,同时转换后的图像被用于监督训练图像增强网络。该算法足够灵活,可以集成任何无监督转换模型和图像模型。本方法通过联合训练图像转换网络和监督网络,相互协作来实现更好的降质学习和超分性能。所提出的方法在 NTIRE 2017 和 NTIRE 2018 的数据集上实现了很好的性能,甚至可以与监督方法相媲美;该方法在 NTIRE2020 Real-World Super-Resolution 比赛中被 AITA-Noah 团队采用并在 track1 中取得 IPIPS 第一、MOS 指标第二的成绩。相关论文发表于 CVPR 2020 Workshop on NTIRE: https://openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Chen_Unsupervised_Image_Super-Resolution_With_an_Indirect_Supervised_Path_CVPRW_2020_paper.pdf 。
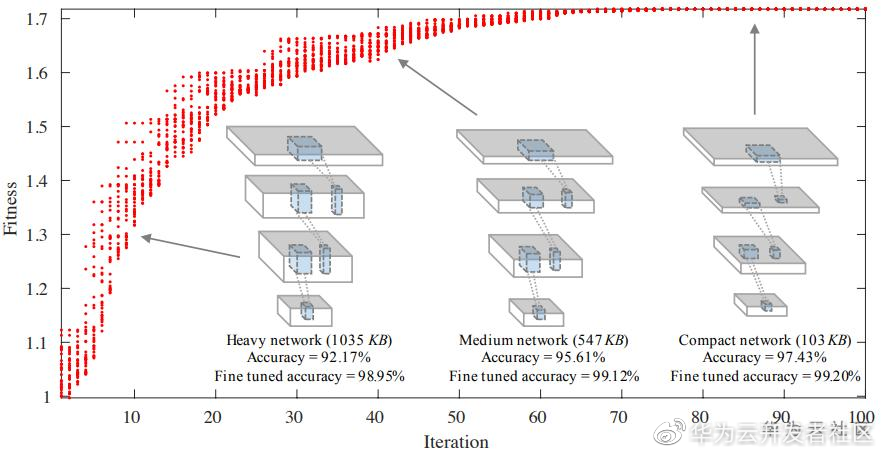
自动化网络压缩(AutoCompress)
基于进化策略神经网络自动压缩
该技术针对神经网络自动压缩,从压缩模型的识别精度、计算量、存储量、运行速度等多个指标出发,使用多目标优化进化算法,对神经网络进行混合比特量化、稀疏剪枝等压缩,搜索出每一层最优压缩超参数,得到一个包含若干性能优秀的压缩模型的非支配解集,可以满足使用者对不同指标的不同需求。该技术适用于高性能云服务器和弱计算性能的移动设备,对于高性能云服务器可以提供算法精度高且计算和内存消耗在一定范围内的模型,对于移动设备,可以在确保算法精度的前提下降低计算和内存消耗,满足移动设备的时延和功耗约束。相关论文发表在 KDD 2018: https://www.kdd.org/kdd2018/accepted-papers/view/towards-evolutionary-compression 。
本次开源发布初步稳定版本,未来不断将最前沿的算法加入其中,增加对新算法和 DaVinci 的支持。开源地址为: https://github.com/huawei-noah/vega ,请大家试用和反馈。
Vega 具备以下优势:
高性能 Model Zoo: 预置了诺亚大量性能领先的深度学习模型,提供在 ImageNet/MSCOCO/NuScenes /NITRE 等数据集上的最优性能模型。这些模型代表了诺亚在 AutoML 研究上的最新研究成果,可以直接使用:https://github.com/huawei-noah/vega/blob/master/docs/en/model_zoo/ 。
硬件亲和的模型优化:为了实现硬件的亲和性,Vege 定义了 Evaluator 模块,可以直接部署到设备上进行推理,支持手机、Davinci 芯片等多种设备的同时运行。
Benchmark 的复现:提供了 benchmark 工具来协助大家复现 Vega 提供的算法。
支持深度学习生命周期中的多环节,并基于 pipeline 编排进行灵活调用:内置了架构搜索、超参优化、损失函数设计、数据扩充、全量训练等组件,每个组件称之为一个 Step,可以将多个 Step 串联起来形式端到端的方案,方便大家试验不同的想法,提高可搜索范围,找到更好的模型。
最后,VEGA 提供大量的示例文档,帮助开发者快速上手。完整中英文文档请参考: https://github.com/huawei-noah/vega/tree/master/docs 。
版权声明: 本文为 InfoQ 作者【华为云开发者社区】的原创文章。
原文链接:【http://xie.infoq.cn/article/2922a020ce979b2a5c0e143a1】。文章转载请联系作者。

提供全面深入的云计算技术干货 2020.07.14 加入
华为云开发者社区,提供全面深入的云计算前景分析、丰富的技术干货、程序样例,分享华为云前沿资讯动态,方便开发者快速成长与发展,欢迎提问、互动,多方位了解云计算! 传送门:https://bbs.huaweicloud.com/









评论