Elasticsearch 可观测最佳实践分享!3 分钟带你快速入门!

简介
Elasticsearch 提供了许多指标,可以帮助您检测故障迹象并在遇到不可靠的节点,内存不足的错误以及较长的垃圾收集时间等问题时采取措施。需要监视的几个关键领域是:
集群运行状况和节点可用性
主机的网络和系统
搜索性能指标
索引性能指标
内存使用和 GC 指标
资源饱和度和错误
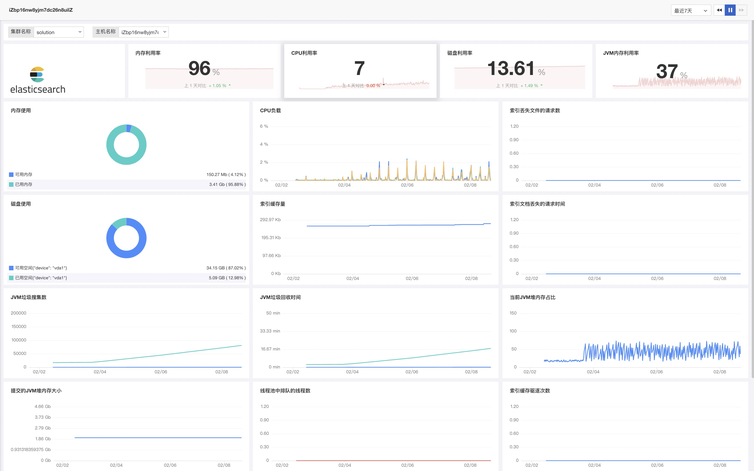
场景视图
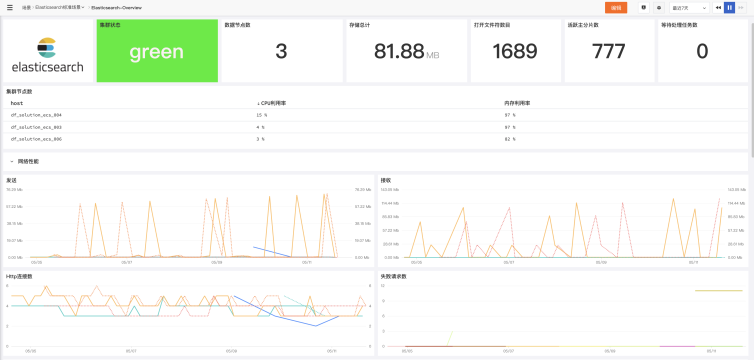

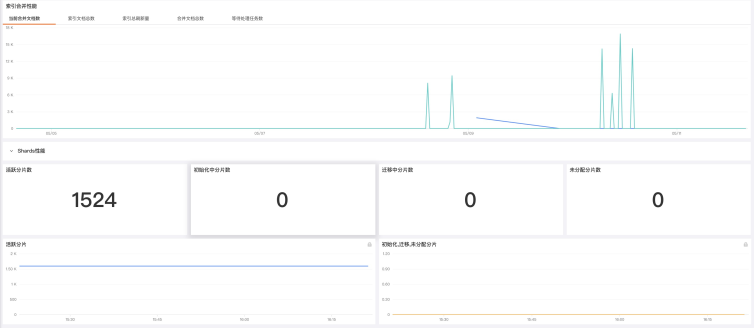

内置视图
前置条件
已安装 DataKit DataKit 安装文档
配置
监控指标采集
进入 DataKit 安装目录下的 conf.d/db 目录,复制 elasticsearch.conf.sample 并命名为 elasticsearch.conf。示例如下:
重新启动 datakit 生效
systemctl restart datakit
日志采集
进入 DataKit 安装目录下的 conf.d/log 目录,复制 tailf.conf.sample 并命名为 tailf.conf。示例如下:
[[inputs.tailf]]# glob logfiles# requiredlogfiles = ["/var/log/elasticsearch/solution.log"]
Elasticsearch 集群信息日志切割 grok 脚本
重新启动 datakit 生效
监控指标说明
1. 集群运行状况和节点可用性指标描述
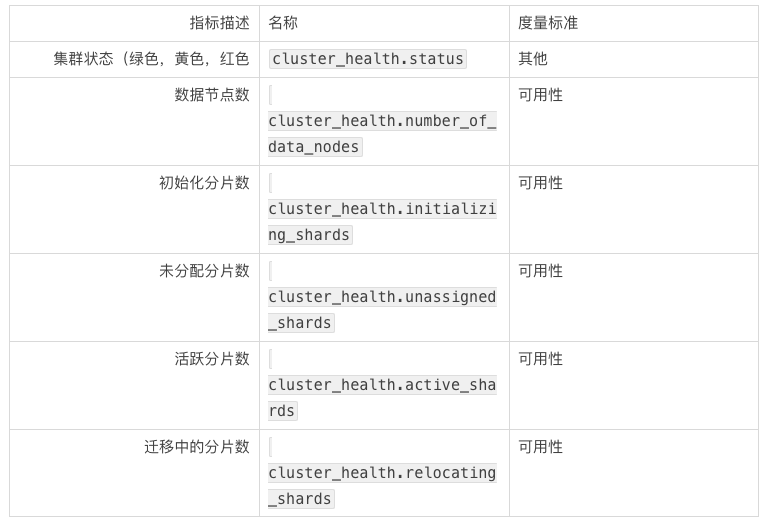
集群运行状况和节点可用性的要点
集群状态: 如果集群状态为 YELLOW,说明至少有一个副本分片未分配或者丢失。尽管这个时候搜索结果仍然是完整的,但是如果更多的分片消失的话,有可能造成整个索引的数据丢失。如果集群状态为 RED,则表示至少有一个主分片丢失,索引缺少数据,这意味着搜索将返回部分结果,而且新的文档数据也无法索引到该分片。这时可以考虑设置一个告警,如果状态为黄色超过 5 分钟,或者上次检测状态为红色,则触发警报。
初始化(initializing)和未分配(unassigned)状态的分片: 当索引首次创建或者节点重新启动时,由于 Master 节点试图将分片分配给 Data 节点,所以在转换为“started”或“unassigned”状态之前,该分片将暂时处于“initializing”状态。 如果您看到分片处于初始化状态或未分配状态的时间过长,则可能是群集不稳定的信号。
2. 主机的网络和系统指标描述
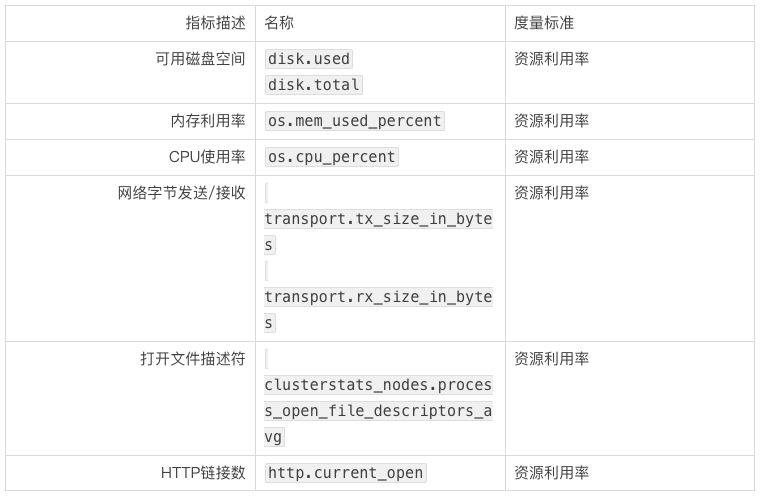
主机的网络和系统的要点
磁盘空间: 如果当 Elasticsearch 集群是写负载型的,那么这个指标将变得更加重要。因为一旦空间不足,将不能进行任何插入和更新操作,节点也会下线,这应该是业务上不允许的。如果节点的可用空间小于 20%,应该利用类似 Curator 这样的工具,删除一些占用空间较大的索引来释放部分空间。如果业务逻辑上不允许删除索引,那么另一种方案就是扩容更多的节点,让 Master 在新节点间重新分配分片(尽管这样会增加 Master 节点的负载)。另外需要记住一点,包含需要分析(analyzed)的字段的文档占用的磁盘空间比那些不需要分析(non-analyzed)的字段(精确值)的文档要多得多。
节点上的 CPU 利用率: 利用图示来展示不同节点类型的 CPU 使用情况会很有帮助。例如,可以创建三个不同的图来表示群集中的不同节点类型(例如 Data 节点,Master 节点和 Client 节点)的 CPU 使用情况,通过对比图示来发现是否某一种类型的节点过载了。如果您看到 CPU 使用率增加,这通常是由于大量的搜索或索引工作造成的负载。设置一个通知,以确定您的节点的 CPU 使用率是否持续增长,并根据需要添加更多的节点来重新分配负载。
网络字节发送/接收: 节点之间的通信是衡量群集是否平衡的关键组成部分。 需要监视网络以确保网络正常运行,并且能够跟上群集的需求(例如,在节点间复制或分片的重新分配)。 Elasticsearch 提供有关集群节点间通信的传输指标,但是也可以通过发送和接收的字节速率,来查看网络正在接收多少流量。
打开文件描述符: 文件描述符用于节点间的通信、客户端连接和文件操作。如果打开的文件描述符达到系统的限制,那么新的连接和文件操作将不可用,直到有旧的被关闭。 如果超过 80%的可用文件描述符正在使用中,则可能需要增加系统的最大文件描述符计数。 大多数 Linux 系统限制每个进程中只允许有 1024 个文件描述符。 在生产中使用 Elasticsearch 时,应该将操作系统文件描述符数量设置为更大的值,例如 64,000。
HTTP 链接: 除了 Java Client 以外的任何语言发送的请求都将使用基于 HTTP 的 RESTful API 与 Elasticsearch 进行通信。 如果打开的 HTTP 连接总数不断增加,则可能表明您的 HTTP 客户端没有正确建立持久化连接。 重新建立连接会在请求响应时间内增加额外的时间开销。 因此务必确保您的客户端配置正确,以避免对性能造成影响,或者使用已正确配置 HTTP 连接的官方 Elasticsearch 客户端之一。
3. 查询性能指标
如果您主要使用 Elasticsearch 进行查询,那么您应该关注查询延迟并在超出阈值时采取措施。监控 Query 和 Fetch 的相关指标可以帮助您跟踪查询在一段时间内的执行情况。例如,您可能需要跟踪查询曲线的峰值以及长期的查询请求增长趋势,以便可以优化配置来获得更好的性能和可靠性。
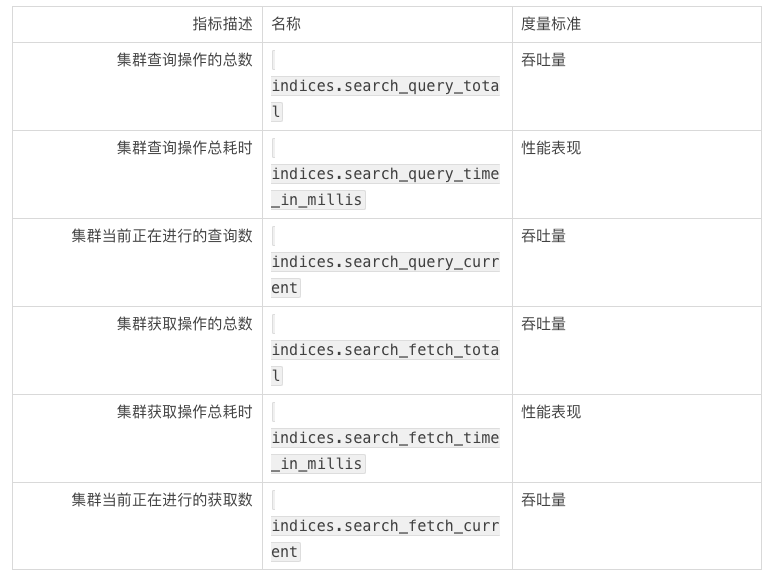
搜索性能指标的要点:
查询(Query)负载: 监控当前查询并发数可以大致了解集群在某个时刻处理的请求数量。对不寻常的峰值峰谷的关注,也许能发现一些潜在的风险。可能还需要监控查询线程池队列的使用情况。
查询(Query)延迟: 虽然 Elasticsearch 并没有直接提供这个指标,但是我们可以通过定期采样查询请求总数除以所耗费的时长来简单计算平均查询延迟时间。如果超过我们设定的某个阀值,就需要排查潜在的资源瓶颈或者优化查询语句。
获取(Fetch)延迟: 查询(search)过程的第二阶段,即获取阶段,通常比查询(query)阶段花费更少的时间。如果您注意到此度量指标持续增加,则可能表示磁盘速度慢、富文档化(比如文档高亮处理等)或请求的结果太多等问题。
4. 索引性能指标
索引(Indexing)请求类似于传统数据库里面的写操作。如果您的 Elasticsearch 集群是写负载类型的,那么监控和分析索引(indices)更新的性能和效率就变得很重要。在讨论这些指标之前,我们先看一下 Elasticsearch 更新索引的过程。如果索引发生了变化(比如新增了数据、或者现有数据需要更新或者删除),索引的每一个相关分片都要经历如下两个过程来实现更新操作:refresh 和 flush。

索引性能指标的要点:
索引(Indexing)延迟: Elasticsearch 并未直接提供这个指标,但是可以通过计算 index_total 和 index_time_in_millis 来获取平均索引延迟。如果您发现这个指标不断攀升,可能是因为一次性 bulk 了太多的文档。Elasticsearch 推荐的单个 bulk 的文档大小在 5-15MB 之间,如果资源允许,可以从这个值慢慢加大到合适的值。
Flush 延迟: 由于 Elasticsearch 是通过 flush 操作来将数据持久化到磁盘的,因此关注这个指标非常有用,可以在必要的时候采取一些措施。比如如果发现这个指标持续稳定增长,则可能说明磁盘 I/O 能力已经不足,如果持续下去最终将导致无法继续索引数据。此时您可以尝试适当调低 index.translog.flush_threshold_size 的值,来减小触发 flush 操作的 translog 大小。与此同时,如果你的集群是一个典型的 write-heavy 系统,您应该利用 iostat 这样的工具持续监控磁盘的 IO,必要的时候可以考虑升级磁盘类型。
5.内存使用和 GC 指标
在 Elasticsearch 运行过程中,内存是需要密切关注的关键资源之一。Elasticsearch 和 Lucene 以两种方式利用节点上的所有可用 RAM:JVM 堆和文件系统缓存。 Elasticsearch 运行在 Java 虚拟机(JVM)上,这意味着 JVM 垃圾回收的持续时间和频率将是其他重要的监控领域。
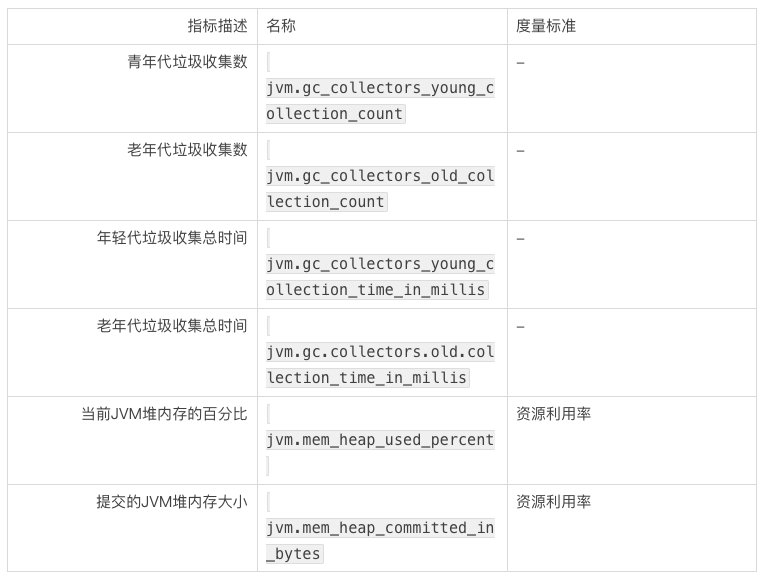
内存使用和 GC 指标的要点:
JVM 堆内存的使用量: Elasticsearch 默认当 JVM 堆栈使用率达到 75%的时候启动垃圾回收。因此监控节点堆栈使用情况并设置告警阀值来定位哪些节点的堆栈使用率持续维持在 85%变得非常有用,这表明垃圾回收的速度已经赶不上垃圾产生的速度了。要解决这个问题,可以增加堆栈大小,或者通过添加更多的节点来扩展群集。
JVM 堆内存的使用量和提交的 JVM 堆内存大小: 和 JVM 堆栈分配了多少内存(committed)相比,监控 JVM 使用了多少内存(used)会更加有用。使用中的堆栈内存的曲线通常会呈锯齿状,在垃圾累积时逐渐上升在垃圾回收时又会下降。 如果这个趋势随着时间的推移开始向上倾斜,这意味着垃圾回收的速度跟不上创建对象的速度,这可能导致垃圾回收时间变慢,最终导致 OutOfMemoryError。
垃圾收集持续时间和频率: 为了收集无用的对象信息,JVM 会暂停执行所有任务,通常这种状态被称为“Stop the world”,不管是 young 还是 old 垃圾回收器都会经历这个阶段。由于 Master 节点每隔 30s 检测一下其他节点的存活状态,如果某个节点的垃圾回收时长超过这个时间,就极可能被 Master 认为该节点已经失联。
内存使用情况: Elasticsearch 可以很好地使用任何尚未分配给 JVM 堆的 RAM。 和 Kafka 一样,Elasticsearch 被设计为依靠操作系统的文件系统缓存来快速可靠地处理请求。如果某个 segment 最近由 Elasticsearch 写入磁盘,那么它已经在缓存中。 但是,如果一个节点已被关闭并重启,则在第一次查询一个 segment 的时候,必须先从磁盘读取数据。所以这是确保群集保持稳定并且节点不会崩溃的重要原因之一。通常,监视节点上的内存使用情况非常重要,并尽可能为 Elasticsearch 提供更多的 RAM,以便在不溢出的情况下最大化利用文件系统缓存。
6.资源饱和度和错误
Elasticsearch 节点使用线程池来管理线程对内存和 CPU 使用。由于线程池是根据处理器的核数自动配置的,因此调整它们通常是没有意义的。 但是通过请求队列和请求被拒绝的情况,来确定你的节点是否够用是一个不错的主意。如果出现了状况,您可能需要添加更多的节点来处理所有的并发请求。
线程池的请求队列(queues)和拒绝情况(rejections): 每个 Elasticsearch 节点都维护着很多类型的线程池。具体应该监控哪些线程池,需要根据 Elasticsearch 的使用场景而定。一般来讲,最重要的几个线程池是搜索(search),索引(index),合并(merger)和批处理(bulk)。每个线程池队列的大小代表着当前节点有多少请求正在等待服务。 队列的作用是允许节点追踪并最终处理这些请求,而不是直接丢弃它们。但是线程池队列不是无限扩展的(队列越大占用的内存越多),一旦线程池达到最大队列大小(不同类型的线程池的默认值不一样),后面的请求都会被线程池拒绝。
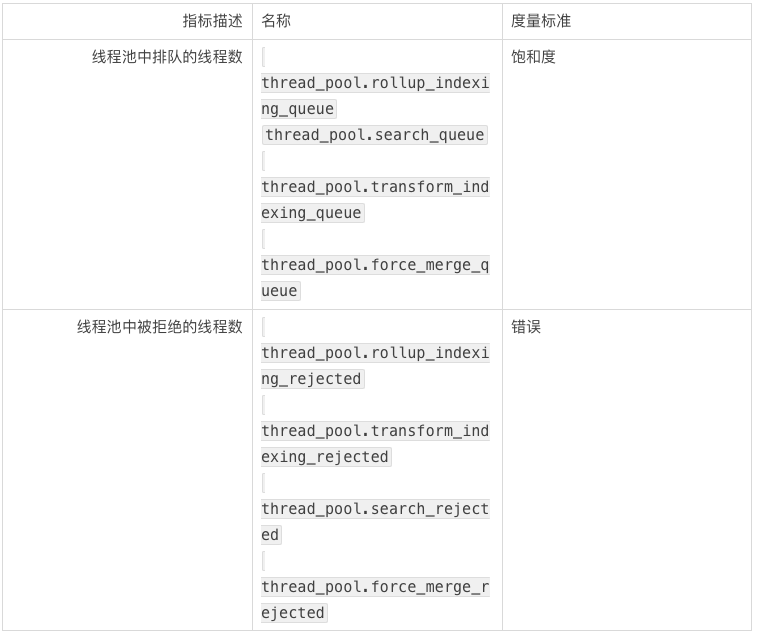
资源饱和度和错误的要点:
线程池队列: 线程池队列并不是越大越好,因为线程池越大占用的资源越多,并且增大了节点宕机时请求丢失的风险。 如果您看到排队和拒绝的线程数量持续增加,则需要尝试减慢请求速率、增加节点上的处理器数量或增加集群中的节点数量。
批处理(bulk)的请求队列和请求拒绝: 批处理是同时发送多个请求的更有效方式。 通常如果要执行许多操作(创建索引,或者添加,更新或删除文档),则应尝试将请求作为批处理发送,而不是多个单独的请求。批处理请求被拒绝通常与试图在一个批处理请求中索引太多文档有关。虽然据 Elasticsearch 的文档所说,出现批处理请求被拒绝的情况,不一定是必须要担心的事情,但是应该尝试实施一些退避策略,以有效处理这种情况。
缓存使用率指标: 每个查询请求都发送到索引中的每个分片,然后命中每个分片的每个段。Elasticsearch 逐段缓存查询,以加快响应时间。另一方面,如果您的缓存占用了太多的堆,它们可能会降低速度而不是加快速度!

守护每一个系统,成就每一个客户 2021.02.08 加入
一站式数据监测云平台









评论