




强化学习比你想象的还要更为低效...


编者按: 为什么在强化学习(RL)中,模型往往需要消耗比有监督学习多出数个数量级的计算资源,却只能换来看似微薄的性能提升,且常常陷入训练不稳定的泥潭?

大模型网关:大模型时代的智能交通枢纽|得物技术

在人工智能技术快速演进的时代,大型语言模型和AI智能体已成为各类应用的核心组件,引发AI相关API流量的指数级增长。而大模型网关,正是这场变革中应运而生的智能交通枢纽。
百度沧海·存储 Mantle 系统架构演进之路,SOSP'25 论文背后的故事

在技术深水区,最大的障碍往往不是未知,而是那些我们深信不疑的已知。

从“人治”到“机治”:得物离线数仓发布流水线质量门禁实践
随着企业数字化转型加速推进,大数据业务规模呈现指数级增长,迭代变更越发频繁。此背景下,呈现"高频变更"与"超大规模"并存的特征,这种双重特性给大数据任务的发布变更带来了严峻挑战。
深度探秘 Apache DolphinScheduler 数据库模式

本文将深入介绍 Apache DolphinScheduler 所采用的数据库模式,此模式主要用于持久化存储工作流定义、执行状态、调度信息以及系统元数据。

微调后的 Qwen3-4B 在多项基准测试上战平或胜过 GPT-OSS-120B
编者按: 如果你正在为边缘计算、本地部署或资源受限场景寻找高效的语言模型解决方案,你是否曾困惑:在众多小型语言模型(SLM)中,哪一个才是微调的最佳起点?是否真的存在“小而强”的模型,能在微调后媲美甚至超越规模大数十倍的教师模型?

一次内存诊断,让资源利用率提升 40%:揭秘隐式内存治理
云监控2.0全新打造底层操作系统诊断能力,可实现对主机、容器运行时及应用进程的全栈内存状态一键扫描与统一分析。该方案无需侵入业务,即可快速识别异常模式,显著提升问题发现与根因定位效率。


Galaxy 比数平台功能介绍及实现原理|得物技术
得物经过10年发展,计算任务已超10万+,数据已经超200+PB,为了降低成本,计算引擎和存储资源需要从云平台迁移到得物自建平台,计算引擎从云平台Spark迁移到自建Apache Spark集群、存储从ODPS迁移到OSS。

了解你的 AI 编码伙伴:Coding Agent 核心机制解析

在了解Coding Agent 的核心工作机制后,与AI伙伴的协作更佳顺畅。

深度应用|从 Vibe Coding 到 SDD:云智慧 Cloudwise 的 AI 编程进化实践

在这场范式迁移中,云智慧内部通过实践 SDD,将 AI 开发工程化,推出了具备企业级落地能力的具体方案——Cloudwise-sdd。 它不仅遵循社区共识,更通过 EARS 格式、.sdd/ 结构化目录等创新,将“规范先行”真正转化为可执行的工作流。


深度复盘:Qwen3-4B-Instruct-2507 微调实战——打造“快思考、强执行”的 ReAct IoT Agent

本文内容来自「百业千模・共创营」—— 百大垂类模型生态支持计划获奖作品,作者闫露为Foresee AI核心技术负责人,深耕AIoT与大模型融合领域多年,专注智能空间管理场景的技术落地与创新。本次带来基于ReAct架构的主动式IoT Agent项目,依托公司在智能空间管
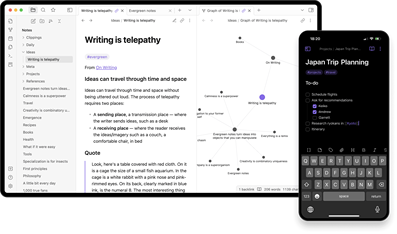
Obsidian 使用指南:从零开始搭建你的个人知识库

我并不认为 Obsidian 是一款使用门槛很高的软件。事实上,只使用 Obsidian 自带的核心功能,就已经可以非常高效地管理我们的笔记与知识。


在 Cloudflare 平台上构建垂直微前端

想象一下,你正在开发一个大型Web应用。营销团队想要用Astro构建他们的页面以获得最佳的SEO效果,而产品团队却坚持要用React来构建功能丰富的后台管理系统。更糟糕的是,每次发布新版本时,十几个团队的代码都需要一起打包、一起测试、一起上线——只要其中一

RuStore 下载量突破 20 亿次 中国开发者迎来新机遇

俄罗斯官方应用商店RuStore于2026年1月宣布,自平台上线以来,其应用和游戏下载总量已突破 20亿次,用户活跃度同比增长近30倍。这一里程碑不仅显示了平台在俄罗斯市场的快速发展,也为中国开发者进入俄罗斯及海外市场提供了前所未有的机会。

汇聚 5000+ 企业,40 万 + 采购商:2026 深圳人工智能展会

2026中国(深圳)国际人工智能展览会·高交会,将于11月26日-28日盛大启幕,汇聚全球5000+企业、40万+采购商,解锁粤港澳万亿级AI蓝海。十大展区全景呈现从算力基建到16大应用场景的完整产业链,更有政企研高端论坛解读政策红利与前沿趋势。

2026 年五大热门远程软件对比:ToDesk 凭 8K360 帧 + 高安全性 + 功能多样稳居第一

作为一个经常需要跨设备、跨地区工作的人,我决定重新亲自测试几款主流和小众的远程软件,看看哪款真正稳定、流畅、好用。






