Sentinel 如何高效精准计算
作者:Damon
程序猿 Damon | 微服务 | 容器化 | 自动化
简单回顾 Sentinel
Sentinel 以流量为切入点,提供流量控制、流量塑形、熔断降级、过载保护等维度的高可用保障策略。在架构上,被识别的流量会转换为 Sentinel Context 对象,通过使用责任链模式,在一系列的功能插槽链中完成稳定性策略验证。
详解 Hystrix 组件
Hystrix 是为了公司的服务集群不稳定而设计的,是国外视频网站 Netflix 开源的组件。
Hystrix 提供了多种实现策略,这些策略的设计主旨是监控应用程序的核心执行单元,也就是代码块的执行情况。当执行情况非符合预期时,将执行单元的调用切换为调用一个符合预期的,或是可正确处理的备选响应。
这样的设计的好处是,在故障持续的时间内,流量会被切换至降级执行单元,保证在一段时间内,不会有持续的报错进而导致故障的发生。
而且 Hystrix 还支持健康探测,也就是会定期将小流量引导至非降级的核心模块上去执行。当监测到核心模块可以健康执行后,应用服务接收到的新流量就会自动切换回去。
Hystrix 的架构设计非常清晰:
首先应用服务在引入 Hystrix 组件后,通过注解或是继承,将核心执行单元封装成 Hystrix Command 类;
然后在执行前,Hystrix 会先后检查应用服务内部“熔断”和“线程池”两个策略是否开启;
若通过策略的验证,将监视执行单元的执行过程;
并在出现异常或是验证策略失败时,执行注解或继承中降级策略。
可以看出 Hystrix 的执行原理非常清晰。正因为 Sentinel 和 Hystrix 的架构实现都非常简单,一经发布就在社区得到了非常多用户的拥趸。
那接下来,我们就对比 Hystrix,看下 Sentinel 在并发编程上使用了哪些设计,使其在流量洪峰下,依旧计算精准且性能损耗低。
在并发编程上,流量控制工具如何作为?
接下来我将以 Sentinel 为主,专注流量控制工具在并发编程上的思考。我会对 “并发请求隔离技术”和“吞吐的并发流量计算技术”进行展开;最后再以原理视角,重新审视 Sentinel 和 Hystrix 在产品形态上的异同。
下图是 Sentinel 官方对 Sentinel 和 Hystrix 的对比。
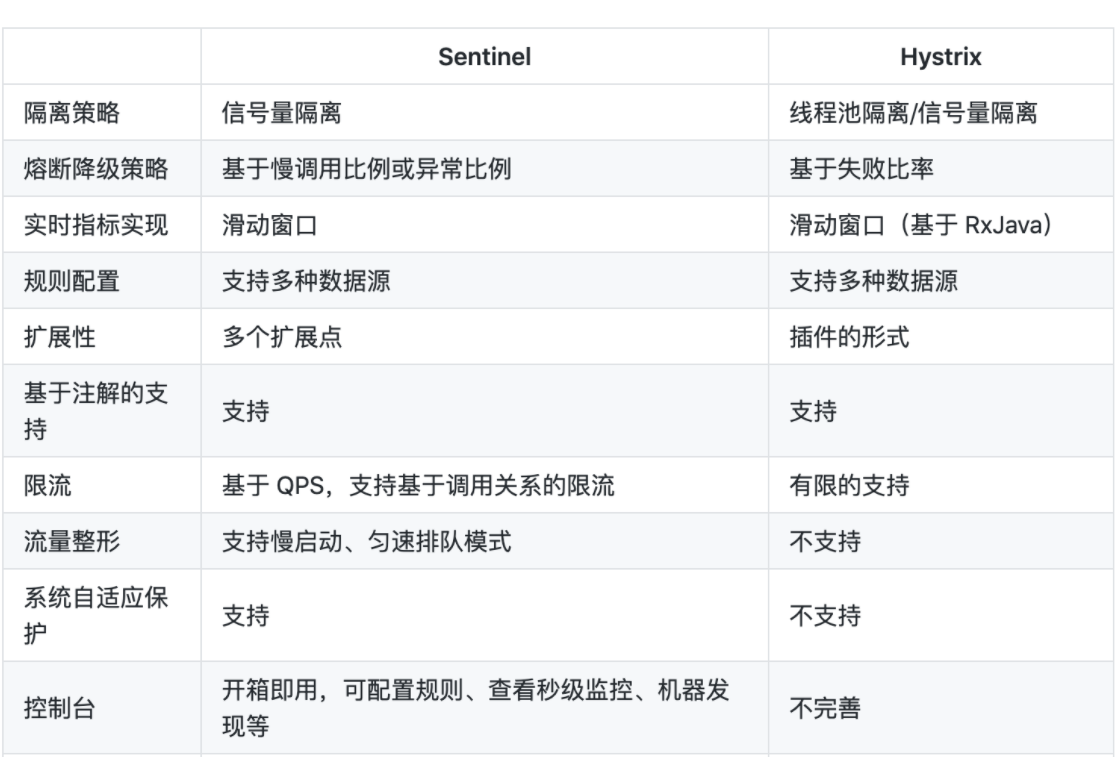
1.并发隔离
通过上面的对比表,我们可以看出:在并发流量的隔离原理上,两者都可使用了信号量隔离技术和线程池隔离技术。由此可见,这两个技术在并发流量的隔离领域非常常见。
但这两个技术对一线开发还是很陌生,所以有必要对这两个技术进行讲解。
1)信号量隔离
信号量隔离比较简单,在 Java 中对应的类名为 Semaphore。常见的 APM 工具,在处理并发时多有涉及该技术。只不过由于业务开发用不到这些技术,所以他们对此多感到陌生。
信号量技术可以理解为计数器,比如我们设计的被监视的执行单元 QPS 是 100,那对应的信号量计数器就设置为 100。
每一次调用执行单元时,就会去申请信号量,造成计数器减 1;
当退出执行单元时,计数器会加 1;
当申请信号量不足时,会无法申请到信号量,进而阻断执行单元被调用。
总的来说,请求会转化为申请信号量的操作。在信号量不足时,会拒绝申请。
2)线程池隔离
顾名思义,就是在流量到达被监视的执行单元时,为执行单元的执行单独创建线程池,进而实现隔离。
常见的策略:1.多个执行单元有对等不同的线程池。2.单一执行单元由于调用来源不同,有着不同的线程池。这样的编程结果是:当接收到并发流量时,由于策略不同,执行单元的任务线程会在不同的线程池里面执行,从而实现了以线程池为维度的并发流量隔离。
综上,这两种隔离技术的核心思想都是:识别并发流量,然后申请对应的统一资源(申请到资源即可执行),并保持申请资源之间的相互隔离;反观没有隔离技术的话,应用服务中的任意一个模块不稳定,都会造成集群的雪崩。
我们再对比一下信号量隔离和线程池隔离,更形象深入地认识一下它们。
信号量隔离,如同高并发下的精准计数器,使架构更加轻量,让引入开销最小。
线程池隔离,将被执行单元封装到指定线程池执行,让隔离更彻底。
由于线程池技术的存在,被执行单元支持在异步线程池排队。在任务线程执行超时时,可以主动断掉工作线程等场景,但这样也会使线程模型架构更加复杂。
2.并发控制
在流量洪峰下想要精准限流,就必须使用高性能的并发计算对象。而 Sentinel 底层便是通过 LongAddr 对象,解决了并发流量计算的两个难题——精确度难题和性能难题。
精准度难题
说到精准度,就要提到 CAS(Compare and Swap)原理了。Compare 表示比较,Swap 表示交换,两者通过 and 连接。其意思是:在替换一个值时,需要使用“原始值想要替换的值”一起进行并发操作;过程中伴随着“比较原始值是否发生变化”,然后“锁住变化的值进行更新”这两个操作。
性能难题
在我们的业务开发中,解决流量洪峰下的精准限流场景的方法是使用 AtomicLong 对象。AtomicLong 对象在实现 CAS 上,使用操作系统的 lock 信号,从而保证原子性。在竞争激烈的并发场景下,Atomic 原子类通过自旋锁实现值的累加,过程中会存在大量的操作失败尝试,也会带来极大的 CPU 消耗。
而 LongAddr 对象为了在性能上超越 AtomicLong 原子对象,便在内部封装了一个 Cell 元素数组。并通过并发线程的 ID 的哈希值,分散访问数组中的元素,从而进行 CAS 操作。
在使用 AtomicLong 计算并发流量的 QPS 时,所有线程都会访问同一个 CAS 变量进行 CAS 操作。
改用 LongAddr 后,再计算并发流量的 QPS 时,通过 Hash 算法将其分为“线程 1、2”和“线程 3、4”两组,从而去操作 CAS 元素数组中的不同变量。
原理易懂,但问题也明显:在并发线程同时操作数组的 CAS 元素时,统计数据会有误差。这时你可能会问:那在读取数据时,可否增加写锁来保证读取的正确性呢?答案是否定的。
因为限流降级会频繁读取对象中的数据。增加写锁的话,LongAddr 就会被降级为类似 AtomicLong 原子对象,所带来的并发优势便荡然无存了。
因此,根据场景来选型合适的并发控制对象非常必要。因为 Sentinel 仅用 LongAddr 对象进行统计,这在高并发场景下其性能损耗优先级最高,所以较小的误差是被允许的。
精彩推荐
结束福利
开源实战利用 k8s 作微服务的架构设计代码:
欢迎大家 star,多多指教。
关于作者
笔名:Damon,技术爱好者,长期从事 Java 开发、Spring Cloud 的微服务架构设计,以及结合 Docker、K8s 做微服务容器化,自动化部署等一站式项目部署、落地。目前主要从事基于 K8s 云原生架构研发的工作。Golang 语言开发,长期研究边缘计算框架 KubeEdge、调度框架 Volcano 等。公众号 程序猿Damon 发起人。个人微信 MrNull008,个人网站:Damon | Micro-Service | Containerization | DevOps,欢迎來撩。
欢迎关注:InfoQ
欢迎关注:腾讯自媒体专栏
欢迎关注

版权声明: 本文为 InfoQ 作者【Damon】的原创文章。
原文链接:【http://xie.infoq.cn/article/f42d98a0cf27b72324b4e9cf6】。文章转载请联系作者。

God bless the fighters. 2020.03.11 加入
欢迎关注公众号:程序猿Damon,长期从事Java开发,研究Springcloud的微服务架构设计。目前主要从事基于K8s云原生架构研发的工作,Golang开发,长期研究边缘计算框架KubeEdge、调度框架Volcano、容器云KubeSphere研究









评论