基于 Spring Cloud 的全自动化微信公众号消息采集系统
前言
由于公司业务需求,需要获取客户提供的微信公众号的历史文章并每天进行更新,三百多个公众号显然不能通过人工去每天查看,问题提交到了 IT 组。对于热爱爬虫的我肯定要盘他,之前做过搜狗的微信爬虫,后来一直致力于 java web 了,这个项目又重新燃起了我对爬虫的热爱,第一次使用 spring cloud 架构来做爬虫,历时二十多天,终于搞定。接下来,我将通过一系列文章来分享此次项目经历,并奉上源码供大家指正!
一、系统简介
本系统是基于 Java 开发,可通过简单配置公众号名称或微信号,实现定时或即时抓取微信公众号的文章(包括阅读量、点赞、在看)。
二、系统架构
技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、RocketMq、nginx
存储
Mysql、MongoDB、Redis、Solr
缓存
Redis
代理
Fiddler
三、系统优劣性
系统优点
1、配置完公众号后可通过 Fiddler 的 JS 注入功能和 Websocket 实现全自动抓取; 2、系统为分布式架构,具有高可用性; 3、RocketMq 消息队列进行解耦,可解决网络抖动导致采集失败情况,若消费三次还未成功则将日志记录到 mysql,确保文章的完整性; 4、可加入任意多个微信号提高采集效率和抵抗反爬限制; 5、Redis 缓存了每个微信号 24 小时内采集记录,防止封号; 6、Nacos 作为配置中心,可通过热配置实时调整采集频率; 7、将采集到的数据存储到 Solr 集群,提高检索速度; 8、将抓包返回的记录存储到 MongoDB 存档便于查看错误日志。
系统缺点:
1、通过真机真号采集消息,如果需要采集大量公众号的话需要有多个微信号作为支撑(若账号当日到了限制,可通过爬取微信公众平台接口获取消息); 2、不是公众号一发文就能马上抓取到,采集时间是系统设定的,消息有一定的滞后(如果公众号不多微信号数量充足可通过提高采集频率优化)。
四、模块简介
由于之后要加入管理系统和 API 调用功能,提前对一些功能进行了封装。
common-ws-starter
公共模块:存放工具类和实体类等公共消息。
redis-ws-starter
Redis 模块:对 spring-boot-starter-data-redis 的二次封装,对外暴露封装的 Redis 工具类和 Redisson 工具类。
rocketmq-ws-starter
RocketMq 模块:对 rocketmq-spring-boot-starter 的二次封装,提供消费重试和记录失败日志功能。
db-ws-starter
mysql 数据源模块:对 mysql 数据源进行封装,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-spider
mysql 数据库模块:提供了所有对 mysql 数据库操作的功能。
pc-wx-spider
PC 端采集模块:包含 PC 端采集公众号历史消息相关功能。
java-wx-spider
Java 提取模块:包含 java 程序提取文章内容相关功能。
mobile-wx-spider
模拟器采集模块:包含通过模拟器或手机端采集消息的互动量相关功能。
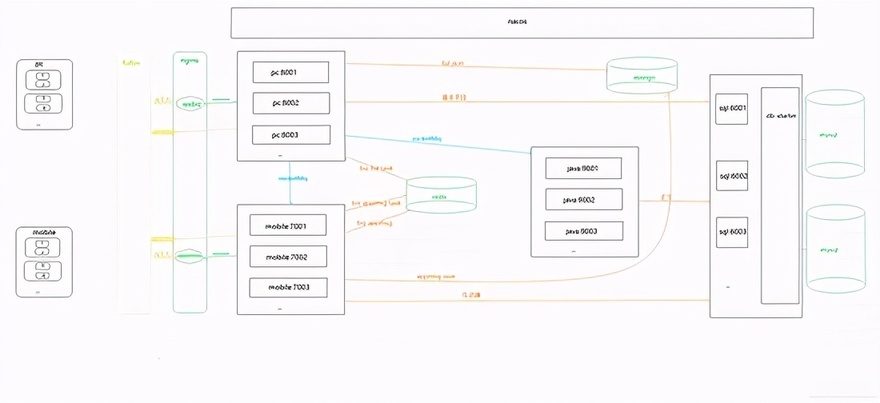
五、大体流程图
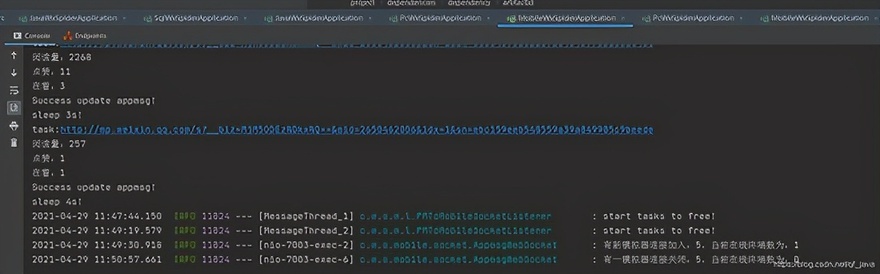
六、运行截图
PC 和移动端

控制台
运行结束
总结
项目亲测可用现在已经在运行中,并且在项目开发中解决了微信的搜狗临时链接转永久链接问题,希望能对被相似业务困扰的老铁有所帮助。如今做 java 如逆水行舟,不进则退,不知什么时候就被卷了进去,祝愿每个人都有一本自己的葵花宝典,看到这还不给个收藏吗。
原文链接:https://juejin.cn/post/6956499860996489230
如果觉得本文对你有帮助,可以转发关注支持一下
版权声明: 本文为 InfoQ 作者【Java王路飞】的原创文章。
原文链接:【http://xie.infoq.cn/article/a125386b941c097ea86844c37】。未经作者许可,禁止转载。

需要资料添加小助理vx:17375779923 即可 2021.01.29 加入
Java领域;架构知识;面试心得;互联网行业最新资讯









评论