从字节跳动到火山引擎(二):私有云 PaaS 场景下的 Kubernetes 集群部署实践

人们常说:没有最好的架构,只有最合适的架构。对于 Kubernetes 集群部署来说也是如此。在本文中,火山引擎云原生研发工程师王敏杰将给大家介绍一种 Kubernetes 集群部署的大致思路,希望可以给大家带来一些参考。
Kubernetes 集群简介
Kubernetes 集群组件
Kubernetes 集群的一些关键组件包括:API Server、Controller Manager、Scheduler、Kubelet、Kube-Proxy、Kubectl。
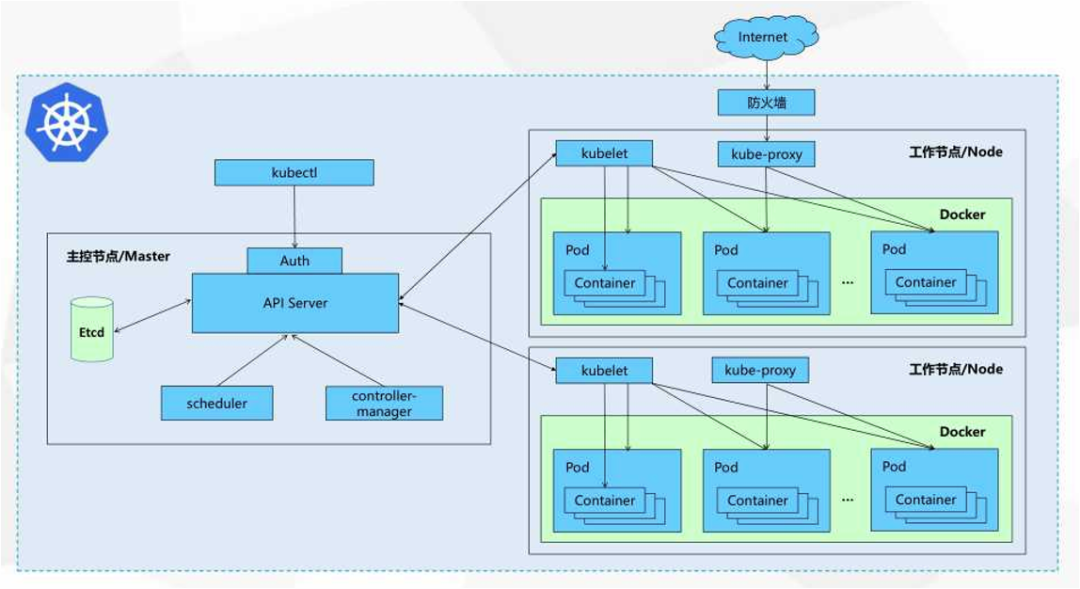
图 1:Kubernetes 集群组件示意图
参考上图左半部分,这里有一个 Kubectl。以常规的 Deployment 创建过程来讲:
Kubectl 以 Deployment 的 YAML 文件或命令行操作创建一个 Deployment。
Kubectl 会把请求发给 API Server。API Server 接收到请求之后,经过一定的验证(验证信息是从 Kubectl 的 kubeconfig 里面提交上来的)会把这些信息会存入 etcd。
etcd 存储完 Deployment 的信息之后,Controller Manager 里的 Deployment Controller 会 get 到这个信息,并创建对应的 ReplicaSet。
Controller Manager 中的 ReplicaSet Controller watch 到这个信息之后,会创建对应的 Pod 资源。
Scheduler 会对每个集群的节点进行打分操作以选择最合适的节点,并把这个节点的信息绑定到 Pod 资源上。
这时候 node 节点上运行的 Kubelet 通过请求 API Server 会得到创建对应 Pod 的任务,Kubelet 会把 Pod 启动需要的 volume 等依赖提前挂载起来。
之后 Docker 或 Containerd 等 runtime 会去拉起对应的容器,这个流程相当于把一个 Deployment 真正创建起来了。
Kube-Proxy 这个组件主要负责当前节点上的网络路由等配置,有两种部署模式:
iptables 模式:使用 iptables 分发的路由规则
IPVS 模式:使用内核的 IPVS 路由功能
两种模式从功能上对 Kubernetes 集群来说是大同小异的,当然我们更推荐使用 IPVS 的模式。
我们从图中可以看到左边 Master 节点只有一个单节点。这时不管集群是运行在虚拟机还是在物理机上,都会面临服务器宕机的风险。为了避免这种风险,我们可以使用下图的拓扑结构。
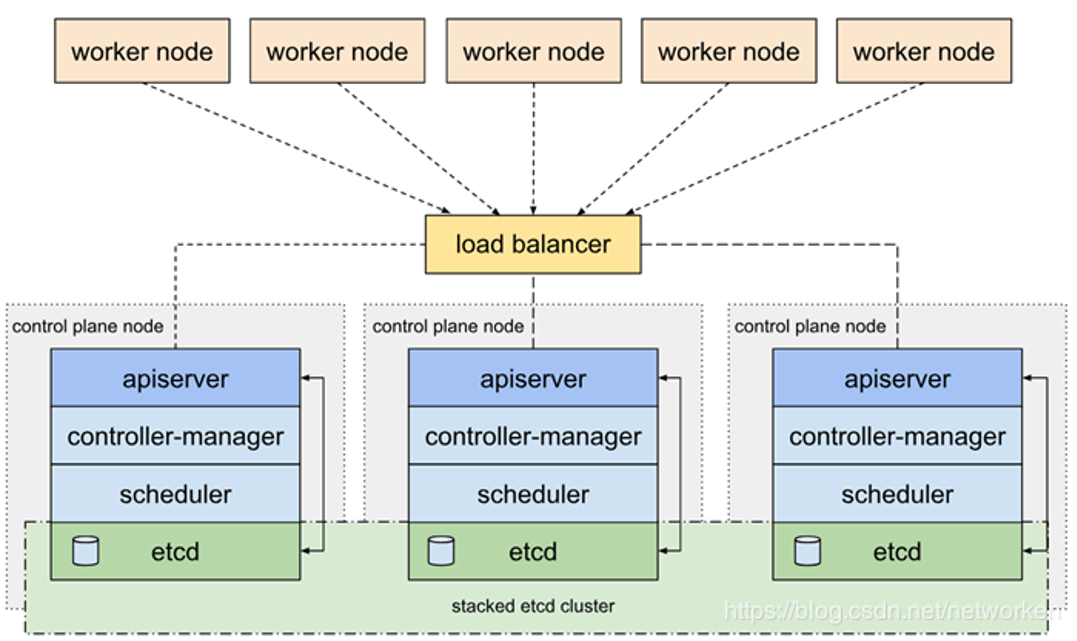
图 2:Kubernetes 集群 load balancer 拓扑
这张图我们从下往上看。
最下面是用三个节点的形式来运行一个集群的 Master 节点,作为一个集群的控制面。我们会在每个 Master 节点上启动 etcd 服务, etcd 通过相互绑定,实现独立的 etcd 集群。在每个 Master 节点上会运行 API Server、Controller Manager、Scheduler 等组件,它们不会像 etcd 自己组成一个集群,可以看作是各自独立运行
在 API Server 之上有一个 load balancer,它是把多个 API Server 节点进行串联的关键组件。load balancer 的功能类似于 Nginx,会把 worker node 发送的请求代理到各个 API Server 上,把流量/请求全部分发过去,这样就可以实现 API Server 的 HA 功能
这个架构中 load balancer 也存在单点的问题。对此有很多常规的处理方式,比如使用 keepalive 创建 VIP。我们采用的是分布式 LB 集群部署方式。
分布式 LB 集群部署
下图是部署架构方案:
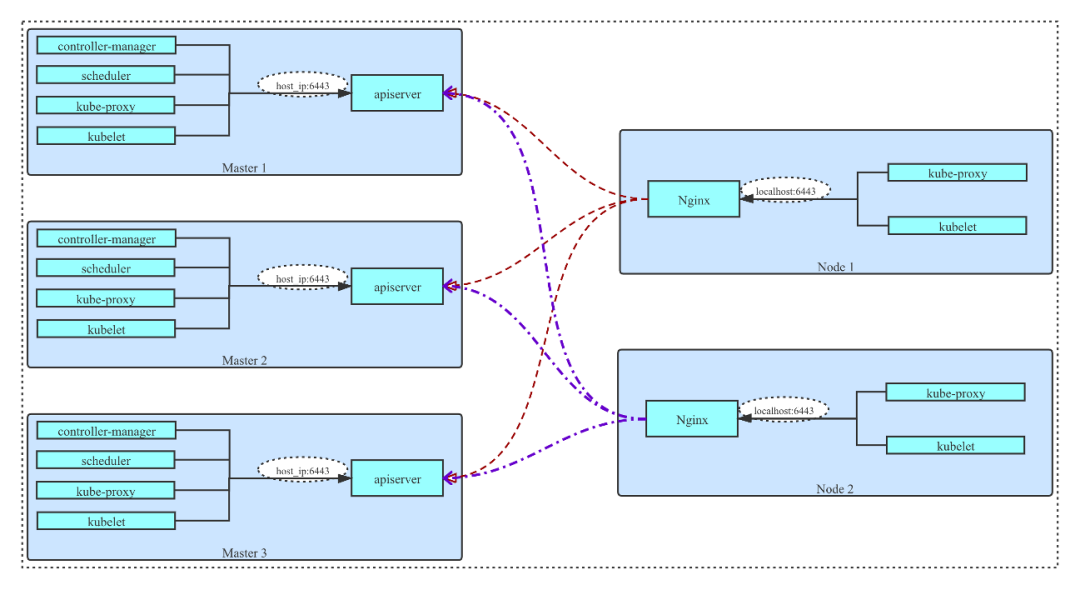
图 3:Kubernetes 集群分布式 LB 集群拓扑
左边有 3 个 Master 节点,都是用 Kubelet 拉起 Static Pod。API Server、Controller Manager、Scheduler、Kube-Proxy 都是用 Static Pod 运行的。
比较关键的一点是在上图右边的 node 上。除了常规部署的 Kubelet 和 Kube-Proxy 这两个组件之外,还会以 Static Pod 的形式运行一个 Nginx 服务,用于监听本地 localhost:6443 端口。Nginx 服务使用反向代理的方式,在 upstream 中填写所有 Master 节点 IP 和 6443 端口。这时 node 上的 Kubelet 服务在请求 API Server 时,其实请求的是本地的 6443 端口。再通过 Nginx 把流量/请求转发到 Master 节点上,即实现了 Node 节点的请求。这样就可以避免上述 load balancer 单点的问题。
单 Kubernetes 集群部署
介绍完 Kubernetes 集群组件,下面一起来看看单 Kubernetes 集群部署。
因为我们是私有云 PaasS 场景,可能会面临如下问题:
没有公网
不能方便地从公网拉取二进制文件或者镜像
自己构建的镜像不希望在公网出现
这种情况下就需要在部署集群之前预先部署一些依赖:
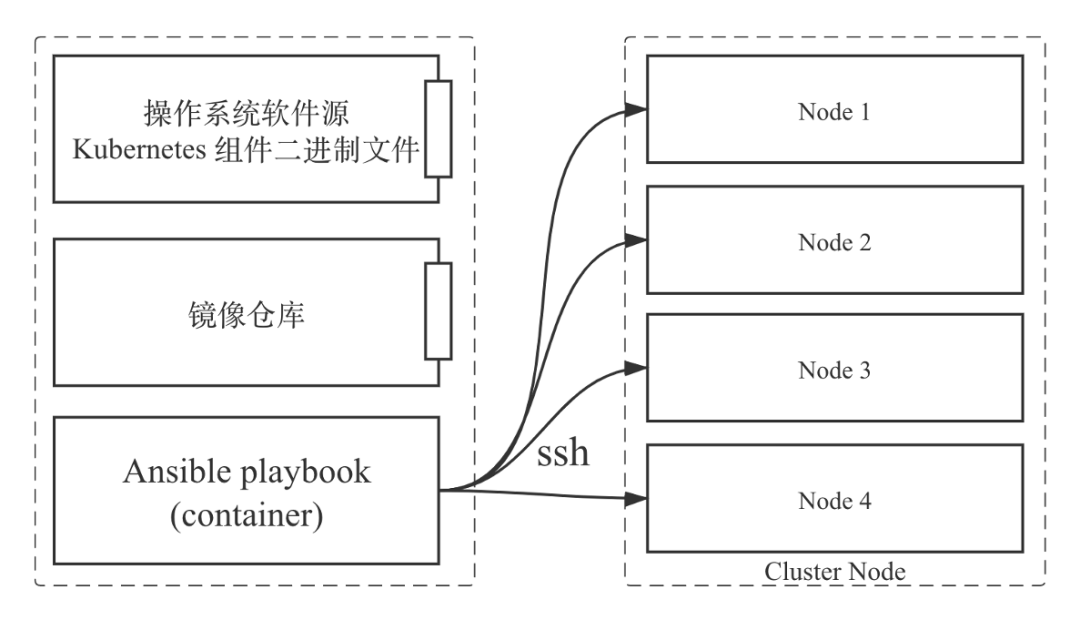
图 4:单 Kubernetes 集群部署方式示意图
首先,如上图左边所示,我们启动了一个 HTTP 服务(可以是 Nginx 或 Apache 等服务)。它的作用可以理解成是一个文件服务器,里面存放的是操作系统软件源以及 Kubernetes 集群的二进制文件(Kubelet、Kubectl 等)
其次,我们会安装一个镜像仓库。集群使用的镜像都存放在里面,后续产品或业务组件更新迭代也会把镜像推送到这边来
上面两个服务起来之后,我们会在这个节点或者服务器上启动另外一个容器——控制集群部署脚本。这个容器里的脚本是 Ansible playbook,会通过 SSH 的方式登录到集群的每个节点上进行部署操作
以上这些预置的操作都完成之后,就可以开始进行集群部署了。我们的集群部署工具是在 Kubeadm 基础上进行的部署脚本开发。在集群部署时,etcd、Kubelet、Containerd 等服务以二进制的方式运行,其他 Kubernetes 组件都以容器的方式运行。有些 Kubeadm 没有支持配置的参数,我们会在部署脚本中使用 patch 的方式修改,以满足对集群的要求。
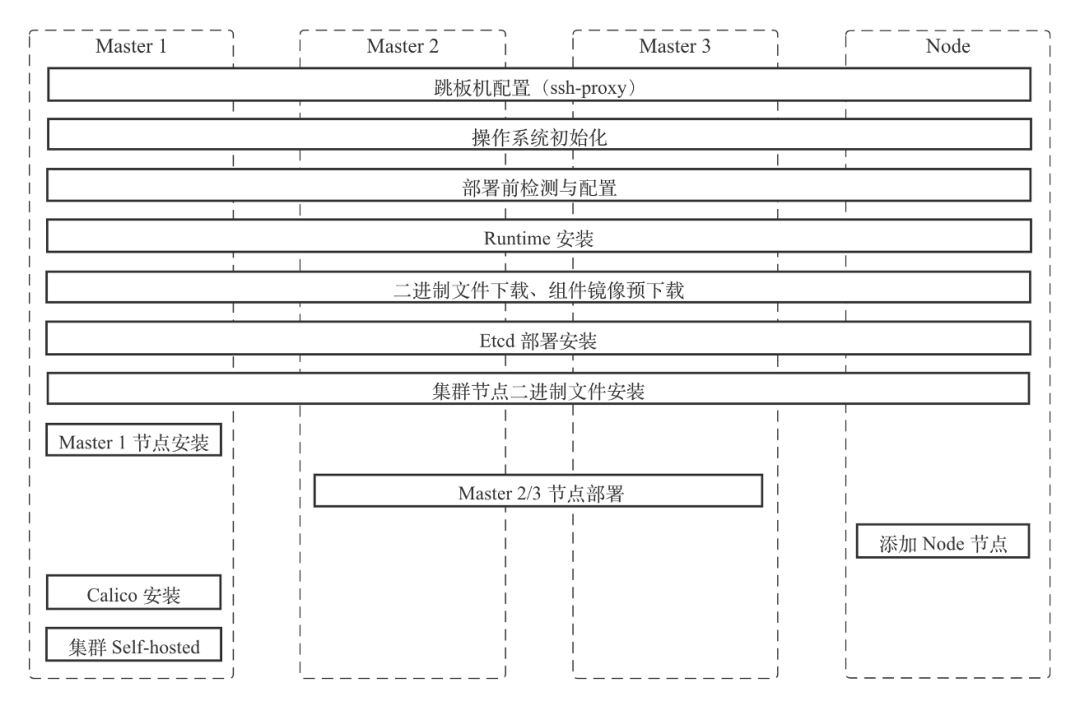
图 5:Kubernetes 集群部署步骤
图 5 展示了我们的部署步骤。从上往下看:
操作系统跳板机配置(ssh-proxy):这一块放到后面讲
操作系统初始化:修改或者更新操作系统的内核参数、依赖的安装包等
部署前检测和配置:集群部署很多时候比较耗时,为了避免部署过程中的一些风险,我们在集群部署之前会进行一些配置或环境检测。如果发现有不符合集群部署的需求就会在这里退出,在这个阶段也会额外修改一些集群对操作系统依赖的配置
Runtime 安装:我们采用的是 Containerd。如果需要使用 Docker 之类的 Runtime,可以在这个步骤中进行替换
二进制文件下载以及组件镜像预下载:为了加快后续的部署效率,我们会提前并行地在需要的节点下载一些二进制文件或组件镜像
etcd 部署安装:Kubeadm 支持 etcd 容器化运行。为了适配更多的部署场景要求,etcd 服务使用二进制方式安装
集群节点二进制文件安装:之后我们会在所有节点上安装 Kubelet,Master 节点上也会安装 Kubectl 以方便后续维护。Kubelet 安装完成之后,第一个 Master 节点会用 Kubeadm init 操作来进行安装,Master2、Master3 则会用 Kubeadm join --control-plane 的方式来进行安装,这样就能完成 Master 节点的部署。在 node 节点上我们会用 Kubeadm join 方式把集群节点加进来
节点创建完成后,都还处于 not ready 的状态,这时需要安装网络组件。我们采用的是 Calico + VXLAN 的方式。Calico 安装完之后集群的所有节点都会进入 ready 状态
集群部署完成之后,为了方便之后的维护,以及维护过程中可以了解部署时的特殊配置,我们会把集群信息全部存放到集群的 ConfigMap 中
以上就是单 Kubernetes 集群的部署方式。
多 Kubernetes 集群部署模式
前面提到过我们是私有云 PaaS 环境,这种环境有如下一些特点:
很多情况下,私有云都存在于自建机房。自建机房很可能是纯内网的环境(如果有公网肯定是最好的)
具有不断扩展的业务需求,具有可规划性:可以不断地往集群内添加机器,能够支持规模的扩大
没有大规模的突发业务流量
具有多个可以划分的业务线,或有需要隔离的业务。当有一些业务需要单独进行隔离时,如果这些业务运行在单集群中,从网络等维度上来说可能无法做到真正隔离。但是如果让不同的业务运行在不同的 Kubernetes 集群中,就可以做到完全隔离
使用多 Kubernetes 集群也会给运维带来一些挑战,主要包括多集群的配置管理、多集群的统一维护入口、多集群中应用组件的统一管理。这些都是要在集群部署方案设计时要考虑的内容。
接下来就给大家介绍我们设计的多集群部署方案。该方案有如下几个特点:
所有集群配置都会存放在控制集群中。用户集群中也会存放一些相应的配置,但是它只存放集群自身相关的配置。在控制集群中可以看到所有用户集群的具体配置
控制集群与用户集群之间在部署时仅由一台服务器连接。如果机房存在于不同的 IDC,网络打通会有一些困难;如果用户集群规模比较大时,需要开通很多访问端口权限,工作量会很大。这个设计方案是只要有一台服务器能允许我们正常登陆上去,集群就可以正常的部署
用户集群在添加删除节点的过程中不依赖于控制集群信息,在集群内部就可以完成相应的操作
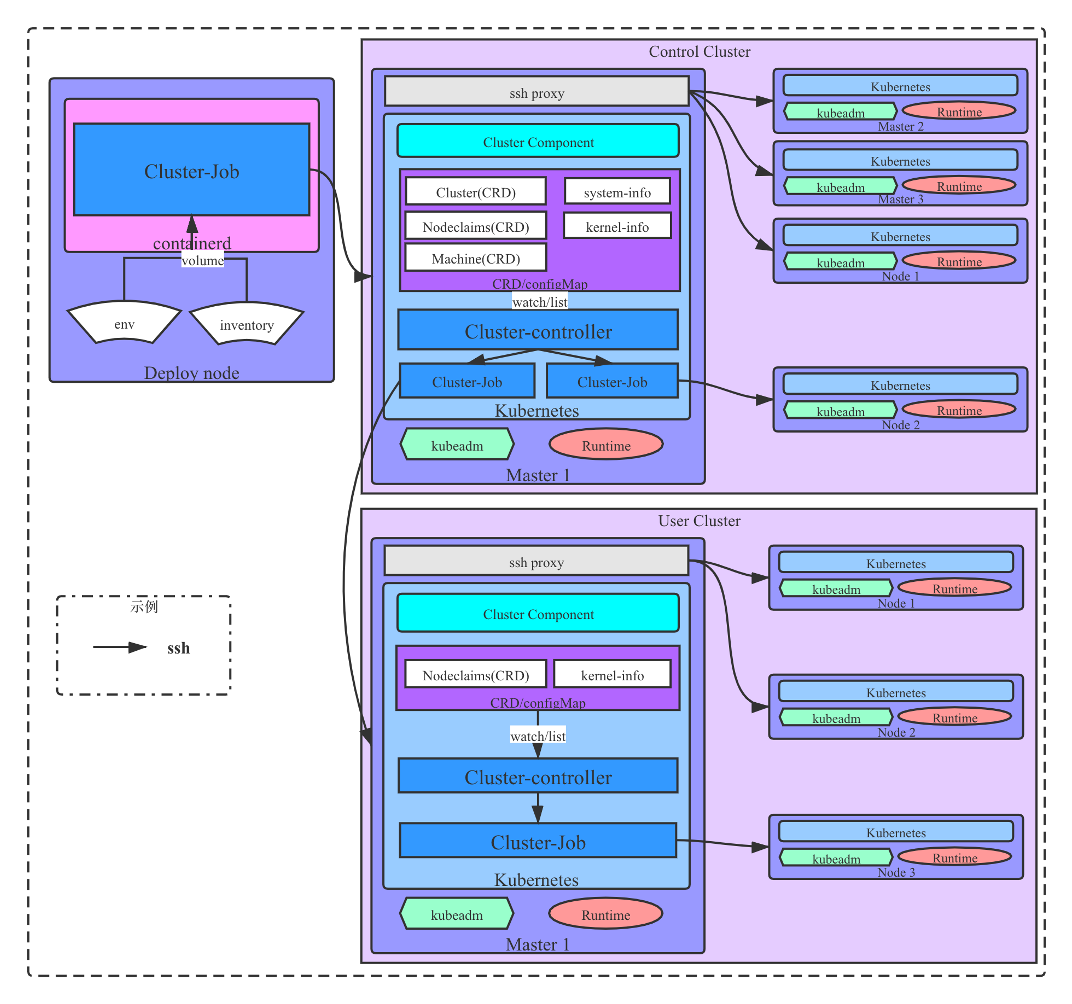
图 6:多 Kubernetes 集群部署架构
上图是我们的部署方案示意图。图中相同名称的组件是使用相同的镜像进行启动的,通过不同的启动参数来满足不同的需求。
从左上开始看。左上角有一个部署节点,它是前面提到的安装了软件源、镜像仓库服务的节点。
这个节点上我们有两个配置文件:env 和 inventory。大家如果熟悉 Ansible 可能会比较清楚, env 存放控制集群配置, inventory 存放控制集群节点。在这个节点上,我们会用 Containerd 或 Docker 等 Runtime 把容器运行起来,然后把 env 和 inventory 这两个配置文件挂载到容器中,在里面调用对应的 Ansible 脚本进行连接。脚本会连接 master1 节点,同时使用 ssh-proxy 的方式连接其余的服务器节点,这就是图 5 中的第一个阶段。在 Deploy node 上的容器中,通过修改 .ssh/ssh-config 的配置文件,实现的这种跳转方式。跳转之后,虽然在 Ansible 的部署日志中我们看到的是直接连接了集群所有节点,但实际的 SSH 连接链路是通过 Master1 节点进行跳转。当然如果使用非集群节点作为跳板机,只要能够使用 SSH 登陆也是可以的。
在 Master1 或者控制集群上,每个节点都有一个 Kubeadm 和对应的 Runtime。通过这些工具,我们会把整个集群启动起来。之后会安装 Cluster Component 和 Cluster Controller 等组件,用于支撑用户集群或当前控制集群节点添加的工作。Cluster Controller 主要负责触发当前集群的扩缩容以及用户集群创建等任务。如果需要控制集群新增一个节点,Cluster Controller 会创建一个 Cluster Job 的脚本任务。
当我们要部署用户集群的时候,也是由控制集群的 Cluster Controller 组件创建 Cluster Job 进行集群部署。
用户集群和控制集群复用了一套部署安装的逻辑。不同的地方在于:用户集群的 Cluster Controller 的作用只是进行当前集群节点的增删操作,不关心集群的其他操作。
总结展望
本次分享主要向大家介绍了 Kubernetes 集群组件、单 Kubernetes 集群部署方式以及多 kubernetes 集群的部署逻辑。如果大家有使用多 Kubernetes 集群的需求,可以考虑本文介绍的部署方式,实际的业务其实都是运行在用户集群中,控制集群控制的是整个平台的集群,这样可以带来如下收益:
一定程度降低运维人员维护集群的工作量,不会因为集群规模增加带来巨大的工作量。
不会受制于单 Kubernetes 集群的规模限制,可以支持更大的业务发展。
使用多 Kubernetes 集群模式可以很方便的对不同业务进行隔离。
最后说一下个人的一些观点:
业务组件容器化:如果后面很多业务都要上 Kubernetes,业务组件的容器化将会是必须要做的。
Kubernetes 集群部署简单化:我刚开始接触 Kubernetes 集群的时候,大多数操作都是手动的,API Server、 Controller Manager、Scheduler 等组件没有以容器方式运行,很多都是用 systemd 的形式部署,非常耗时。现在社区有很多集群部署工具,像 Kind、Minikube 对于单集群或测试集群的部署非常方便。Kubespray、Kops 等工具是成型的 HA 的 Kubernetes 集群部署方案。Kubeadm 是一个十分好用的部署工具,它把部署过程拆成了很多小的步骤,只需一条命令就可以完成一个部署操作,非常灵活方便。
Kubernetes 集群配置个性化:当不同的业务上到 Kubernetes 集群或私有云以后,会对集群有一些特殊要求。这种情况下就需要对每个 Kubernetes 集群都有一些个性化的支撑。
多 Kubernetes 集群普遍化:多 Kubernetes 集群更利于集群的使用和运维,我认为未来将更加普遍。
Q&A
Q1:如何解决混合云情况下非 K8s 集群和 K8s 集群之间的 Dubbo 依赖问题?
A:常规私有云场景下,可以采用 Calico 的 BGP 网络,这个网络可能会对机房网络有一定的要求,因为它需要依赖于一些物理的路由规则的分发。另外一种方式就是使用 IPVLAN 作为 CNI 的方案,这个方式可能会更适用于 Dubbo 环境,只是对集群的规模会有一定的限制。
Q2:Nginx Static Pod 做 LB, VIP 和公网 IP 怎么分配?
A:我们把它设计成分布式 LB 的方式,最主要的目的就是让集群自身不会依赖于一个固定 LB 的 IP。如果集群外部要对它有一个请求,可以额外创建一个 LB 的服务来进行请求。这样即使 LB 挂掉了或者要进行切换,也不会影响集群稳定性。
Q3:CNI 之间的选择主要考虑到哪些方面?
A:性能是一方面,此外实际的使用环境以及通用性也是需要考虑的。
Q4:为什么使用 VXLAN 模式而不是 BGP?
A:如果只是单纯的使用,VXLAN 和 BGP 可能不会有很大的差异。使用 BGP 更多的是为了把路由信息通过网络设备建立连接,这个过程对物理网络有一些依赖。我们为了有更好的兼容性,还是采用了 VXLAN 模式。当然实际部署过程中,我们也是支持通过修改 env 文件的配置,使用 BGP 进行部署。
版权声明: 本文为 InfoQ 作者【火山引擎】的原创文章。
原文链接:【http://xie.infoq.cn/article/fbcb4e15472a517b858a76819】。文章转载请联系作者。

还未添加个人签名 2020.07.28 加入
火山引擎是字节跳动旗下的数字服务与智能科技品牌,基于公司服务数亿用户的大数据、人工智能和基础服务等能力,为企业客户提供系统化全链路解决方案,助力企业务实地创新,实现业务持续快速的增长。









评论