基于 K8S 构建 Zeppelin 大数据可视化分析工具
背景
大多数互联网企业都提供有类似 Notebook 类的产品,采用交互式的方式进行数据分析、数据建模及数据可视化。主要实现大多都是基于 jupyter 、Zeppelin 进行定制化开发,重点会打通大数据计算、存储及底层资源管理,支持常见的机器学习和深度学习计算框架。
目前部门这块主要的产品是数据查询平台 BigQuery,主要是用于 Hive sql 数据分析查询,底层是 Tez 计算引擎跑在 yarn 集群上,缺乏交互式可编程分析工具,无法满足于机器学习、深度学习等迭代计算以及结果可视化的需求,需要补充 Notebook 交互式编程能力以及对 spark 计算引擎等的支持。Apache Zeppelin 是一款大数据分析和可视化工具类似于 jupyter notebook 交互式代码编辑器,满足这些需求,同时相较于 Juypter 其更适合于大数据企业应用。
文章主要分几个方面进行介绍,先对 Zeppelin 进行介绍,接着会讲下 Zeppelin 的生产实践,包括如何定制化去做 K8S 集群上的部署、资源的隔离、文件数据的上传和持久化。
Zeppelin 介绍
Apache Zeppelin 是一款大数据分析和可视化工具,可以让数据分析师在一个基于 Web 页面的笔记本中,使用不同的语言,对不同数据源中的数据进行交互式分析,并对分析结果进行可视化的工具。可以承担数据接入、数据分析、数据可视化、以及大数据建模的全流程,前端提供丰富的可视化图形库,后端支持 Spark、HBase、Flink 等大数据系统,并支持 Spark、Python、JDBC、Markdown、Shell 、ES 等各种常用 Interpreter,这使得开发者可以方便地使用 SQL 在 Zeppelin 中做数据开发。
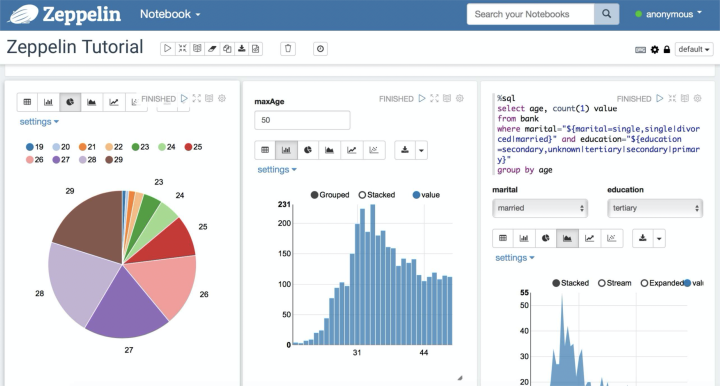
主要功能和特点
可视化交互式数据分析 ,用户通过可视化界面,交互式地输入指令、代码提交给 Zeppelin 编译执行。
Notebook 管理 用户通过 Web 页面轻松地实现 Notebook 应用的增加、修改、运行和删除,支持应用的快速导入导出。
数据可视化指令、代码提交后 Zeppelin 返回结果给用户,如果是结构化的数据,Zeppelin 提供可视化机制,通过各类图表展示数据,十分方便。
解释器配置 用户可以配置系统内置的 Spark、JDBC、Elasticsearch 等解释器,支持按组管理解释器、为一个 Notebook 应用绑定多个解释器。
运行任务管理 用户将 Notebook 应用提交给 Zeppelin 运行,也可以停止正在运行的任务。
用户认证 Zeppelin 提供完善的用户认证机制。
Notebook 应用一键分享 调试完毕的 Notebook 应用可以提供统一访问的 HTTP 地址给外部应用访问。
IntelliJ 提供的 big data tool 插件实现 Zeppelin 高效的本地数据开发和调试
一张官方支持解释器的全景图:

Zeppelin 架构
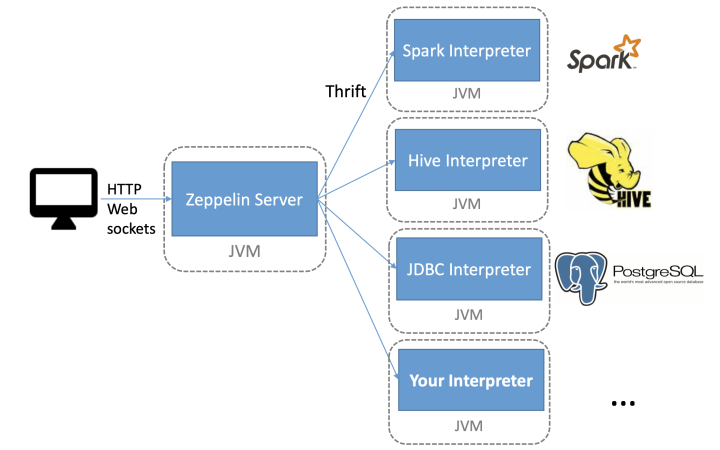
Zeppelin 架构主要分从三块:Zeppelin 前端、Zeppelin Server、Zeppelin Interpreter;Zeppelin 前端是基于 AngularJS ;Zeppelin Server 是一个基于 Jetty 的轻量级 Web Server。主要负责 Zeppelin 服务配置信息管理、Interpreter 配置信息和生命周期管理、Note 存储管理、插件机制管理以及登陆权限管理。
Zeppelin 前端和 Zeppelin Server 之间的通信机制主要有 Rest api 和 WebSocket 两种。Zeppelin Server 和 Zeppelin Interpreter 是通过 Thrift RPC 来通信,而且他们彼此之间是双向通信,Zeppelin Server 可以向 Zeppelin Interpreter 发送请求,Zeppelin Interpreter 也可以向 Zeppelin Server 发送请求。
Interpreter 组件是指各个计算引擎在 Zeppelin 这边的适配。比如 Python,Spark,Flink 等等。每个 Interpreter 都 run 在一个单独的 JVM 进程里,这个 JVM 进程可以是和 Zeppelin Server 在同一台机器上(默认方式),也可以 run 在 Zeppelin 集群里的其他任何机器上或者 K8s 集群的一个 Pod 里。
Interpreter 支持动态加载 maven 格式依赖包的能力,多 JVM 隔离 runtime 依赖。Thrift-Based 跨语言 IPC(Inter-Process-Communication)机制(规定 repl 解释器集成和平台之间的数据交换的格式和时序)。抽象出 repl 解释器生命周期管理接口,各 repl 解释器受 zeppelinServer 端控制。
关于为什么要采用单独的 JVM 进程来启动 repl 解释器,原因有以下两点:
zeppelin 旨在提供一个开放的框架,支持多种语言和产品,由于每种语言和产品都是各自独立演进的,各自的运行时依赖也各不相同,甚至是相互冲突的,如果放在同一 JVM 中,仅解决冲突,维护各个产品之间的兼容性都是一项艰巨的任务,某些产品版本甚至是完全不能兼容的。
大数据分析,是否具有横向扩展能力是生产可用的一项重要的衡量指标,如果将 repl 进程与主进程合在一起,会验证影响系统性能。
因此,在有必要的时候,zeppelin 采用独立 JVM 的方式来启动 repl 进程,并且采用 Thrift 协议定义了主进程 ZeppelinServer 与 RemoteInterpreterServer 进程(解释器进程)之间的通信协议。
Zeppelin 生产实践
Zeppelin 单机多进程方式运行,不满足可扩展性、隔离性。当前大数据存储和计算的分离以及 Zeppelin 的核心引擎解释器 Spark 跑 Kubernetes 方案的成熟因此部署到 Kubernetes 上以镜像容器的方式启动,也就是水到渠成的事情,可以解决 Zeppelin 的扩展性、安全性、隔离性问题。生产上 K8S 集群也会遇到,如何去做资源隔离以及解释器空闲如何回收,要去打通大数据存储、HIVE 数据访问,提供文件上传数据持久化等功能。
部署到 K8S 需要解决如下问题:
如何解去对接 K8S 管理 Zeppelin 生命周期?包括 Zeppelin 服务的启动、状态、Zeppelin 停止、资源回收?
如何去为每个用户生成 Zeppelin Server 解决多租房问题,并暴露统一的服务访问入口?
如何解决 Zeppelin Server 停止后,用户创建的 Note 数据能够持久化不随着服务的停止而删除?
K8S 部署
K8S 部署相比于单机上部署可以带来如下好处:

单机多进程情况下,扩展能力有限,尤其是运行需要占用资源诸如 Spark 、tensorflow 等任务,采用 K8S 多进程以多 POD 的形式能够调度到 K8S 不同的 NODE 这样扩展性大大增强。
解释器运行在容器中,避免安装依赖对系统环境进行更改,并产生依赖包冲突,同时 shell 解释器之类的存在着文件删除、非法访问等非安全性的操作,运行依赖以镜像的方式交付,进程运行在容器中,大大提高了安全性。
K8S 部署的整体架构如下图所示:
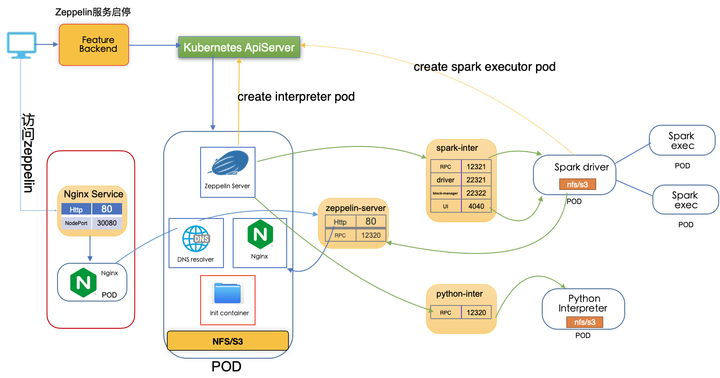
架构主要分为三部分:
Zeppelin 服务的启动,停止和状态获取,这块主要包含调用 k8s Api 去创建 Namespace、ConfigMap、Service、RBAC、PV、PVC 以及 Zeppelin Server Deployment 等 Zeppelin 启动相关的 k8s 对象,这里我们做了相关个性化开发,首先是通过调用 JAVA K8S API 去创建 Zeppelin K8S 对象,其次就是通过挂载 NFS 或 S3 解决 notebook 无法持久化存储问题、接着就是另外新增 init container 容器去实现多个用户 demo note 的拷贝操作,其中还会涉及以 configmap 和环境变量 实现相关动态参数的传递。
Zeppelin 服务的访问,这块主要设计了为每个用户创建独立的 namespace,并启动一个独立 zeppelin server 去做多租户, 每个用户暴露不同的访问 url,然后部署一个 nginx 并创建暴露 NodePort 类型 nginx Service 去代理不同用户的访问链接 ,通过 nginx 解析 url location 获取不同用户 namespace 及具体的 location 拼装成最终不同用户反向代理的 DNS 地址.
这部分改造的相对比较少,主要就是 Zeppelin 如何去启动 Interpreter 以及之间的通信。
打通计算和存储
Zeppelin 支持许多大数据计算引擎,生产支持的话需要解决依赖包安装、环境变量配置、解释器配置等工作,既然是平台化的支持,应该这些功能在 Zeppelin Server 启动后就可以直接使用,不需要用户在做许多配置这类繁琐的工作,这块的话我们在设计开发的时候,打通底层 spark 访问 HDFS、新建了 HIVE SQL 解释器,不需要用户额外配置可以直接访问生产 Hive 、HDFS 并解决了权限认证、包依赖等问题。
比如说,通过镜像内置 hdfs、hive、yarn 客户端,提供相应线上的配置文件,传递不同的用户认证信息解决依赖及访问权限问题,配置 DNS 域名解析,搞定 K8S 集群和大数据集群访问权限,最终能够让 spark hive 任务正常运行起来。
资源隔离及回收
问题背景:
用户用 zeppelin 跑 spark 任务配置多达 100 个 executor,400G 内存导致 K8S 集群中其他任务无法调度。
原因分析:
这个比较容易分析到,主要 k8s 集群 CPU、内存是有限制的,不可能无限扩容,当申请的资源过多,如果没有调度和隔离策略的话就会影响到其他任务的调度,同时的话 如果 k8s 分配出去的资源无法回收,总有一天会有资源用尽导致其他任务无法调度的情况。
解决方案:
K8S 官方提供了资源隔离方案,有基于节点选择的、任务亲和度的、以及 namespace 资源限制的,还有就是启动任务资源限制的,这块我们采取的最基本的节点标记选择,具体如下图所示:
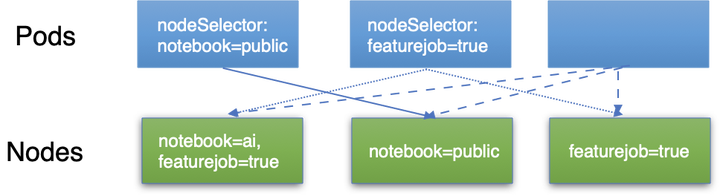
对 K8S 集群的计算节点打上不同的标记,规定了一些节点是 notebook 公用的节点,默认创建的 Zeppelin notebook 会调度到这些 公用资源组节点上去,如果有些 notebook 比较重要就会指定到另外的资源组中,这块实现比较简单,一个就是就是为要运行的任务打上需要调度到某些标记的节点,另外就是提供管理接口,提前对 k8s 中的计算节点打上标记,这样 k8s 在进行任务调度时,会去自动过滤选择符合条件的节点。
针对资源限制和回收的问题在启动时候增加的配置参数,规定了 pod 启动的资源限制以及服务空闲后多久会被回收,如下图所示:
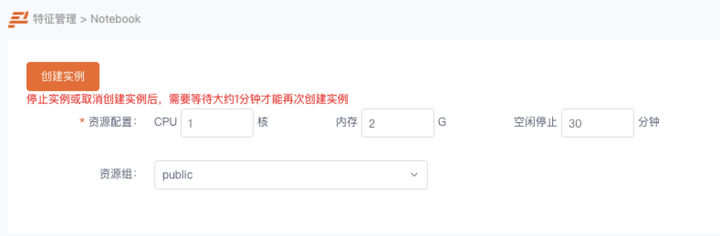
这块资源限制,主要是在调用 k8s api 创建 pod 时候 增加 request 和 limit 对 cpu 和内存进行限制。
资源回收主要是前端选择空闲停止时间,后端服务进程获取配置参数,在 Zeppelin server 与解释器交互请求的地方启动线程,不停更新交互时间,直到判断空闲超过配置时间,触发进程退出操作。
文件上传及数据持久化
问题背景:
用户创建 zeppelin notebook 重启后 notebook 消失
Zeppelin 不支持本地文件上传以及上传后的文件如何共享到不同解释器的 Pod 中。
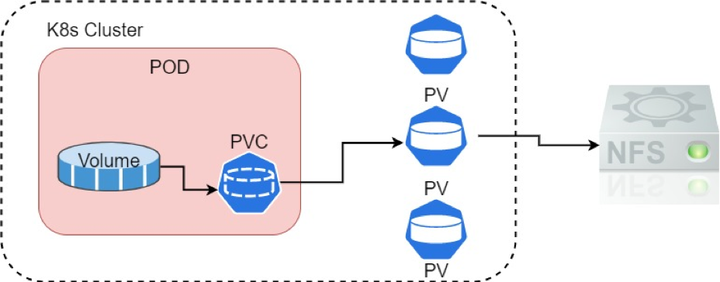
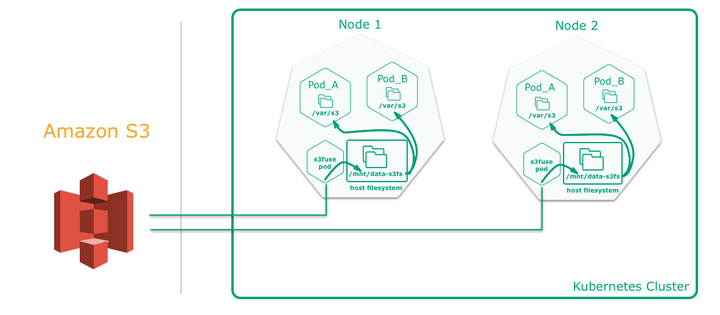
解决方案:
这里的问题比较明显,主要是容器中所进行的文件修改并不会持久化,容器停止重新启动后又是一个新的环境,在其中创建的 notebook、安装的依赖包都会随着下次启动而消失,为了能够持久的保存用户数据,就需要去挂载网络存储或者对象存储,这块的话就比较常规了为每个启动的 Zeppelin Server 挂载一个 NFS 网络存储,同时通过 subpath 参数为每个用户创建不同的子目录解决用户数据隔离的问题。不同用户挂载到容器中就是同一个网络存储不同的子目录。同时也提供了 S3 网络存储挂载方式,具体可以查看参考资料。
另外一种情况是,用户在做数据探索和数据分析,所访问的数据要么是从网络中下载的数据,要么就是 HDFS 中的文件,要么就是具体的解释器自身的访问数据方式,相对于 jupyter notebook ,zeppelin 本身就没有提供文件上传的操作,这块我们进行了定制化提供文件上传操作,只不过这个文件上传操作稍微有点特殊,还记得之前提到 zeppelin 运行到 k8s 中的架构 interpreter 是运行在不同机器节点的 pod 中,上传到 zeppelin server 中的数据要在其他解释器中能够使用,这就需要 zeppelin 和其他 interpreter pod 也需要挂载对应的网络存储,这块我们在创建 interpreter pod 时就会同样增加网络存储的挂载操作。
总结和展望
Zeppelin notebook 可以满足数据开发、数据分析及产品运营报表分析以及大数据交互式建模,通过部署到 K8S 集群中可以解决其扩展性、安全性、多租户等问题。并在生产实践中进行了一些定制化功能,同时积极拥抱开源社区,对 Zeppelin 中的代码存在通用的问题进行了修复并提交了社区如:ZEPPELIN-5379及ZEPPLIN-5349,另外 Zeppelin on k8s 的未来还有许多事情需要去解决,比如 Flink on Zeppelin 如何跑在 K8S 之中,web shell、Spark web ui 跑在 K8S 遇到的访问链接如何打开,zeppelin 定时调度以及其他解释器如何运行在 Zeppelin K8S 环境中等功能,在之后的迭代开发中会继续紧跟社区完善相关功能。
参考资料
版权声明: 本文为 InfoQ 作者【张浩_house】的原创文章。
原文链接:【http://xie.infoq.cn/article/fadae78720f4e91ca75378e8d】。文章转载请联系作者。

还未添加个人签名 2017.11.22 加入
还未添加个人简介









评论