阿里三面居然被问到 HTML?? 我:那就不好意思了...

阿里二面被问到 HTML? 我:那就不好意思了
直接干货搞起!
一. 认识 WEB
网页主要由文字、图像和超链接等元素构成。当然,除了这些元素,网页中还可以包含音频、视频以及 Flash 等
浏览器的分类和内核
五大常见浏览器介绍:
IE (edge)(Trident) 👉 (blink)
火狐(firefox)(Gecko)
谷歌(chrome)(blink)
苹果(safari)(webkit)
欧朋(Opera)(blink 早期:presto )

浏览器的内核相当于汽车的发动机,是最核心的存在,它负责将代码转换成用户眼中的界面
图解 web 标准

添加入了
JS

二.什么是 HTML
HTML 是 Hyper Text Markup Language(超文本标记语言)的简写,是一种标记语言,而不是一种编程语言,是网页制作所必备的。超文本,本质也是文本。
自 HTML3.2 之后,由 W3C 推荐标准,定义了多种类型的元素(div,p...)和众多类型的属性值(id,name...)。
HTML 文档基本结构
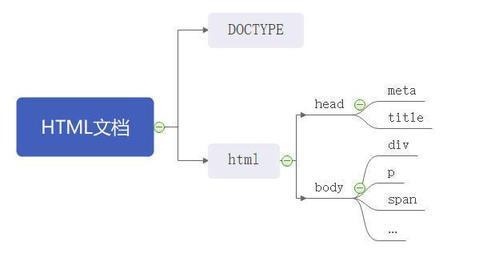
HTML 文档基本结构示例
文件类型描述(DOCTYPE)
为了说明文档使用的超文本标记语言标准,所有超文本标记语言文档应该以“文件类型声明”(外语全称加缩写)开头,引用一个文件类型描述或者必要情况下自定义一个文件类型描述。举例来说: html5:
html4:
根标签(html)
html 文档的最高节点标签。
元数据(meta)
元数据(Metadata)是数据的数据信息。
标签提供了 HTML 文档的元数据。元数据不会显示在客户端,但是会被浏览器解析。
META 元素通常用于指定网页的描述,关键词,文件的最后修改时间,作者及其他元数据。
元数据可以被使用浏览器(如何显示内容或重新加载页面),搜索引擎(关键词),或其他 Web 服务调用。
网页标题(title)
title 是网页的标题元素包含在 head 中例如:<title>百度一下你就知道</title>在网页上方的标签中显示:百度一下你就知道,相当于一个关键字搜索引擎可以通过关键字查找到此页面。
主题部分(body)
body 元素是网页的主体部分,网页的内容都写在里面,包括文本,图像,表单,音频,视频等其他内容。
我们编写网页的头部在 head 里编写,主体是在 body 内编写。在 head 里面可编写的内容大多是固定的,而在主体中的标签却是繁多且灵活组合使用的。
带 5 标识的,是 HTML5 新增的标签:

三.标签的分类
如此多的标签,看得眼花缭乱,可以适当的将它们分分类。例如单标签/双标签,块级元素/内联元素,或者根据功能分类。
单标签/双标签
单标签:
双标签: 除去以上的单标签都是双标签
块级元素/内联元素
块级元素定义
总是在新行上开始;
高度,行高以及外边距和内边距都可控制;
宽度缺省是它的容器的 100%,除非设定一个宽度。
它可以容纳内联元素和其他块元素
内联元素定义
和其他元素都在一行上;
高,行高及外边距和内边距不可改变;
宽度就是它的文字或图片的宽度,不可改变
内联元素只能容纳文本或者其他内联元素
块级元素有哪些
内联元素有哪些
根据块级元素/内联元素分类的话,还有一些元素根据内容才能判断元素类型,例如:
我们可以通过 css 的 display 属性对块级元素、行内元素进行转换,也可以设置行内块元素。
行内块元素
1、和其他元素都在一行上; 2、元素的高度、宽度、行高以及顶和底边距都可设置
四. HTML 基础
文档类型<!DOCTYPE>
作用: 声明位于文档中的最前面的位置,处于 <html> 标签之前。此标签可告知浏览器文档使用哪种 HTML 或 XHTML 规范。
页面语言 lang
最常见的 2 个:
en定义语言为英语zh-CN定义语言为中文
字符集
utf-8是目前最常用的字符集编码方式,常用的字符集编码方式还有gbk和gb2312。
gb2312 简单中文 包括 6763 个汉字 GUO BIAO
BIG5 繁体中文 港澳台等用
GBK 包含全部中文字符 是 GB2312 的扩展,加入对繁体字的支持,兼容 GB2312
UTF-8 则基本包含全世界所有国家需要用到的字符
这句代码非常关键, 是必须要写的,否则可能引起乱码的情况
作用: 这句话是让 html 文件是以 UTF-8 编码保存的, 浏览器根据编码去解码对应的 html 内容
标签语义化
一个需求可以用不同的标签来完成,那么这之间有什么区别呢?
一个是标签语义强,起强调作用。一个是没有语义,没有强调作用 语义好的网页更受 SEO 的喜欢,在搜索引擎里面的排名会更靠前
SEO 优化 ===> 在输入关键字的时候,搜索引擎会罗列很多很多的网页出来,而用户基本习惯都是点前面的网页,不会去点后面的网页,所以如果网页在搜索引擎中的排名更加靠前,那么自然而然会带来更多的用户点击访问。
如何优化(了解):
作用: 根据标签的语义,在合适的地方给一个最为合理的标签,让结构更清晰。
锚点定位
通过创建锚点链接,用户能够快速定位到目标内容。
创建锚点链接分为两步:
base 标签
**总结: **
base 可以设置整体链接的打开状态
base 写到 <head> </head> 之间
把所有的连接 都默认添加 target="_blank"
特殊符号
一些特殊的符号,我们再 html 里面很难或者不方便直接使用,我们此时可以使用下面的替代代码

五.面试干货知识点
html 元素布局分类有哪些?
内联元素(
display:inline):无法设定宽高,元素大小由内容大小决定,不会自动换行,从左到右排列,内部不能嵌套块级元素块级元素(
display:block):会自动换行,宽度默认父元素的宽度,高度默认内容高度内联块级元素(
display:inline-block):可以设置宽高,排列方式从左向右
html 中 b 标签和 strong 标签的区别?
b:为了加粗而加粗
strong:为了标明重点加粗 (盲人使用阅读设备 strong 会重读,b 不会)
减少 dom 数量的办法?
使用伪元素替代 dom 元素解决方案,比如清除浮动,样式实现等。
不滥用 dom 标签,结构合理。
按需加载,减少不必要的渲染。
一次性给你大量 dom 如何优化?
缓存 dom 对象,比如循环插入大量 dom 对象,将父 dom 在循环外获取,循环内插入。
使用 document.createDocumentFragement 创建文档碎片节点或者创建一个不在 dom 树上的节点,将大量 dom 一次性更新进入该节点,然后批量替换或插入 dom 中。
将连续的 appendChild 替换成使用 innerHtml,避免多次对 dom 造成影响(ps:appendChild 向父元素最后一个子节点插入元素,innerHtml 直接替换父元素下所有元素,appendChild 添加的元素如果是页面上已有的元素,执行完原元素会被销毁。)
如何禁用 a 标签默认事件且禁用后如何实现跳转?
禁用 a 标签默认事件
a 标签的 href 属性设置为
href="javascript:;"||href="javascript:void(0);",通过执行空 js 代码,阻止跳转在 a 标签点击事件上使用
e.preventDefault()与window.event.returnValue=false,后者兼容 ie,以此阻止 dom 元素默认行为实现跳转
点击事件 使用 location.href = url 进行跳转。
什么是 SEO?
搜索引擎后台有个非常庞大的数据库,数据库存储海量关键词,每个关键词对应多个网址。这些数据由蜘蛛每天在互联网中收集获取,从一个链接爬行到另一个链接,对当前网页进行提炼关键词,之后将关键词与对应网站保存在数据库中,而当我们使用搜索引擎时,搜索引擎肯定会将与搜索词与数据库中存在的关键词对比,匹配程度越高的关键词对应的网站越是优先展示在前面。而 seo(seach engine optimization)就是在此基础上,对当前网站进行优化,改进网站对应关键词在搜索引擎中的排名,获取更多的曝光程度。
前端如何进行 seo 优化?
前端进行 seo 优化无非是期望通过对网页的处理,使得爬虫对当前网站提取出的关键词更加贴切,提高网站关键词在搜索引擎中的排名。
合理控制网站首页链接数量,链接足够多蜘蛛才能爬取内页,提高网站收录数量,但也不能太多,过多无意义链接不仅影响用户体验也会降低网站首页权重
控制网站结构层次在三层以内,让蜘蛛跳转三次就能到到达网站任何一个内页,这意味着层次低越容易被蜘蛛收录,如果层次太多蜘蛛可能就不愿意继爬取
导航尽量使用文字的方式,如果是图片也必须加入 alt 与 title 属性,告诉搜索引擎导航的定位
利用布局,将重要的的 html 放在前面,便于蜘蛛的优先爬取
控制页面大小,提高页面加载速度,如果页面加载速度很慢,蜘蛛就会离开
页面的<meta keywords>keywords><meta description>尽量强调重点关键词,不要重复过分堆砌
正文标题使用 h1 标签,h1 标签自带权重,蜘蛛认为它最重要
使用 strong 标签 em 标签而不是 b 标签,因为 strong 与 em 目的就是标明重点而加粗,在搜索引擎能够得到高度重视
重要内容不要使用 js 输出,蜘蛛不会读取 js 输出,可以采用服务端渲染的办法将中药内容直接呈现在当前 html 中。
蜘蛛只抓取 get 请求页面,不抓去 post 请求页面,合理控制页面请求方式
外部链接需要加上
el = nofollow属性,告诉蜘蛛不要去爬取,因为爬取外链可能蜘蛛就不回来了。不要使用 iframe 框架,蜘蛛一般不会读取其内容
什么是 meta 标签及其常用属性?
meta 标签位于 html 的 head 区域,它描述了当前网页的各种信息,比如页面的说明,关键字,修改日企等。对于用户它是不可见的,它服务于浏览器,搜索引擎及其他网络服务。
charset:定义文档字符编码
content:定义 name 属性或者 http-equiv 属性相关元信息
name:将 content 属性关联到一个名称
http-equiv:将 content 属性关联到 http 头部
script 的 async 与 defer 区别?
浏览器在解析 html 时遇到 script 标签会停止解析,先去下载执行 js 文件,再继续解析,所以如果该标签至于 html 前面会影响 html 解析给用户带来不好体验,而 async 与 defer 就是处理这个事情。
defer:defer 加载完成时会等到 dom 解析完毕执行 (当 dom 加载完会执行 DOMContentLoaded 事件,defer 标签未加载或未执行完,将推迟该事件执行,直到 defer 标签加载执行完才会触发该事件 ),这就相当于将 script 标签放在 html 文档底部,且 defer 按原本 script 标签出现顺序执行
async:async 加载完毕立即执行,所以 js 执行顺序与标签出现顺训很有可能不一样(js 创建的脚本默认都是以 async 加载的)
ps:二者都是使得 script 标签异步加载,加载时不阻塞 dom 解析且对内联 js 脚本不起作用(
<script>var a = 1</script>)脚本内不可是用 document.write 二者都会阻塞 onload 事件(onload 意味着所有依赖资源加载完成执行)defer 阻塞 DOMContentLoaded 事件,async 不阻塞(DOMContentLoaded:当 dom 资源下载解析完执行该事件,此时 css 图片等资源可能未加载完成)defer 与 async 同时出现,async 优先级更高,除非浏览器不兼容 async,则以 defer 为准。
preload,prefetch,dns-prefetch?
preload:顾名思义预加载资源
<link rel='preload' as='script' src = 'main.js' onload="_load()"/>,提升了你所需要资源加载优先级,提前加载你所需要的资源,该方式不会阻塞 DOMContentLoaded 与 onload 事件,但是该方式不管你是否是用都会预先加载资源,使用该资源需要手动指定,一般我们使用 preload 方案为先头部预加载资源,在 window.onload 事件中去使用,在预加载字体时需要设置 crossorigin,使用匿名跨域模式,否则字体文件会被加载两次(当你期望不影响当前页面性能去加载某个脚本资源时 preload+window.onload 是最优方案)prefetch:顾名思义预先获取资源,
<link rel="prefetch" href="main.jpg">使用该方式可以利用浏览器空闲时间去获取将来可能用的上的资源缓存起来,当我们用到该资源可以直接从缓存获取,不需要发送请求。他将下载优先级降到最低。(可以这么说,prefetch 专注于未来的资源,preload 专注于当前资源)dns-prefetch:顾名思义预先进行 dns 解析,dns 解析需要耗时,所以我们当前页面如果可能跳转到别的网站可以使用 dns-prefetch
<link ref="dns-prefetch" href="xxx.com."/>,这将在浏览器空闲时解析该网站的 dns,当我们前往该网站时就不需要在进行 dns 解析。preconnect:顾名思义预先链接,dns-prefetch 是提前 dns 解析,而 preconnect 则是提前完成与某个网站的连接,包括 dns 解析,tls 协商,tcp 握手,与 dns-prefetch 进行优化区别是一般我们知道用户可能一定会使用的某个链接可以使用 preconnect,其他不确定的可以 dns-prefetch,否则全部进行 preconnect,不管用不用得到反而得不偿失。
什么是 Html 语义化及语义化的优点?
h5 出现后,新增了很多语义化标签,比如 header,footer,nav,article 等,能够清楚的向浏览器或者开发者解释当前内容的意义。
便于开发者阅读代码,清晰代码结构
利于 Seo 蜘蛛爬取数据时对数据的理解
最后,祝大家早日学有所成,拿到满意 offer,快速升职加薪,走上人生巅峰。
我是一名渗透测试工程师,为了感谢读者们,我想把我收藏的一些 CTF 夺旗赛干货贡献给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
①1000+CTF 历届题库(主流和经典的应该都有了)
②CTF 技术文档(最全中文版)
③项目源码(四五十个有趣且经典的练手项目及源码)
④ CTF 大赛、web 安全、渗透测试方面的视频(适合小白学习)
⑤ 网络安全学习路线图(告别不入流的学习)
⑥ CTF/渗透测试工具镜像文件大全
⑦ 2021 密码学/隐身术/PWN 技术手册大全
各位朋友们可以关注+评论一波 然后扫描下方 备注:开源中国 即可免费获取全部资料



还未添加个人签名 2021.03.28 加入
需要获取网络安全/渗透测试学习资料工具的朋友可联系V:machinegunjoe666 免费索取









评论