微信 ClickHouse 实时数仓的最佳实践
作者:微信 WeOLAP 团队 &腾讯云数据仓库 Clickhouse 团队
微信作为一款国民级应用,已经覆盖了社交、支付、出行等人们生活的方方面面。海量多样化的业务形态,对数据分析提出了新的挑战。为了满足业务数据分析的需求,微信 WeOLAP 团队联手腾讯云,共建千台规模、数据 PB 级、批流一体的 ClickHouse 数据仓库,实现了 10 倍以上的性能提升。下文将由浅入深,为大家揭晓微信在 ClickHouse 实时数仓实践中积累的经验及方法。
一、微信遇到的挑战
一般来说,微信主要的数据分析场景包含以下几个方面:
1.科学探索:服务于数据科学家,通过即席查询做业务上的归因推断。
2.看板:服务于运营和管理层,展示所关注的核心指标。
3.A/B 实验平台:服务于算法工程师,把新的模型,放在 A/B 实验平台上做假设检验,看模型是否符合预期。
除此以外,还有实时监控、日志系统明细查询等场景。
在所有的场景当中,使用者都有非常重要的诉求——快:希望查询响应更快,指标开发更快完成,看板更新更及时。与此同时,微信面临的是海量的数据,业务场景中“单表日增万亿”很常见,这就对下一代“数据分析系统”提出新的挑战。
在使用 ClickHouse 之前,微信使用的是 Hadoop 生态为主的数仓,存在以下这些问题:
1.响应慢,基本上是分钟级,可能到小时,导致决策过程长;
2.开发慢,由于传统的数仓理念的多层架构,使得更新一个指标的成本很高。
3.架构臃肿,在微信业务体量规模的数据下,传统架构很难做到流批一体。进而导致,代码需要写多套、数据结果难以对齐、存储冗余。经过十几年的发展之后,传统的 Hadoop 生态的架构变得非常臃肿,维护难度和成本都很大。
所以,微信一直在寻求更轻量、简单敏捷的方案来解决这些问题。经过一番调研,在百花齐放的 OLAP 产品中,最终选定了 ClickHouse 作为微信 OLAP 的主要核心引擎。主要有两个原因:
1.效率:在真实数据的实验场景下,ClickHouse 要比 Hadoop 生态快 10 倍以上(2020 年底测试);
2.开源:微信的 A/B 实验、线上特征等场景会有些个性化需求,需要对引擎内核做较多改动。
因此,微信尝试在 OLAP 场景下,构建基于 ClickHouse 计算存储为核心的“批流一体”数仓。
但是,使用原生的 ClickHouse,在真正放量阶段出现了很多问题:
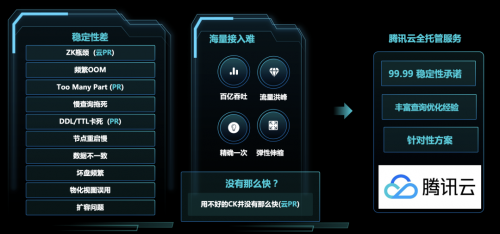
1.稳定性:ClickHouse 的原始稳定性并不好,比如说:在高频写入的场景下经常会出现 too many part 等问题,整个集群被一个慢查询拖死,节点 OOM、DDL 请求卡死都比较常见。另外,由于 ClickHouse 原始设计缺陷,随数据增长的依赖的 zookeeper 瓶颈一直存在,无法很好解决;微信后期进行多次内核改动,才使得它在海量数据下逐步稳定下来,部分 issue 也贡献给了社区。
2.使用门槛较高:会用 ClickHouse 的,跟不会用 ClickHouse 的,其搭建的系统业务性能可能要差 3 倍甚至 10 倍,有些场景更需要针对性对内核优化。
二、微信和腾讯云数据仓库共建
此时,腾讯云数据仓库 Clickhouse 团队积极深入业务,主动与微信团队合作,双方开始共同解决上述问题。腾讯云数据仓库 Clickhouse 提供全托管一站式的全面服务,使得微信团队不需要过多关注稳定性问题。另外,双方团队积累了丰富查询优化经验,共享经验更有利于 Clickhouse 性能极致提升。
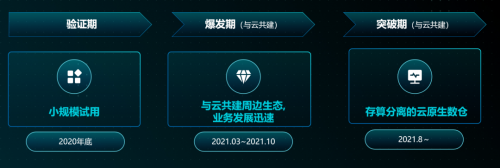
微信跟腾讯云数据仓库 Clickhouse 的合作,从今年 3 月份开始,在验证期小规模试用 ClickHouse 后,业务一直在快速增长,双方开始共建进行稳定性和性能上的优化。主要做了两件事:一个是建立了整个 ClickHouse OLAP 的生态,另外一个是做了探索出贴近业务的查询优化方法。
三、共建 ClickHouse OLAP 的生态
要想比较好地解决 ClickHouse 易用性和稳定性,需要生态支撑,整体的生态方案有以下几个重要的部分:
1.QueryServer:数据网关,负责智能缓存,大查询拦截,限流;
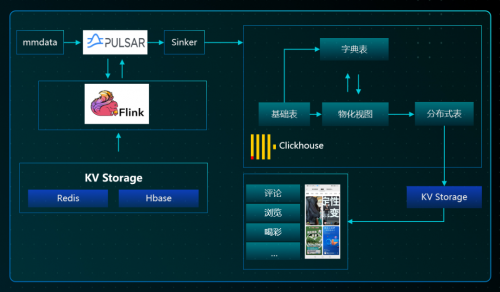
2.Sinker:离线/在线高性能接入层,负责削峰、hash 路由,流量优先级,写入控频;
3.OP-Manager:负责集群管理、数据均衡,容灾切换、数据迁移;
4. Monitor:负责监控报警,亚健康检测,查询健康度分析,可与 Manager 联动;
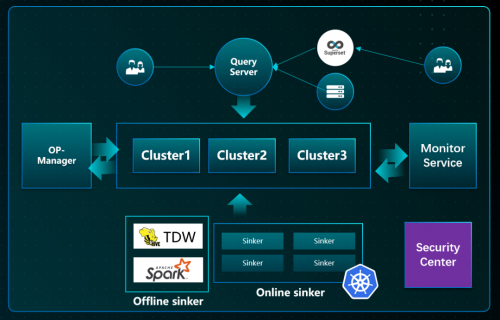
微信 WeOLAP 团队和腾讯云重点在以下方面进行了合作攻坚:
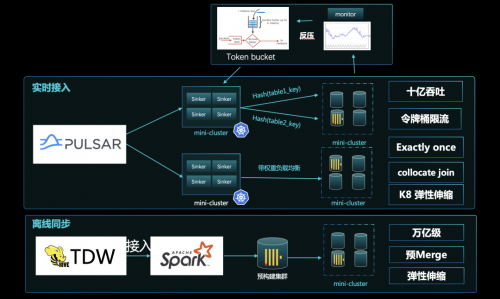
1.高性能接入:微信的吞吐达到了十亿级别,实时接入方面,通过令牌、反压的方案,比较好地解决了流量洪峰的问题。另外通过 Hash 路由接入,使数据落地了之后可直接做 Join,无需 shuffle 实现更快 Join 查询,在接入上也实现了精确一次。离线同步方案上,微信跟大多数业界的做法基本上一致,在通过预构 Merge 成建成 Part,再送到线上的服务节点,这其实是种读写分离的思想,更便于满足高一致性、高吞吐的场景要求。
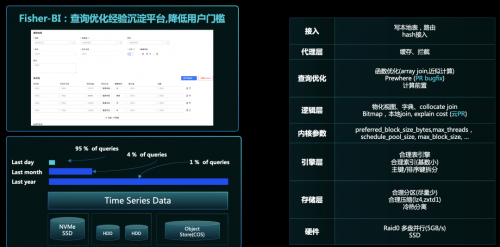
2. 极致的查询优化:ClickHouse 整个的设计哲学,要求在特定的场景下,采用特定的语法,才能得到最极致的性能。为解决 ClickHouse 使用门槛高的问题,微信把相应的优化经验落地到内部 BI 平台上,沉淀到平台后,使得小白用户都可以方便使用 ClickHouse。通过一系列优化手段,在直播、视频号等多个 Case 实现 10 倍以上性能提升。
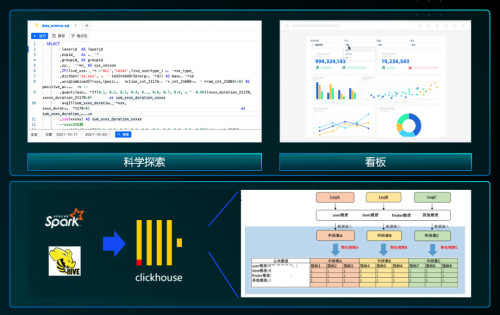
基于共建的 ClickHouse 生态,在微信有以下的典型应用场景:
1. BI 分析/看板:由于科学探索是随机的,很难通过预构建的方式来解决,之前用 Hadoop 的生态只能实现小时到分钟的级别。目前 ClickHouse 优化完之后,在单表万亿的数据量下,大多数的查询,P95 在 5 秒以内。数据科学家现在想做一个验证,非常快就可以实现。
2. A/B 实验平台:早期做 A/B 实验的时候,前一天晚上要把所有的实验统计结果,预先聚合好,第二天才能查询实验结果。在单表数据量级千亿/天、大表实时 Join 的场景下,微信前后经历了几个方案,实现了近 50 倍的性能提升。从离线到实时分析的飞跃,使得 P95 响应<3S,A/B 实验结论更加准确,实验周期更短 ,模型验证更快。
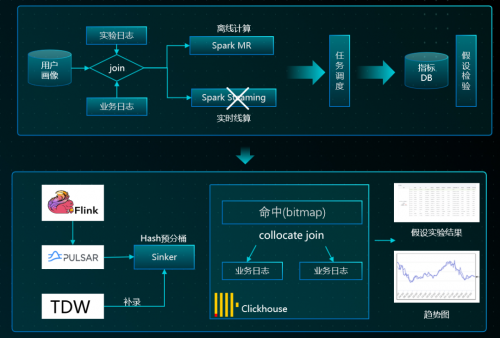
3. 实时特征计算:虽然大家普遍认为 ClickHouse 不太擅长解决实时相关的问题,但最终通过优化,可以做到扫描量数十亿,全链路时延<3 秒,P95 响应近 1 秒。
四、性能的显著提升
目前,微信当前规模千台,数据量 PB 级,每天的查询量上百万,单集群 TPS 达到了亿级,而查询耗时均值仅需秒级返回。ClickHouse OLAP 的生态相对于之前的 Hadoop 生态,性能提升了 10 倍以上,通过流批一体提供更稳定可靠的服务,使得业务决策更迅速,实验结论更准确。
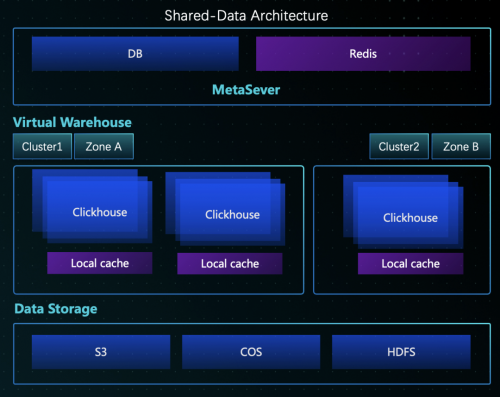
五、共建存算分离的云原生数仓
ClickHouse 原始的设计和 Shard-Nothing 的架构,无法很好地实现秒级伸缩与 Join 的场景;因此下一个微信和腾讯云数据仓库 ClickHouse 的共建目标,是实现存算分离的云原生数仓:
1.弹性扩容:秒级弹性能力,用户只为使用付费,实现高峰查询更快,低峰成本更省;
2.稳定性:无 ZK 瓶颈,读写易分离,异地容灾
3.易运维:数据容易均衡,存储无状态;
4. 功能全:专注于查询优化与 Cache 策略、支持高效多表 Join;
存算分离的云原生数仓能力,明年将会在腾讯云官网上线,敬请期待!
本文章由微信技术架构部-WeOLAP 团队出品,「WeOLAP」专注于用前沿大数据技术解决微信海量数据高性能查询问题。
腾讯云数据仓库 Clickhouse 10 元新客体验活动火爆进行中↓↓


还未添加个人签名 2021.05.31 加入
还未添加个人简介









评论