
ECCV2022 | 腾讯优图 29 篇论文入选,含人脸安全、图像分割、目标检测等多个研究方向
近日,欧洲计算机视觉国际会议 ECCV2022(European Conference on Computer Vision)发布了论文录用结果。本届 ECCV2022 论文总投稿数超过 8170 篇,其中 1629 篇论文中选,录用率不足 20%。
ECCV(European Conference on Computer Vision)是国际顶尖的计算机视觉会议之一,每两年举行一次。随着人工智能的发展,计算机视觉的研究深入和应用迅速发展,每次 ECCV 的举行都会吸引大量的论文投稿,而今年 ECCV 2022 的投稿量更是接近 ECCV 2020 的两倍,创下历史新高。今年,腾讯优图实验室共有 29 篇论文入选,内容涵盖人脸安全、图像分割、目标检测等多个研究方向,展示了腾讯在计算机视觉领域的科研及创新实力。
以下为腾讯优图实验室部分入选论文概览:
基于差分隐私框架的频域下人脸识别隐私保护算法 Privacy-Preserving Face Recognition with Learnable Privacy Budget in Frequency Domain
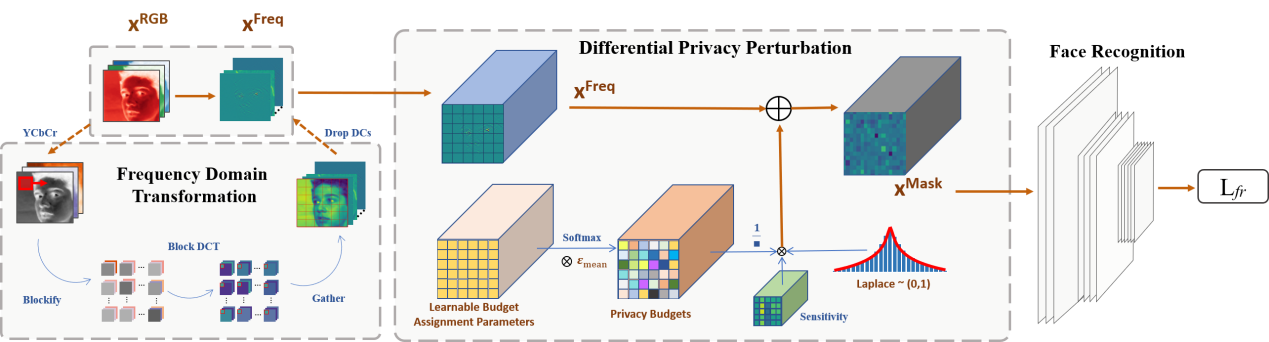
脸识别技术因其极高的准确性在日常生活中被广泛使用,但与此同时,用户对于个人人脸图像被滥用的担忧亦与日俱增。目前保护隐私的人脸识别方法往往伴随着许多副作用,如推理时间的大幅增加和识别精度的明显下降。本文提出了一种在频域下使用差分隐私的人脸识别隐私保护算法。该方法首先将原始图像转换为频域特征,并去除其中的直流部分以消除原始图像中绝大部分的可视化信息。然后在差分隐私框架内根据后端人脸识别网络的损失学习隐私预算分配模块,并将相应的噪声添加到频域特征中。由于该方法基于差分隐私框架,隐私性的保证得到了理论支撑。并且可学习的隐私预算分配模块的加入使得噪声的添加尽可能少的影响该方法的识别精度。根据大量的实验,该方法在经典的人脸识别测试集上获得了极好的表现并在对抗攻击下具备很强的抗攻击能力。
具备领域自适应能力的行人搜索算法 Domain Adaptive Person Search
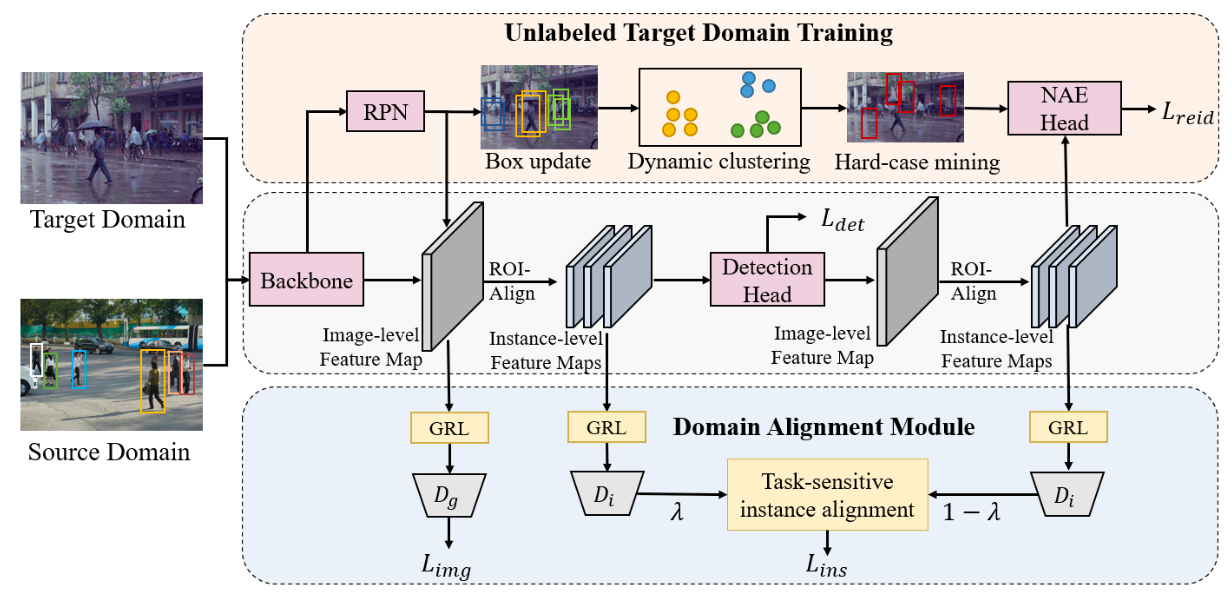
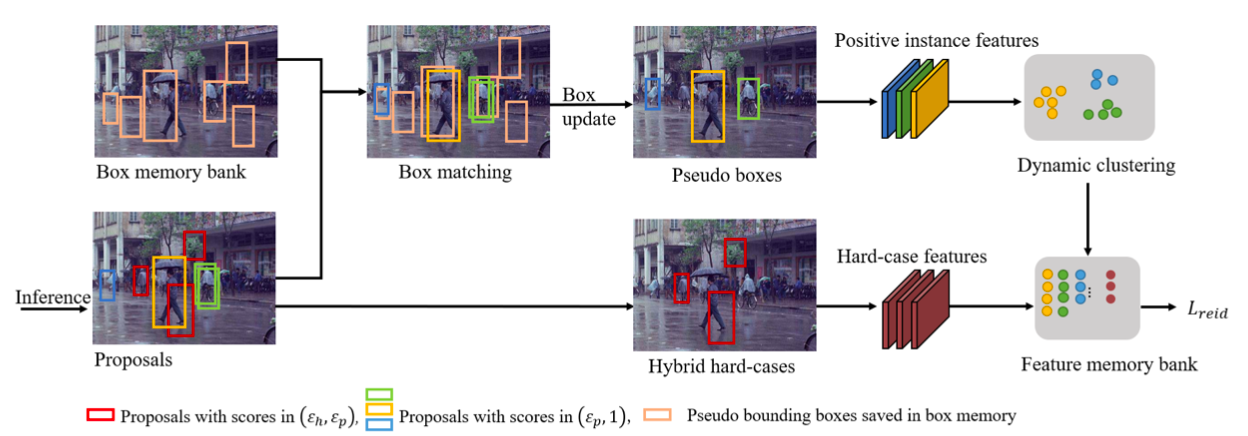

行人搜索技术旨在实现端到端联合行人检测和行人重识别任务。以前的工作在全监督和弱监督的环境下取得了重大进展。然而,这些方法忽略了行人搜索模型的跨领域泛化能力。我们进一步提出领域自适应行人搜索方法 DAPS,旨在将模型从已知身份和检测框标注的源领域推广到没有任何标注的目标领域。在这种新设置下出现了两个主要挑战:一个是如何同时解决检测和行人重识别任务的领域错位问题,另一个是如何在目标域上没有可靠检测结果的情况下训练行人重识别子任务。为了应对这些挑战,我们提出了一个具有专用设计的强大基线框架。 1)我们设计了一个领域对齐模块,包括图像级和任务敏感的实例级对齐,以最小化跨领域差异。 2)我们通过动态聚类策略充分利用未标记数据,并使用伪边界框来支持目标域上的检测和行人重识别联合训练。通过上述设计,我们的框架在 PRW 和 CUHK-SYSU 数据集间的跨领域迁移性能,大大超过了未经跨领域自适应直接迁移的模型。我们的无监督自适应模型的性能甚至可以超过一些全监督和仅知检测框的弱监督的方法。
大规模掌纹识别训练的“免费午餐”Geometric Synthesis: A Free lunch for Large-scale Palmprint Recognition Model Pretraining

掌纹是一种稳定可靠的生物特征,并且具有很强的隐私属性。在深度学习时代,掌纹识别技术的发展被训练数据不足限制。在本文中,通过对模型响应的观察我们确定掌纹线是深度学习掌纹识别中的关键信息,可以通过人造掌纹线进行训练。具体来说,我们引入了一个直观的几何模型,该模型使用参数化的贝塞尔曲线表示掌纹线。通过随机抽样贝塞尔参数,我们可以合成大量不同身份的训练样本,进而使用预训练掌纹识别模型。实验结果表明这种使用人造数据预训练的模型有非常强的泛化性,可以高效率地迁移到真实数据集并显著提高掌纹识别的性能指标。例如在开集设置下,我们的方法在 FAR=10^-6 时 TPR 相对 Arcface 提升 10%以上。在闭集条件下我们的方法也能减少 EER 一个数量级。
基于生成式域适应的人脸活体检测方法 Generative Domain Adaptation for Face Anti-Spoofing
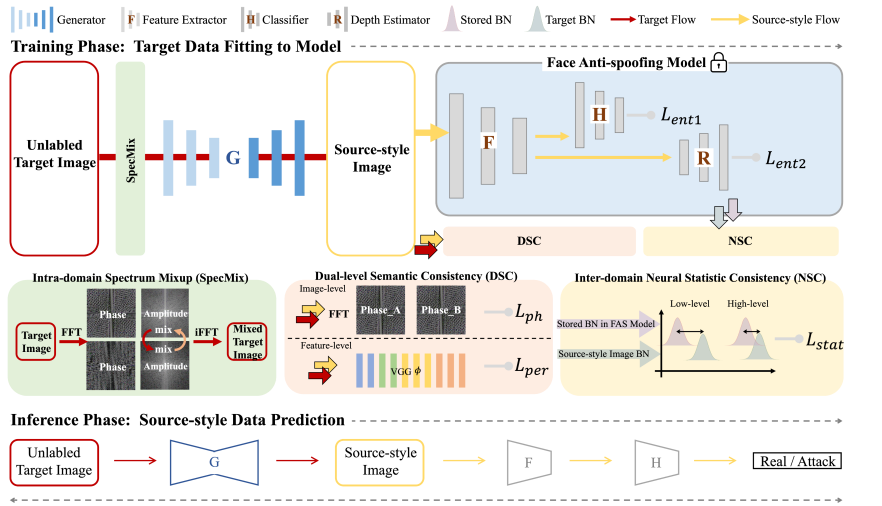
基于域适应 (DA) 的人脸活体检测 (FAS) 方法因其在目标场景中的迁移性能良好而受到越来越多的关注。大多数现有的域适应人脸活体检测方法通过对齐语义级别的高层特征分布将源域模型拟合到目标数据。然而,因为目标域上标签缺失导致的监督不足以及对于低层特征对齐的忽视限制了现有方法在人脸活体检测上的性能。为了解决这个问题,本文从一个新的角度来解决域适应人脸活体检测问题,即让目标数据拟合到源域模型,通过图像转换将目标数据风格化为源域风格,并进一步将风格化的数据输入源域的活体检测模型进行判断。具体而言,本文提出了生成式域适应(GDA)框架,并结合域间特征分布一致性约束和双重语义一致性约束来保证生成图像风格和内容与目标的一致性;此外,我们还提出域内频谱混合模块来进一步扩展目标域数据分布并提升泛化性。多个活体检测数据集上的实验和可视化结果表明,比起当前的领先方法,我们方法具有更好的迁移性。
基于多层级对比学习的视频编辑检测算法 Hierarchical Contrastive Inconsistency Learning for Deepfake Video Detection
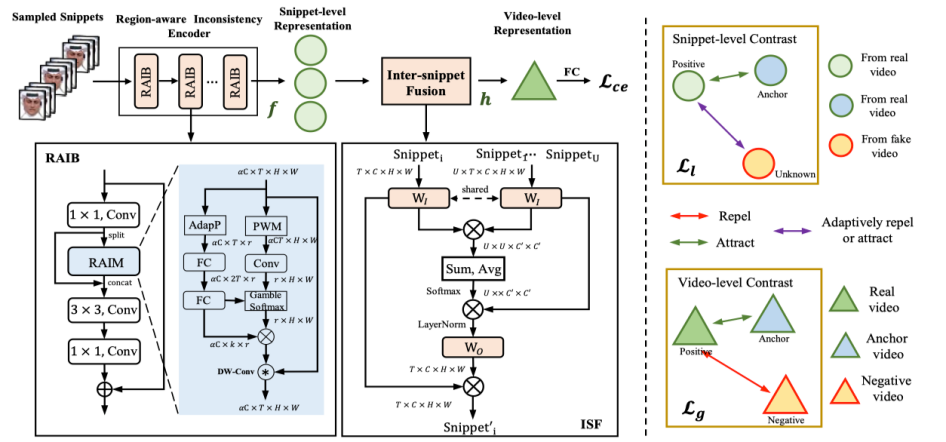
近年来,随着 Deepfake 技术的快速发展,生成逼真伪造人脸的能力引发了公众的担忧。与真实人脸视频对比,伪造视频中人脸面部运动的时序不一致性是识别 Deepfake 的有效线索,然而现有的方法往往只施加二分类监督来建模这种不一致性。在本文中,我们提出了一种新型多层级对比不一致性学习框架(HCIL)。具体而言, HCIL 首先对视频进行多片段采样, 并同时在局部片段和全局视频层级上构建对比表征学习,从而能够捕获真假视频之间更本质的时序不一致差异。此外我们还引入了用于片段内不一致性挖掘的区域自适应模块和用于跨片段信息融合的片段间融合模块,来进一步促进特征学习。大量实验表明, HCIL 模型的性能在多个 Deepfake 视频数据集上优于当前的方法。同时, 跨数据集泛化性实验和可视化也证明了该方法的有效性。
基于信息注意力驱动的图像编辑检测算法 An Information Theoretic Approach forAttention-Driven Face Forgery Detection
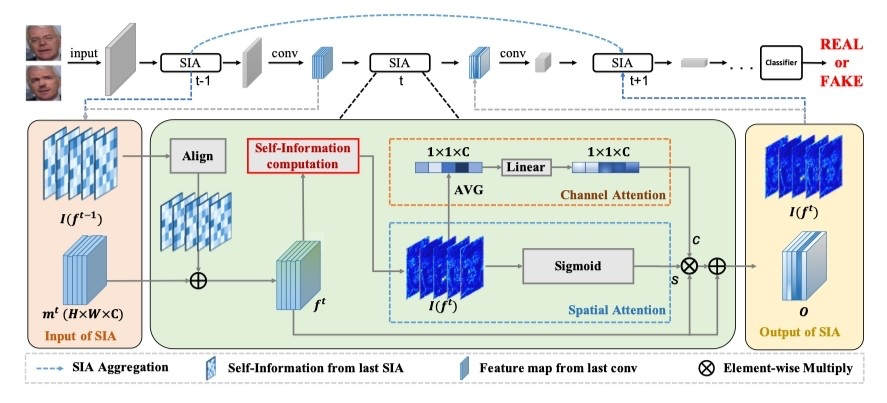
在人脸伪造检测任务中,先前基于 CNN 的启发式方法容易忽略细微的篡改痕迹。本文指出这些细微伪影往往富含高信息量,进而将自信息作为一种度量引入到伪造脸检测任务中,并结合注意力机制来增强网络对高信息量伪造区域的特征提取。同时本文还提出了一种跨层间的自信息聚合机制来缓解卷积神经网络下采样操作对细微伪造区域的擦除问题,进一步加强伪造区域特征的保留和提取。具体而言,我们首先对输入特征图计算自信息,用于发掘所有潜在的高频伪造信息。随后结合自信息与双流注意力机制,分别在通道维度和空间维度计算注意力值来进一步增强潜在的高信息量区域,让网络挖掘出更多易被忽略的伪造信息。最后,当前层的自信息特征图将会跨层连接到下一个层注意力模块,更好地保留浅层细微伪造信息。本文设计的即插即用的注意力模块,可以应用到多种人脸伪造检测框架中。多个伪造人脸检测数据集上的实验表明我们的方法在增加少量参数的情况下,可以进一步提升网络的检测性能和泛化性。
基于原型对比的语义分割迁移学习算法 Prototypical Contrast Adaptation for Domain Adaptive Semantic Segmentation
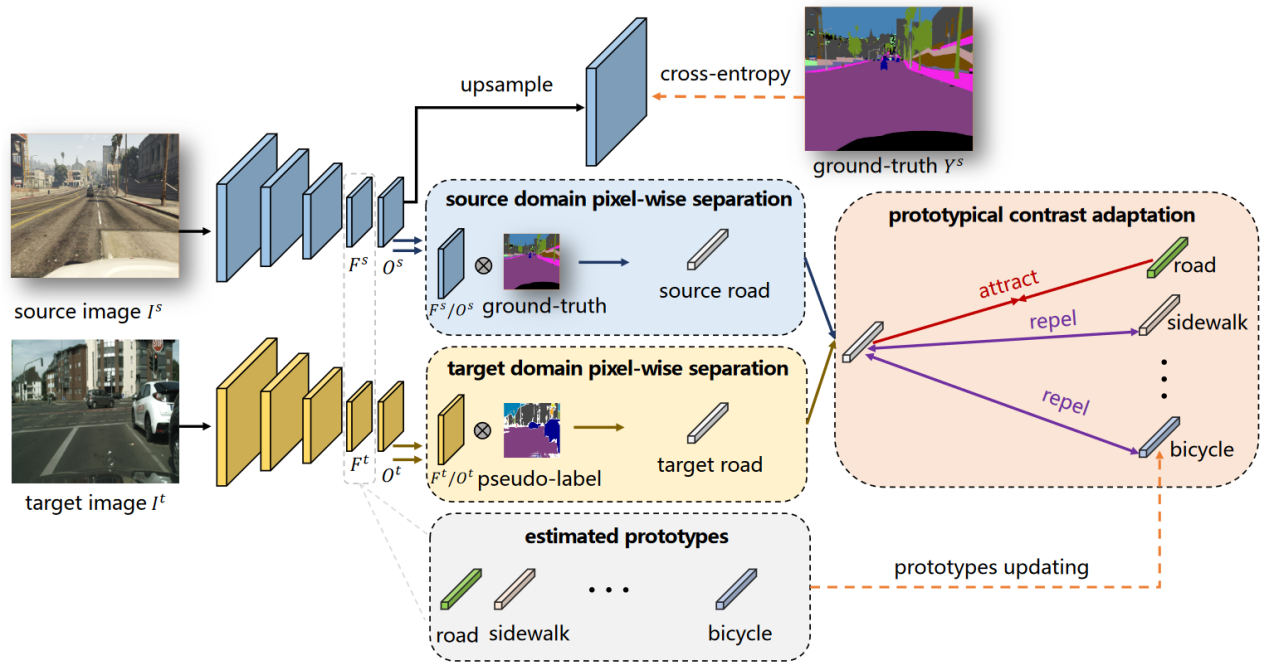
无监督迁移学习旨在将源域训练好的模型直接迁移在无标签的目标域,在实际场景如工业质检场景下有着重要作用,因为新场景下缺陷出现的概率往往很低,难以收集缺陷数据。以往的方法往往只利用特征的类间分布进行特征对齐,忽略了类间的关系建模,这就造成目标域下对齐的特征判别能力不足。因此,本文提出通过原型对比的方式同时建模类内以及类间分布,我们的方法 Prototypical Contrast Adaptation, 简称 ProCA。具体地,ProCA 通过对每一类维持一个原型表达,在特征对齐时,考虑同类的原型作为正样本,不同类的原型作为负样本从而实现类中心的分布对齐。相比目前已有的工作,ProCA 在 GTA5-Cityscapes 以及 SYNTHINA-Cityscapes 上取得了更先进的结果。

还未添加个人签名 2021.05.31 加入
还未添加个人简介









评论