
连流量染色都没有,你说要搞微服务?
一、序言
在当下盛行的微服务架构下,服务数量多导致的依赖问题经常会成为开发过程中的绊脚石。也经常会在各种技术交流会上听到类似的话题,大家都在积极的讨论这种问题如何去解决。于是决定给大家介绍下流量染色的原理以及能解决微服务架构下开发过程中的哪些问题。
二、流量染色的概念
流量染色说白了就是为对请求的流量打上标签进行染色,然后这个请求在整个链路中都会携带这个标签信息,可以通过标签进行流量的调度等功能。
基于流量染色可以实现很多功能,比如灰度逻辑,蓝绿部署,泳道隔离等。
这里简单讲下流量染色跟微服务的关系,免得大家觉得这是一篇标题党的文章。试想一下,如果是一个单体应用,还能有流量染色的应用场景吗?请求的大致流程就是 App -> 负载均衡 -> 应用,整个链路就很简单,流量染色在这个场景下完全无用武之地。只有在服务数量众多的情况下,一个业务功能涉及到 N 个服务,才需要对流量进行染色控制来解决我们开发,测试等过程中遇到的问题。
三、基于流量染色的应用
测试环境多套部署的痛点,只需增量部署
目前,我们的测试环境除了经常用的 T 环境,还有很多 MF 环境。而 MF 环境基本上是在独立的需求中会用到,正常的版本迭代都是走 T 环境。
问题一:各环境配置不同
这样就会导致一个问题,很多功能是在 T 环境进行测试的,当有独立需求需要在 MF 环境中测试时,就需要部署对应的服务,部署过程中经常会碰到各种配置的缺失或者错误的情况,导致应用无法启动。
问题二:没有改动的服务也要部署
有一个需求需要在 MF 环境测试,服务也部署好了,联调的时候却发现依赖的下游服务都没有部署。但这些服务在这个需求是没有改动的,依赖的接口也是已经上线了的功能。
如果没有在对应的环境部署,整个链路就无法调通。所以这个时候又要去找对应的下游,让下游去部署这些服务,下游部署的时候可能也会出现各环境配置不同的问题,导致整个联调前期的耗时较长,影响项目进度。
流量染色如何解决上述问题?
比如说当前在开发一个需求,然后会在要改动的应用中配置一个版本,这个版本信息会存储在注册中心的元数据里面。
然后就去创建一个属于这个需求的泳道(独立环境)进行部署,只需要部署这个需求改动的应用即可。这个应用依赖的下游应用不需要部署,在当前环境找不到对应的服务提供者就去路由到稳定环境,如果稳定环境中也没有就报错。
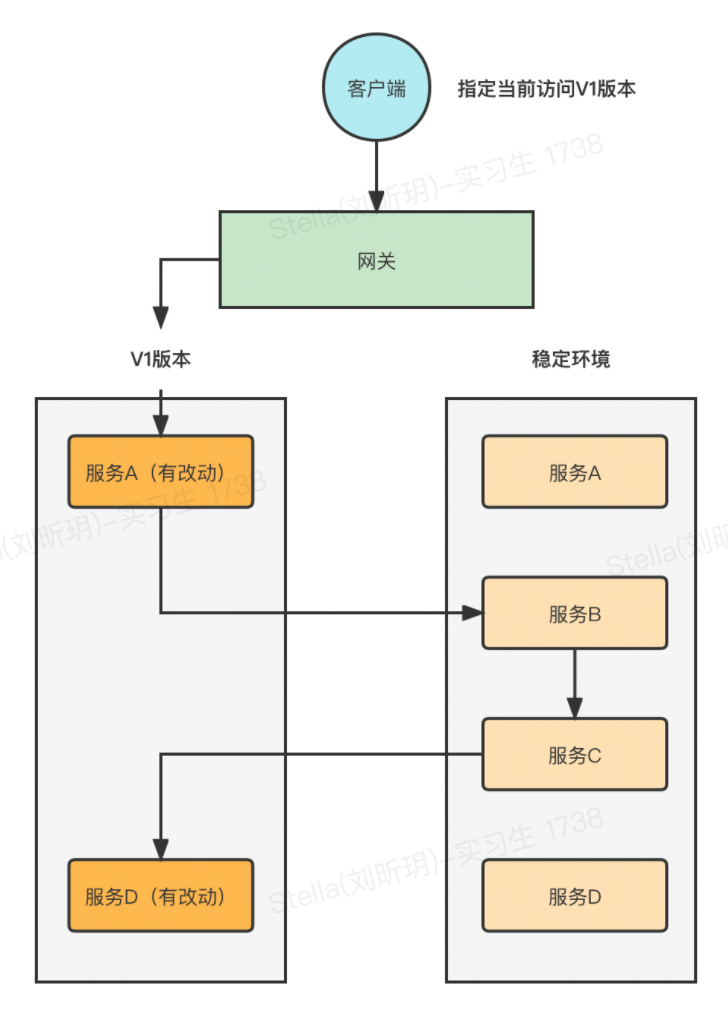
研发本地启动随意注册问题
研发有的时候会在本地启动服务,主要是用来调试某个问题,好处就是能够快速复现测试环境的问题,及时发现问题代码。
由于本地启动的服务也会注册到注册中心里面,这样测试环境的请求就有可能会路由到研发本地启动的这个服务上,研发本地的这个服务代码有可能不是最新的,导致调用异常。
这个问题目前常用的解决方案是通过在本地启动时屏蔽掉服务的注册功能,也就是不注册上去,这样就不会被正常的测试请求路由到。
如果有了流量染色的功能,研发本地启动服务的时候指定一个属于自己的版本号,只要不跟正常测试的版本一致即可。正常测试的请求就不会路由到研发注册的这个实例上。
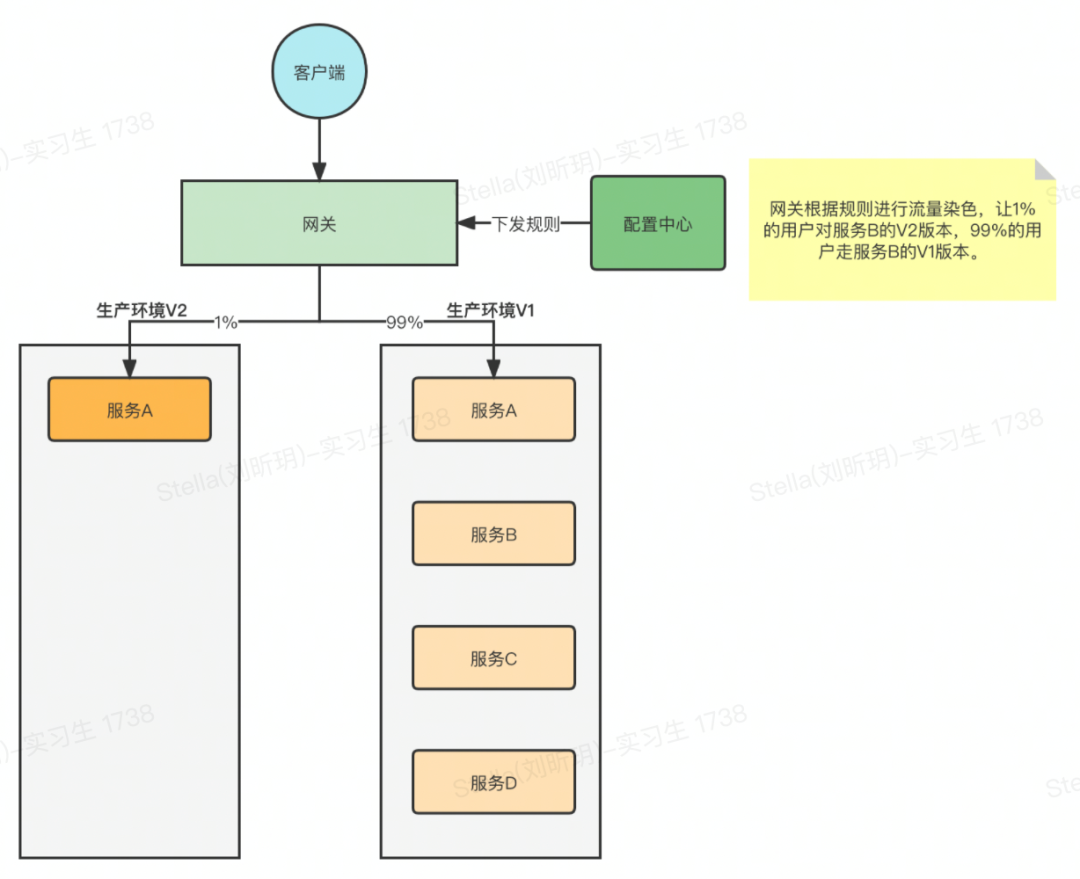
应用级别的灰度
针对接口级别的灰度,目前都是在应用内进行灰度控制。但是应用级别的,目前没有特别好的方式来控制灰度。比如有一个技改需求,需要将 Redis 的 Client 从 Lettuce 换成 Jedis,这种场景的灰度就是应用级别的,目前的做法就是发布一个节点,然后结束发布流程,具体能被灰度到的量是由服务实例的总数量来决定的,没办法灵活控制。
如果有流量染色,可以新发一个节点,这个节点的版本升级一下,比如之前的版本是 V1,那么新发的就是 V2 版本。首先 V1 版本肯定是承载生产所有流量的,可以通过网关进行控制让流量按某种方式转发到 V2 版本,比如用户白名单,地区,用户比例等等。有问题也可以随时将流量切回 V1,非常方便。
服务的优雅下线
服务要想无损进行优雅下线,还是需要做很多工作的,比如目前发布时会先将要发布的服务从注册中心注销掉,但是应用内部还是会有服务实例信息的缓存,需要等到一定的时间缓存完成清除后,对应的目标实例才不会被请求到。
如果基于染色去实现的话,将需要下线的实例信息(IP:PORT)通过配置中心推送给网关进行染色处理,染色信息跟随着请求贯穿整个链路,应用内的负载均衡组件,MQ 等中间件会对要下线的目标实例信息进行过滤,这样就不会有流量到要下线的实例上去。
生产环境发布提速
目前,主流的发布都是滚动部署,滚动发布的好处是成本低,不用额外增加部署的资源,一个萝卜一个坑,慢慢替换就是。不好的点在于发布时间长,全链路依赖太严重,如果发布之前依赖关系错乱了,那就是一个线上故障。
要解决这个发布速度的问题,可以基于流量染色来实现蓝绿部署。也就是在发布的时候重新部署一个 V2 的版本,这个 V2 版本的实例数量跟 V1 保持一致,由于这个 V2 版本是没有流量的,所以不存在依赖关系,大家可以同时发布,等到全部发完之后,就可以通过网关进行流量分发了,先分发一点点流量到 V2 版本进行验证,如果没有问题就可以慢慢放大流量,然后将 V1 版本的容器释放掉。
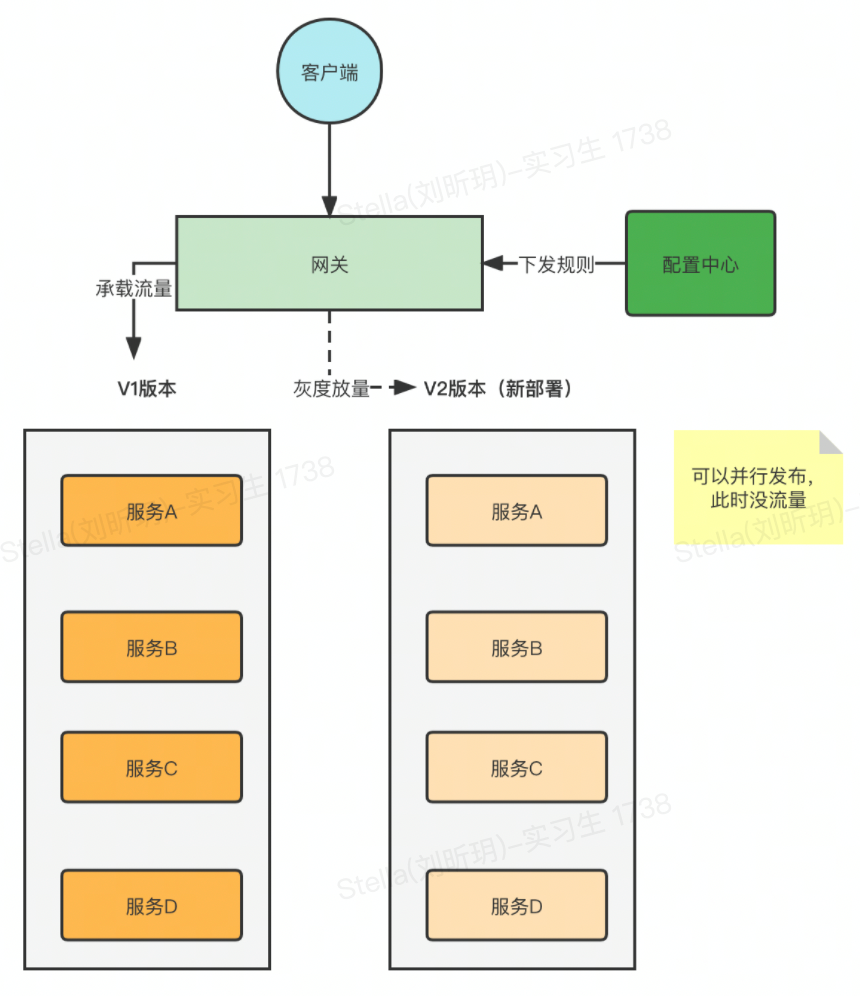
发布速度确实提升了,可是问题在于蓝绿部署的成本太高了,资源成本要翻倍,虽然发布后老的资源就回收了,但是你总的资源池还是得容纳下这 2 个版本并行才行。
那有没有折中的方式,既能提高发布效率又能不增加资源成本呢?
可以在发布的时候采用替换的形式,先发布一半的实例,这一半的实例就是我们的 V2 版本,发布时是没有流量的,所以还是可以并行的去发布。
发布完成后,开始放量到 V2 版本,然后验证。验证之后就可以发布另一半的实例了,这样的方式总的资源是没有变化的,但是有一个比较严重的问题就是直接停掉了一半的实例,剩下的实例能不能支撑当前的流量,因为交易内的应用都是面向 C 端用户的,流量很有可能在短时间内达到很高的量。
全链路压测
全链路压测对于电商业务来说必不可少,每年有 N 次大促,都需要提前进行压测来确保大促的稳定。其中全链路压测最核心的一点就是流量的区分,需要区分流量是正常的用户请求还是压测平台的压测流量。
只有区分了流量,才能将压测流量进行对应的路由,比如数据库,Redis 等流量需要路由到影子库中。基于流量染色就很容易给流量打标,从而区分流量的类型。
四、流量染色的实现
应用要有版本的概念
每个应用都需要有版本的概念,其实就跟每次迭代绑定即可。只不过是要将这个版本信息放入项目中的配置文件里面,项目启动的时候会将这个版本信息跟自身的实例信息一起注册到注册中心里面,这些信息一般称之为元数据(Metadata)。
有了 Metadata,在控制流量路由的时候才可以根据染色的信息进行对应的匹配,比如某个请求指定了对订单的调用要走 V2 版本,那么在路由的时候怎么匹配出 V2 版本的实例信息呢?就需要依赖 Metadata。
染色信息全链路透传
染色信息全链路透传这个很关键,如果不能全链路透传就没办法在所有节点进行流量的路由控制。这个染色信息的透传其实跟分布式链路跟踪是一样的原理。
目前主流支持分布式链路跟踪的有 Skywalking,Jaeger 等等,基本上都借鉴了 Google Dapper 的思想。每次请求都会在入口处生成一个唯一的 TraceId,通过这个 TraceId 就可以将整个链路关联起来,这个 TraceId 就需要在整个链路中进行传递,流量染色的信息也是一样需要全链路传递。
传递的手段一般分为两种,一种是在独立的 Agent 包中进行传递,一种是在基础框架中进行埋点传递。如果内网之间采用 Http 进行接口的调用,那么就在请求头中将信息进行传递。如果是用 RPC 的方式,则可以用 RpcContext 进行传递。
信息传递到了应用中,在这个应用中还会继续调用其他下游的接口,这个时候要继续透传,一般都是将信息放入到 ThreadLocal 中,然后在发起接口调用的时候继续透传。这里需要注意的就是用 ThreadLocal 要防止出现线程池切换的场景,否则 ThreadLocal 中的信息会丢失。当然也有一些手段来解决 ThreadLocal 异步场景下的信息传递问题,比如使用 transmittable-thread-local。
流量路由控制
当流量有了标签信息,剩下的工作就是要根据标签信息将请求路由到正确的实例上。如果内部框架是 Spring Cloud 体系,可以通过 Ribbon 去控制路由。如果是 Dubbo 体系,可以通过继承 Dubbo 的 AbstractRouter 重新制定路由逻辑。如果是内部自研的 RPC 框架,肯定留有对应的扩展去控制路由。
五、总结
流量染色总体来说还是非常有用的,但这也是一个大的技术改造。除了在基础框架层面要打通染色信息的传递,更为重要的是各业务方的配合,当然如果是 Agent 方式的接入就更好了,不然每个业务方还要去升级包,确实有点烦。
*文/尹吉欢
关注得物技术 @得物技术公众号
版权声明: 本文为 InfoQ 作者【得物技术】的原创文章。
原文链接:【http://xie.infoq.cn/article/e9e4161b445d5b417d6fe9d6a】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

得物APP技术部 2019.11.13 加入
关注微信公众号「得物技术」








评论