
在本地利用虚拟机快速搭建一个小型 Hadoop 大数据平台
一、 虚拟机备份:
注意:VM 虚拟机并不是一个非常稳定的系统,在虚拟化情况下,有时候会出现一些非常莫名奇妙的错误,这就需要我们有足够的克隆备份,以用于错误出现的恢复和追溯,大家可以参考我的虚拟机建设方式。

在基础平台中,一般都有一些搭建好的基础组件,例如我们在 Hadoop 基础平台搭建时候,需要的 JDK 1.8 基础组件,我们可以先行搭建好,后在使用的时候,直接克隆,省时省力,在搭建好的基础组件里,我们可以挑选一部分重要的(或者复杂的)进行备份。
我们配置到一半的虚拟机,在休息或者阶段性达成时,请在关机时直接进行一次克隆,然后编辑克隆后的虚拟机,按照自己舒服的方式编号即可。
在完成配置后,将完成配置的虚拟机移到已完成的组别,然后在完成备份组进行一个备份。
虚拟机默认安装系统在 C 盘,建议有一个大一点的 C 盘空间,至少 100-300G。
一、 虚拟机网络设置:
虚拟机常用有三种连接网络模式,分别是桥接,NAT,本地,这三种模式都分别代表什么意思?有什么用呢?我用类比法给大家解释一下这个问题。
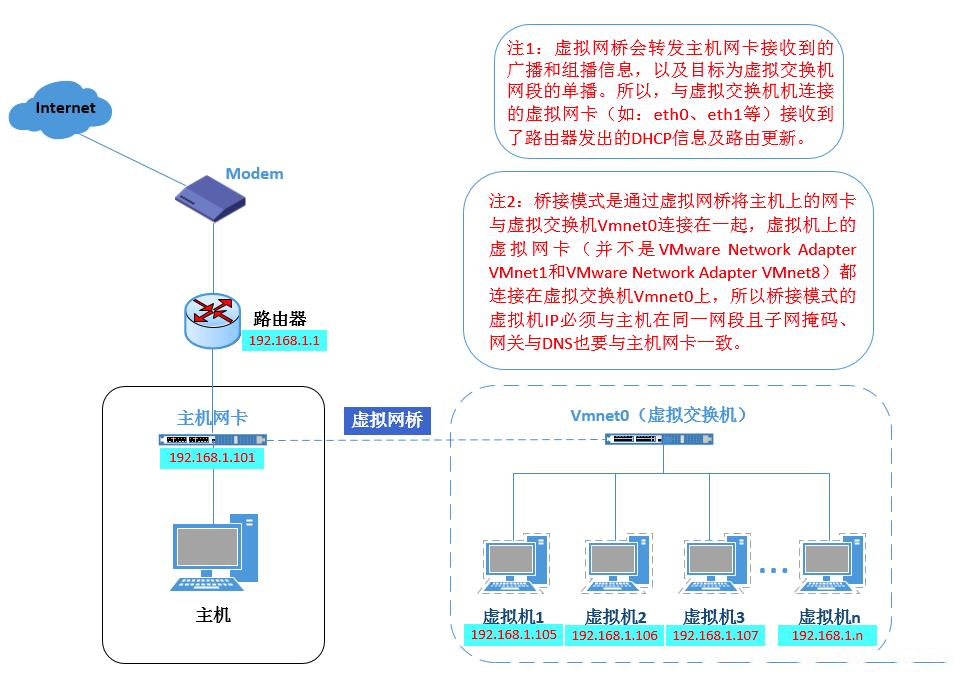
1) 桥接模式:在这种模式下,物理主机好像是一个“交换机”所有的虚拟机都连接这个物理主机的交换机上,所有虚拟机之间的交流不受影响,外界带有 DHCP 功能的路由器会直接分配给虚拟机地址,需要注意的是,你虚拟机的网段和物理机应在同一个网段,不然无法访问。示意图如下:
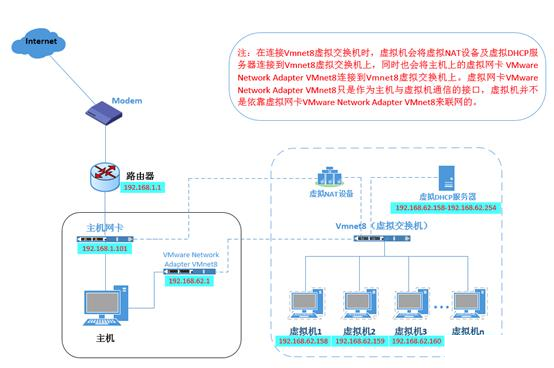
2) NAT 模式:NAT(网络地址转,用于把内部的私有网络地址转换成可以通讯的公网地)NAT 模式相当于在桥接的 Vmnet0(虚拟交换机)上又加入了 NAT 设备和 DHCP 服务器来自行分配地址,也就是说,相当于在桥接模式的“交换机”上又加了个“路由器”,这样,物理主机和虚拟机的通讯就需要对于这个“路由器”进行配置才能实现和物理主机的通讯。示意图如下:
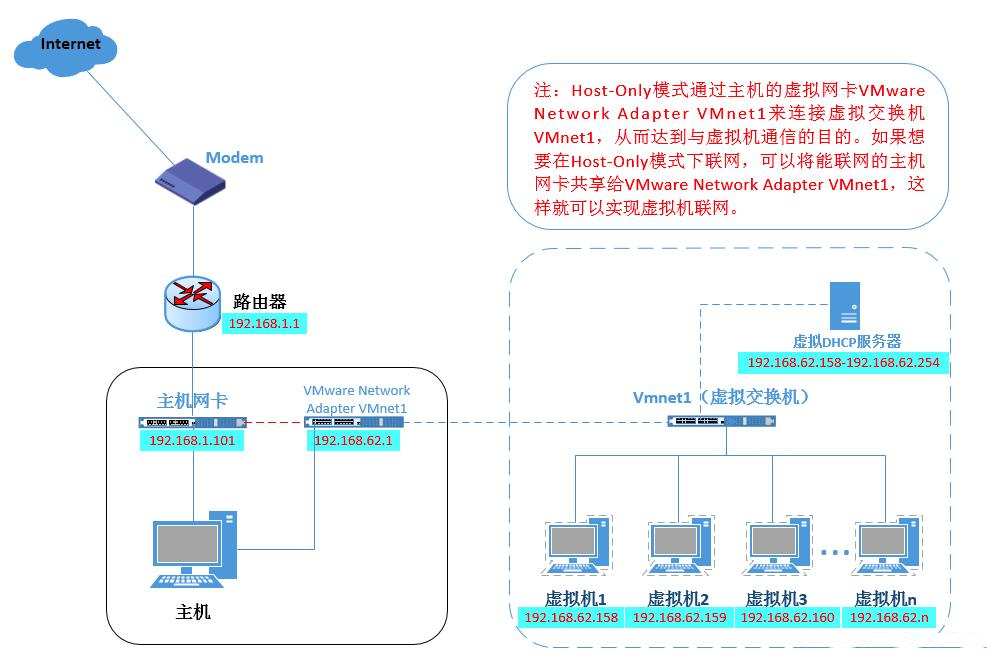
3) 本地模式:本地模式,是 NAT 模式去掉了 NAT 设备(只剩 DHCP 服务器)通过共享网卡可以实现上网。示意图如下:
我们在配置 Hadoop 平台的时候,使用 NAT 方式。
三、 JDK 环境配置
1) 环境及需要软件:
1. 物理机操作系统:windows 10 1903
2. VM 版本:15.5 pro
3. 虚拟机操作系统:CentOS 7 x86_64 1804
4. 软件需求:Xshell、Xftp、JDK1.8_211
2) 虚拟机建立:省略
3) 网络设置:
1. 网段:192.168.127.0
2. 网关:192.168.127.1
3. V8 网卡:192.168.127.88
4. 主机 IP:192.168.127.31
4) 登录 root 用户:省略
5) 开始配置:
1. IP 配置
# 修改 IP 地址
# 这步完成后需重新启动
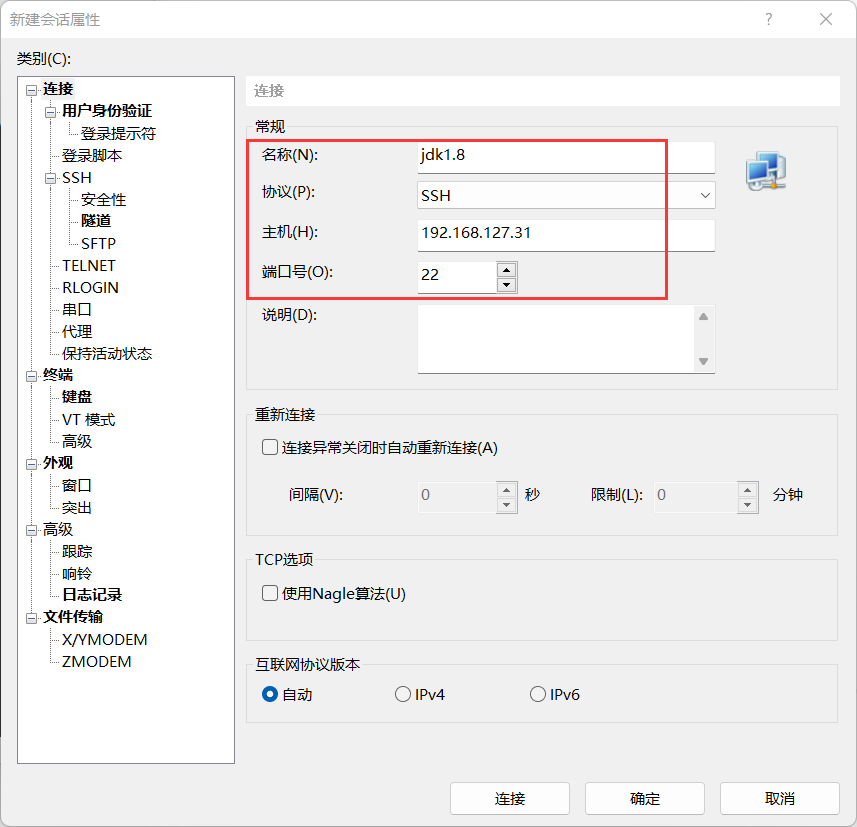
2. Xshell 到主机
# 在 Xshell 上创建 Shell 连接
# 在 XFTP 中的 /root 文件夹下新建一个文件夹为 apps,且将 JDK1.8 传输进去
3. 解压缩 JDK1.8
# 把解压后的 JDK 1.8.0_211 通过 XFTP 拖回 apps 文件夹
4. 设置并且加载 JDK1.8
# 在环境变量中加入 JDK1.8.0_211
重新加载环境变量
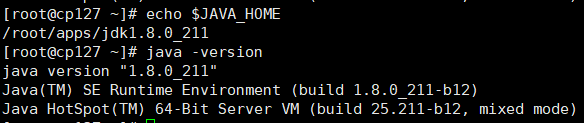
# 测试
5. 关闭主机后,克隆到大数据平台
一、 Hadoop 平台单节点搭建
1) 环境及需要软件:
1. 物理机操作系统:windows 10 1903
2. VM 版本:15.5 pro
3. 虚拟机操作系统:CentOS 7 x86_64 1804
4. 软件需求:Xshell、Xftp、hadoop 2.7.7
2) 虚拟机建立:省略
3) 登录 root 用户:省略
4) 开始配置
1. 修改主机名和 IP 映射
2. IP 地址和域名
3. 关闭防火墙
关闭防火
4. 配置 SSH 免密登录
5. 正式安装 Hadoop
# 在文件夹下解压缩
# 将 hadoop 安装包移入 apps 文件夹中:省略,参照 JDK
# 配置依赖环境
# 配置文件目录存放位置
# 配置 HDFS 副本
# 复制 mapred 组建使 mapreduce 可编辑
配置 Yarn 关联 MapReduce 运行
# 格式化 NameNode(第一次启动需要,之后都不需要)
启动命令
测试地址
http://hadoop31:50070
http://hadoop31:8088
版权声明: 本文为 InfoQ 作者【Jack20】的原创文章。
原文链接:【http://xie.infoq.cn/article/e7da89a34e96364fc742c73c6】。文章转载请联系作者。

还未添加个人签名 2022.08.08 加入
还未添加个人简介









评论