
ACM MM 2022 | 腾讯优图 11 篇论文入选,含盲超分辨率算法等研究方向
近日,腾讯优图实验室 11 篇论文被国际人工智能多媒体领域顶级会议 ACM MM 2022(ACM International Conference on Multimedia)所接收,涵盖盲超分辨率算法、视频场景分割分类等多个研究方向,这些技术创新面向智慧文娱、智慧媒体、智慧旅游等场景的落地应用,助力进一步提升 AI 技术能力,推进全球人工智能的发展。
作为世界多媒体领域重要的顶级会议和中国计算机学会推荐的该领域唯一的 A 类国际学术会议,本届 ACM MM 吸引了国内外多媒体领域中的知名厂商和学者广泛参与,共收到有效稿件 2473 篇,其中 690 篇被大会接收,接收率为 27.9%。
以下为腾讯优图实验室部分入选论文概览:
基于频域通道拆分的合作隐私保护人脸识别
DuetFace: Collaborative Privacy-Preserving Face Recognition via Channel Splitting in the Frequency Domain
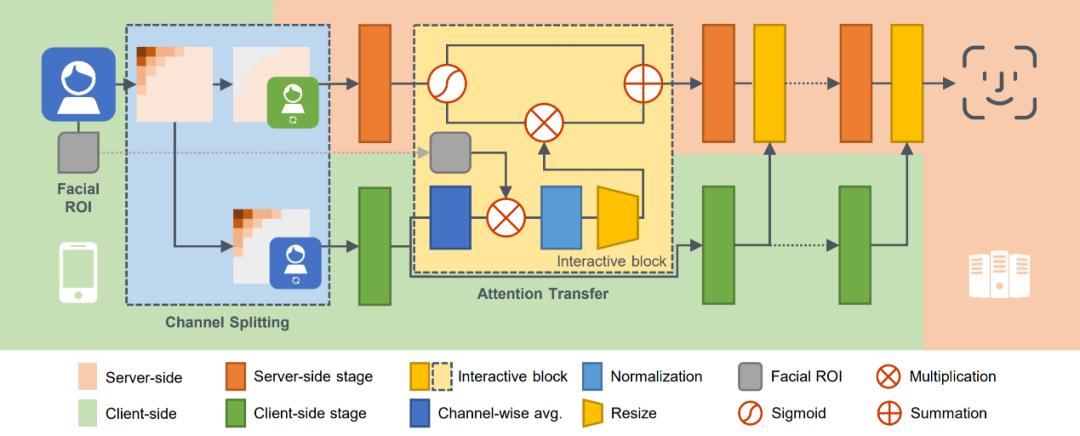
随着人脸识别系统的普及,人们日益担心原始的人脸图像会被用于未被授权的用途,导致个人隐私受到侵犯。本文提出一种隐私保护的人脸识别方法,由用户和服务器协同在频域图像上协作进行推理。本文始于一个反直觉的发现,即人脸识别模型可以仅利用视觉上无法区分的高频通道取得令人惊讶的识别性能。基于此,本文按通道对可视化的贡献程度在频域上拆分人脸图像,并仅将非重要通道交予服务器推理,以此实现隐私保护。
然而,由于视觉信息的缺失,模型对面部特征的注意力精度有所下降。作为矫正,本文引入了一个插件式交互模块,由用户侧利用剩余通道生成人脸特征掩码,将正确的注意力传递给服务器模型,并通过叠加基于面部特征点的人脸 ROI,进一步完善掩码的准确性。在多个数据集上进行的广泛实验,验证了本文所提方法能有效保护人脸视觉信息并对抗重建攻击,同时保持良好的识别精度和性能。
基于专家自适应混合的域
泛化人脸活体检测方法
Adaptive Mixture of Experts Learning for Generalizable Face Anti-Spoofing
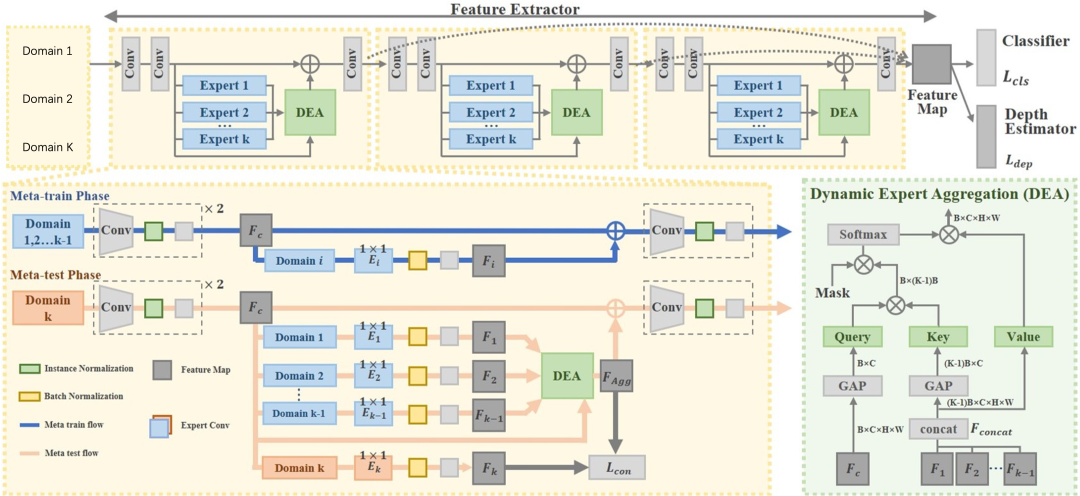
随着各种人脸攻击的不断出现,基于域泛化(DG)的人脸活体检测(FAS)方法越来越受到关注。现有基于域泛化的人脸活体检测方法旨在捕获域不变的特征,并将训练后的模型直接应用于未知域,忽略了每个源域独特的判别信息,可能会影响最后的检测效果。为了解决这个问题,我们提出了一个基于专家自适应混合的学习框架(AMEL),它利用每个域的特定信息来自适应地建立源域和目标域之间的联系,以进一步提高泛化能力。具体来说,域专家模块 (DSE) 旨在提取具有判别性和独特性的源域特征,作为对域不变特征的补充。此外,本文提出了专家动态聚合模块(DEA),根据源域和目标域的相关性自适应地聚合每个源域专家的补充信息。并通过元学习训练方法,进一步提升本方法的泛化能力。相比最先进的技术,大量的实验和可视化证明了我们方法的有效性。
基于内容与降质联合感知特征的
盲超分辨率算法
Joint Learning Content and
Degradation Aware Embedding
for Blind Super-Resolution
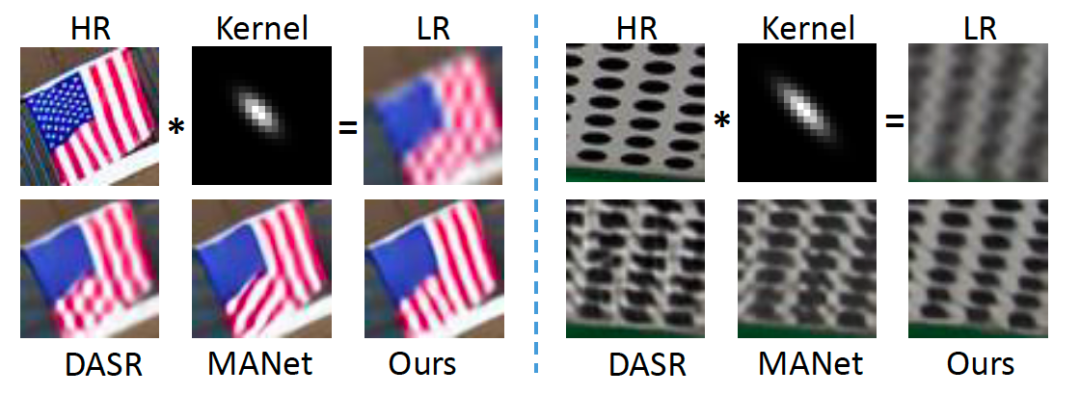
目前流行的盲超分辨率算法可以分为两类:基于核监督(SKP)和 无监督降质预测(UDP) 。因为 SKP 需要预测降质图像的模糊核,而当训练集中不含有真实世界中的模糊核的时候泛化性不高,所以 SKP 的实用性不高。UDP 可以避免 SKP 的问题,但是仍然与一些 SKP 的方法在效果上存在一些差距。
本文首先通过探索退化特征和 SR 特征之间的相关性,观察到联合学习内容和退化感知特征是相对较优的。基于此本文提出了一种基于内容与降质联合感知特征的盲超分算法 CDSR。该模型利用轻量级基于 patch 的编码器联合提取内容和退化特征,同时设计了一种新型的基于域查询的注意力模块,自适应地减少特征域之间的不一致性,最后基于码本的空间压缩模块来抑制模型中的冗余信息。
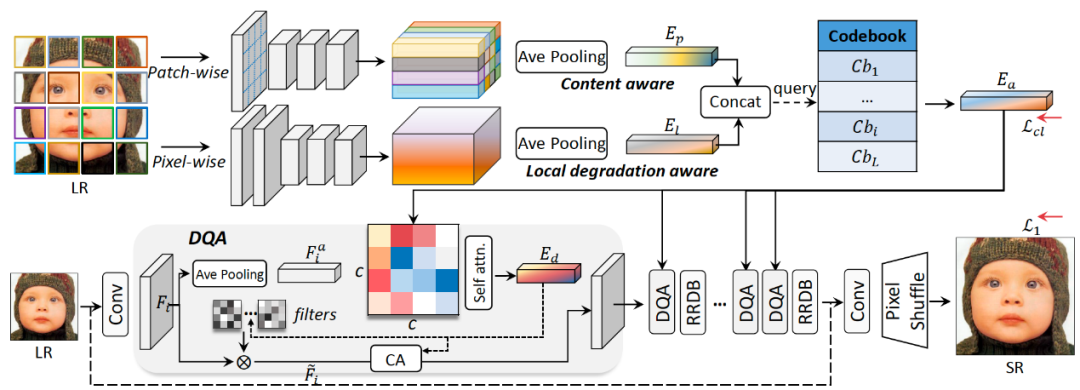
我们在多个公认的盲超分数据集上进行大量实验后,结果表明,所提出的 CDSR 优于现有的 UDP 模型,且即使与最新的 SKP 方法相比也同样具有优势。
全局与局部的结合:通过类别感知的弱监督
进行有效的多标签图像分类
Global Meets Local: Effective Multi-Label Image Classification via
Category-Aware Weak Supervision
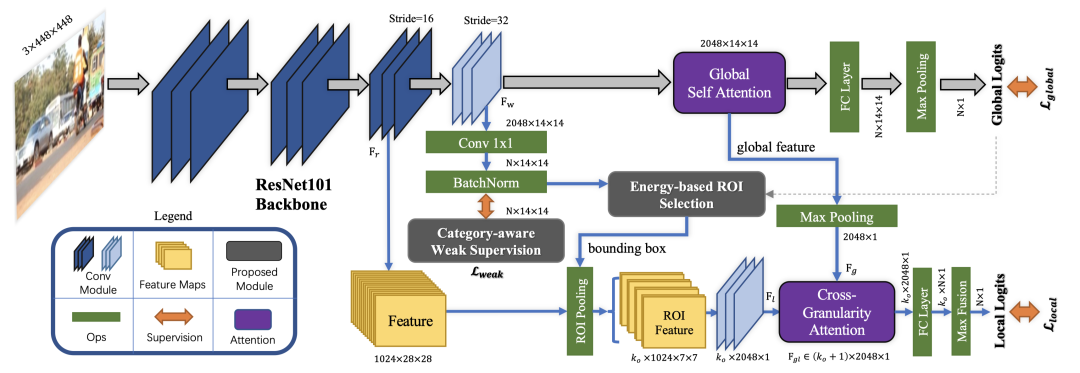
多标签图像分类,可分为标签依赖和基于区域的方法,由于其具有复杂的目标布局和场景干扰,是一个十分具有挑战性的问题。虽然基于区域的方法比标签依赖的方法更不容易遇到模型泛化的问题,但它们往往会产生数以百计的无意义或嘈杂的提议,这些提议不包含偏向性,而且局部区域之间的上下文依赖关系往往被忽视或过度简化。
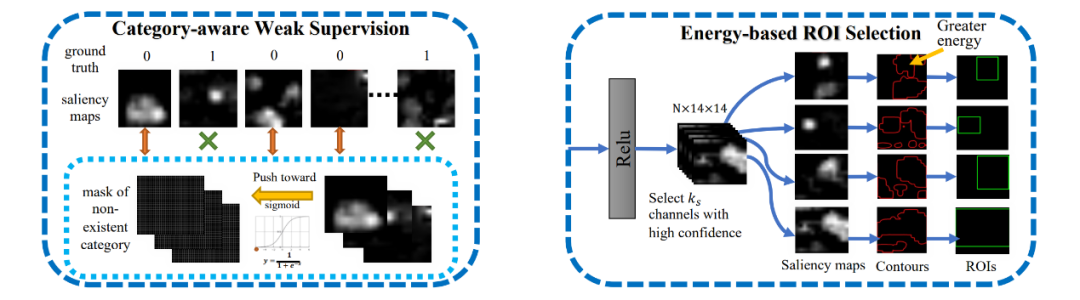
本文建立了一个统一的框架,以进行有效的噪声提议抑制,并在全局和局部特征之间进行互动,以实现强大的特征学习。具体来说,我们提出了类别感知的弱监督机制,使得模型聚焦于目标缺席的类别,从而为局部特征学习提供更精确的信息,约束局部分支聚焦于更多的高质量感兴趣候选区域。
此外,我们还开发了一个跨粒度的注意力模块,用于探索全局和局部特征之间的互补信息,从而建立包含全局到局部、局部到局部关系的高阶特征关联。这两个优点保证了整个网络性能的提升。在两个大规模数据集(MS-COCO 和 VOC 2007)上的实验表明,我们的框架取得了比现有方法更好的性能。
面向视频场景分割分类的
一阶段多模态序列连接框架
OS-MSL: One Stage Multimodal
Sequential Link Framework
for Scene Segmentation and Classification
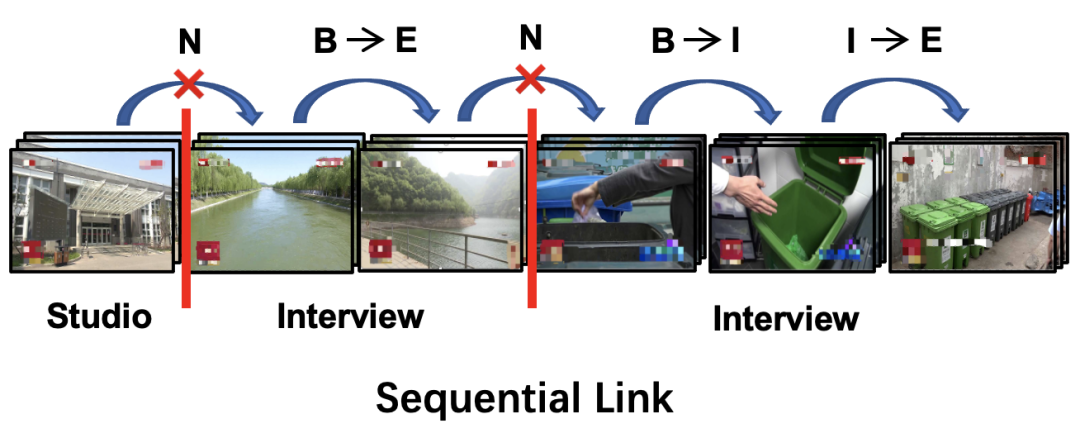
场景分割与分类是视频结构化分析的关键环节。直观上来看,将分割与分类任务进行联合学习对两个任务都是有益的,因为利用两个任务的共享信息能够起到相互促进的效果。然而,由于场景分割更多关注的是相邻镜头之间的局部差异,而分类则需要考量整个场景的全局表示,这两个不同的目标会导致模型在训练过程中陷入被某一个目标所支配的困境。
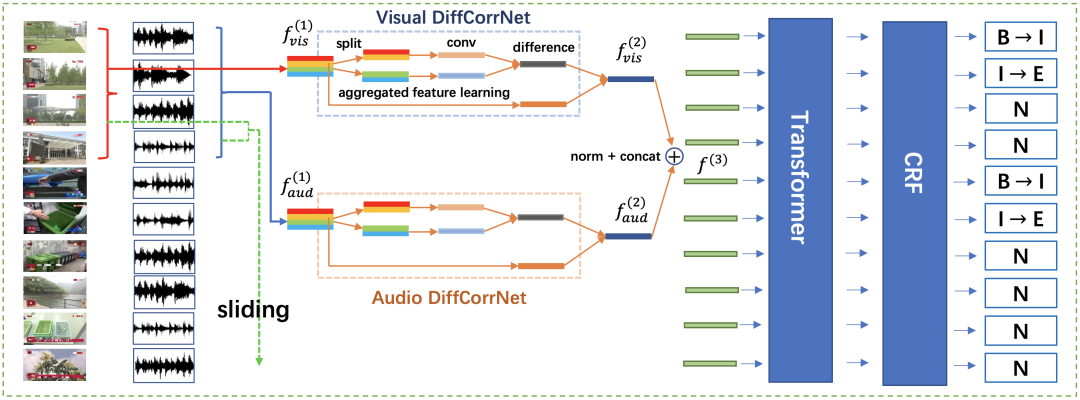
在本文中,为了克服上述挑战,我们将分割与分类任务合并为一个全新的任务——镜头连接预测。“连接”蕴含着镜头与镜头间的关系,能够表示相邻镜头是否属于同一个场景及其类别。所以,我们提出了一种通用的一阶段多模态序列连接框架(OS-MSL),能够将两个任务融合为一个统一的任务,同时能够利用这两种任务的不同语义。此外,我们创新性的设计了 DiffCorrNet 模块,能够显式地提取镜头之间的差异性和相关性。在大规模新闻数据集以及电影数据集上,实验结果都验证了本框架的有效性。

还未添加个人签名 2021.05.31 加入
还未添加个人简介









评论