你真的懂语音特征吗?
摘要:本文旨在详细介绍语音转化声学特征的过程,并详细介绍不同声学特征在不同模型中的应用。
本文分享自华为云社区《你真的懂语音特征背后的原理吗?》,作者: 白马过平川 。
语音数据常被用于人工智能任务,但语音数据往往不能像图像任务那样直接输入到模型中训练,其在长时域上没有明显的特征变化,很难学习到语音数据的特征,加之语音的时域数据通常由 16K 采样率构成,即 1 秒 16000 个采样点,直接输入时域采样点训练数据量大且很难有训练出实际效果。因此语音任务通常是将语音数据转化为声学特征作为模型的输入或者输出。因此本文指在详细介绍语音转化声学特征的过程,并详细介绍不同声学特征在不同模型中的应用。
首先搞清语音是怎么产生的对于我们理解语音有很大帮助。人通过声道产生声音,声道的形状决定了发出怎样的声音。声道的形状包括舌头,牙齿等。如果可以准确的知道这个形状,那么我们就可以对产生的音素进行准确的描述。声道的形状通常由语音短时功率谱的包络中显示出来。那如何得到功率谱,或者在功率谱的基础上得到频谱包络,便是可以或得语音的特征。
一、时域图
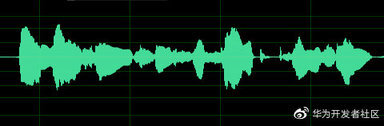
图 1:音频的时域图
时域图中,语音信号直接用它的时间波形表示出来,上图 1 是用 Adobe Audition 打开的音频的时域图,表示这段语音波形时量化精度是 16bit,从图中可以得到各个音的起始位置,但很难看出更加有用的信息。但如果我们将其放大到 100ms 的场景下,可以得到下图 2 所示的图像。
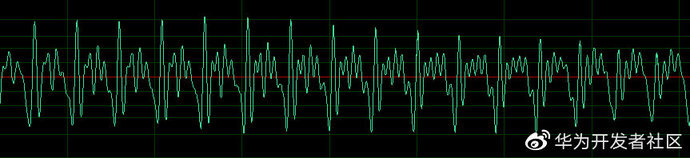
图 2:音频的短时时域图
从上图我们可以看出在短时的的时间维度上,语音时域波形是存在一定的周期的,不同的发音往往对应着不同的周期的变化,因此在短时域上我们可以将波形通过傅里叶变换转化为频域图,观察音频的周期特性,从而获取有用的音频特征。
短时傅里叶变换(STFT)是最经典的时频域分析方法。所谓短时傅里叶变换,顾名思义,是对短时的信号做傅里叶变化。由于语音波形只有在短时域上才呈现一定周期性,因此使用的短时傅里叶变换可以更为准确的观察语音在频域上的变化。傅里叶变化实现的示意图如下:
图 3:傅里叶变换的从时域转化为频域的示意图
上图显示的了如何通过傅里叶变化将时域波形转化为频域谱图的过程,但在由于本身傅里叶变化的算法复杂度为 O(N^2),难以应用,在计算机中应用中更多的是使用快速傅里叶变换(FFT)。其中转化的推理证明参考[知乎](https://zhuanlan.zhihu.com/p/31584464)
二、获取音频特征
由上述一可以知道获取音频的频域特征的具体方法原理,那如何操作将原始音频转化为模型训练的音频特征,其中任然需要很多辅助操作。具体流程如下图 4 所示:
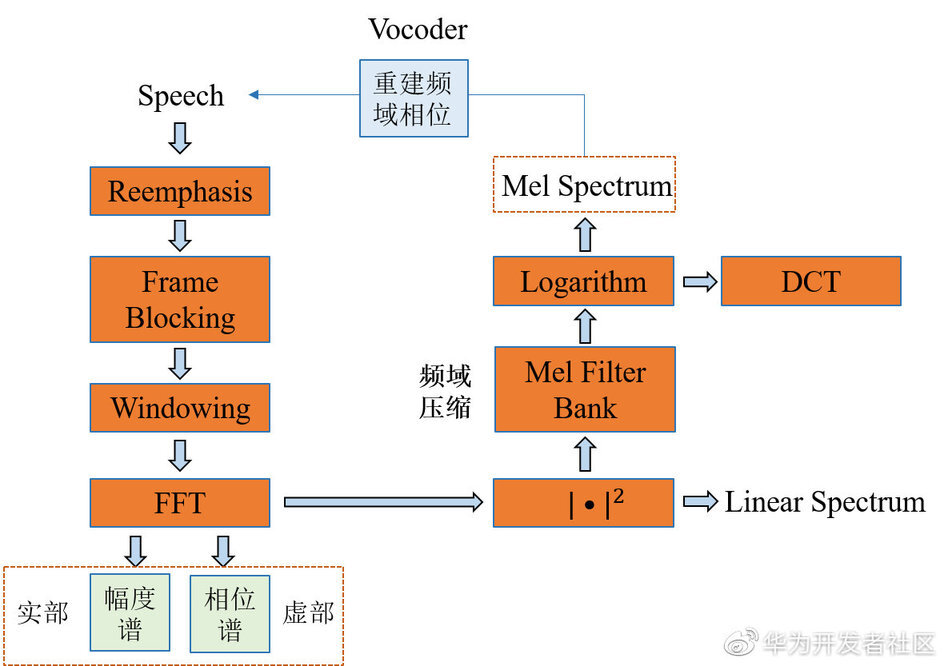
图 4:音频转化为音频特征的流程图图
(1)预加重
预加重处理其实是将语音信号通过一个高通滤波器:
H(z) = 1 - \mu z^{-1}H(z)=1−μz−1
其中\muμ ,我们通常取为 0.97。预加重的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱。同时,也是为了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰。
(2)分帧
由于傅里叶变换要求输入信号是平稳的,不平稳的信号做傅里叶变换是没有什么意义的。由上述我们可以知道语音在长时间上是不稳定的,在短时上稳定是有一定的周期性的,即语音在宏观上来看是不平稳的,你的嘴巴一动,信号的特征就变了。但是从微观上来看,在比较短的时间内,嘴巴动得是没有那么快的,语音信号就可以看成平稳的,就可以截取出来做傅里叶变换了,因此要进行分帧的操作,即截取短时的语音片段。
那么一帧有多长呢?帧长要满足两个条件:
从宏观上看,它必须足够短来保证帧内信号是平稳的。前面说过,口型的变化是导致信号不平稳的原因,所以在一帧的期间内口型不能有明显变化,即一帧的长度应当小于一个音素的长度。正常语速下,音素的持续时间大约是 50~200 毫秒,所以帧长一般取为小于 50 毫秒。
从微观上来看,它又必须包括足够多的振动周期,因为傅里叶变换是要分析频率的,只有重复足够多次才能分析频率。语音的基频,男声在 100 赫兹左右,女声在 200 赫兹左右,换算成周期就是 10 ms 和 5 ms。既然一帧要包含多个周期,所以一般取至少 20 毫秒。
注意: 分帧的截取并不是严格的分片段,而是有一个帧移的概念,即确定好帧窗口的大小,每次按照帧移大小移动,截取短时音频片段,通常帧移的大小为 5-10ms,窗口的大小通常为帧移的 2-3 倍即 20-30ms。之所以设置帧移的方式主要是为了后续加窗的操作。
具体分帧的流程如下所示:
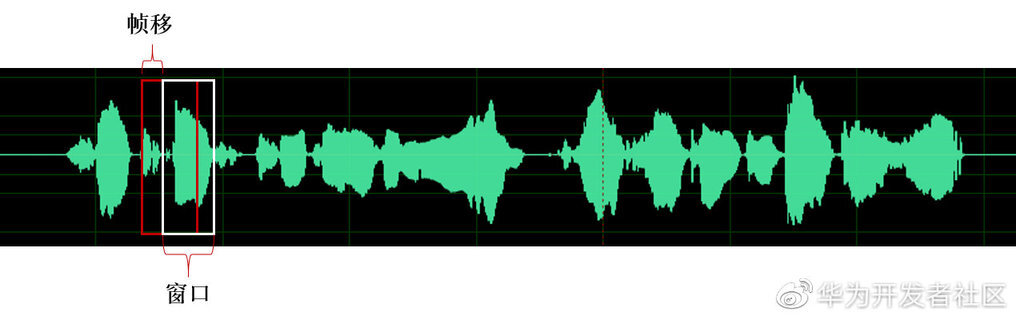
图 5:音频分帧示意图
(3)加窗
取出来的一帧信号,在做傅里叶变换之前,要先进行「加窗」的操作,即与一个「窗函数」相乘,如下图所示:

图 5:音频加窗示意图
加窗的目的是让一帧信号的幅度在两端渐变到 0。渐变对傅里叶变换有好处,可以让频谱上的各个峰更细,不容易糊在一起(术语叫做减轻频谱泄漏),加窗的代价是一帧信号两端的部分被削弱了,没有像中央的部分那样得到重视。弥补的办法是,帧不要背靠背地截取,而是相互重叠一部分。相邻两帧的起始位置的时间差叫做帧移。
通常我们使用汉明窗进行加窗,将分帧后的每一帧乘以汉明窗,以增加帧左端和右端的连续性。假设分帧后的信号为 S(n), n=0,1,…,N-1, NS(n),n=0,1,…,N−1,N 为帧的大小,那么乘上汉明窗后:
W(n,a)=(1-a)-a\times \cos(\frac{2\pi n}{N-1}), \quad 0 \leq n \leqN-1W(n,a)=(1−a)−a×cos(N−12πn),0≤n≤N−1
不同的 a 值会产生不同的汉明窗,一般情况下取为 0.46。
S^{'}(n) = S(n) \times W(n, a)S′(n)=S(n)×W(n,a)
实现的代码:
(4)快速傅里叶变换 FFT
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。快速傅里叶变换的实现原理已经在前面介绍过,这里不过多介绍。详细的推理和实现推介参考知乎 FFT(https://zhuanlan.zhihu.com/p/31584464)
注意 : 这里音频经过快速傅里叶变换返回的是复数,其中实部表示的频率的振幅,虚部表示的是频率的相位。
包含 FFT 函数的库有很多,简单列举几个:
得到音频的振幅和相位谱,需要对频谱取模平方得到语音信号的功率谱,也就是语音合成上常说的线性频谱。
(5)Mel 频谱
人耳能听到的频率范围是 20-20000Hz,但人耳对 Hz 这种标度单位并不是线性感知关系。例如如果我们适应了 1000Hz 的音调,如果把音调频率提高到 2000Hz,我们的耳朵只能觉察到频率提高了一点点,根本察觉不到频率提高了一倍。因此可以将普通的频率标度转化为梅尔频率标度,使其更符合人们的听觉感知,这种映射关系如下式所示:
mel(f)=2595 \times \log_{10}(1+\frac{f}{700})mel(f)=2595×log10(1+700f)
f=700 \times (10^{\frac{m}{2595}}-1)f=700×(102595m−1)
在计算机中,线性坐标到梅尔坐标的变换,通常使用带通滤波器来实现,一般常用的使用三角带通滤波器,使用三角带通滤波器有两个主要作用:对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。其中三角带通滤波器构造的示意图如下所示:
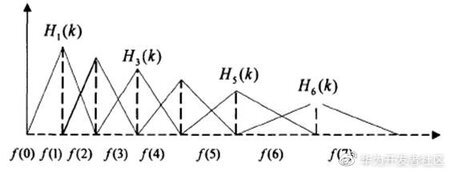
图 6:三角带通滤波器构造示意图
这是非均等的三角带通滤波器构造示意图,因为人类对高频的能量感知较弱,因此低频的保存能量要明显大与高频。其中三角带通滤波器的构造代码如下:
然后只需将线性谱乘以三角带通滤波器,并取对数就能得到 mel 频谱。通常语音合成的任务的音频特征提取一般就到这,mel 频谱作为音频特征基本满足了一些语音合成任务的需求。但在语音识别中还需要再做一次离散余弦变换(DCT 变换),因为不同的 Mel 滤波器是有交集的,因此它们是相关的,我们可以用 DCT 变换去掉这些相关性可以提高识别的准确率,但在语音合成中需要保留这种相关性,所以只有识别中需要做 DCT 变换。其中 DCT 变换的原理详解可以参考知乎 DCT(https://zhuanlan.zhihu.com/p/85299446)
想了解更多的 AI 技术干货,欢迎上华为云的 AI 专区,目前有 AI 编程 Python 等六大实战营供大家免费学习。(六大实战营 link:http://su.modelarts.club/qQB9
版权声明: 本文为 InfoQ 作者【华为云开发者社区】的原创文章。
原文链接:【http://xie.infoq.cn/article/dd46c1f0884816138d567bcec】。文章转载请联系作者。

提供全面深入的云计算技术干货 2020.07.14 加入
华为云开发者社区,提供全面深入的云计算前景分析、丰富的技术干货、程序样例,分享华为云前沿资讯动态,方便开发者快速成长与发展,欢迎提问、互动,多方位了解云计算! 传送门:https://bbs.huaweicloud.com/









评论