
Introduction to ByteDance Pitaya

What is ByteDance Pitaya?
1. Pitaya Defined
Over the past decade, with the increased computing power, more efficient hardware, as well as rapid advances in AI algorithms, we are witnessing a paradigm shift in how on-device AI is gradually put into large-scale productions. Major players in the industry like FAANG, Alibaba, Tencent, and Baidu have been investing significantly in applying on-device AI to products and to new domains, and consider it a game-changer in creating impactful experiences for their customers and improving their business intelligence efficiency.
Client AI is an on-device AI research team under the umbrella of ByteDance Infra. Client AI brings together experts in on-device AI framework, kernel and system programming, advanced algorithm, and machine learning to create an on-device AI infrastructure that powers ByteDance.
ByteDance Pitaya is the on-device AI infrastructure introduced by the Client AI team and MLX team collaboratively. It provides complete end-to-end support for the whole cycle of on-device AI applications from development to deployment.
Pitaya's vision is to develop a state-of-the-art on-device AI infrastructure in the field. We center around advancing on-device AI techniques, driving the democratization of machine learning, and supporting ByteDance's business intelligence with AI-driven solutions to boost businesses, increase operational efficiency, optimize cost, and improve user experience.
Up to now, Pitaya has provided tailored on-device AI solutions for more than 30 ByteDance products such as Douyin, TikTok, and Toutiao in large-scale production and is currently supporting AI models and strategies to operate at 10-billion scale per day on smartphone devices.

2. Pitaya Architecture
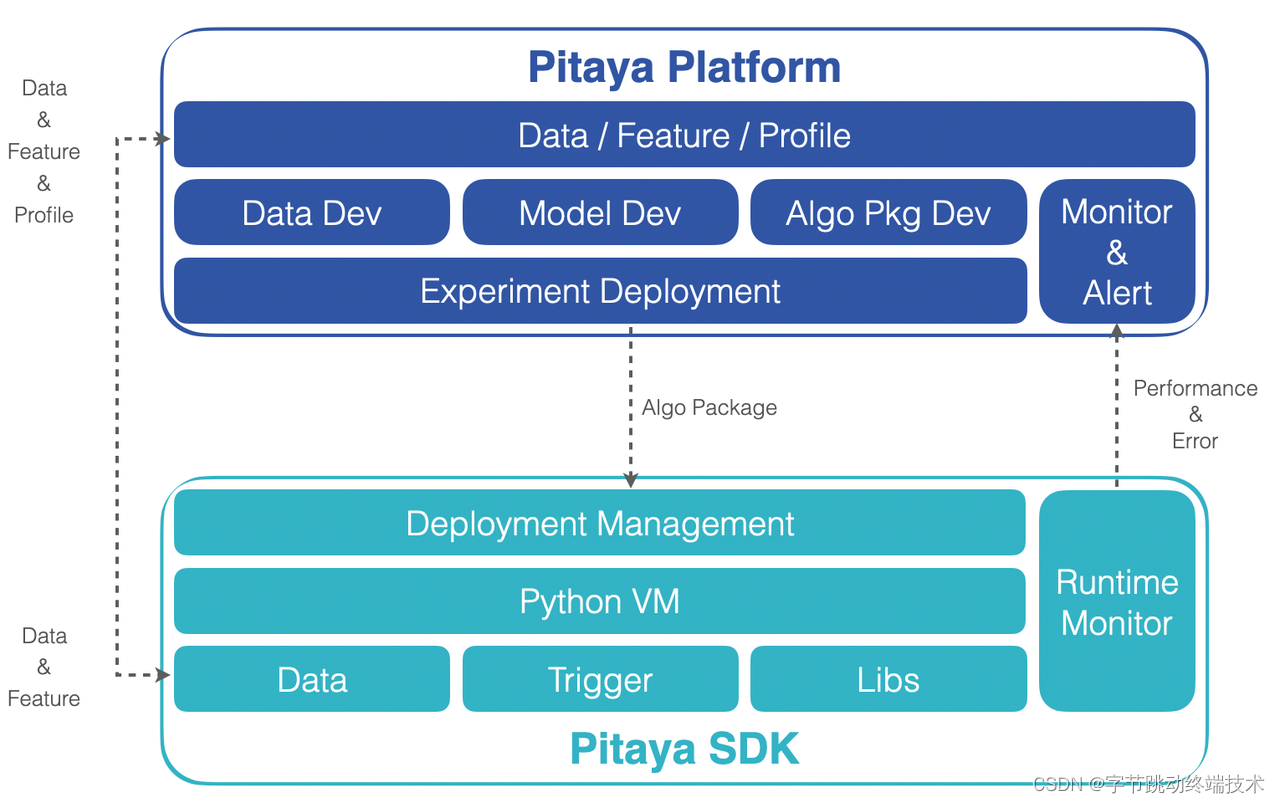
Pitaya consists of two main components: the Pitaya platform and the Pitaya SDK.
Pitaya platform provides a comprehensive, managed, end-to-end workbench for on-device AI applications, which enables ML engineers to build and manage AI projects, access data from various sources, train, optimize, and deploy AI models that can operate on devices with ease. Pitaya platform also comes with integrated services that enable us to develop, debug and experiment on AI-powered solutions, deploy AI packages into mobile devices, monitor services in real-time, customize alerting, and visualize the performance of your AI tasks and models.
Pitaya SDK offers an integrated runtime environment for us to seamlessly deploy and run machine learning models on smartphone devices. It also provides a strongly consistent, composable on-device Feature Engineering framework, allowing for easy implementation of data processing, storing, and managing. To ensure user privacy and security, Pitaya SDK comes with a Federated Learning service that allows training of both cloud-based and on-device AI models without the risk of a data breach.
3. Pitaya Platform
3.1 Pitaya Workbench
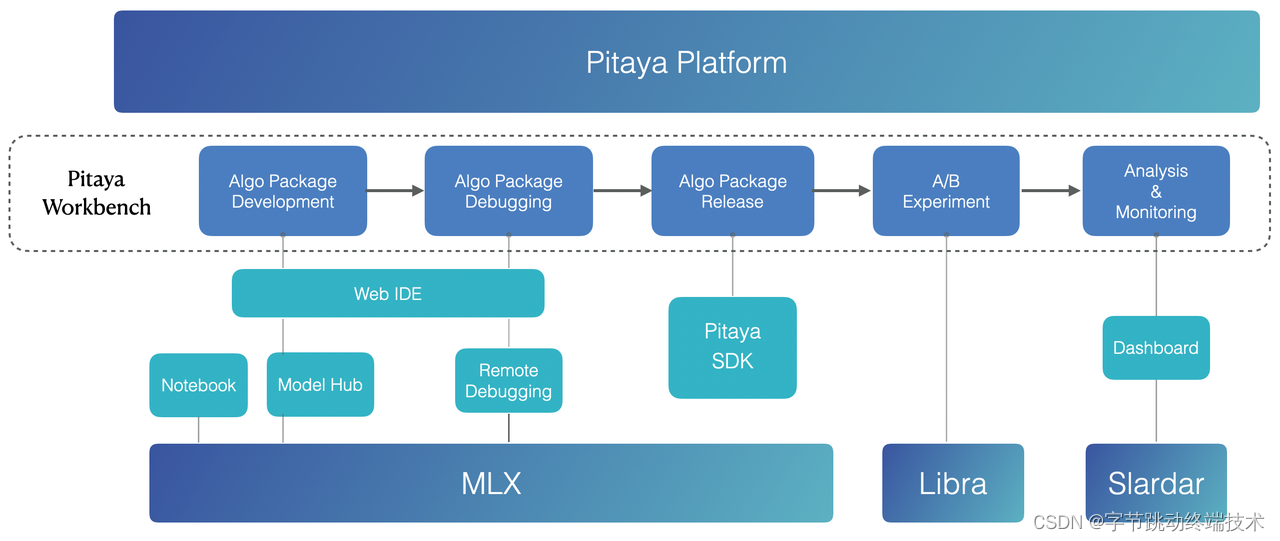
MLX: ByteDance's unified end-to-end machine learning platform
Libra: ByteDance's large-scale online AB experimentation platform
Slardar: ByteDance's comprehensive monitoring APM platform
Pitaya platform provides a fully-managed, scalable, foundational Pitaya Workbench that covers the entire lifecycle of on-device AI and machine learning, from development to experimentation, to managing and monitoring the AI models. It includes:
An integrated Web IDE production environment serves a built-in web UI and a web editor in which machine learning engineers and data scientists can develop, manage, debug, release, deploy, experiment, and monitor ML tasks in billion-scale mobile devices. The web IDE houses the workflow system used to orchestrate data, models, intelligence strategies, task triggers, and release policies through an easy configuration of an algorithm package.
A set of debugger tools for ML engineers to effectively debug their algorithm packages on mobile devices before releasing them into production. The debugger tools allow you to start a debugging session where you can view and filter the system messages in a logcat window and set several types of breakpoints in the algorithm code that pauses the execution of your app at any code location. While paused, you can examine variables, evaluate expressions, then continue execution line by line to determine the causes of runtime errors. The debugger tools also support executing mock SQL queries for inspecting and testing the value and the format of real-time feature data stored in the on-device repository.
An algorithm package deployment and release system which supports you to only release your algorithm package within a particular group of users (the control group or one of the treatment groups) in an A/B experiment hosted by Libra (ByteDance's large-scale online A/B Testing platform). In this way, you can easily evaluate the effectiveness of your ML-powered strategy with a data-driven measurement by comparing the core business metrics between experiment groups (online strategies or other ML-powered strategies of different models).
A Monitoring and Alert System that supports you in tracking your algorithm package's performance comprehensively, coverage rate, stability, as well as AI model metrics (e.g., accuracy, recall) in production. It also integrates with real-time dashboards that visually present performance measures and metrics trending, offering deep insights into your on-device AI strategies and models.
3.2 ML Platform
To support the need for large-scale data processing and deep learning model training, Pitaya Platform engages with MLX Notebook (ByteDance's device-cloud collaborative Notebook service) to provide an integrated JupyterLab environment for training on-device AI models.
MLX Notebook has native integration with large-scale data processing engines (Spark, Flink) and machine learning frameworks (TensorFlow, PyTorch, XGBoost, LightGBM, SparkML, Scikit-Learn). It allows you to train ML and DL models by exporting datasets from multiple sources (HDFS, Hive, Kafka, MySQL). MLX Notebook also extends standard SQL with MLSQL OPs, compiling SQL queries into distributed computing workflow to enable the pipeline of data extracting, processing, model training, evaluating, serving, and explaining.
4. Pitaya SDK
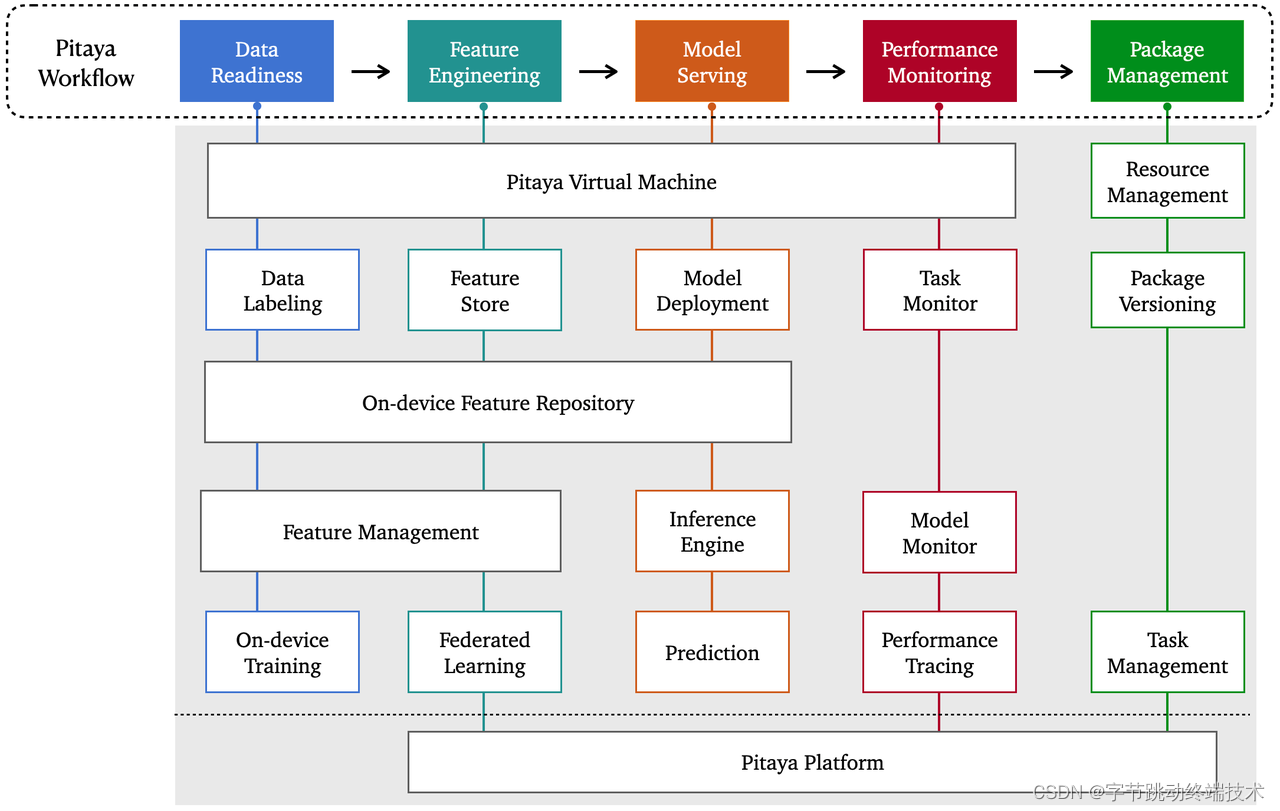
4.1 On-Device AI Environment
4.1.1 Pitaya Virtual Machine
The core of the Pitaya SDK is an on-device Virtual Machine developed by the Client AI team, called Pitaya VM, which provides the essential environment for AI models to operate on smartphone devices. Pitaya VM is specifically designed for solving the problems of on-device VM with respect to its excessive size and limited performance. Pitaya VM retains most of the on-device VM's core functionality and optimizes it in several ways:
Lightweight: Mobile app size is a crucial factor that directly impacts users' update and download rates of mobile applications. Pitaya VM is integrated with an analysis tool that thoroughly inspects the target bundle to detect possible duplicates and create a visual representation of the components that impact the bundle size most. With the bundle analyzer, we can consistently optimize Pitaya VM by excluding unnecessary functions and optimizing its implementation. The size of Pitaya VM is now minimized from more than 10 megabytes down to a manageable size strictly under 1 megabyte, almost a factor x10 reduction.
Efficiency: While reducing the bundle size of the On-device VM, Pitaya makes determined efforts to improve its performance on edge devices, bringing it close to what could be achieved on dedicated implementations in Kotlin or Swift in most cases or even better. For high-concurrency scenarios, Pitaya VM enables an asynchronous mode that allows for operating AI and machine learning codes natively at scale. For high-performance use cases, Pitaya VM features a JIT (Just-in-Time) compiler to improve the performance of ML programs by compiling bytecodes into native machine code just-in-time to run, which could effectively increase its operating speed by 30 percent.
Security: Pitaya VM ensures protection from network and application-based attacks by encrypting all the files and codes in a specially designed format.
For products susceptible to the application size (e.g., ToB products), Pitaya offers a MinVM variant with a bundle size reduced to less than 100 kilobytes. MinVM attains the ultra-thin size using a lightweight interpreter developed by the Client AI team.
4.2 Pitaya Core Workflow
4.2.1 Data Readiness
Pitaya SDK supports and facilitates the process of your data preparation. You can ingest data directly from various sources (e.g., Pitaya On-device Feature Repository, Cloud Feature Store) and extract features of the current device, your applications, and your target scenes. Pitaya SDK also allows for leveraging integrated AI on-device data labeling to annotate high-quality training data in real-time for exploration and model training.
4.2.2 Feature Engineering
Pitaya Feature Engineering is a product-centric service aiming to provide ML feature and data capabilities with best-in-class SLAs (availability, quality, performance, security, and cost-effectiveness).
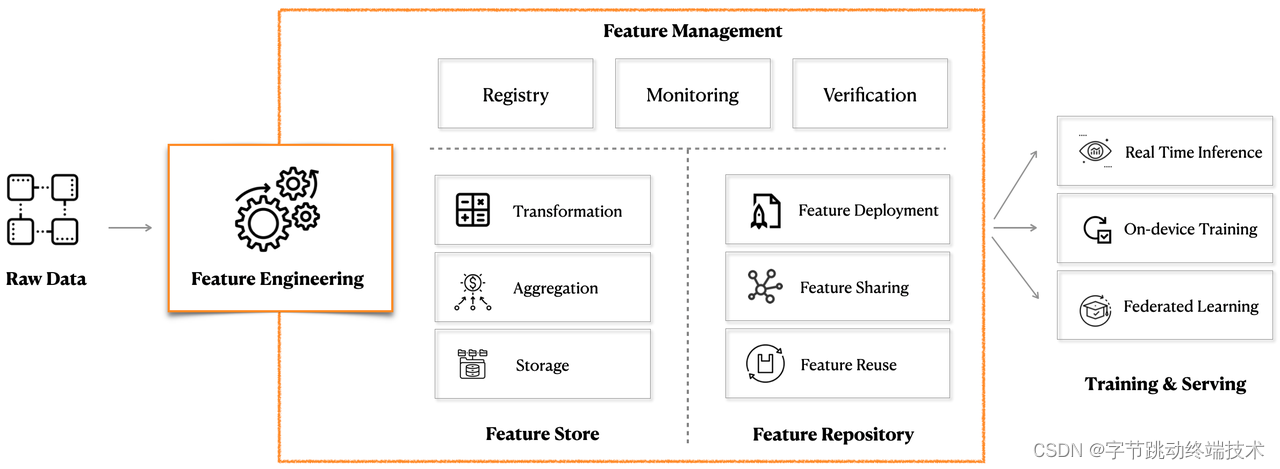
It comprises three main components: Feature Management, Feature Store, and Feature Repository.
Pitaya Feature Store
Pitaya Feature Store is a fully-managed service specialized in extracting, transforming data, engineering ML features, and storing them efficiently on mobile devices for AI and machine learning applications.
For feature processing, it offers configurable, managed, and performant data transformation pipelines, allowing data scientists, ML engineers, and general practitioners to build data integration solutions reliably. The data pipelines can automatically absorb, cleanse, and blend raw data and transform it into usable features based on user-defined configuration without the hassle of struggling with repetitive curation work.
It also includes libraries such as Numpy, MobileCV, and MLOps to satisfy the needs for more complex, custom, or project-specific data processing logic. All integrated libraries are optimized to have less size and better performance for mobile deployment.
For feature storage, there is built-in support for different kinds of highly scalable, available, and consistent feature storage (such as Redis-like KV databases and Hive-like SQLite databases) that can ingest, store, and sync ML features generated on devices.
For feature serving, the Pitaya Feature Store enables easy access to the real-time, constantly updated, and highly consistent data available on databases for analytics, training, and predicting purposes.
Feature data comes from the current device, processes on the device, and directly serves in the device with an almost millisecond-latency, which significantly mitigates the training-serving skew in production and results in the best model performance. The Pitaya Feature Store can further engineer its ingested data into high-level features to support different needs of on-device AI use cases in Computer Vision, Natural Language Processing, Recommendation, et cetera.
Pitaya Feature Repository
Features might be generated by different producers ranging from data engineers in the data teams to business product teams. As the number of features grows exponentially, the system becomes increasingly complex and challenging to maintain, adding extra costs to feature discovery, lineage, and understanding.
To aid this problem, it is critical to pivot to a new way of enabling all internal teams to efficiently share, discover, and reuse ML features at scale, which introduces the requirement for Pitaya Feature Repository, a centralized, performant, compliance-focused data warehouse on the device.
Pitaya Feature Repository is the custodian of the most crucial data on mobile devices. It provides a centralized on-device repository that manages, aggregates, and consolidates data from disparate sources, including Pitaya Feature Store, Cloud Feature Store, and other Streaming sources.
Pitaya Feature Repository is designed to facilitate and accelerate the process of consuming, customizing, sharing, and reusing features. It aims to make features shareable across multiple teams cost-effectively within the organization to reduce duplicate work of re-extracting and wasted overlapping toil, as well as supporting project-specific usage.
Pitaya Feature Repository automates the process of producing, filtering, and aggregating features based on multiple dimensions, such as grouping the features by time windows of different sizes, the application's lifecycle, and even by a custom user-defined session or context.
The aggregated features are stored in a unified form. They can be easily sourced and exported to be used for various purposes, which can increase productivity and feature engineering efficiency significantly.
Feature Management
Pitaya SDK provides a Feature Management service specifically designed for managing and orchestrating on-device features which have immense flexibility and a rich set of input sources.
Feature Management hosts the entire lifecycle of data management from production to consumption. It offers simple administration for data engineers to ensure that data processing pipelines are reliable, sustainable, and trackable.
Feature Management offers the following services:
On-device Feature Monitor: On-device Feature Monitor incorporates integrated monitoring for data flow and quality, which checks for data distribution validation, uniqueness, missingness, and distinctiveness so that features have expected values. The monitor guarantees that data produced by the Feature Store is consistent and in a proper format to alleviate the gap of features between the experimentation and the production environment that may lead to data drift and ultimately worsen the edge ML models on the user's end.
On-device Feature Map: On-device Feature Map provides a central data orchestration system that establishes the data registry and validation rules for both data producers and consumers. It maintains a list of features along with their definitions (feature name and data type), feature group, and metadata (owner, description, SLA, etc.). On-device Feature Map makes it easy for data producers to query, manage, organize and contribute features in the on-device Feature Repository, leading to increased efficiency and guaranteed reproducibility.
4.2.3 Model Serving
Deploying and serving ML models on mobile devices are challenging, as mobile devices have limited memory, less compute resources, and restricted storage.
Under such constraints, supporting the deployment of AI models from different frameworks and optimizing their performance are essential in helping developers run AI models on mobile devices.
Pitaya SDK addressed these challenges with integrated support for high-performance on-device inference engines such as ByteDance's neural network inference engine ByteNN, decision tree inference engine ByteDT, and automated optimizing DL-compiler TVM.
The on-device inference engines that Pitaya SDK currently supports make it possible to house AI and ML capabilities directly on any handheld device, where AI models can be seamlessly deployed and perform low-latency inference. It has empowered numerous use cases with on-device models by providing the following three main features:
Compatibility: It incorporates most of the OP kernels that are widely used in the areas of CV, NLP, and Speech Recognition, allowing for converting AI models from multiple mainstream ML frameworks (e.g., Tensorflow, Pytorch, Caffe, XGBoost, Catboost, LightGBM) into an efficient portable format supported by our on-device Inference Engines. The converted AI models are hyper-optimized with model pruning and quantization to ensure accuracy for a small binary size with low latency and can operate on all Android and iOS devices on the mobile end.
Extensive processor support: It supports a variety of processors (e.g., CPU, GPU, NPU, DSP, CUDA) on the device with automated dispatch strategies based on the hardware and its current resource usage.
High performance: It leverages hardware acceleration on model inference with concurrent processing and low-bit quantization (int8, int16, fp16), enabling AI models to execute efficiently on limited compute and memory resources with improved performance and less energy consumption.
4.3 Pitaya Core Services
4.3.1 Pitaya Monitoring
Pitaya Monitoring provides comprehensive, proactive, and continuous monitoring of the overall stability, success rate, duration, model performance, and business statistics through a set of services.
It offers automatic and intelligent observability throughout on-device AI workflows with real-time dashboard visualizations for you to perform precise root-cause analysis with ease.
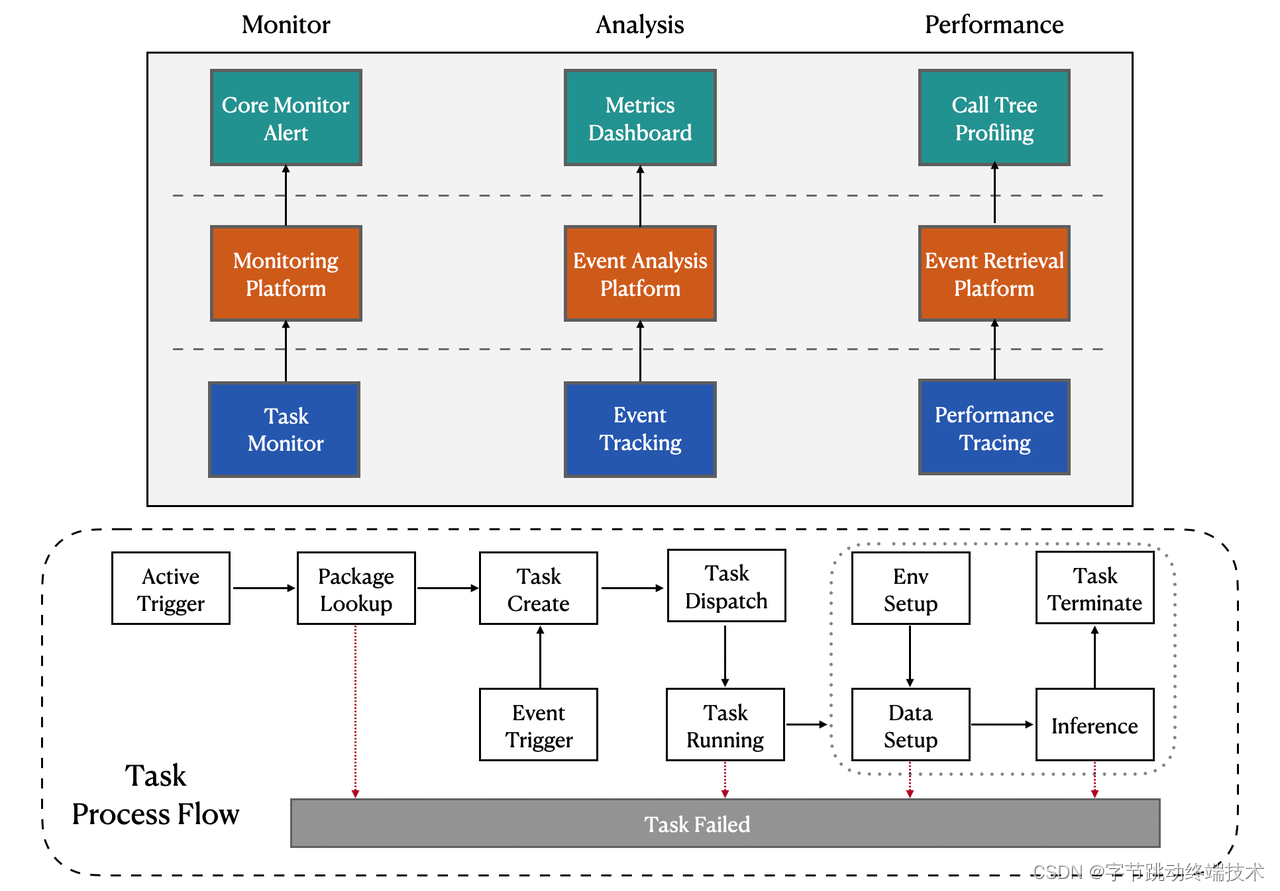
Pitaya Monitoring is equipped with the following services:
Component Monitoring Service: It offers comprehensive, proactive, and continuous monitoring of the overall stability of on-device AI tasks. Component Monitoring Service hosts a runtime probe and can ingest application and custom log data at scale from Pitaya VM to keep tracking of the status, exception, and errors of each AI task. It also includes standard tools such as Task Instrumentation, Error Reporting, and Alert Management, which analyzes and aggregates all the errors and exceptions and can automatically send notifications when the overall error rate surpasses a customized threshold.
Behavior Analysis Service: It collects metrics, logs, and events from Feature Store and Inference Engine to generate ongoing, live measurements of model performance and business statistics of each task.
In the case of model performance, it calculates and combines model metrics like RMSE, MAE, and R square for regression models, as well as accuracy, precision, recall, and AUC for classification models. It also supports publishing the calculated model metrics into an online report, which enables you to analyze and evaluate on-device models over time. In the meantime, you can set up customized alerts using the Alert Management tools mentioned above. They can signal for your model's predictive performance and alert when the signals deviate while diagnosing the cause of the deviation.
In the case of business statistics, it allows you to create and customize real-time dashboards with sophisticated visualization tools to help understand and evaluate the efficacy of on-device business intelligence strategies. It provides visibility into various business metrics, supporting you to deliver superior user experiences confidently.
Performance Tracing service: It provides continuous profiling of resource consumption, latency sampling, and reporting, as well as runtime duration (e.g., preparing, waiting, and operating time) for each on-device AI task. After an AI task with suspicious high latency is reported, it consolidates all related performance data and provides a thorough inspection of its latency by creating a function dependency mapping. The dependency mapping can provide visibility into the detailed latency of each method, helping you identify and eliminate potential performance issues.
4.3.2 Algorithm Package Management
Resource Management
Resource Management is a fully-managed service designed to facilitate seamless deployment, versioning, and iteration of on-device resources, including the ML algorithm package running on mobile devices, along with its ML models and related dependency files. At a high level, it accomplishes three things:
Customized Package Release: Resource Management offers various policies (e.g., an as-needed-basis policy, on manual-control policy) for ML algorithm packages to be deployed on mobile devices to meet the need for different use cases.
Flexible Task Triggering: Resource Management offers multiple kinds of triggers for you to decide when and how to run ML algorithm packages by simply setting a trigger condition in the configuration. It supports triggering ML algorithm packages by specifying a target event, a time scheduler, or at a customized point in time on demand.
Environment Isolation: Resource Management offers an isolated environment for each ML algorithm package to avoid the compatibility problem of running ML packages with different dependencies and versions concurrently. To balance accelerating the task processing speed while keeping the memory consumption at a manageable level, Resource Management automates the caching and releasing of resources for better performance and more minor potential resource leaks.
Task Management
On-device AI leverages the benefits of processing data internally and making predictions directly on mobile devices. It eliminates the need for back-and-forth communication with the cloud, enabling AI models to perform smoothly in real-time without communication and connectivity lags. Due to low latency inference, on-device AI can operate instantaneously at an extremely high frequency to create ML-powered mobile experiences and unlock new real-time interactive use cases such as processing live-streaming video.
Task Management is specifically designed to manage and schedule high-frequency on-device AI tasks with the following features:
High Concurrency: Task Management supports processing AI tasks concurrently with task-level multi-threading and provides an isolated environment for each AI task to execute on the device efficiently.
Circuit-Breaker: Task Management drives a Circuit-breaker measure to guarantee the stability of core ML tasks by suspending the task that continuously fails multiple times or leads to application crashes.
Priority Processing: With AI tasks running at an increased scale and frequency on the mobile device, smartphone processors might not always be able to process AI tasks as fast as they arrive, especially at peak hours, resulting in potential traffic congestion. Task Management adopts a priority processing approach which supports setting a priority for processing AI tasks to ensure the functionalities of core AI-powered applications.
Block Prevention: Task Management supports Block Prevention to dynamically detect and diagnose whether a thread is blocked by tasks that are doing slow operations or stuck in infinite recursion, resulting in a colossal waste of computation resources. Once a blocked thread is detected, Block Prevention will notify the interpreter in the thread to release its tasks and related resources and then reset the runtime environment along with the interpreter to its initial state.
4.3.3 Pitaya Federated Learning
Uploading the raw data with sensitive contents may raise severe security and privacy concerns for users. Storing and processing raw data on the cloud may also suffer from the risk of a data breach.
Pitaya provides a Federated Learning service that allows training AI models without uploading any user privacy data to the cloud servers to help protect and secure users' most sensitive data.
In the case of training a cloud-based model, Pitaya Federated Learning first downloads the base model to mobile devices, improves it with local training data, and then sends only the local updates from local models to the cloud for updating the global cloud model. Pitaya Federated Learning will then apply end-to-end encryption on all data and aggregate them using cryptographic techniques (e.g., differential privacy, Secure multi-party computation) to assure data confidentiality. In other words, all the training data remains on the user's device, and no individual updates are stored in the cloud, therefore maintaining user privacy and security.
In the case of training an on-device model, there is no need to send any data to the cloud since all of the data processing and model training happens on the device itself. On-device models get fine-tuned based on local inputs and thereby optimized to create personalized models for individual users to provide them with ML-powered experiences while keeping data in their hands.
Pitaya Federated Learning also comes with an Automated Scheduling solution that only allows devices that satisfy certain restrictions (e.g., being idle, plugged in, and connected to a wireless network) to be involved in the FL training processing in order to avoid its potential impact on user experiences.
Building on the Pitaya
ByteDance Client AI team has developed the foundations for an end-to-end on-device AI infrastructure Pitaya with a fully-managed platform that manages the entire lifecycle of AI development and a robust SDK integrated with leading on-device Virtual Machine, Feature Engineering, Model Serving, and Monitoring. Pitaya has been deployed in ByteDance for wide-scale production use and serves billion-scale users in Douyin, TikTok, Toutiao, and other applications. There's a great emphasis at ByteDance on continuously making on-device AI techniques better.
In the coming months, we are committed to continuing scaling and hardening the existing AI infrastructure to enhance AI development efficiency. As the Pitaya Platform and SDK mature, we plan to invest in building more general-purpose AI capabilities, making on-device AI universally accessible to support both the growth of our set of customer teams and ByteDance's business overall.
If you have the passion, drive, and experience to explore the possibility of on-device AI, we just might be a great fit for you. We are always looking for great talent to help us make a meaningful impact in this field.
Contact Email: yuanwei.yw@bytedance.com
版权声明: 本文为 InfoQ 作者【字节跳动终端技术】的原创文章。
原文链接:【http://xie.infoq.cn/article/d9a05a40ddbc1b01218f46a0a】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

还未添加个人签名 2021.05.17 加入
字节跳动终端技术团队是大前端基础技术行业领军者,负责整个字节跳动的大前端基础设施建设,提升公司全产品线的性能、稳定性和工程效率,在移动端、Web、Desktop等各终端都有深入研究。









评论