想要年薪 20W+ 吗?看完 Github 上分享的 Java 并发题,面试大厂稳了

今日分享开始啦,请大家多多指教~
unlock 方法
解锁调用的就是 unlock 方法

可以看到其调用的还是内部类 sync 的方法,而且可以看到这是一个无返回值的方法。
并且传入了一个为 1 的参数
release 方法
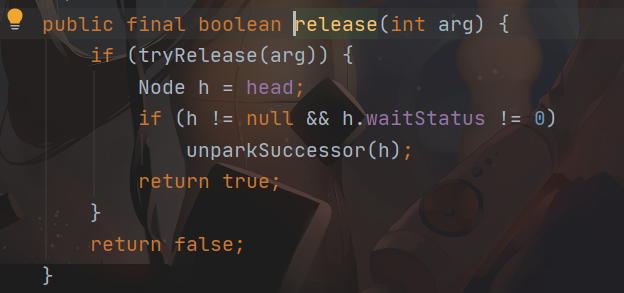
可以看到,其调用的是 AQS 里面的 release 方法
步骤如下:
先调用 tryRelease 方法,尝试进行解锁
然后判断是否需要唤醒线程
返回 true,代表释放锁成功
tryRelease 方法返回 false,表表释放锁失败,返回 false
tryRelease 方法

可以看到这个方法是 AQS 里面的一个未实现的方法,实现这个方法有 ReentrantLock 与 ReentrantReadWriteLock。
所以,具体的实现肯定是 ReentrantLock 的。
实现的源码如下所示
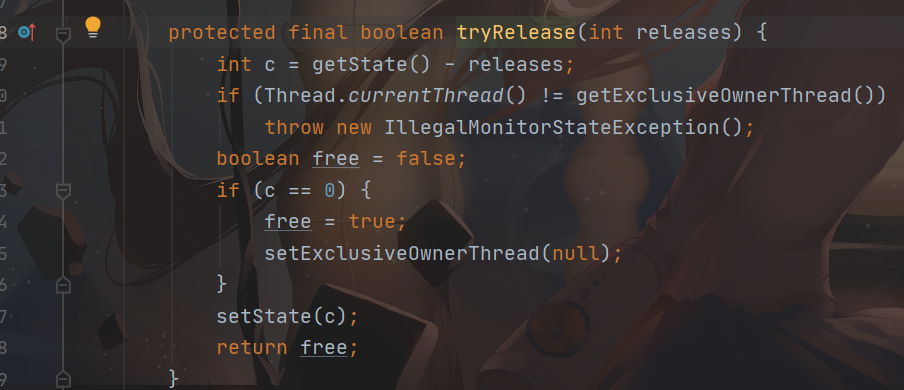
步骤如下:
计算锁被释放后的新状态,记录在变量 c。
判断当前线程是不是拥有锁(如果拥有了锁,在 AbstartOwnableSychronizer 的 exclusiveOwnerThread 会记录,AOS 是被 AQS 所继承的)。
如果不拥有锁就会报错,因为锁并不是自己的,没有资格释放。
定义一个 free 变量看是否锁的新状态是不是变成可被占用了(进入到这一步就证明了当前线程拥有锁)。
判断新的状态是不是为 0。
如果是 0,让 free 变量为 true,并且将锁记录占用自己的线程为 null。
将锁的状态更新(这一步过后,其他线程就可以争夺锁了,因为 ReentrantLock 的状态已经变为了 0)。
返回 free 变量给上一层,告知上一层锁是否不被占用了。
接下来我们返回到 release 方法
下面的判断是这样的
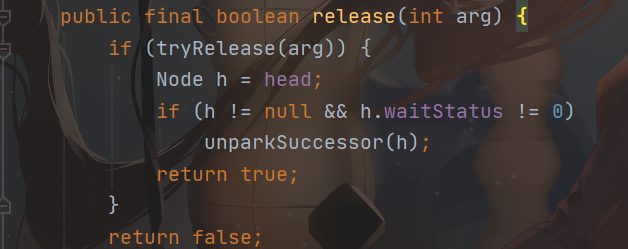
从上面可以看到,如果锁没被占用了,那么 tryRelease 方法就会返回 True,那么就会进行下面的判断:
1.先记录一下当前线程队列的头结点;
2.判断头结点是否不为空,而且 waitStatus 状态是否不为 0(0 代表线程正常运行,-1 代表被挂起)。
如果头结点不为空,代表仍有线程在等待。
如果头结点 waitStatus 不为 0,那就代表后面的线程被挂起了或者取消了(这个操作是针对后面的那些线程等待时间过长,CAS 超过了两次,全部进入了挂起状态)。
所以,接下来的一步就是去唤醒被后面被挂起的线程(前面提到过,队列里面是不存放正在执行的线程的,只存放需要排队的线程,头结点是不放线程的,不过会记录上一个执行线程的状态,因为在获取锁的时候,是将要执行的线程为头结点,然后将头结点里面的 thread 改为了 null,但 waitStatus 是还在的)。
返回 True。
3.如果头结点为空,或者头结点状态为 0。
代表没有线程等待了;
返回 false。
unparkSuccessor 方法
这个方法是唤醒被挂起的头结点,并且还要去整理线程队列。
这个方法也是 AQS 里面的
源码如下
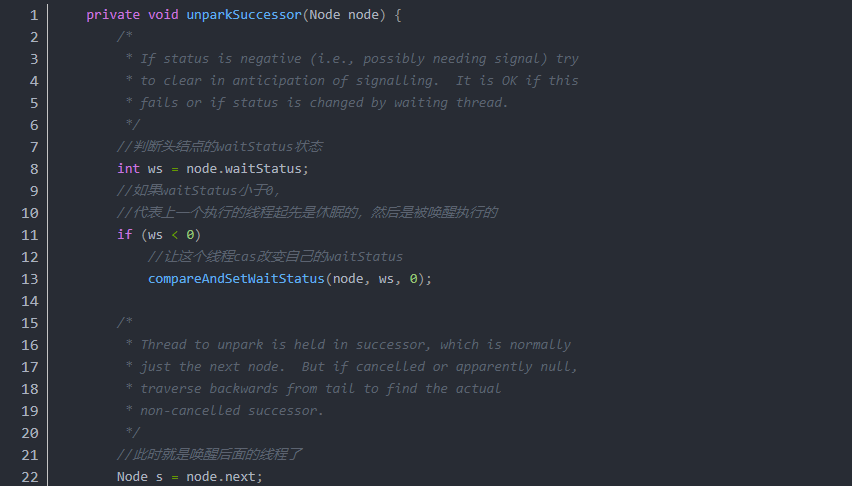
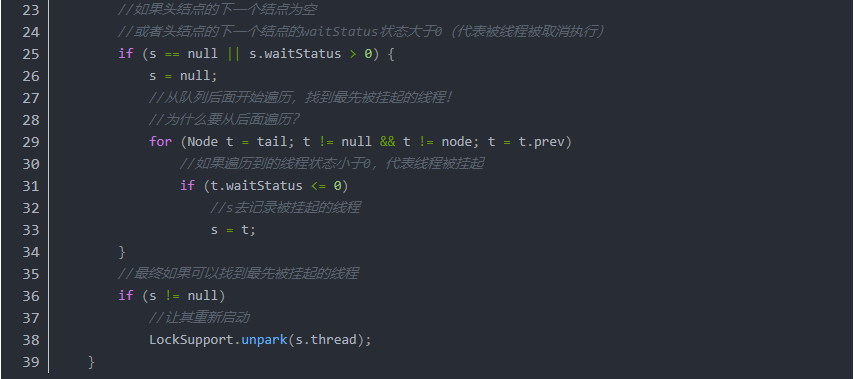
步骤如下
1.判断上一个执行完成的结点的 waitStatus 状态。
如果 waitStatus 状态小于 0,代表上一个线程是被挂起了。
所以将 waitStatus 状态改回 0(这一步是关联上线程抢锁时的 CAS 操作)。
2.接下来,唤醒后面的线程,其实是去获取最先的一个未被取消的线程。
一般这个线程就是头结点的下一个;
但也有可能头结点的下一个被取消了。
此时就要进行遍历,从尾进行遍历整个队列,去找到最先的一个被挂起的线程(不包括新插入进来正在尝试获取锁的线程,也就是状态为 0)。
3.接下来,让最先的一个未被取消的线程重新启动。
这里这样做的原因是,前面提到过,在线程去抢锁的过程中,CAS 第一次时,会认为前面的一个线程被挂起了,将前面线程的 waitStatus 改为-1,CAS 第二次,如果前面的线程仍然为-1,代表前面的线程仍然被挂起(只有在前面的线程释放锁的时候,才会改变 waitStatus 为 0),所以自己也会挂起。
所以,个人认为:如果一个线程执行太久了,后面的线程都被是有可能都被挂起的,那么就需要一个一个去唤醒他,就完全变成了一个重量级锁。
在 Java 里面,锁除了让临界区互斥外,还可以让释放锁的线程向获取同一个锁的线程发送消息。
锁的释放和获取的内存语义
接下来,看一下线程在锁的释放和获取究竟对内存是怎样的操作。
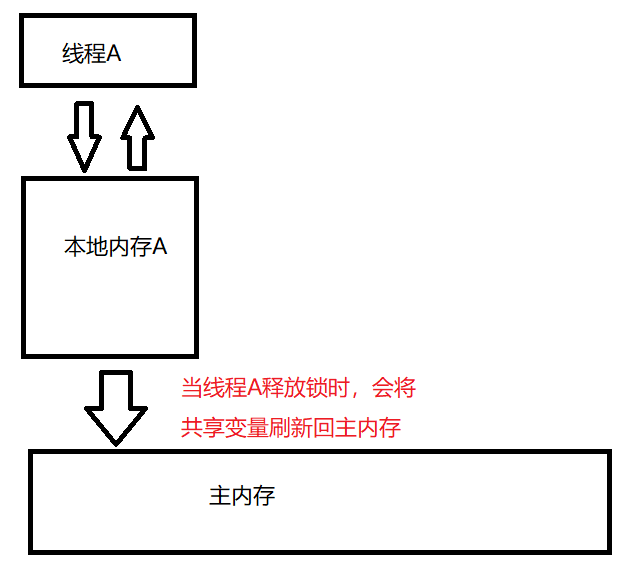
锁的释放
当线程释放锁时,JMM 会把该线程对应的本地内存中的共享变量刷新到主内存中。
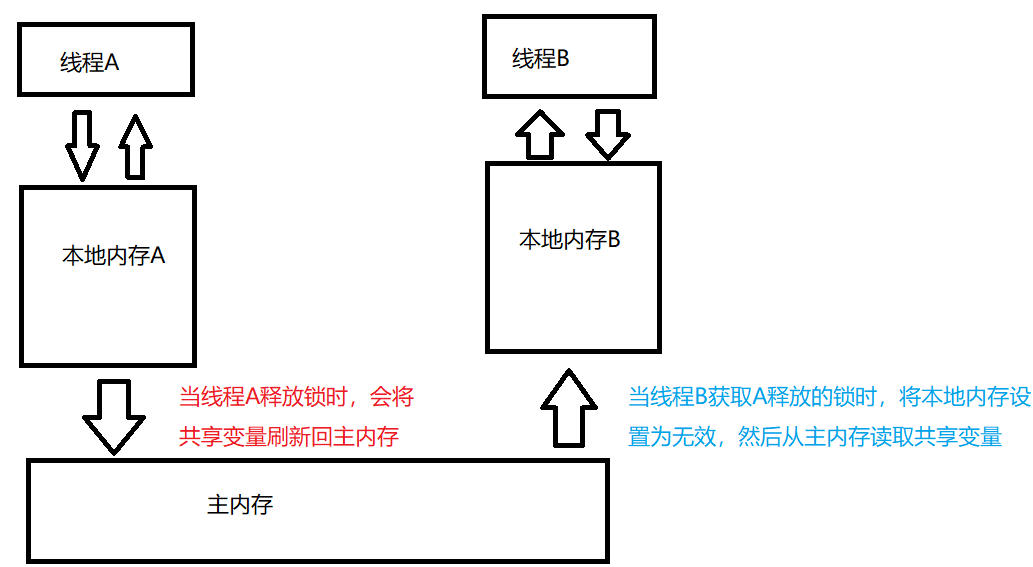
锁的获取
当线程获取锁时,JMM 会把该线程对应的本地内存置为无效,从而使得被监视器 monitor 保护的临界区代码必须从主内存中读取共享变量(前面已经提到过,synchroniced 会在字节码上加上 monitor 与 monitor exit)。
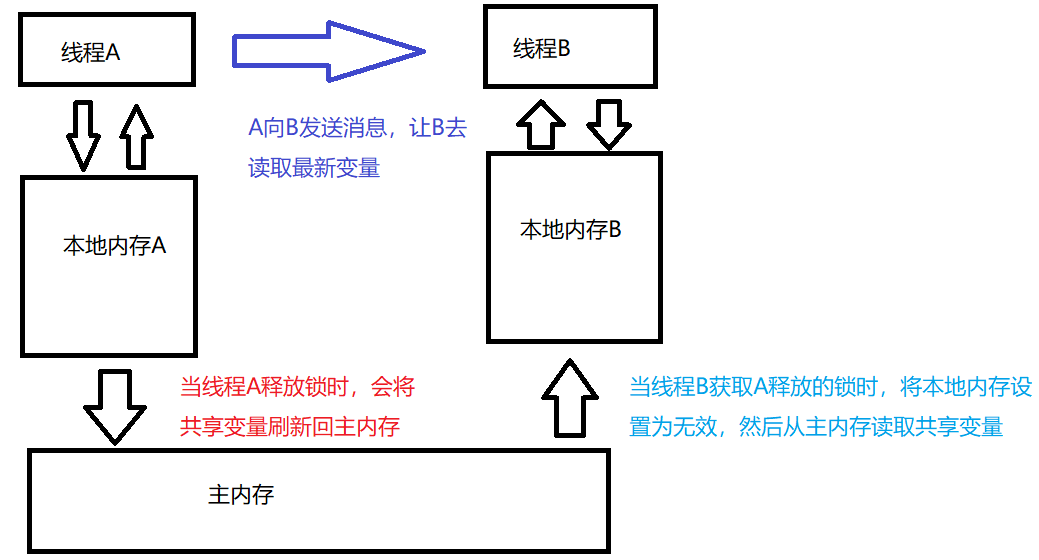
这两个过程相当于线程 A 向线程 B 发送了通信消息,让 B 读取最新的共享变量。
与 volatile 的读写内存语义比较
通过与前面学习的 volatile 的读写内存语义比较:
锁释放与 volatile 的写语义时相同的(立即更新共享变量到主内存);
锁获取与 volatile 的读语义是相同的(本地内存无效,重新读取);
写语义与读语义让线程之间实现了通信;
锁释放与所获取也让线程之间实现了通信。
锁内存语义的实现
锁内存语义的实现其实就是 ReentrantLock 的底层实现。
final 这个修饰可以加在类、方法、变量上
加在类上面是让类不可以被继承,而且里面的方法全部默认为 final 修饰;
加在方法上是让该方法不可以被子类重写;
加在变量上,表示该变量变为常量,而且必须进行初始化。
但其实 final 也是可以解决一些并发重排序问题的。
final 域的重排序规则
final 域也有自己的重排序规则
在构造函数来对一个 final 域进行写入,与之后把这个构造对象的引用赋值给一个引用变量,这两个操作是不可以发生重排序的,即初始化不可以与引用赋值发生重排序,跟 volatile 是一样的。
第一次读一个包含 final 域的对象的引用,与随后初次读这个 final 域,这两个操作之间是不能发生重排序的。
这两个规则分别对应 final 的读写的重排序规则
写 final 域的重排序规则
写 final 域的重排序规则其实就是上面的,初始化不可以与引用赋值发生重排序,必须先初始化,然后再进行引用赋值,但如果对于普通变量来说,也就是普通域,很可能会发生这两个步骤的重排序。
这个规则可以确保,在对象引用为任意线程可见之时,对应的 final 域已经被正确初始化了。
写 final 域的重排序规则是使用内存屏障来实现的。
编译器会在 final 域的写之后,构造函数 return 之前,插入一个 StoreStore 屏障,这个屏障禁止了处理器将 final 域的写命令重排序到 return 之后,也就是构造函数之外。
读 final 域的重排序规则
读 final 域的重排序规则就是,初次读对象引用与初次读对象里面的 final 引用是不可以发生重排序的,必须先读对象引用然后再读 final 引用。
这个规则可以确保,在读一个 final 域之前,一定会先读包含这个 final 域的对象的引用,这是因为 final 域是依赖于对象的。
读 final 域的重排序规则也是使用内存屏障来实现的。
编译器会在都 final 域操作的前面插入一个 LoadLoad 屏障,确保前面如果有初次读对象操作时,要先读对象,然后再读 final 域。
final 域的引用类型
如果 final 域的变量是一个引用类型,那么对于读的重排序规则是没有变的,但写的重排序规则会增加多一条。
在构造函数内对一个 final 引用的对象的成员域写入时,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作是不能重排序的。
即构造函数在初始化 final 引用对象时,构造函数之外的其他地方可能正在修改这个 final 引用对象,那么这两个操作是不可以发生重排序的,也就是一定要先构造函数初始化完 final 引用对象后才可以允许其他地方进行修改。
所以总的 final 域的引用类型的写规则如下:
构造函数里面初始化 final 引用的对象时,不可以被重排序到构造函数外。
构造函数里面初始化 final 引用的对象前,外部不可以对 final 引用的对象进行修改。
为什么 final 引用不能从构造函数内溢出?即发生重排序
我个人觉得,可能是因为 final 的引用每次改变都会成为一个新的对象,所以必须要确保改变是要按照顺序的。
如果从构造函数内溢出,很有可能这个 final 引用还没从构造函数里面初始化好,外面的其他线程就会将其修改,就会导致了顺序扰乱现象。
final 的底层实现
前面已经对此提到过
在读 final 域时,会插入 load-load 屏障;
在写 final 域时,会插入 store-store 屏障。
下面我们来谈一下双重检查锁定与延迟初始化
volatile 解决重排序问题
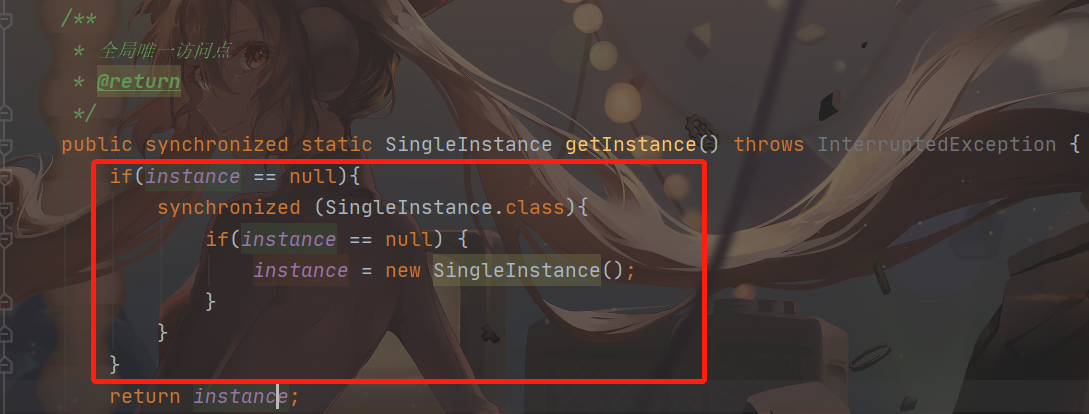
在前面学习懒汉模式实现单例模式的时候,我们已经使用过下面的这一套优化流程了
1.代码块中加锁判断单例对象是否已经初始化。
如果已经初始化,直接返回单例对象。
2.再进行判断多一次单例对象是否已经初始化,来判断单例模式对象是否已经初始化,因为可能同时有多个线程判断出单例对象未初始化,这时上一把锁,让一个线程进去初始化了,初始化了之后,应该再让其他线程再判断一次,看前面一个线程初始化没有(感觉这个方案可以解决一下缓存雪崩)。
如果已经初始化,返回单例对象。
3.给单例对象加 volatile 修饰,防止其构造指令出现重排序。
代码如下(instance 记得要被 volatile 修饰)
类初始化解决重排序问题
上面使用 volatile 可以解决重排序问题,在这里也是可以用类来解决重排序问题的。
JVM 在类的初始化阶段时,即在 Class 被加载后,且正在被线程使用之前,会执行类的初始化(初始化静态变量),在执行类的初始化期间,JVM 会去获取一个锁,这个锁可以同步多个线程对同一个类的初始化,总的来说,就是利用类的初始化这个机制,让实例变量初始化的时候可以发生重排序,但其他线程看不到这个重排序,必须要等待完成整个类初始化过程才可以被访问这个类。
还是以单例模式为例
要用类初始化来实现单例模式,其实就是使用静态内部类
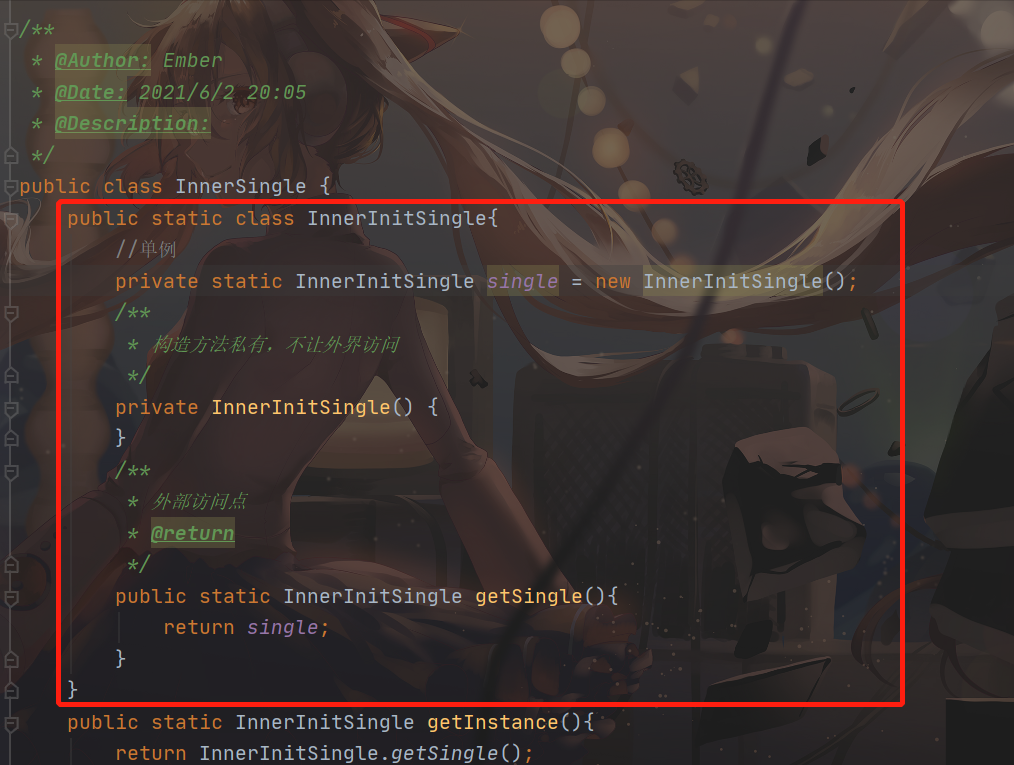
当多个线程调用 getInstance 时候,会发生阻塞(JVM 获得锁),只有一个线程可以去加载初始化这个 InnerSIngle 类,然后该线程初始化里面的 single 静态变量。
类初始化过程中的同步机制
下面来看一下 JVM 是怎么保证类初始化过程中的同步
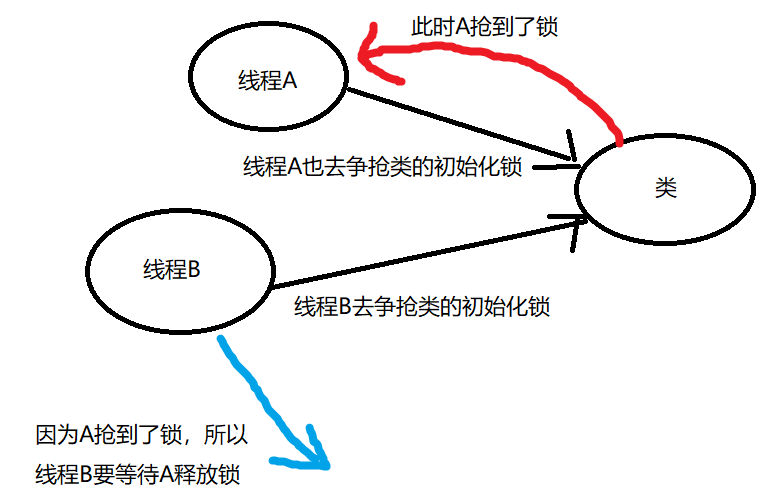
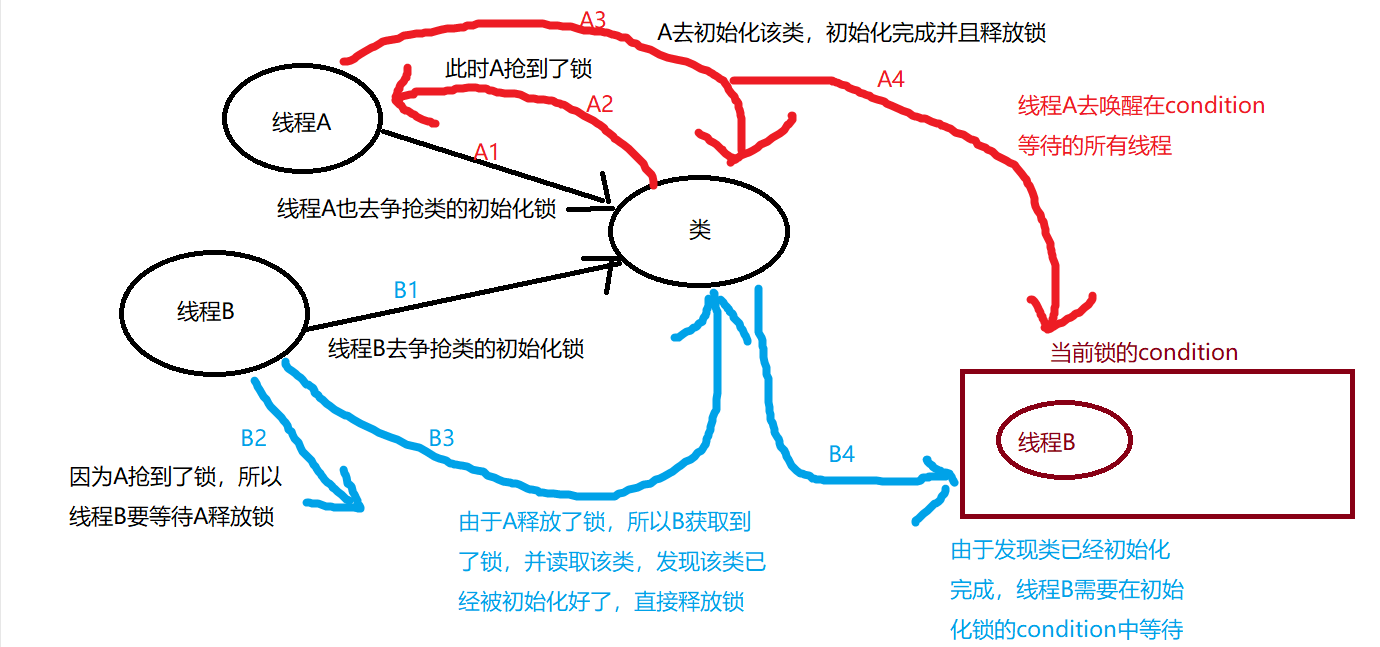
第一阶段
第一阶段是:通过在 Class 对象上进行同步(即获取 Class 对象的初始化锁),来控制类或者接口的初始化,当多个线程初始化同一个类的时候,只有一个线程可以获得这个 Class 对象的初始化锁,其他线程会一直等待获取锁的线程去释放锁。
第二阶段
第二阶段是:抢到类的初始化锁的线程去执行初始化,未抢到锁的线程在初始化锁对应的 condition 上等待,相当于是等待抢到类的初始化锁的线程去完成初始化动作。
初始化的动作先简单理解成是执行类的静态初始化代码和初始化类中声明的静态字段,底层方面的知识是涉及到 JVM 相关知识的。
过程如下所示
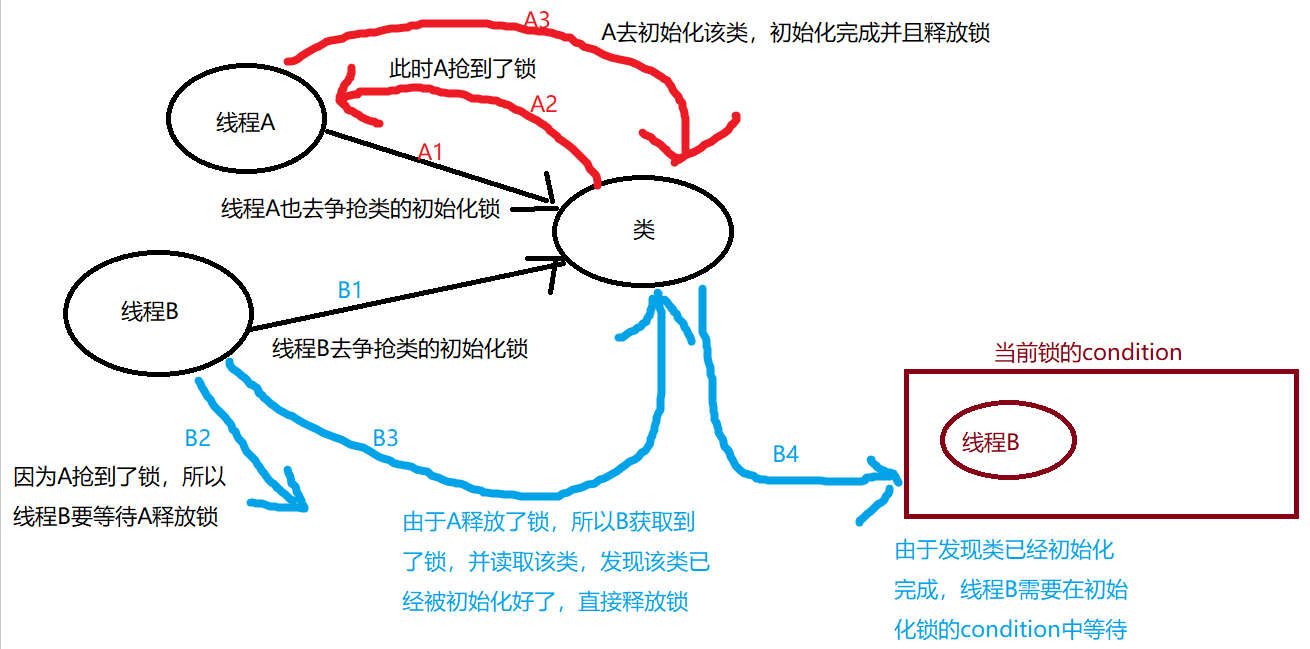
第三阶段
第三阶段是:获取到锁的线程去唤醒在 condition 中等待的所有线程,提醒这些线程,类已经初始化好了。
第四阶段
第四阶段是:被唤醒的线程结束自己对类的初始化处理。
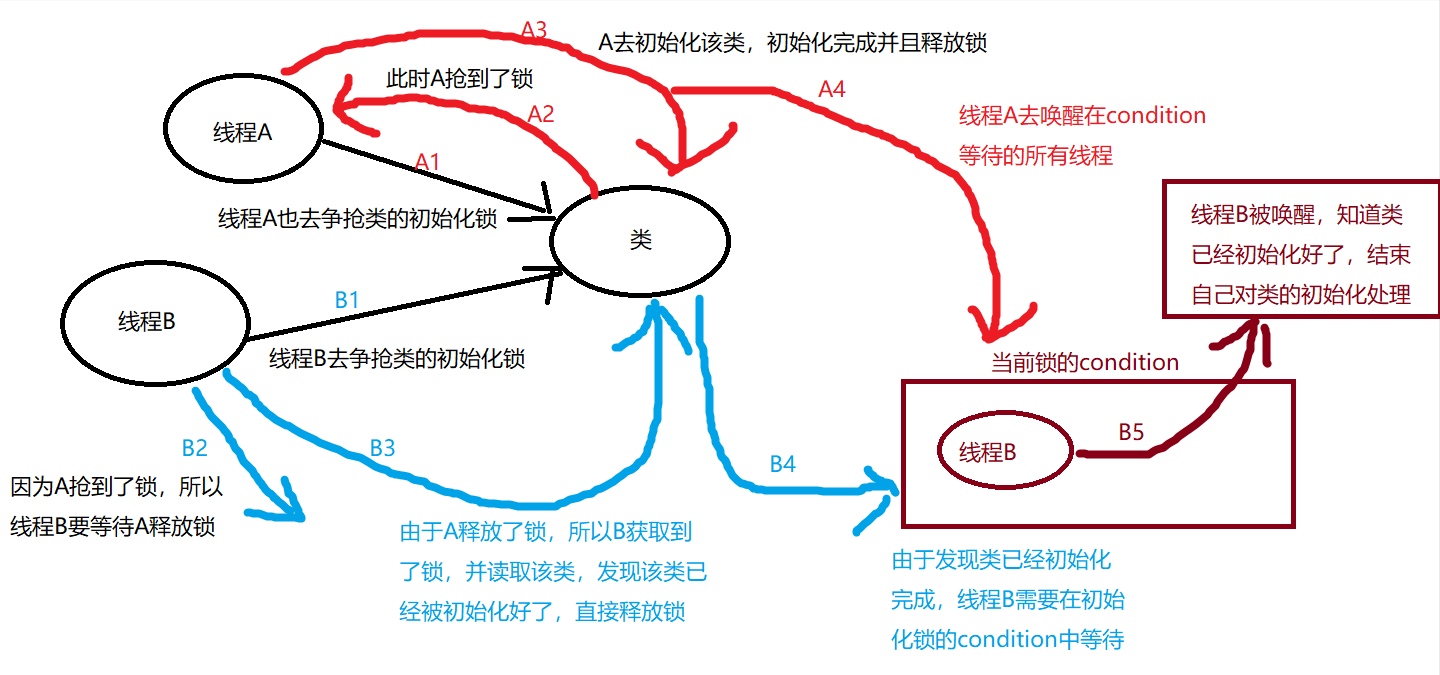
第五阶段
第五阶段是:后面的线程如果再对类进行初始化,那么只会简单地获取锁,发现已经被初始化好了,释放锁,直接获取类。
volatile 与类初始化的两个方案之间存在什么区别?
区别如下
类初始化的代码比较简单、间接;
不过类初始化只能针对静态字段来实现延迟初始化;
volatile 不仅可以针对静态字段实现延迟初始化,还可以针对实例字段来实现延迟初始化。
今日份分享已结束,请大家多多包涵和指点!

还未添加个人签名 2021.04.20 加入
Java工具与相关资料获取等WX: pfx950924(备注来源)









评论