阿里大规模业务混部下的全链路资源隔离技术演进

作者:钱君、南异
审核 &校对:溪洋、海珠
编辑 &排版:雯燕
混部顾名思义,就是将不同类型的业务在同一台机器上混合部署起来,让它们共享机器上的 CPU、内存、IO 等资源,目的就是最大限度地提高资源利用率,从而降低采购和运营等成本。
2014 年,阿里开始了第一次探索混部,经过七年磨练,这把将资源利用率大幅提升的利剑正式开始商用。
通过计算资源、内存资源、存储资源、网络资源等全链路的隔离以及毫秒级的自适应调度能力,阿里可以在双十一的流量下进行全时混部,通过智能化的决策与运维能力,支撑着内部百万级的 Pod 混部,不管是 CPU 与 GPU 资源,普通容器与安全容器,包括国产化环境各种异构基础设施,都能实现高效混部,这让阿里核心电商业务生产集群成本下降了 50% 以上,同时让核心业务受到的干扰小于 5%。
针对云原生时代的资源效能提升问题,我们将基于大规模场景下的混部实践推出系列文章,详细介绍并分享关于混部技术的细节,及大规模生产中碰到的种种落地的实际问题。作为系列开篇,本篇文章将介绍资源隔离技术在混部中的重要性、其落地挑战及我们的应对思路。
混部和资源隔离之间的关系:资源隔离是混部的基石
混部通常是将不同优先级的任务混合在一起,例如高优先级的实时任务(对时延敏感,资源消耗低;称为在线)和低优先级的批处理任务(对时延不敏感,资源消耗高;称为离线),当高优先级业务需要资源时,低优先级任务需要立即归还,并且低优先级任务的运行不能对高优先级任务造成明显干扰。
为了满足混部的需求,在单机维度的内核资源隔离技术是最为关键的一项技术,阿里云在内核资源隔离技术上深耕多年,积累了许多业界领先的经验,我们将这些内核资源隔离技术主要涉及的范围概括为内核中的调度、内存和 IO 这三大子系统,并且在各个子系统领域根据云原生的混部场景进行了深入的改造和优化,包括 CPU Group Identity、SMT expeller、基于 Cgroup 的内存异步回收等。这些关键的技术使客户有能力在云原生混部场景中根据业务特点给出最优解决方案,有效提高用户的资源使用率并降低用户资源的使用成本,非常适用于容器云混部场景,同时也是大规模化混合部署方案所强依赖的关键技术。
下图是资源隔离能力在整个混部方案中的位置:
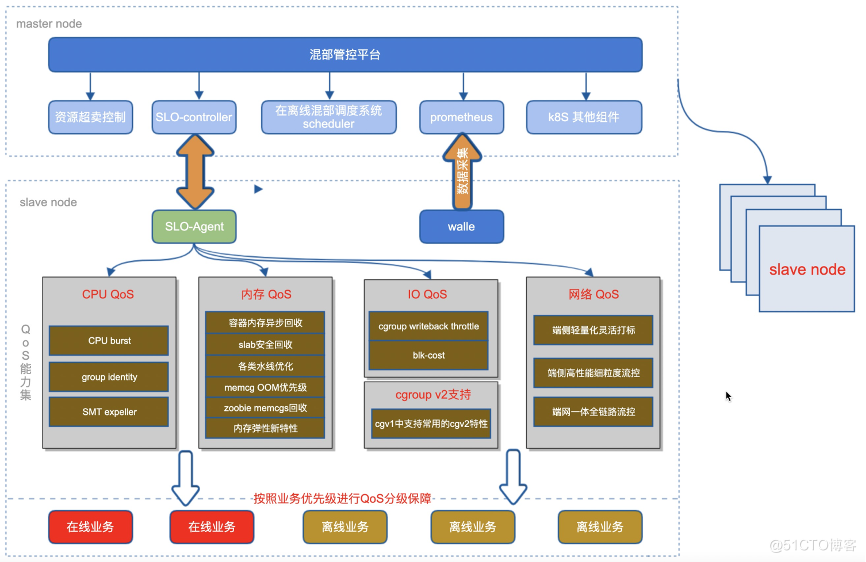
为什么需要资源隔离,资源隔离会遇到哪些拦路虎
假设我们现在有一台服务器,上面运行了高优的在线业务以及离线任务。在线任务对响应时间 (Response Time, RT) 的需求是很明确的,要求尽可能低的 RT,故被称之为延迟敏感型 (Latency-Sensitive, LS) 负载;离线任务永远是有多少资源吃多少资源的,故此类负载被称之为 Best Effort (BE)。如果我们对在线和离线任务不加干涉,那么离线任务很有可能会频繁、长期占用各种资源,从而让在线任务没有机会调度,或者调度不及时,或者获取不到带宽等等,从而出现在线业务 RT 急剧升高的情况。所以在这种场景下我们需要必要的手段来对在线和离线容器进行资源使用上的隔离,来确保在线高优容器在使用资源时可以及时地获取,最终能够在提升整体资源使用率的情况下保障高优容器的 QoS。
下面让我们一起看看在线和离线混跑时可能出现的情况:
首先,CPU 是最有可能面对在离线竞争的,因为 CPU 调度是核心,在线和离线任务可能分别会调度到一个核上,相互抢执行时间;
当然任务也可能会分别跑到相互对应的一对 HT 上,相互竞争指令发射带宽和其他流水线资源;
接下来 CPU 的各级缓存必然是会被消耗掉的,而缓存资源是有限的,所以这里涉及到了缓存资源划分的问题;
即使我们已经完美解决了各级缓存的资源划分,问题仍然存在。首先内存是 CPU 缓存的下一级,内存本身也类似,会发生争抢,不论在线或离线任务,都是需要像 CPU 缓存一样进行内存资源划分的;
另外当 CPU 最后一级缓存 (Last Level Cache, LLC) 没有命中的时候,内存的带宽(我们称之为运行时容量,以有别于内存大小划分这种静态容量)会变高,所以内存和 CPU 缓存之间的资源消耗,是相互影响的;
假设 CPU 和内存资源都没问题,对于本机来说现在隔离已经做得很好了,但是在线高优的业务和离线任务的运行过程中都是和网络有密切的关系,那么很容易理解,网络也可能是需要隔离的;
最后,线上部分机型对 IO 的使用可能会发生抢占,我们需要有效的 IO 隔离策略。
以上就是一个很简单的资源隔离流程的思路,可以看到每一环都有可能会出现干扰或者竞争。
隔离技术方案介绍:独有的隔离技术方案,各显神通
内核资源隔离技术主要涉及内核中的调度、内存和 IO 这三大子系统,这些技术基于 Linux Cgroup V1 提供资源的基本隔离划分以及 QoS 保障,适用于容器云场景,同时也是大规模化混合部署方案所强依赖的关键技术。
除了基本的 CPU、内存和 IO 资源隔离技术外,我们也研发了资源隔离视图、资源监控指标 SLI (Service Level Indicator) 以及资源竞争分析等配套工具,提供包括监控、告警、运维、诊断等在内的整套资源隔离和混部解决方案,如下图所示:
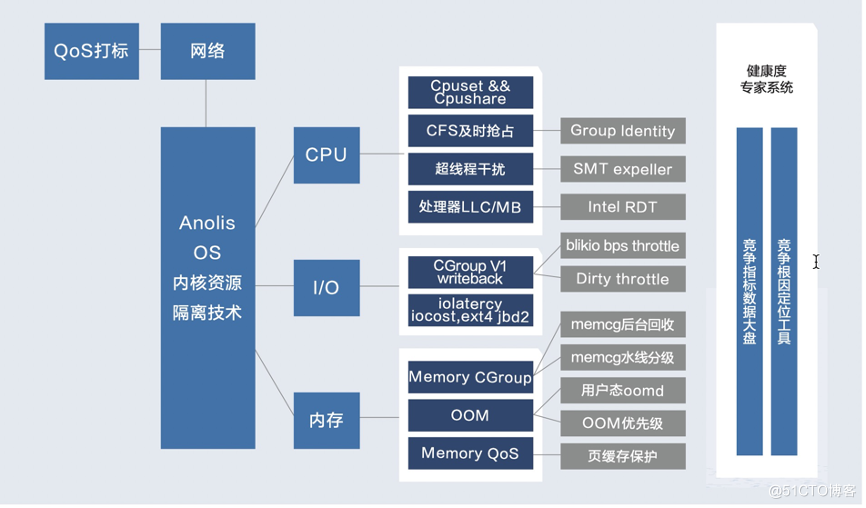
弹性容器场景的调度器优化
如何保证计算服务质量的同时尽可能提高计算资源利用率,是容器调度的经典问题。随着 CPU 利用率不断提升,CPU 带宽控制器暴露出弹性不足的问题日趋严重,面对容器的短时间 CPU 突发需求,带宽控制器需要对容器的 CPU 使用进行限流,避免影响负载延迟和吞吐。
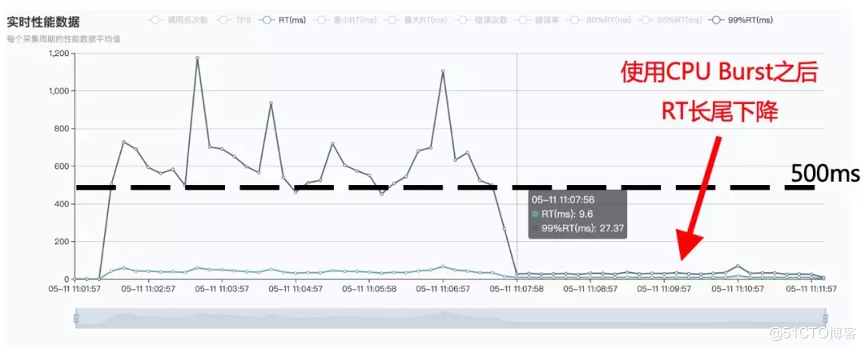
CPU Burst 技术最初由阿里云操作系统团队提出并贡献到 Linux 社区和龙蜥社区,分别在 Linux 5.14 和龙蜥 ANCK 4.19 版本被收录。它是一种弹性容器带宽控制技术,在满足平均 CPU 使用率低于一定限制的条件下,CPU Burst 允许短时间的 CPU 突发使用,实现服务质量提升和容器负载加速。
在容器场景中使用 CPU Burst 之后,测试容器的服务质量显著提升,如下图所示,在实测中可以发现使用该特性技术以后,RT 长尾问题几乎消失。
Group Identity 技术
为了满足业务方在 CPU 资源隔离上的需求,需要在满足 CPU 资源利用最大化的情况下,保证高优业务的服务质量不受影响,或将影响范围控制在一定范围内。此时内核调度器需要赋予高优先级的任务更多的调度机会来最小化其调度延迟,并把低优先级任务对其带来的影响降到最低,这是行业中通用的需求。
在这样的背景下,我们引入了 Group Identity 的概念,即每个 CPU Cgroup 会有一个身份识别,以 CPU Cgroup 组为单位实现调度特殊优先级,提升高优先级组的及时抢占能力确保了高优先级任务的性能,适用于在线和离线混跑的业务场景。当在离线混部时,可以最大程度降低由于离线业务引入的在线业务调度不及时的问题,增加高优先业务的 CPU 抢占时机等底层等核心技术保障在线业务在 CPU 调度延迟上不受离线业务的影响。
SMT expeller 技术
在某些线上业务场景中,使用超线程情况下的 QPS 比未使用超线程时下降明显,并且相应 RT 也增加了不少。根本原因跟超线程的物理性质有关,超线程技术在一个物理核上模拟两个逻辑核,两个逻辑核具有各自独立的寄存器(eax、ebx、ecx、msr 等等)和 APIC,但会共享使用物理核的执行资源,包括执行引擎、L1/L2 缓存、TLB 和系统总线等等。这就意味着,如果一对 HT 的一个核上跑了在线任务,与此同时它对应的 HT 核上跑了一个离线任务,那么它们之间是会发生竞争的,这就是我们需要解决的问题。
为了尽可能减轻这种竞争的影响,我们想要让一个核上的在线任务执行的时候,它对应的 HT 上不再运行离线任务;或者当一个核上有离线任务运行的时候,在线任务调度到了其对应的 HT 上时,离线任务会被驱赶走。听起来离线混得很惨对不对?但是这就是我们保证 HT 资源不被争抢的机制。
SMT expeller 特性是基于 Group Identity 框架进一步实现了超线程 (HT) 隔离调度,保障高优先级业务不会受到来自 HT 的低优先级任务干扰。通过 Group Identity 框架进一步实现的超线程调度隔离,可以很好保障高优先级业务不会受到来自对应 HT 上的低优先级任务的干扰。
处理器硬件资源管理技术
我们的内核架构支持 Intel®Resource Director Technology(Intel®RDT),它是一种处理器支持的硬件资源管理技术。包括监控 Cache 资源的 Cache Monitoring Technology (CMT) ,监控内存带宽的 Memory Bandwidth Monitoring (MBM),负责 Cache 资源分配的 Cache Allocation Technology(CAT) 和监控内存带宽的 Memory Bandwidth Allocation(MBA)。
其中,CAT 使得 LLC(Last Level Cache) 变成了一种支持 QualityofService(QoS) 的资源。在混部环境里面,如果没有 LLC 的隔离,离线应用不停的读写数据导致大量的 LLC 占用,会导致在线的 LLC 被不断污染,影响数据访问甚至硬件中断延迟升高、性能下降。
MBA 用于内存带宽分配。对于内存带宽敏感的业务来说,内存带宽比 LLC 控制更能影响性能和时延。在混部环境里面,离线通常是资源消耗型的,特别是一些 AI 类型的作业对内存带宽资源的消耗非常大,内存占用带宽一旦达到瓶颈,可能使得在线业务的性能和时延成倍的下降,并表现出 CPU 水位上升。
Memcg 后台回收
在原生的内核系统中,当容器的内存使用量达到上限时,如果再申请使用内存,则当前的进程上下文中就会进行直接内存回收的动作,这无疑会影响当前进程的执行效率,引发性能问题。那我们是否有方法当容器的内存达到一定水线的时候让其提前进行内存的异步回收?这样就有比较大的概率避免容器内的进程在申请使用内存时由于内存使用达到上限而进入直接内存回收。
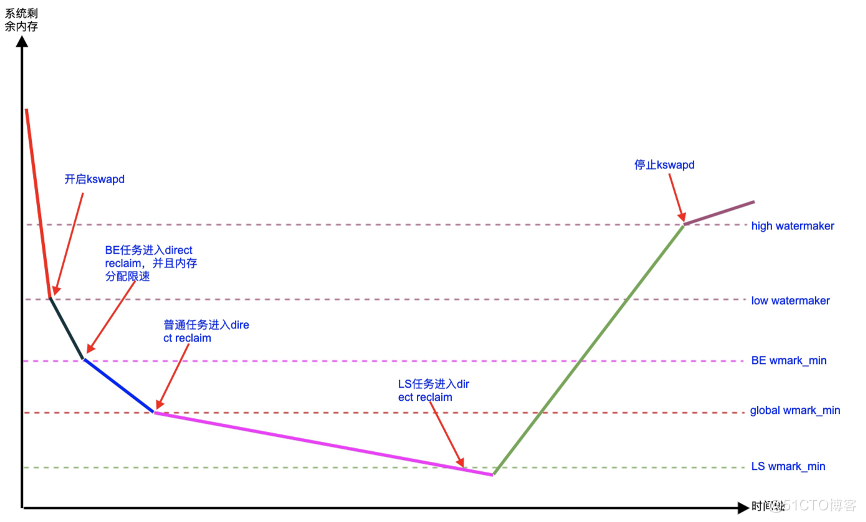
我们知道在内核中有一个 kswapd 的后台内核线程,用来当系统的内存使用量达到一定水位以后来进行异步的内存回收。但是这里有一种情况,比如当前高优业务容器的内存使用已经达到一个比较紧张的状态,但是宿主机总体的空闲内存还有很多,这样内核的 kswapd 的线程就不会被唤醒进行内存回收,导致这些内存使用压力大的高优容器的内存没有机会被回收。这是个比较大的矛盾。由于目前原生内核中没有 memory Cgroup 级别的内存异步回收机制,也就是说容器的内存回收严重依赖宿主机层面的 kswapd 的回收或者只能依靠自己的同步回收,这会严重影响一些高优容器的业务性能。
基于以上背景,阿里云操作系统团队提供了一个类似宿主机层面的 kswapd 的基于 Memcg 的异步回收策略,可以根据用户需求提前进行容器级别的内存回收机制,做到提前内存释压。
具体的异步回收过程可以通过下面这幅图进行描述:
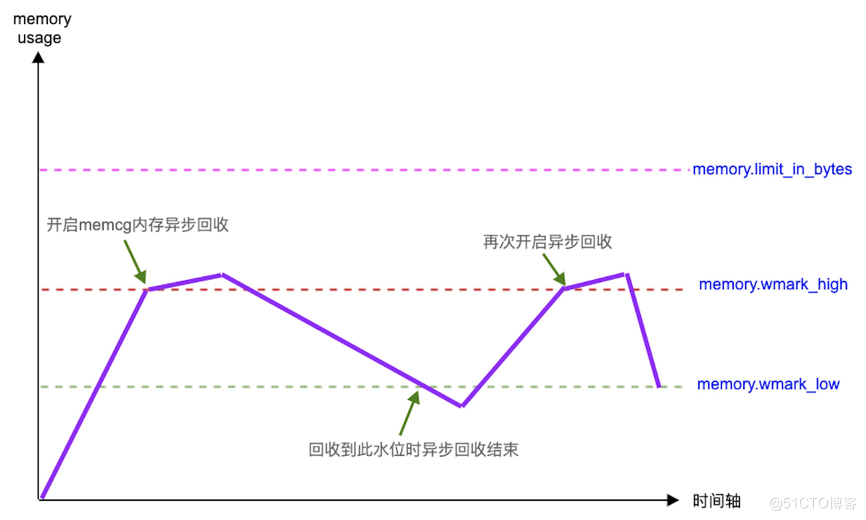
Memcg 全局水位线分级
通常资源消耗型的离线任务时常会瞬间申请大量的内存,使得系统的空闲内存触及全局 min 水线,引发系统所有任务进入直接内存回收的慢速流程,这时时延敏感型的在线业务很容易发生性能抖动。此场景下,无论是全局 kswapd 后台回收还是 Memcg 级别的后台回收机制,都是无能为力的。
我们基于 "内存消耗型的离线任务通常对时延不敏感" 这样一个事实,设计了 "Memcg 的全局 min 水线分级功能" 来解决上述抖动难题。在标准 upstream 全局共享 min 水线的基础上,将离线任务的全局 min 水线上移让其提前进入直接内存回收,同时将时延敏感的在线任务的全局 min 水线下移,在一定程度上实现了离线任务和在线任务的 min 水线隔离。这样当离线任务瞬间大量内存申请的时候,会将离线任务抑制在其上移的 min 水线,避免了在线任务发生直接内存回收,随后当全局 kswapd 回收一定量的内存后,离线任务的短时间抑制得以解除。
核心思想是通过为在离线容器设置不同标准的全局水位线来分别控制其申请内存的动作,这样能让离线容器的任务在申请内存时先与在线业务进入直接内存回收,解决离线容器瞬间申请大量内存引发的问题。
对 Linux 内存管理有一定基础的同学也可以查阅下面这幅图,详细记录了在离线容器混部过程中多种水位线作用下的走势:
Memcg OOM 优先级
在真实的业务场景中,特别是内存超卖环境,当发生 Global OOM 的时候,有理由去选择杀掉那些优先级比较低的离线业务,而保护高优先级在线业务;当发生离线 Memcg OOM 的时候,有理由去选择杀掉那些优先级比较低的作业,而保高优先级离线作业。这其实是云原生场景中一个比较通用的需求,但是目前的标准 Linux 内核并不具备这个能力。在选择杀进程的时候,内核会有一个算法去选择 victim,但通常是找一个 OOM score 最大的进程杀,这个被杀的进程有可能是在线高优业务进程,这并不是我们想看到的。
基于以上原因,阿里云操作系统团队提供了一个 Memcg OOM 优先级的特性,通过该特性我们可以保障在系统由于内存紧张而发生 OOM 时通过选择低优的业务进程进行 Kill,从而避免高优业务进程被杀的可能,可以大幅降低由于在线业务进程退出而给客户业务带来的影响。
CgroupV1 Writeback 限流
Block IO Cgroup 自合入内核之后,一直存在一个问题,就是只能对 Direct IO 进行限流 (buffer IO 之后短期内执行 fsync 也可以限流),因为这些 IO 到达 Block Throttle 层时,当前进程就是真正发起 IO 的进程,根据进程可以获取到相应的 Cgroup 从而正确记账,如果超过了用户设置的带宽 /IOPS 上限,则进行限制。对于那些 buffer 写,且最终由 kworker 线程下发的 IO,Block Throttle 层无法通过当前进程获取 IO 所属的 Cgroup,也就无法对这些 IO 进行限流。
基于以上背景,目前在 Cgroup V2 版本中已经支持异步 IO 限流,但是在 Cgroup V1 中并不支持,由于目前在云原生环境下主要还是使用 Cgroup V1 版本,阿里云操作系统团队通过建立 Page <-> Memcg <-> blkcg 这三者的关系实现了在 Cgroup V1 中对 IO 异步限流的功能,限流的主要算法基本上和 Cgroup V2 保持一致。
blk-iocost 权重控制
正常情况下,为了避免一个 IO 饥饿型作业轻易耗尽整个系统 IO 资源,我们会设置每个 Cgroup 的 IO 带宽上限,其最大缺点是即使设备空闲,配置上限的 Cgroup 在其已发送 IO 超过上限时不能继续发送 IO,引起存储资源浪费。
基于以上需求,出现了一种 IO 控制器 - IOCOST,该控制器是基于 blkcg 的权重来分配磁盘的资源,可以做到在满足业务 IO QOS 的前提下,尽最大程度利用磁盘的 IO 资源,一旦出现磁盘 IO 能力达到上限导致触及 QOS 设置的目标时,此时 iocost 控制器会通过权重来控制各个 group 的 IO 使用,在此基础上,blk-iocost 又拥有一定的自适应能力,尽可能的避免磁盘能力被浪费。
展望与期待
以上所有这些的资源隔离能力目前已经完全贡献给了龙蜥社区,相关源码可以参考 ANCK(Anolis Cloud Kernel),有兴趣的同学可以关注龙蜥社区:https://openanolis.cn/
同时,阿里云容器服务团队也正在与操作系统团队合作,通过阿里云容器服务 ACK 敏捷版及 CNStack(CloudNative Stack) 产品家族对外输出,持续落地 ACK Anywhere,为更多企业赋能。在商用化版本里,我们将完全基于云原生社区标准,以插件化的方式无缝的安装在 K8s 集群为输出形态线下交付客户。其中核心的 OS 层隔离能力,已经发布到支持多架构的开源、中立、开放的 Linux 操作系统发行版-龙蜥(Anolis OS)中。
近期,阿里云混部核心技术系列文章将陆续分享关于 CPU Brust 技术实践、内核资源隔离之 CPU 相关隔离/内存相关隔离/IO 相关隔离/网络相关隔离等内容,敬请持续关注!
👇👇点击此处,即可查看容器服务 ACK 产品详情!
了解更多相关信息,请扫描下方二维码或搜索微信号(AlibabaCloud888)添加云原生小助手!获取更多相关资讯!


阿里巴巴云原生 2019.05.21 加入
还未添加个人简介









评论