
[数据分析]- 音频分析 -BirdCLE-1
![[数据分析]-音频分析-BirdCLE-1](https://static001.geekbang.org/infoq/8e/8e1038cb8c41f18698c91005693b8740.jpeg)
数据背景
作为“世界灭绝之都”,夏威夷已经失去了 68%的鸟类物种,其后果可能会损害整个食物链。研究人员利用种群监测来了解本地鸟类对环境变化和保护措施的反应。但岛上的许多鸟类都被隔离在难以接近的高海拔栖息地。由于身体监测困难,科学家们转向了声音记录。这种被称为生物声学监测的方法可以为研究濒危鸟类种群提供一种被动的、低成本的、经济的策略。目前处理大型生物声学数据集的方法涉及对每个记录的手工注释。这需要专门的训练和大量的时间。因此使用机器学习技能,通过声音来识别鸟类的种类,可以节约大量成本。具体来说,开发一个模型,可以处理连续的音频数据,然后从声音上识别物种。最好的条目将能够用有限的训练数据训练可靠的分类器。

数据介绍
数据集来源:https://www.kaggle.com/competitions/birdclef-2022/data
下载方式:https://github.com/Kaggle/kaggle-apikaggle competitions download -c birdclef-2022
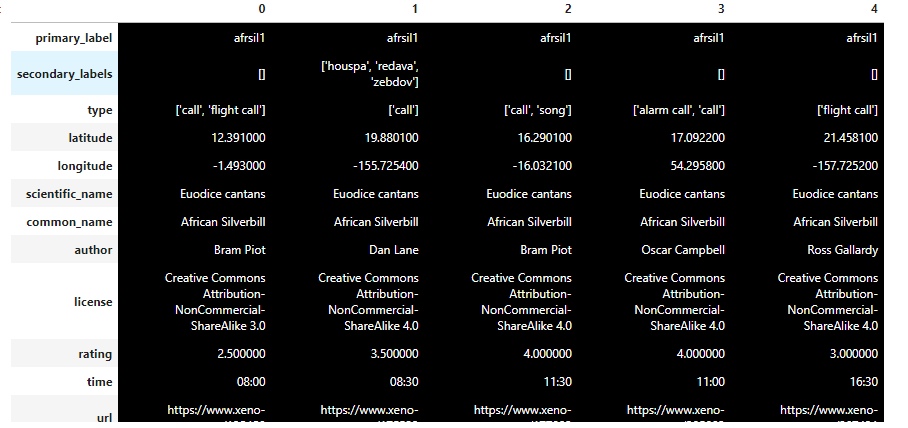
train_metadata.csv:为训练数据提供了广泛的元数据primary_label -鸟类的编码。可以通过将代码附加到 https://ebird.org/species/来查看有关鸟类代码的详细信息,例如美国乌鸦的代码添加到 https://ebird.org/species/amecro
secondary_labels: 记录员标注的背景物种,空列表并不意味着没有背景鸟的声音。
author - 提供录音的 eBird 用户
Filename:关联音频文件。
rating: 浮动值在 0.0 到 5.0 之间,作为 Xeno-canto 的质量等级和背景物种数量的指标,其中 5.0 是最高的,1.0 是最低的。0.0 表示此记录还没有用户评级。
train_audio:大量的训练数据由 xenocanto.org 的用户慷慨上传的单个鸟类叫声的短录音组成。这些文件已被下采样到 32khz,适用于匹配测试集的音频,并转换为 ogg 格式。test_soundscapes:当您提交一个笔记本时,test_soundscapes 目录将填充大约 5500 段录音,用于评分。每一个都是 1 分钟几毫秒的 ogg 音频格式,并只有一个音景可供下载。test.csv:测试数据row_id:行的唯一标识符。
file_id:音频文件的唯一标识符。
bird :一行的 ebird 代码。每个音频文件每 5 秒窗口有一排为每个得分物种。
end_time:5 秒时间窗口(5、10、15 等)的最后一秒。
数据分析
文章从以下几个方面展开
了解每个数据集,使用简单模型检查哪些特征是重要特征。
了解音频数据
转换音频数据并设计数据加载器来处理它们
设计一个模型并通过引入各种方法来训练它以提高性能
加载数据
简要分析

从简单模型中理解元数据
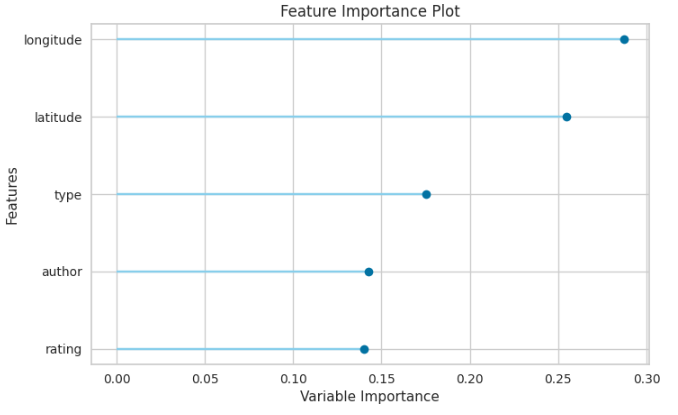
观察可以发现
latitue 和 longitude 是重要的特征
rating 的重要性相对较低。
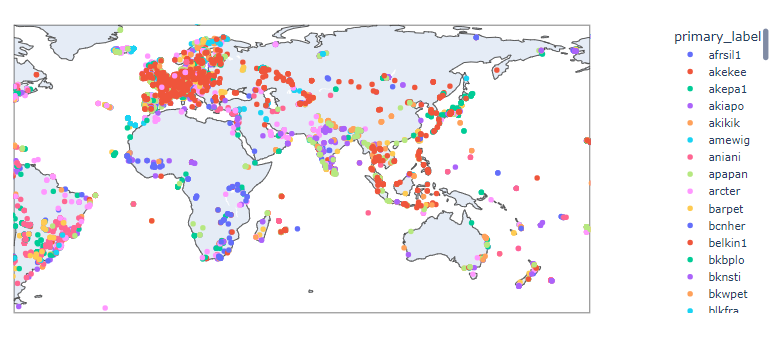
了解训练集
train data 是一个音频文件,我们想一下有什么策略可以解决这个问题
观察发现
它们属于同一鸟类,但听起来不同
似乎有可以听到噪音的音频文件
即使你看波形,也没有相似之处


版权声明: 本文为 InfoQ 作者【浩波的笔记】的原创文章。
原文链接:【http://xie.infoq.cn/article/c34d10f503ba687215bdf08db】。
本文遵守【CC BY-NC】协议,转载请保留原文出处及本版权声明。

还未添加个人签名 2022.05.12 加入
还未添加个人简介









评论