微服务架构技术栈:程序员必须掌握的微服务架构框架详细解析
主要技术
基础框架: springboot
微服务架构: dubbo,springboot cloud
ORM 框架: mybatis plus
数据库连接池: Alibaba Druid
网关(统一对外接口 ): zuul
缓存: redis
注册中心: zookeeper,eureka
消息队列:
作业调度框架: Quartz
分布式文件系统:
接口测试框架: Swagger2
数据库版本控制: Liquibase (flyway)
部署: docker
持续集成: jenkins
自动化测试: testNG
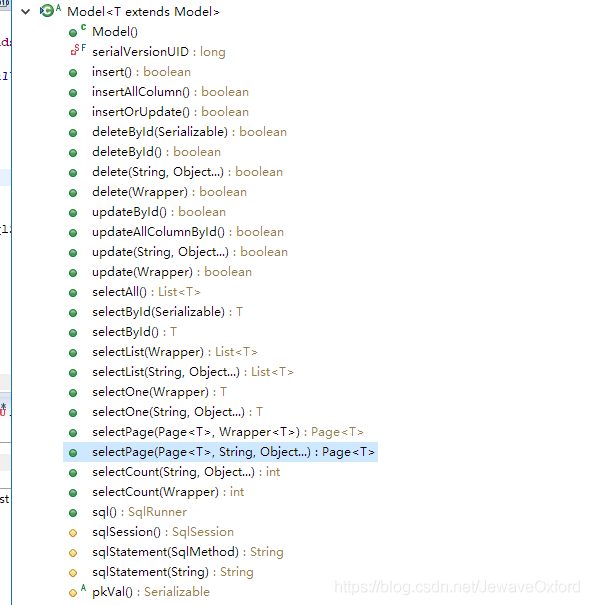
ORM 框架-Mybatis Plus
MyBatis Plus 是在 MyBatis 的基础上只做增强不做改变,可以简化开发,提高效率.
Mybatis Plus 核心功能
支持通用的 CRUD,代码生成器与条件构造器
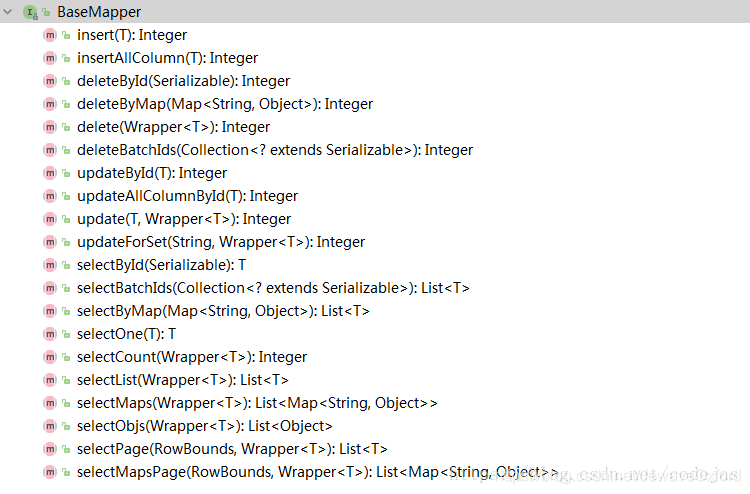
通用 CRUD: 定义好 Mapper 接口后,只需要继承 BaseMapper<T>接口即可获得通用的增删改查功能,无需编写任何接口方法与配置文件
条件构造器: 通过 EntityWrapper<T>(实体包装类),可以用于拼接 SQL 语句,并且支持排序,分组查询等复杂的 SQL
代码生成器: 支持一系列的策略配置与全局配置,比 MyBatis 的代码生成更好用 BaseMapper<T>接口中通用的 CRUD 方法:
MyBatis Plus 与 SpringBoot 集成
数据库 USER
pom.xml 依赖
spring-mybatis.xml 配置文件也可以直接使用 @Bean 的方式进行或者通过 application 配置文件进行
编写启动类,应用启动时自动加载配置 xml 文件
MyBatis Plus 集成 Spring
数据表结构
pom.xml
MyBatis 全局配置文件 mybatis-config.xml
数据源 db.properties
Spring 配置文件 applicationContext.xml
MyBatis Plus 使用示例
实体类 Employee
mapper 接口
在测试类中生成测试的 mapper 对象
查询:
分页查询:
条件构造器:
控制台输出的 SQL 分析日志

简单的数据库操作不需要在 EmployeeMapper 接口中定义任何方法,也没有在配置文件中编写 SQL 语句,而是通过继承 BaseMapper<T>接口获得通用的的增删改查方法,复杂的 SQL 也可以使用条件构造器拼接.不过复杂的业务需求还是要编写 SQL 语句的,流程和 MyBatis 一样.
MyBatis Plus 使用场景
代码生成器
代码生成器依赖 velocity 模版引擎,引入依赖
代码生成器类 MysqlGenerator:
通用 CRUD
通用 CRUD 测试类 GeneralTest:
MyBatis Plus 定义的数据库操作方法
对于通用代码如何注入的,可查看 com.baomidou.mybatisplus.mapper.AutoSqlInjector 类,这个就是注入通用的 CURD 方法的类.
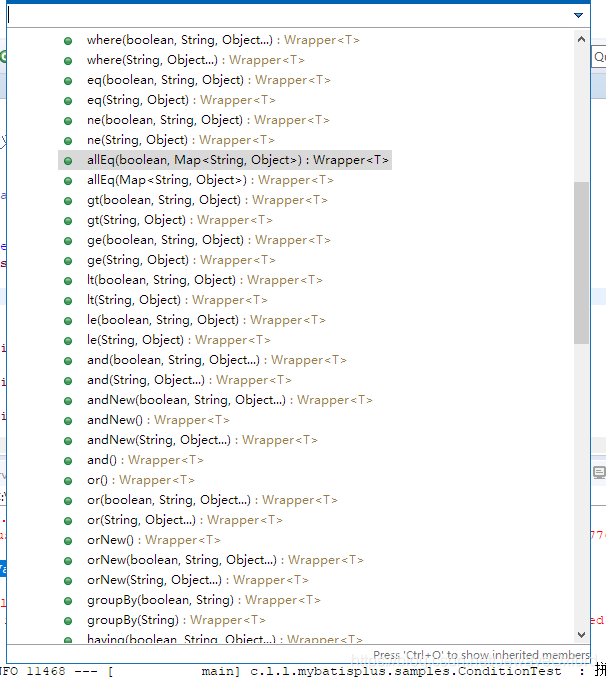
条件构造器
条件构造器主要提供了实体包装器,用于处理 SQL 语句拼接,排序,实体参数查询:使用的是数据库字段,不是 Java 属性
sql 条件拼接:SQL 条件拼接测试类 ConditionTest
MyBatis Plus 提供的条件构造方法 com.baomidou.mybatisplus.mapper.Wrapper<T>
自定义 SQL 使用条件构造器:UserDao.java 加入接口方法:
UserMapper.xml 加入对应的 xml 节点:
自定义 SQL 使用条件构造器测试类:
xml 形式使用 wrapper:UserDao.java:
UserMapper.xml:
条件参数说明:
自定义 SQL 语句
在多表关联时,条件构造器和通用 CURD 都无法满足时,可以编写 SQL 语句进行扩展.这些都是 mybatis 的用法.首先改造 UserDao 接口,有两种方式:
注解形式:
xml 形式:
UserMapper.xml 新增一个节点:
自定义 SQL 语句测试类 CustomSqlTest:
==注意:==在使用 spring-boot-maven-plugin 插件打包成 springboot 运行 jar 时,需要注意:由于 springboot 的 jar 扫描路径方式问题,会导致别名的包未扫描到,所以这个只需要把 mybatis 默认的扫描设置为 Springboot 的 VFS 实现.修改 spring-mybatis.xml 文件:
分页插件,性能分析插件
mybatis 的插件机制使用只需要注册即可
mybatis-config.xml
分页测试类(性能分析,配置后可以输出 sql 及取数时间):
性能插件体现,控制台输出:
公共字段自动填充
通常,每个公司都有自己的表定义,在《阿里巴巴 Java 开发手册》中,就强制规定表必备三字段:id,gmt_create,gmt_modified.所以通常我们都会写个公共的拦截器去实现自动填充比如创建时间和更新时间的,无需开发人员手动设置.而在 MP 中就提供了这么一个公共字段自动填充功能
设置填充字段的填充类型:
User==注意==可以在代码生成器里面配置规则的,可自动配置
定义处理类:
MybatisObjectHandler
修改 springb-mybatis.xml 文件,加入此配置
再新增或者修改时,对应时间就会进行更新:
数据库连接池-Alibaba Druid
Druid 是 JDBC 组件,包括三个部分:
DruidDriver: 代理 Driver,能够提供基于 Filter-Chain 模式的插件体系
DruidDataSource: 高效可管理的数据库连接池
SQL Parser: Druid 内置使用 SQL Parser 来实现防御 SQL 注入(WallFilter),合并统计没有参数化的 SQL(StatFilter 的 mergeSql),SQL 格式化,分库分表
Druid 的作用:
监控数据库访问性能: Druid 内置提供了一个功能强大的 StatFilter 插件,能够详细统计 SQL 的执行性能,提升线上分析数据库访问性能
替换 DBCP 和 C3P0: Druid 提供了一个高效,功能强大,可扩展性好的数据库连接池
数据库密码加密: 直接把数据库密码写在配置文件容易导致安全问题,DruidDruiver 和 DruidDataSource 都支持 PasswordCallback
监控 SQL 执行日志: Druid 提供了不同的 LogFilter,能够支持 Common-Logging,Log4j 和 JdkLog,可以按需要选择相应的 LogFilter,监控数据库访问情况
扩展 JDBC: 通过 Druid 提供的 Filter-Chain 机制,编写 JDBC 层的扩展
配置参数: Druid 的 DataSource:com.alibaba.druid.pool.DruidDataSource
Druid 的架构
Druid 数据结构
Druid 架构相辅相成的是基于 DataSource 和 Segment 的数据结构
DataSource 数据结构: 是逻辑概念, 与传统的关系型数据库相比较 DataSource 可以理解为表
时间列: 表明每行数据的时间值
维度列: 表明数据的各个维度信息
指标列: 需要聚合的列的数据
Segment 结构: 实际的物理存储格式,
Druid 通过 Segment 实现了横纵向切割操作
Druid 将不同的时间范围内的数据存放在不同的 Segment 文件块中,通过时间实现了横向切割
Segment 也面向列进行数据压缩存储,实现纵向切割
Druid 架构包含四个节点和一个服务:
实时节点(RealTime Node): 即时摄入实时数据,并且生成 Segment 文件
历史节点(Historical Node): 加载已经生成好的数据文件,以供数据查询使用
查询节点(Broker Node): 对外提供数据查询服务,并且从实时节点和历史节点汇总数据,合并后返回
协调节点( Coordinator Node): 负责历史节点的数据的负载均衡,以及通过规则管理数据的生命周期
索引服务(Indexing Service): 有不同的获取数据的方式,更加灵活的生成 segment 文件管理资源
实时节点
主要负责即时摄入实时数据,以及生成 Segment 文件
实时节点通过 firehose 进行数据的摄入,firehose 是 Druid 实时消费模型
Segment 文件从制造到传播过程:
历史节点
历史节点再启动的时候:
优先检查自己的本地缓存中是否已经有了缓存的 Segment 文件
然后从文件系统中下载属于自己,但还不存在的 Segment 文件
无论是何种查询,历史节点首先将相关的 Segment 从磁盘加载到内存.然后再提供服务
历史节点的查询效率受内存空间富余程度的影响很大:
内存空间富余,查询时需要从磁盘加载数据的次数减少,查询速度就快
内存空间不足,查询时需要从磁盘加载数据的次数就多,查询速度就相对较慢
原则上历史节点的查询速度与其内存大小和所负责的 Segment 数据文件大小成正比关系
查询节点
查询节点便是整个集群的查询中枢:
在常规情况下,Druid 集群直接对外提供查询的节点只有查询节点, 而查询节点会将从实时节点与历史节点查询到的数据合并后返回给客户端
Druid 使用了 Cache 机制来提高自己的查询效率.
Druid 提供两类介质作为 Cache:
外部 cache:Memcached
内部 Cache: 查询节点或历史节点的内存, 如果用查询节点的内存作为 Cache,查询的时候会首先访问其 Cache,只有当不命中的时候才会去访问历史节点和实时节点查询数据
协调节点
对于整个 Druid 集群来说,其实并没有真正意义上的 Master 节点.
实时节点与查询节点能自行管理并不听命于任何其他节点,
对于历史节点来说,协调节点便是他们的 Master,因为协调节点将会给历史节点分配数据,完成数据分布在历史节点之间的负载均衡.
历史节点之间是相互不进行通讯的,全部通过协调节点进行通讯
利用规则管理数据的生命周期:
Druid 利用针对每个 DataSoure 设置的规则来加载或者丢弃具体的文件数据,来管理数据的生命周期
可以对一个 DataSource 按顺序添加多条规则,对于一个 Segment 文件来说,协调节点会逐条检查规则
当碰到当前 Segment 文件负责某条规则的情况下,协调节点会立即命令历史节点对该文件执行此规则,加载或者丢弃,并停止余下的规则,否则继续检查
索引服务
除了通过实时节点生产 Segment 文件之外,druid 还提供了一组索引服务来摄入数据
索引服务的优点:
有不同的获取数据的方式,支持 pull 和 push
可以通过 API 编程的方式来配置任务
可以更加灵活地使用资源
灵活地操作 Segment 文件
索引服务的主从架构:索引服务包含一组组件,并以主从结构作为架构方式,统治节点 Overload node 为主节点,中间管理者 Middle Manager 为从节点
Overload node: 索引服务的主节点.对外负责接收任务请求,对内负责将任务分解并下发到从节点即 Middle Manager.有两种运行模式:
本地模式(默认): 此模式主节点不仅需要负责集群的调度,协调分配工作,还需要负责启动 Peon(苦工)来完成一部分具体的任务
远程模式: 主从节点分别运行在不同的节点上,主节点只负责协调分配工作.不负责完成任务,并且提供 rest 服务,因此客户端可以通过 HTTP POST 来提交任务
网关-Zuul
Zuul 是 netflix 开源的一个 API Gateway 服务器, 本质上是一个 web servlet 应用-Zuul 是一个基于 JVM 路由和服务端的负载均衡器,提供动态路由,监控,弹性,安全等边缘服务的框架,相当于是设备和 Netflix 流应用的 Web 网站后端所有请求的前门
Zuul 工作原理
过滤器机制
Zuul 提供了一个框架,可以对过滤器进行动态的加载,编译,运行
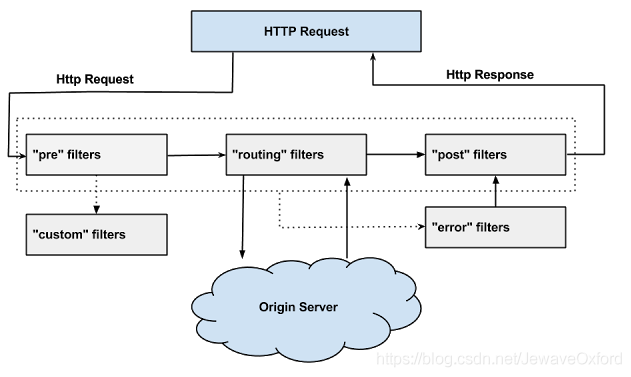
标准过滤器类型:Zuul 大部分功能都是通过过滤器来实现的。Zuul 中定义了四种标准过滤器类型,这些过滤器类型对应于请求的典型生命周期
PRE: 在请求被路由之前调用,利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等
ROUTING: 请求路由到微服务,用于构建发送给微服务的请求,使用 Apache HttpClient 或 Netfilx Ribbon 请求微服务
POST: 在路由到微服务以后执行,用来为响应添加标准的 HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等
ERROR: 在其他阶段发生错误时执行该过滤器
内置的特殊过滤器:
StaticResponseFilter: StaticResponseFilter 允许从 Zuul 本身生成响应,而不是将请求转发到源
SurgicalDebugFilter: SurgicalDebugFilter 允许将特定请求路由到分隔的调试集群或主机
自定义的过滤器:除了默认的过滤器类型,Zuul 还允许我们创建自定义的过滤器类型。如 STATIC 类型的过滤器,直接在 Zuul 中生成响应,而不将请求转发到后端的微服务
过滤器的生命周期 Zuul 请求的生命周期详细描述了各种类型的过滤器的执行顺序
过滤器调度过程
动态加载过滤器
Zuul 的作用
Zuul 可以通过加载动态过滤机制实现 Zuul 的功能:
验证与安全保障: 识别面向各类资源的验证要求并拒绝那些与要求不符的请求
审查与监控: 在边缘位置追踪有意义数据及统计结果,得到准确的生产状态结论
动态路由: 以动态方式根据需要将请求路由至不同后端集群处
压力测试: 逐渐增加指向集群的负载流量,从而计算性能水平
负载分配: 为每一种负载类型分配对应容量,并弃用超出限定值的请求
静态响应处理: 在边缘位置直接建立部分响应,从而避免其流入内部集群
多区域弹性: 跨越 AWS 区域进行请求路由,旨在实现 ELB 使用多样化并保证边缘位置与使用者尽可能接近
Zuul 与应用的集成方式
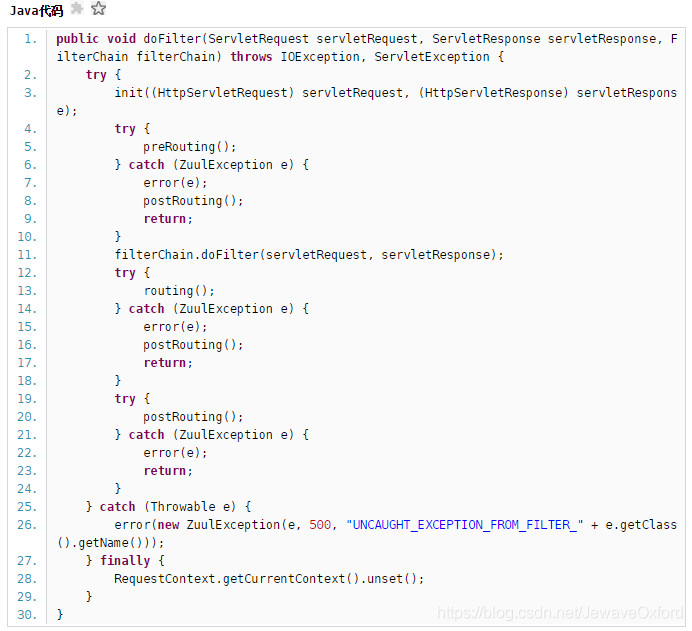
ZuulServlet - 处理请求(调度不同阶段的 filters,处理异常等)
所有的 Request 都要经过 ZuulServlet 的处理,
Zuul 对 request 处理逻辑的三个核心的方法: preRoute(),route(), postRoute()
ZuulServletZuulServlet 交给 ZuulRunner 去执行。由于 ZuulServlet 是单例,因此 ZuulRunner 也仅有一个实例。ZuulRunner 直接将执行逻辑交由 FilterProcessor 处理,FilterProcessor 也是单例,其功能就是依据 filterType 执行 filter 的处理逻辑
FilterProcessor 对 filter 的处理逻辑:
ContextLifeCycleFilter - RequestContext 的生命周期管理:
ContextLifecycleFilter 的核心功能是为了清除 RequestContext;请求上下文 RequestContext 通过 ThreadLocal 存储,需要在请求完成后删除该对象 RequestContext 提供了执行 filter Pipeline 所需要的 Context,因为 Servlet 是单例多线程,这就要求 RequestContext 即要线程安全又要 Request 安全。context 使用 ThreadLocal 保存,这样每个 worker 线程都有一个与其绑定的 RequestContext,因为 worker 仅能同时处理一个 Request,这就保证了 Request Context 即是线程安全的由是 Request 安全的。
GuiceFilter - GOOLE-IOC(Guice 是 Google 开发的一个轻量级,基于 Java5(主要运用泛型与注释特性)的依赖注入框架(IOC).Guice 非常小而且快.)
StartServer - 初始化 zuul 各个组件(ioc,插件,filters,数据库等)
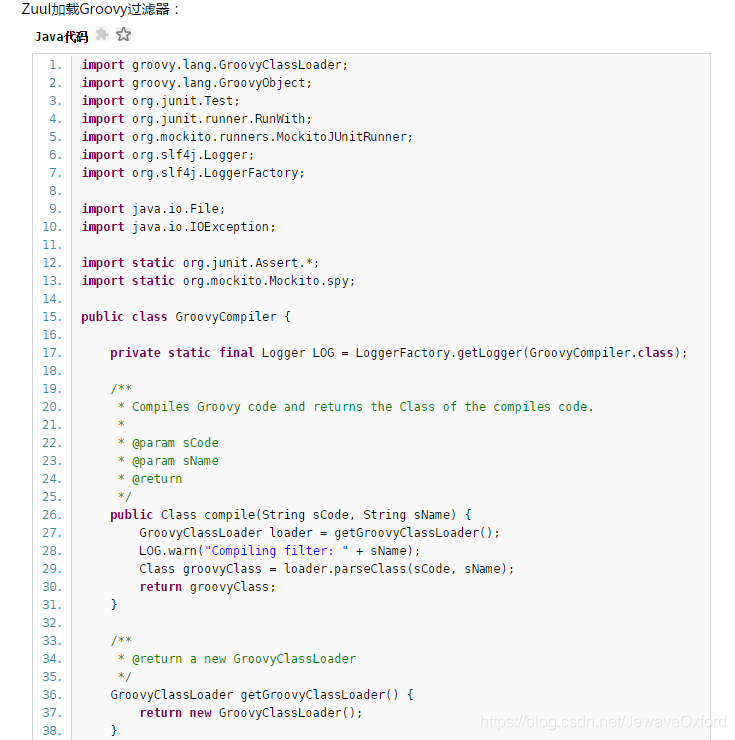
FilterScriptManagerServlet - uploading/downloading/managing scripts, 实现热部署 Filter 源码文件放在 zuul 服务特定的目录, zuul server 会定期扫描目录下的文件的变化,动态的读取\编译\运行这些 filter,如果有 Filter 文件更新,源文件会被动态的读取,编译加载进入服务,接下来的 Request 处理就由这些新加入的 filter 处理
缓存-Redis
Redis: Redis 是一个开源的内存中的数据结构存储系统,可以用作数据库,缓存和消息中间件
操作工具:Redis Desktop Manager
整合 Redis 缓存
在 pom.xml 中引入 redis 依赖
配置 redis,在 application.properties 中配置 redis
RedisTemplate:(操作 k-v 都是对象)
保存对象时,使用 JDK 的序列化机制,将序列化后的数据保存到 redis 中
为了增强 Redis 数据库中的数据可读性:
将对象数据以==json==方式保存:
将对象转化为 json
配置 redisTemplate 的 json 序列化规则
StringRedisTemplate(操作 k-v 都是字符串)在 RedisAutoConfiguration 中:
在 StringRedisTemplate 中:
注册中心-Zookeeper,Eureka
Zookeeper 基本概念
Zookeeper 是一个分布式的,开放源码的分布式应用程序协调服务
Zookeeper 是 hadoop 的一个子项目
包含一个简单的原语集, 分布式应用程序可以基于它实现同步服务,配置维护和命名服务等
在分布式应用中,由于工程师不能很好地使用锁机制,以及基于消息的协调机制不适合在某些应用中使用,Zookeeper 提供一种可靠的,可扩展的,分布式的,可配置的协调机制来统一系统的状态
Zookeeper 中的角色:
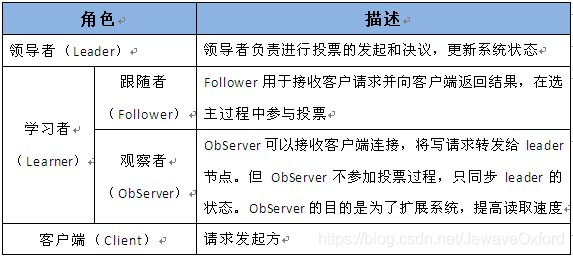
系统模型图:
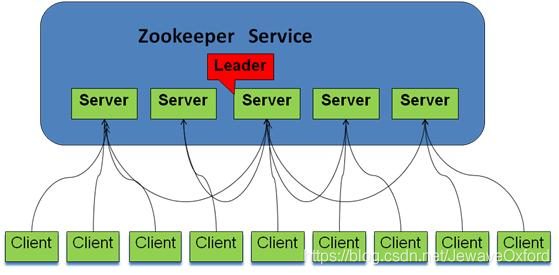
Zookeeper 特点:
最终一致性: client 不论连接到哪个 Server,展示给它都是同一个视图,这是 Zookeeper 最重要的性能
可靠性: 具有简单,健壮,良好的性能,如果消息 m 被到一台服务器接受,那么它将被所有的服务器接受
实时性: Zookeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息.但由于网络延时等原因,Zookeeper 不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用 sync()接口
等待无关(wait-free): 慢的或者失效的 client 不得干预快速的 client 的请求,使得每个 client 都能有效的等待
原子性: 更新只能成功或者失败,没有中间状态
顺序性: 包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前被发布.偏序是指如果一个消息 b 在消息 a 后被同一个发送者发布,a 必将排在 b 前面
Zookeeper 工作原理
Zookeeper 的核心是原子广播,这个机制保证了各个 Server 之间的同步实现这个机制的协议叫做 Zab 协议
Zab 协议有两种模式:恢复模式(选主),广播模式(同步)
当服务启动或者在领导者崩溃后,Zab 就进入了恢复模式,当领导者被选举出来,且大多数 Server 完成了和 leader 的状态同步以后,恢复模式就结束了
状态同步保证了 leader 和 Server 具有相同的系统状态
为了保证事务的顺序一致性,zookeeper 采用了**递增的事务 id 号(zxid)**来标识事务
所有的提议(proposal)都在被提出的时候加上了 zxid.实现中 zxid 是一个 64 位的数字,它高 32 位是 epoch 用来标识 leader 关系是否改变,每次一个 leader 被选出来,它都会有一个新的 epoch,标识当前属于那个 leader 的统治时期.低 32 位用于递增计数
每个 Server 在工作过程中有三种状态:
LOOKING: 当前 Server 不知道 leader 是谁,正在搜寻
LEADING: 当前 Server 即为选举出来的 leader
FOLLOWING: leader 已经选举出来,当前 Server 与之同步
选主流程
当 leader 崩溃或者 leader 失去大多数的 follower 这时候 Zookeeper 进入恢复模式
恢复模式需要重新选举出一个新的 leader,让所有的 Server 都恢复到一个正确的状态.
Zookeeper 的选举算法有两种:系统默认的选举算法为 fast paxos
基于 fast paxos 算法
基于 basic paxos 算法
基于 fast paxos 算法:fast paxos 流程是在选举过程中,某 Server 首先向所有 Server 提议自己要成为 leader,当其它 Server 收到提议以后,解决 epoch 和 zxid 的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出 Leader
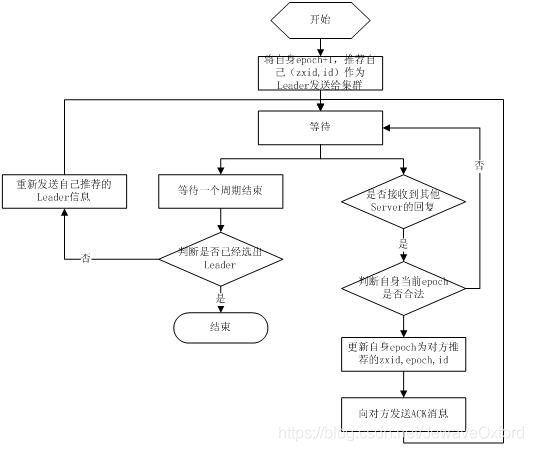
基于 basic paxos 算法:
选举线程由当前 Server 发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的 Server
选举线程首先向所有 Server 发起一次询问(包括自己)
选举线程收到回复后,验证是否是自己发起的询问(验证 zxid 是否一致),然后获取对方的 id(myid),并存储到当前询问对象列表中,最后获取对方提议的 leader 相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中
收到所有 Server 回复以后,就计算出 zxid 最大的那个 Server,并将这个 Server 相关信息设置成下一次要投票的 Server;
线程将当前 zxid 最大的 Server 设置为当前 Server 要推荐的 Leader,如果此时获胜的 Server 获得 n/2+1 的 Server 票数,设置当前推荐的 leader 为获胜的 Server,将根据获胜的 Server 相关信息设置自己的状态,否则,继续这个过程,直到 leader 被选举出来
通过流程分析我们可以得出:要使 Leader 获得多数 Server 的支持,则 Server 总数必须是奇数 2n+1,且存活的 Server 的数目不得少于 n+1.每个 Server 启动后都会重复以上流程.在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的 server 还会从磁盘快照中恢复数据和会话信息,Zookeeper 会记录事务日志并定期进行快照,方便在恢复时进行状态恢复.选主的具体流程图如下所示:
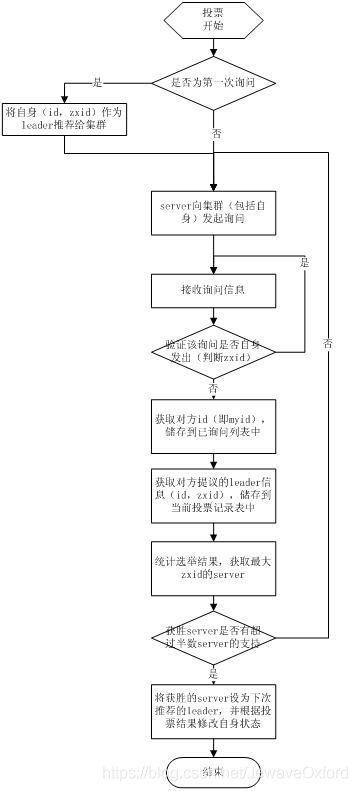
同步流程
选完 leader 以后,Zookeeper 就进入状态同步过程:
leader 等待 server 连接
Follower 连接 leader,将最大的 zxid 发送给 leader
Leader 根据 follower 的 zxid 确定同步点
完成同步后通知 follower 已经成为 uptodate 状态
Follower 收到 uptodate 消息后,又可以重新接受 client 的请求进行服务

工作流程
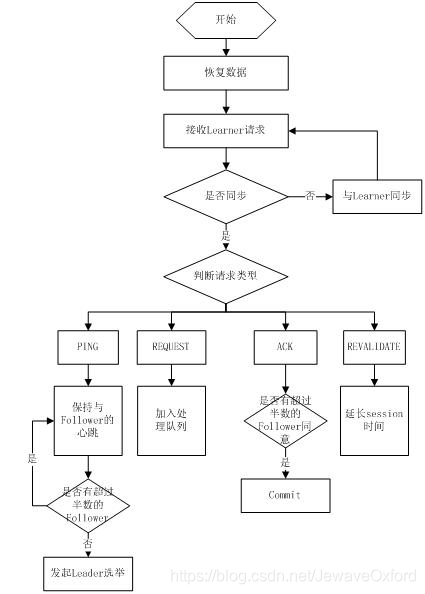
Leader 工作流程:Leader 主要有三个功能:
恢复数据
维持与 Learner 的心跳,接收 Learner 请求并判断 Learner 的请求消息类型
Learner 的消息类型主要有 PING 消息,REQUEST 消息,ACK 消息,REVALIDATE 消息,根据不同的消息类型,进行不同的处理
PING 消息: Learner 的心跳信息
REQUEST 消息: Follower 发送的提议信息,包括写请求及同步请求
ACK 消息: Follower 的对提议的回复.超过半数的 Follower 通过,则 commit 该提议
REVALIDATE 消息: 用来延长 SESSION 有效时间
Leader 的工作流程简图如下所示,在实际实现中,流程要比下图复杂得多,启动了三个线程来实现功能:
Follower 工作流程:
Follower 主要有四个功能:
向 Leader 发送请求(PING 消息,REQUEST 消息,ACK 消息,REVALIDATE 消息)
接收 Leader 消息并进行处理
接收 Client 的请求,如果为写请求,发送给 Leader 进行投票
返回 Client 结果
Follower 的消息循环处理如下几种来自 Leader 的消息:
PING 消息: 心跳消息
PROPOSAL 消息: Leader 发起的提案,要求 Follower 投票
COMMIT 消息: 服务器端最新一次提案的信息
UPTODATE 消息: 表明同步完成
REVALIDATE 消息: 根据 Leader 的 REVALIDATE 结果,关闭待 revalidate 的 session 还是允许其接受消息
SYNC 消息: 返回 SYNC 结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新
Follower 的工作流程简图如下所示,在实际实现中,Follower 是通过 5 个线程来实现功能的:
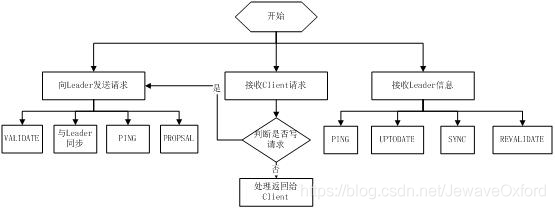
observer 流程和 Follower 的唯一不同的地方就是 observer 不会参加 leader 发起的投票
Zookeeper 应用场景
配置管理
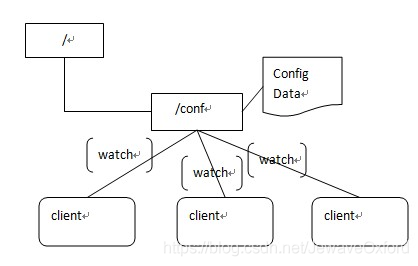
集中式的配置管理在应用集群中是非常常见的,一般都会实现一套集中的配置管理中心,应对不同的应用集群对于共享各自配置的需求,并且在配置变更时能够通知到集群中的每一个机器,也可以细分进行分层级监控
Zookeeper 很容易实现这种集中式的配置管理,比如将 APP1 的所有配置配置到/APP1 znode 下,APP1 所有机器一启动就对/APP1 这个节点进行监控(zk.exist("/APP1",true)),并且实现回调方法 Watcher,那么在 zookeeper 上/APP1 znode 节点下数据发生变化的时候,每个机器都会收到通知,Watcher 方法将会被执行,那么应用再取下数据即可(zk.getData("/APP1",false,null))
集群管理
应用集群中,我们常常需要让每一个机器知道集群中(或依赖的其他某一个集群)哪些机器是活着的,并且在集群机器因为宕机,网络断链等原因能够不在人工介入的情况下迅速通知到每一个机器
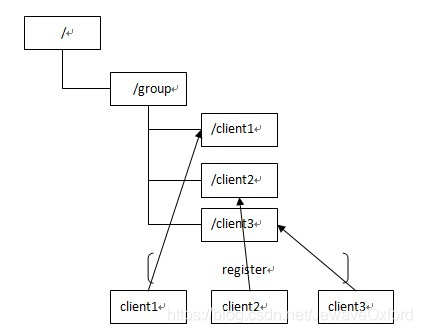
Zookeeper 同样很容易实现这个功能,比如我在 zookeeper 服务器端有一个 znode 叫 /APP1SERVERS, 那么集群中每一个机器启动的时候都去这个节点下创建一个 EPHEMERAL 类型的节点,比如 server1 创建/APP1SERVERS/SERVER1(可以使用 ip,保证不重复),server2 创建/APP1SERVERS/SERVER2,然后 SERVER1 和 SERVER2 都 watch /APP1SERVERS 这个父节点,那么也就是这个父节点下数据或者子节点变化都会通知对该节点进行 watch 的客户端.因为 EPHEMERAL 类型节点有一个很重要的特性,就是客户端和服务器端连接断掉或者 session 过期就会使节点消失,那么在某一个机器挂掉或者断链的时候,其对应的节点就会消失,然后集群中所有对/APP1SERVERS 进行 watch 的客户端都会收到通知,然后取得最新列表即可
另外有一个应用场景就是集群选 master: 一旦 master 挂掉能够马上能从 slave 中选出一个 master,实现步骤和前者一样,只是机器在启动的时候在 APP1SERVERS 创建的节点类型变为 EPHEMERAL_SEQUENTIAL 类型,这样每个节点会自动被编号
我们默认规定编号最小的为 master,所以当我们对/APP1SERVERS 节点做监控的时候,得到服务器列表,只要所有集群机器逻辑认为最小编号节点为 master,那么 master 就被选出,而这个 master 宕机的时候,相应的 znode 会消失,然后新的服务器列表就被推送到客户端,然后每个节点逻辑认为最小编号节点为 master,这样就做到动态 master 选举
Zookeeper 监视
Zookeeper 所有的读操作-getData(),getChildren(),和 exists() 都可以设置监视(watch),监视事件可以理解为一次性的触发器. 官方定义如下: a watch event is one-time trigger, sent to the client that set the watch, which occurs when the data for which the watch was set changes:
One-time trigger(一次性触发)
当设置监视的数据发生改变时,该监视事件会被发送到客户端
例如:如果客户端调用了 getData("/znode1", true)并且稍后/znode1 节点上的数据发生了改变或者被删除了,客户端将会获取到/znode1 发生变化的监视事件,而如果/znode1 再一次发生了变化,除非客户端再次对/znode1 设置监视,否则客户端不会收到事件通知
Sent to the client(发送至客户端)
Zookeeper 客户端和服务端是通过 socket 进行通信的,由于网络存在故障,所以监视事件很有可能不会成功地到达客户端,监视事件是异步发送至监视者的
Zookeeper 本身提供了保序性(ordering guarantee):即客户端只有首先看到了监视事件后,才会感知到它所设置监视的 znode 发生了变化(a client will never see a change for which it has set a watch until it first sees the watch event).网络延迟或者其他因素可能导致不同的客户端在不同的时刻感知某一监视事件,但是不同的客户端所看到的一切具有一致的顺序
The data for which the watch was set(被设置 watch 的数据)
znode 节点本身具有不同的改变方式
例如:Zookeeper 维护了两条监视链表:数据监视和子节点监视(data watches and child watches) getData() and exists()设置数据监视,getChildren()设置子节点监视
又例如:Zookeeper 设置的不同监视返回不同的数据,getData()和 exists()返回 znode 节点的相关信息,而 getChildren()返回子节点列表.因此,setData()会触发设置在某一节点上所设置的数据监视(假定数据设置成功),而一次成功的 create()操作则会出发当前节点上所设置的数据监视以及父节点的子节点监视.一次成功的 delete()操作将会触发当前节点的数据监视和子节点监视事件,同时也会触发该节点父节点的 child watch
Zookeeper 中的监视是轻量级的,因此容易设置,维护和分发.当客户端与 Zookeeper 服务器端失去联系时,客户端并不会收到监视事件的通知,只有当客户端重新连接后,若在必要的情况下,以前注册的监视会重新被注册并触发,对于开发人员来说这通常是透明的.只有一种情况会导致监视事件的丢失,即:通过 exists()设置了某个 znode 节点的监视,但是如果某个客户端在此 znode 节点被创建和删除的时间间隔内与 zookeeper 服务器失去了联系,该客户端即使稍后重新连接 zookeeper 服务器后也得不到事件通知
Eureka(服务发现框架)
Eureka 是一个基于 REST 的服务,主要用于定位运行在 AWS 域中的中间层服务,以达到负载均衡和中间层服务故障转移的目的. SpringCloud 将它集成在其子项目 spring-cloud-netflix 中,以实现 SpringCloud 的服务发现功能
Eureka 的两个组件
Eureka Server: Eureka Server 提供服务注册服务,各个节点启动后,会在 Eureka Server 中进行注册,这样 EurekaServer 中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中看到. Eureka Server 之间通过复制的方式完成数据的同步
Eureka Client: 是一个 java 客户端,用于简化与 Eureka Server 的交互,客户端同时也就是一个内置的、使用轮询(round-robin)负载算法的负载均衡器
Eureka 通过心跳检查、客户端缓存等机制,确保了系统的高可用性、灵活性和可伸缩性
在应用启动后,将会向 Eureka Server 发送心跳, 如果 Eureka Server 在多个心跳周期内没有接收到某个节点的心跳,Eureka Server 将会从服务注册表中把这个服务节点移除。
Eureka 还提供了客户端缓存机制,即使所有的 Eureka Server 都挂掉,客户端依然可以利用缓存中的信息消费其他服务的 API。Eureka 通过心跳检查、客户端缓存等机制,确保了系统的高可用性、灵活性和可伸缩性
作业调度框架-Quartz
Quartz 作业调度框架概念
Quartz 是一个完全由 java 编写的开源作业调度框架,是 OpenSymphony 开源组织在 Job scheduling 领域的开源项目,它可以与 J2EE 与 J2SE 应用程序相结合也可以单独使用,Quartz 框架整合了许多额外功能.Quartz 可以用来创建简单或运行十个,百个,甚至是好几万个 Jobs 这样复杂的程序
Quartz 三个主要的概念:
调度器:
Quartz 框架的核心是调度器
调度器负责管理 Quartz 应用运行时环境
调度器不是靠自己做所有的工作,而是依赖框架内一些非常重要的部件
Quartz 怎样能并发运行多个作业的原理: Quartz 不仅仅是线程和线程池管理,为确保可伸缩性,Quartz 采用了基于多线程的架构.启动时,框架初始化一套 worker 线程,这套线程被调度器用来执行预定的作业.
Quartz 依赖一套松耦合的线程池管理部件来管理线程环境
任务:
自己编写的业务逻辑,交给 quartz 执行
触发器:
调度作业,什么时候开始执行,什么时候结束执行
Quartz 设计模式
Builer 模式
Factory 模式
组件模式
链式写法
Quartz 体系结构
Quartz 框架中的核心类:
JobDetail:
Quartz 每次运行都会直接创建一个 JobDetail,同时创建一个 Job 实例.
不直接接受一个 Job 的实例,接受一个 Job 的实现类
通过 new instance()的反射方式来实例一个 Job,在这里 Job 是一个接口,需要编写类去实现这个接口
Trigger:
它由 SimpleTrigger 和 CronTrigger 组成
SimpleTrigger 实现类似 Timer 的定时调度任务,CronTrigger 可以通过 cron 表达式实现更复杂的调度逻辑
Scheduler:
调度器
JobDetail 和 Trigger 可以通过 Scheduler 绑定到一起
Quartz 重要组件
Job 接口
可以通过实现该接口来实现我们自己的业务逻辑,该接口只有 execute()一个方法,我们可以通过下面的方式来实现 Job 接口来实现我们自己的业务逻辑
JobDetail
每次都会直接创建一个 JobDetail,同时创建一个 Job 实例,它不直接接受一个 Job 的实例,但是它接受一个 Job 的实现类,通过 new instance()的反射方式来实例一个 Job.可以通过下面的方式将一个 Job 实现类绑定到 JobDetail 中
JobBuiler
主要是用来创建 JobDeatil 实例
JobStore
绑定了 Job 的各种数据
Trigger
主要用来执行 Job 实现类的业务逻辑的,我们可以通过下面的代码来创建一个 Trigger 实例
Scheduler
创建 Scheduler 有两种方式
通过 StdSchedulerFactory 来创建
通过 DirectSchedulerFactory 来创建
Scheduler 配置参数一般存储在 quartz.properties 中,我们可以修改参数来配置相应的参数.通过调用 getScheduler() 方法就能创建和初始化调度对象
Scheduler 的主要函数:
Date schedulerJob(JobDetail,Trigger trigger): 返回最近触发的一次时间
void standby(): 暂时挂起
void shutdown(): 完全关闭,不能重新启动
shutdown(true): 表示等待所有正在执行的 job 执行完毕之后,再关闭 scheduler
shutdown(false): 直接关闭 scheduler
quartz.properties 资源文件:在 org.quartz 这个包下,当我们程序启动的时候,它首先会到我们的根目录下查看是否配置了该资源文件,如果没有就会到该包下读取相应信息,当我们咋实现更复杂的逻辑时,需要自己指定参数的时候,可以自己配置参数来实现
quartz.properties 资源文件主要组成部分:
调度器属性
线程池属性
作业存储设置
插件设置
调度器属性:
org.quartz.scheduler.instanceName 属性用来区分特定的调度器实例,可以按照功能用途来给调度器起名
org.quartz.scheduler.instanceId 属性和前者一样,也允许任何字符串,但这个值必须是在所有调度器实例中是唯一的,尤其是在一个集群当中,作为集群的唯一 key.假如想 quartz 生成这个值的话,可以设置为 Auto
线程池属性:
threadCount: 设置线程的数量
threadPriority: 设置线程的优先级
org.quartz.threadPool.class: 线程池的实现
作业存储设置:
描述了在调度器实例的声明周期中,job 和 trigger 信息是怎么样存储的
插件配置:
满足特定需求用到的 quartz 插件的配置
监听器
对事件进行监听并且加入自己相应的业务逻辑,主要有以下三个监听器分别对 Job,Trigger,Scheduler 进行监听:
JobListener
TriggerListener
SchedulerListener
Cron 表达式
接口测试框架-Swagger2
Swagger 介绍
Swagger 是一款 RESTful 接口的文档在线生成和接口测试工具
Swagger 是一个规范完整的框架,用于生成,描述,调用和可视化 RESTful 风格的 web 服务
总体目标是使客户端和文件系统作为服务器以同样的速度更新
文件的方法,参数和模型紧密集成到服务器端代码,允许 API 始终保持同步
Swagger 作用
接口文档在线自动生成
功能测试
Swagger 主要项目
Swagger-tools: 提供各种与 Swagger 进行集成和交互的工具. 比如 Swagger Inspector,Swagger Editor
Swagger-core: 用于 Java 或者 Scala 的 Swagger 实现,与 JAX-RS,Servlets 和 Play 框架进行集成
Swagger-js: 用于 JavaScript 的 Swagger 实现
Swagger-node-express: Swagger 模块,用于 node.js 的 Express Web 应用框架
Swagger-ui: 一个无依赖的 html,js 和 css 集合,可以为 Swagger 的 RESTful API 动态生成文档
Swagger-codegen: 一个模板驱动引擎,通过分析用户 Swagger 资源声明以各种语言生成客户端代码
Swagger 工具
Swagger Codegen:
通过 Codegen 可以将描述文件生成 html 格式和 cwiki 形式的接口文档,同时也能生成多种语言的服务端和客户端的代码
支持通过 jar 包 ,docker,node 等方式在本地化执行生成,也可以在后面 Swagger Editor 中在线生成
Swagger UI:
提供一个可视化的 UI 页面展示描述文件
接口的调用方,测试,项目经理等都可以在该页面中对相关接口进行查阅和做一些简单的接口请求
该项目支持在线导入描述文件和本地部署 UI 项目
Swagger Editor:
类似于 markdown 编辑器用来编辑 Swagger 描述文件的编辑器
该编辑器支持实时预览描述文件的更新效果
提供了在线编辑器和本地部署编辑器两种方式
Swagger Inspector:
在线对接口进行测试
会比 Swagger 里面做接口请求会返回更多的信息,也会保存请求的实际请求参数等数据
Swagger Hub:
集成上面的所有工具的各个功能
可以以项目和版本为单位,将描述文件上传到 Swagger Hub 中,在 Swagger Hub 中可以完成上面项目的所有工作
Swagger 注解
@Api
该注解将一个 controller 类标注为一个 Swagger API. 在默认情况下 ,Swagger core 只会扫描解析具有 @Api 注解的类,而忽略其它类别的资源,比如 JAX-RS endpoints, Servlets 等注解. 该注解的属性有:
tags: API 分组标签,具有相同标签的 API 将会被归并在一组内显示
value: 如果 tags 没有定义 ,value 将作为 Api 的 tags 使用
@ApiOperation
在指定接口路径上,对一个操作或者 http 方法进行描述. 具有相同路径的不同操作会被归组为同一个操作对象. 紧接着是不同的 http 请求方法注解和路径组合构成一个唯一操作. 该注解的属性有:
value: 对操作进行简单说明
notes: 对操作进行详细说明
httpMethod: http 请求动作名,可选值有 :GET, HEAD, POST, PUT, DELETE, OPTIONS, PATCH
code: 成功操作后的返回类型. 默认为 200, 参照标准Http Status Code Definitions
@ApiParam
增加对参数的元信息说明,紧接着使用 Http 请求参数注解. 主要属性有:
required: 是否为必传参数
value: 参数简短说明
@ApiResponse
描述一个操作的可能返回结果. 当 RESTful 请求发生时,这个注解可用于描述所有可能的成功与错误码.可以使用也可以不使用这个注解去描述操作返回类型. 但成功操作后的返回类型必须在 @ApiOperation 中定义. 如果 API 具有不同的返回类型,那么需要分别定义返回值,并将返回类型进行关联. 但是 Swagger 不支持同一返回码,多种返回类型的注解. 这个注解必须被包含在 @ApiResponses 中:
code: http 请求返回码,参照标准Http Status Code Definitions
message: 更加易于理解的文本消息
response: 返回类型信息,必须使用完全限定类名,即类的完整路径
responseContainer: 如果返回值类型为容器类型,可以设置相应的值. 有效值 :List, Set, Map. 其它的值将会被忽略
@ApiResponses
注解 @ApiResponse 的包装类,数组结构. 即使需要使用一个 @ApiResponse 注解,也需要将 @ApiResponse 注解包含在注解 @ApiResponses 内
@ApiImplicitParam
对 API 的单一参数进行注解. 注解 @ApiParam 需要同 JAX-RS 参数相绑定, 但这个 @ApiImplicitParam 注解可以以统一的方式定义参数列表,这是在 Servlet 和非 JAX-RS 环境下唯一的方式参数定义方式. 注意这个注解 @ApiImplicitParam 必须被包含在注解 @ApiImplicitParams 之内,可以设置以下重要属性:
name: 参数名称
value: 参数简短描述
required: 是否为必传参数
dataType: 参数类型,可以为类名,也可以为基本类型,比如 String,int,boolean 等
paramType: 参数的请求类型,可选的值有 path, query, body, header, from
@ApiImplicitParams
注解 @ApiImplicitParam 的容器类,以数组方式存储
@ApiModel
提供对 Swagger model 额外信息的描述. 在标注 @ApiOperation 注解的操作内,所有类将自动 introspected. 利用这个注解可以做一些更详细的 model 结构说明. 主要属性值有:
value: model 的别名,默认为类名
description: model 的详细描述
@ApiModelProperty
对 model 属性的注解,主要属性值有:
value: 属性简短描述
example: 属性示例值
required: 是否为必须值
数据库版本控制-Liquibase,flyway
Liquibase
Liquibase 基本概念
Liquibase 是一个用于跟踪,管理和应用数据库变化的数据重构和迁移的开源工具,通过日志文件的形式记录数据库的变更,然后执行日志文件中的修改,将数据库更新或回滚到一致的状态
Liquibase 的主要特点:
不依赖于特定的数据库,支持所有主流的数据库. 比如 MySQL, PostgreSQL, Oracle, SQL Server, DB2 等.这样在数据库的部署和升级环节可以帮助应用系统支持多数据库
提供数据库比较功能,比较结果保存在 XML 中,基于 XML 可以用 Liquibase 部署和升级数据库
支持多开发者的协作维护,以 XML 存储数据库变化,以 author 和 id 唯一标识一个 changeSet, 支持数据库变化的合并
日志文件支持多种格式. 比如 XML, YAML, JSON, SQL 等
支持多种运行方式. 比如命令行, Spring 集成, Maven 插件, Gradle 插件等
在数据库中保存数据库修改历史 DatabaseChangeHistory, 在数据库升级时自动跳过已应用的变化
提供变化应用的回滚功能,可按时间,数量或标签 tag 回滚已经应用的变化
可生成 html 格式的数据库修改文档
日志文件 changeLog
changeLog 是 Liquibase 用来记录数据库变更的日志文件,一般放在 classpath 下,然后配置到执行路径中
changeLog 支持多种格式, 主要有 XML, JSON, YAML, SQL, 推荐使用 XML 格式
一个 < changeSet > 标签对应一个变更集, 由属性 id, name, changelog 的文件路径唯一标识组合而成
changelog 在执行时不是按照 id 的顺序,而是按照 changSet 在 changlog 中出现的顺序
在执行 changelog 时 ,Liquibase 会在数据库中新建 2 张表,写执行记录:databasechangelog - changelog 的执行日志和 databasechangeloglock - changelog 锁日志
在执行 changelog 中的 changeSet 时,会首先查看 databasechangelog 表,如果已经执行过,则会跳过,除非 changeSet 的 runAlways 属性为 true, 如果没有执行过,则执行并记录 changelog 日志
changelog 中的一个 changeSet 对应一个事务,在 changeSet 执行完后 commit, 如果出现错误就会 rollback
常用标签及命令
changeSet 标签
< changeSet > 标签的主要属性有:
runAlways: 即使执行过,仍然每次都要执行
由于 databasechangelog 中还记录了 changeSet 的 MD5 校验值 MD5SUM, 如果 changeSet 的 id 和 name 没变,而内容变化.则 MD5 值变化,这样即使 runAlways 的值为 true, 也会导致执行失败报错.
这时应该使用 runOnChange 属性
runOnChange: 第一次的时候以及当 changeSet 发生变化的时候执行,不受 MD5 校验值的约束
runInTransaction: 是否作为一个事务执行,默认为 true.
如果设置为 false, 需要注意: 如果执行过程中出错了不会 rollback, 会导致数据库处于不一致的状态
< changeSet > 有一个 < rollback > 子标签,用来定义回滚语句:
对于 create table, rename column, add column 等 ,Liquibase 会自动生成对应的 rollback 语句
对于 drop table, insert data 等需要显式定义 rollback 语句
include 标签
当 changelog 文件越来越多时,需要使用 < include > 标签将文件管理起来:
file: 包含的 changelog 文件的路径,这个文件可以是 Liquibase 支持的任意格式
relativeToChangelogFile: 相对于 changelogFile 的路径,表示 file 属性的文件路径是相对于 changelogFile 的而不是 classpath 的,默认为 false
< include >标签存在循环引用和重复引用的问题,循环引用会导致无限循环,需要注意
includeAll 标签
< includeAll > 标签指定的是 changelog 的目录,而不是文件
diff 命令
diff 命令用于比较数据库之间的异同
generateChangeLog
在已有项目上使用 LiquiBase, 需要生成当前数据的 changeSet, 可以使用两种方式:
使用数据库工具导出 SQL 数据,然后在 changLog 文件中以 SQL 格式记录
使用 generateChangeLog 命令生成 changeLog 文件
generateChangeLog 不支持存储过程,函数以及触发器
Liquibase 使用示例
在 application.properties 中配置 changeLog 路径:
# Liquibase配置 liquibase=true # changelog默认路径 liquibase.change-log=classpath:/db/changelog/sqlData.xml
xml 配置 sample:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd"> <changeSet author="chova" id="sql-01"> <sqlFile path="classpath:db/changelog/sqlfile/init.sql" encoding="UTF-8" /> <sqlFile path="classpath:db/changelog/sqlfile/users.sql" encoding="UTF-8" /> </changeSet> <changeSet author="chova" id="sql-02"> <sqlFile path="classpath:db/changelog/sqlfile/users2.sql" encoding="UTF-8" /> </changeSet> </databaseChangeLog>
待执行的 SQL 语句 - init.sql:
CREATE TABLE usersTest( user_id varchar2(14) DEFAULT '' NOT NULL, user_name varchar2(128) DEFAULT '' NOT NULL )STORAGE(FREELISTS 20 FREELIST GROUPS 2) NOLOGGING TABLESPACE USER_DATA; insert into usersTest(user_id,user_name) values ('0','test');
启动项目.
在 maven 配置插件生成已有数据库的 changelog 文件: 需要在 pom.xml 中增加配置,然后配置 liquibase.properties
<build> <plugins> <plugin> <groupId>org.liquibase</groupId> <artifactId>liquibase-maven-plugin</artifactId> <version>3.4.2</version> <configuration> <propertyFile>src/main/resources/liquibase.properties</propertyFile> <propertyFileWillOverride>true</propertyFileWillOverride> <!--生成文件的路径--> <outputChangeLogFile>src/main/resources/changelog_dev.xml</outputChangeLogFile> </configuration> </plugin> </plugins> </build>changeLogFile=src/main/resources/db/changelog/sqlData.xml driver=oracle.jdbc.driver.OracleDriver url=jdbc:oracle:thin:@chova username=chova password=123456 verbose=true # 生成文件的路径 outputChangeLogFile=src/main/resources/changelog.xml然后执行 [ mvn liquibase:generateChangeLog ] 命令,就是生成 changelog.xml 文件
liquibase:update
执行 changeLog 中的变更
liquibase:rollback
rollbackCount: 表示 rollback 的 changeSet 的个数
rollbackDate: 表示 rollback 到指定日期
rollbackTag: 表示 rollback 到指定的 tag, 需要使用 liquibase 在具体的时间点上打上 tag
rollbackCount 示例:
rollbackDate 示例: 需要注意日期格式,必须匹配当前平台执行 DateFormat.getDateInstance() 得到的格式,比如 MMM d, yyyy
rollbackTag 示例: 使用 tag 标识,需要先打 tag, 然后 rollback 到 tag
flyway
flyway 基本概念
flyway 是一款数据库版本控制管理工具,支持数据库版本自动升级,不仅支持 Command Line 和 Java API, 同时也支持 Build 构建工具和 SpringBoot, 也可以在分布式环境下安全可靠地升级数据库,同时也支持失败恢复
flyway 是一款数据库迁移 (migration) 工具,也就是在部署应用的时候,执行数据库脚本的应用,支持 SQL 和 Java 两种类型的脚本,可以将这些脚本打包到应用程序中,在应用程序启动时,由 flyway 来管理这些脚本的执行,这些脚本在 flyway 中叫作 migration
没有使用 flyway 时部署应用的流程:
开发人员将程序应用打包,按顺序汇总并整理数据库升级脚本
DBA 拿到数据库升级脚本检查,备份,执行,以完成数据库升级
应用部署人员拿到应用部署包,备份,替换,完成应用程序升级
引入 flyway 时部署应用的流程:
开发人员将程序打包
应用部署人员拿到应用部署包,备份,替换,完成应用程序升级.期间 flyway 自动执行升级,备份脚本
flyway 的核心: MetaData 表 - 用于记录所有版本演化和状态
flyway 首次启动会创建默认名为 SCHMA_VERSION 表,保存了版本,描述和要执行的 SQL 脚本
flyway 主要特性
普通 SQL: 纯 SQL 脚本,包括占位符替换,没有专有的 XML 格式
无限制: 可以通过 Java 代码实现高级数据操作
零依赖: 只需运行在 Java 6 以上版本及数据库所需的 JDBC 驱动
约定大于配置: 数据库迁移时,自动查找系统文件和类路径中的 SQL 文件或 Java 类
高可靠性: 在集群环境下进行数据库的升级是安全可靠的
云支持: 完全支持 Microsoft SQL Azure, Google Cloud SQL & App Engine, Heroku Postgres 和 Amazon RDS
自动迁移: 使用 flyway 提供的 API, 可以让应用启动和数据库迁移同时工作
快速失败: 损坏的数据库或失败的迁移可以防止应用程序启动
数据库清理: 在一个数据库中删除所有的表,视图,触发器. 而不是删除数据库本身
SQL 脚本
格式 : V + 版本号 + 双下划线 + 描述 + 结束符
V 是默认值,可以进行自定义配置:
flyway 工作原理
flyway 对数据库进行版本管理主要由 Metadata 表和 6 种命令 : Migrate, Clean, Info, Validate, Undo, Baseline, Repair 完成
在一个空数据库上部署集成 flyway 应用:
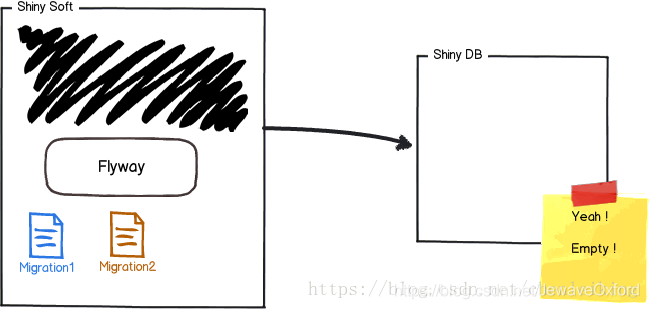
应用程序启动时 ,flyway 在这个数据库中创建一张表,用于记录 migration 的执行情况,表名默认为:schema_version:
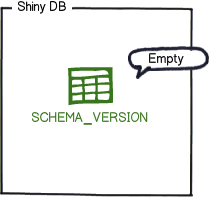
然后 ,flyway 根据表中的记录决定是否执行应用程序包中提供的 migration:
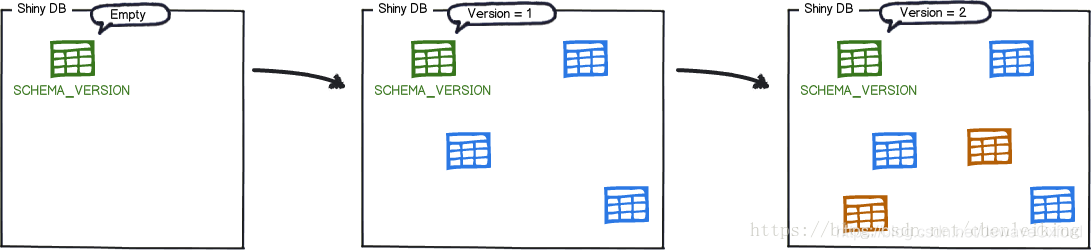
最后,将执行结果写入 schema_version 中并校验执行结果:

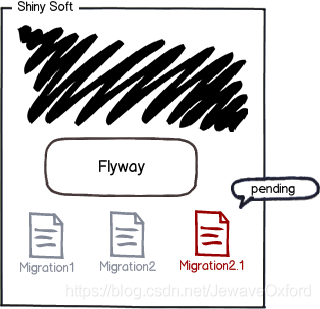
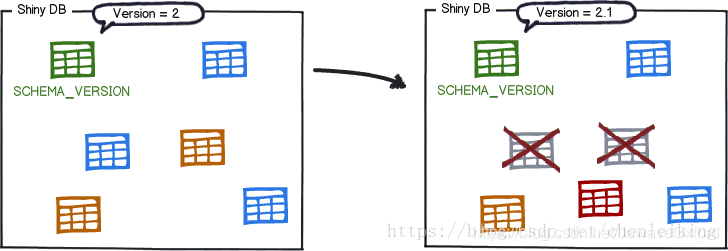
下次版本迭代时,提供新的 migration, 会根据 schema_version 的记录执行新的 migration:

flyway 核心
Metadata Table
flyway 中最核心的就是用于记录所有版本演化和状态的 Metadata 表
在 flyway 首次启动时会创建默认表名为 SCHEMA_VERSION 的元数据表,表结构如下:
Migration
flyway 将每一个数据库脚本称之为 migration,flyway 主要支持两种类型的 migrations:
Versioned migrations:
最常用的 migration,用于版本升级
每一个版本都有一个唯一的标识并且只能被应用一次,并且不能再修改已经加载过的 Migrations,因为 Metadata 表会记录 Checksum 值
version 标识版本号由一个或多个数字构成,数字之间的分隔符可以采用点或下划线,在运行时下划线其实也是被替换成点了,每一部分的前导数字 0 都会被自动忽略
Repeatable migrations:
指的是可重复加载的 Migrations,每一次的更新会影响 Checksum 值,然后都会被重新加载,并不用于版本升级.对于管理不稳定的数据库对象更新时非常有用
Repeatable 的 Migrations 总是在 Versioned 的 Migrations 之后按顺序执行,开发者需要维护脚本并且确保可以重复执行.通常会在 sql 语句中使用 CREATE OR REPLACE 来确保可重复执行
Migration 命名规范:

prefix: 前缀标识.可以配置,默认情况下: V - Versioned, R - Repeatable
version: 标识版本号. 由一个或多个数字构成,数字之间的分隔符可以使用点或者下划线
separator: 用于分割标识版本号和描述信息. 可配置,默认情况下是两个下划线 _ _
description: 描述信息. 文字之间可以用下划线或空格分割
suffix: 后续标识. 可配置,默认为 .sql
确保版本号唯一 ,flyway 按照版本号顺序执行 . repeatable 没有版本号,因为 repeatable migration 会在内容改变时重复执行
默认情况下 ,flyway 会将单个 migration 放在一个事务里执行,也可以通过配置将所有 migration 放在同一个事务里执行
每个 Migration 支持两种编写方式:
Java API
SQL 脚本
Java API: 通过实现 org.flywaydb.core.api.migration.jdbc.JdbcMigration 接口来创建一个 Migration, 也就是通过 JDBC 来执行 SQL, 对于类是 CLOB 或者 BLOB 这种不适合在 SQL 中实现的脚本比较方便
public class V1_2_Another_user implements JdbcMigration { public void migrate(Connection connection) throws Exception { PreparedStatement statement = connection.prepareStatement("INSERT INTO test_user (name) VALUES ("Oxford")"); try { statement.execute(); } finally { statement.close(); } } }
SQL 脚本: 简单的 SQL 脚本文件
// 单行命令 CREATE TABLE user (name VARCHAR(25) NOT NULL, PRIMARY KEY(name)); // 多行命令 -- Placeholder INSERT INTO ${tableName} (name) VALUES ("oxford");
Callbacks
flyway 在执行 migration 时提供了一系列的 hook, 可以在执行过程中进行额外的操作:
只要将 migration 的名称以 hook 开头,这些 hook 就可以执行 SQL 和 Java 类型的 migrations:
SQL 类型的 hook:
beforeMigrate.sql
beforeEachMigrate.sql
beforeRepair_vacuum.sql
Java 类型的 hook 需要实现接口 : org.flyway.core.api.callback.CallBack
flyway 中 6 种命令
Migrate:
将数据库迁移到最新版本,是 flyway 工作流的核心功能.
flyway 在 Migrate 时会检查元数据 Metadata 表.如果不存在会创建 Metadata 表,Metadata 表主要用于记录版本变更历史以及 Checksum 之类
在 Migrate 时会扫描指定文件系统或 classpath 下的数据库的版本脚本 Migrations, 并且会逐一比对 Metadata 表中已经存在的版本记录,如果未应用的 Migrations,flyway 会获取这些 Migrations 并按次序 Apply 到数据库中,否则不会做任何事情
通常会在应用程序启动时默认执行 Migrate 操作,从而避免程序和数据库的不一致
Clean:
来清除掉对应数据库的 Schema 的所有对象 .flyway 不是删除整个数据库,而是清除所有表结构,视图,存储过程,函数以及所有相关的数据
通常在开发和测试阶段使用,能够快速有效地更新和重新生成数据库表结构.但是不应该在 production 的数据库使用
Info:
打印所有 Migrations 的详细和状态信息,是通过 Metadata 表和 Migrations 完成的
能够快速定位当前数据库版本,以及查看执行成功和失败的 Migrations
Validate:
验证已经 Apply 的 Migrations 是否有变更 ,flyway 是默认开启验证的
操作原理是对比 Metadata 表与本地 Migration 的 Checksum 值,如果相同则验证通过,否则验证失败,从而可以防止对已经 Apply 到数据库的本地 Migrations 的无意修改
Baseline:
针对已经存在 Schema 结构的数据库的一种解决方案
实现在非空数据库中新建 Metadata 表,并将 Migrations 应用到该数据库
可以应用到特定的版本,这样在已有表结构的数据库中也可以实现添加 Metadata 表,从而利用 flyway 进行新的 Migrations 的管理
Repair:
修复 Metadata 表,这个操作在 Metadata 表表现错误时很有用
通常有两种用途:
移除失败的 Migration 记录,这个问题针对不支持 DDL 事务的数据库
重新调整已经应用的 Migrations 的 Checksums 的值. 比如,某个 Migration 已经被应用,但本地进行了修改,又期望重新应用并调整 Checksum 值. 不建议对数据库进行本地修改
flyway 的使用
正确创建 Migrations
Migrations: flyway 在更新数据库时使用的版本脚本
一个基于 sql 的 Migration 命名为 V1_ _init_tables.sql, 内容即为创建所有表的 sql 语句
flyway 也支持基于 Java 的 Migration
flyway 加载 Migrations 的默认 Locations 为 classpath:db/migration, 也可以指定 filesystem:/project/folder. Migrations 的加载是在运行时自动递归执行的
除了指定的 Locations 外,flyway 需要遵从命名格式对 Migrations 进行扫描,主要分为两类:
Versioned migrations:
Versioned 类型是常用的 Migration 类型
用于版本升级,每一个版本都有一个唯一的标识并且只能被应用一次. 并且不能再修改已经加载过的 Migrations, 因为 Metadata 表会记录 Checksum 值
其中的 version 标识版本号,由一个或者多个数字构成,数字之间的分隔符可以采用点或者下划线,在运行时下划线也是被替换成点了. 每一部分的前导零都会被省略
Repeatable migrations:
Repeatable 是指可重复加载的 Migrations, 其中每一次更新都会更新 Checksum 值,然后都会被重新加载,并不用于版本升级. 对于管理不稳定的数据库对象的更新时非常有用
Repeatable 的 Migrations 总是在 Versioned 之后按顺序执行,开发者需要维护脚本并确保可以重复执行,通常会在 sql 语句中使用 CREATE OR REPLACE 来保证可重复执行
flyway 数据库
flyway 支持多种数据库:
Oracle
SQL Server
SQL Azure
DB2
DB2 z/OS
MySQL
Amazon RDS
Maria DB
Google Cloud SQL
PostgreSQL
Heroku
Redshift
Vertica
H2
Hsql
Derby
SQLite
SAP HANA
solidDB
Sybase ASE and Phoenix
目前主流使用的数据库有 MySQL,H2,Hsql 和 PostgreSQL. 对应的 flyway.url 配置如下:
flyway 命令行
flyway 命令行工具支持直接在命令行中运行 Migrate,Clean,Info,Validate,Baseline 和 Repair 这 6 种命令
flyway 会依次搜索以下配置文件:
/conf/flyway.conf
/flyway.conf
后面的配置会覆盖前面的配置
SpringBoot 集成 flyway
引入 flyway 依赖:
创建的 springboot 的 maven 项目,配置数据源信息:
在 classpath 目录下新建/db/migration 文件夹,并创建 SQL 脚本:
启动 springboot 项目:
在项目启动时 ,flyway 加载了 SQL 脚本并执行
查看数据库:
默认情况下,生成 flyway-schema-history 表
如果需要指定 schema 表的命名,可以配置属性 : flyway.tableflyway
flyway 配置
部署-Docker
Docker 基本概念
Docker
是用于开发应用,交付应用,运行应用的开源软件的一个开放平台
允许用户将基础设施中的应用单独分割出来,形成更细小的容器,从而提交交付软件的速度
Docker 容器:
类似虚拟机,不同点是:
Docker 容器是将操作系统层虚拟化
虚拟机则是虚拟化硬件
Docker 容器更具有便携性,能够高效地利用服务器
容器更多的是用于表示软件的一个标准化单元,由于容器的标准化,因此可以无视基础设施的差异,部署到任何一个地方
Docker 也为容器提供更强的业界隔离兼容
Docker 利用 Linux 内核中的资源分离机制 cgroups 以及 Linux 内核的 namespace 来创建独立的容器 containers
可以在 Linux 实体下运作,避免引导一个虚拟机造成的额外负担
Linux 内核对 namespace 的支持可以完全隔离工作环境下的应用程序,包括:
线程树
网络
用户 ID
挂载文件系统
Linux 内核的 cgroups 提供资源隔离,包括:
CPU
存储器
block I/O
网络
Docker 基础架构
Docker 引擎
Docker 引擎: Docker Engine
是一个服务端 - 客户端结构的应用
主要组成部分:
Docker 守护进程: Docker daemons,也叫 dockerd.
是一个持久化进程,用户管理容器
Docker 守护进程会监听 Docker 引擎 API 的请求
Docker 引擎 API: Docker Engine API
用于与 Docker 守护进程交互使用的 API
是一个 RESTful API,不仅可以被 Docker 客户端调用,也可以被 wget 和 curl 等命令调用
Docker 客户端: docker
是大部分用户与 Docker 交互的主要方式
用户通过客户端将命令发送给守护进程
命令遵循 Docker Engine API
Docker 注册中心
Docker 注册中心: Docker registry,用于存储 Docker 镜像
Docker Hub: Docker 的公共注册中心,默认情况下,Docker 在这里寻找镜像.也可以自行构建私有的注册中心
Docker 对象
Docker 对象指的是 :Images,Containers,Networks, Volumes,Plugins 等等
镜像: Images
一个只读模板,用于指示创建容器
镜像是分层构建的,定义这些层次的文件叫作 Dockerfile
容器: Containers
镜像可运行的实例
容器可以通过 API 或者 CLI(命令行)进行操作
服务: Services
允许用户跨越不同的 Docker 守护进程的情况下增加容器
并将这些容器分为管理者(managers)和工作者(workers),来为 swarm 共同工作
Docker 扩展架构
Docker Compose
Docker Compose 是用来定义和运行多个容器 Docker 应用程序的工具
通过 Docker Compose, 可以使用 YAML 文件来配置应用程序所需要的所有服务,然后通过一个命令,就可以创建并启动所有服务
Docker Compose 对应的命令为 : docker-compose
Swarm Mode
从 Docker 1.12 以后 ,swarm mode 集成到 Docker 引擎中,可以使用 Docker 引擎 API 和 CLI 命令直接使用
Swarm Mode 内置 k-v 存储功能,特点如下:
具有容错能力的去中心化设计
内置服务发现
负载均衡
路由网格
动态伸缩
滚动更新
安全传输
Swarm Mode 的相关特性使得 Docker 本地的 Swarm 集群具备与 Mesos.Kubernetes 竞争的实力
cluster: 集群
Docker 将集群定义为 - 一群共同作业并提供高可用性的机器
swarm: 群
一个集群的 Docker 引擎以 swarm mode 形式运行
swarm mode 是指 Docker 引擎内嵌的集群管理和编排功能
当初始化一个 cluster 中的 swarm 或者将节点加入一个 swarm 时 ,Docker 引擎就会以 swarm mode 的形式运行
Swarm Mode 原理:
swarm 中的 Docker 机器分为两类:
managers: 管理者. 用于处理集群关系和委派
workers: 工作者. 用于执行 swarm 服务
当创建 swarm 服务时,可以增加各种额外的状态: 数量,网络,端口,存储资源等等
Docker 会去维持用户需要的状态:
比如,一个工作节点宕机后,那么 Docker 就会把这个节点的任务委派给另外一个节点
这里的任务 task 是指: 被 swarm 管理者管理的一个运行中的容器
swarm 相对于单独容器的优点:
修改 swarm 服务的配置后无需重启
Docker 以 swarm mode 形式运行时,可以选择直接启动单独的容器
在 swarm mode 下,可以通过 docker stack deploy 使用 Compose 文件部署应用栈
swarm 服务分为两种:
replicated services: 可以指定节点任务的总数量
global services: 每个节点都会运行一个指定任务
swarm 管理员可以使用 ingress 负载均衡使服务可以被外部接触
swarm 管理员会自动地给服务分配 PublishedPort, 或者手动配置.
外部组件,比如云负载均衡器能通过集群中任何节点上的 PublishedPort 去介入服务,无论服务是否启动
Swarm Mode 有内部 DNS 组件,会为每个服务分配一个 DNS 条目 . swarm 管理员使用 internal load balancing 去分发请求时,就是依靠的这个 DNS 组件
Swarm Mode 功能是由 swarmkit 提供的,实现了 Docker 的编排层,使得 swarm 可以直接被 Docker 使用
文件格式
Docker 有两种文件格式:
Dockerfile: 定义了单个容器的内容和启动时候的行为
Compose 文件: 定义了一个多容器应用
Dockerfile
Docker 可以依照 Dockerfile 的内容,自动化地构建镜像
Dockerfile 包含着用户想要如何构建镜像的所有命令的文本
RUN:
RUN 会在当前镜像的顶层上添加新的一层 layer,并在该层上执行命令,执行结果将会被提交
提交后的结果将会应用于 Dockerfile 的下一步
ENTRYPOINT:
入口点
ENTRYPOINT 允许配置容器,使之成为可执行程序. 即 ENTRYPOINT 允许为容器增加一个入口点
ENTRYPOINT 与 CMD 类似,都是在容器启动时执行,但是 ENTRYPOINT 的操作稳定并且不可被覆盖
通过在命令行中指定 - -entrypoint 命令的方式,可以在运行时将 Dockerfile 文件中的 ENTRYPOINT 覆盖
CMD:
command 的缩写
CMD 用于为已经创建的镜像提供默认的操作
如果不想使用 CMD 提供的默认操作,可以使用 docker run IMAGE [:TAG|@DIGEST] [COMMAND] 进行替换
当 Dockerfile 拥有入口点的情况下,CMD 用于为入口点赋予参数
Compose 文件
Compose 文件是一个 YAML 文件,定义了服务, 网络 和卷:
service: 服务. 定义各容器的配置,定义内容将以命令行参数的方式传给 docker run 命令
network: 网络. 定义各容器的配置,定义内容将以命令行参数的方式传给 docker network create 命令
volume: 卷. 定义各容器的配置,定义内容将以命令行参数的方式传给 docker volume create 命令
docker run 命令中有一些选项,和 Dockerfile 文件中的指令效果是一样的: CMD, EXPOSE, VOLUME, ENV. 如果 Dockerfile 文件中已经使用了这些命令,那么这些指令就被视为默认参数,所以无需在 Compose 文件中再指定一次
Compose 文件中可以使用 Shell 变量:
Compse 文件可通过自身的 ARGS 变量,将参数传递给 Dockerfile 中的 ARGS 指令
网络
bridge
Docker 中的网桥使用的软件形式的网桥
使用相同的网桥的容器连接进入该网络,非该网络的容器无法进入
Docker 网桥驱动会自动地在 Docker 主机上安装规则,这些规则使得不同桥接网络之间不能直接通信
桥接经常用于:
在单独容器上运行应用时,可以通过网桥进行通信
网桥网络适用于容器运行在相同的 Docker 守护进程的主机上
不同 Docker 守护进程主机上的容器之间的通信需要依靠操作系统层次的路由,或者可以使用 overlay 网络进行代替
bridge: 网桥驱动
是 Docker 默认的网络驱动,接口名为 docker0
当没有为容器指定一个网络时,Docker 将使用这个驱动
可以通过 daemon.json 文件修改相关配置
自定义网桥可以通过 brtcl 命令进行配置
host
host: 主机模式
用于单独容器,该网络下容器只能和 Docker 主机进行直接连接
这种 host 主机模式只适用于 Docker 17.06 以后版本的 swarm 服务
host 网络和 VirtualBox 的仅主机网络 Host-only Networking 类似
overlay
overlay: 覆盖模式
网络驱动将会创建分布式网络,该网络可以覆盖若干个 Docker 守护进程主机
overlay 是基于主机特定网络 host-specific networks, 当加密功能开启时,允许 swarm 服务和容器进行安全通信
在覆盖网络 overlay 下,Docker 能够清晰地掌握数据包路由以及发送接收容器
overlay 有两种网络类型网络:
ingress: 是可掌控 swarm 服务的网络流量, ingress 网络是 overlay 的默认网络
docker_gwbridge: 网桥网络, docker_gwbridge 网络会将单独的 Docker 守护进程连接至 swarm 里的另外一个守护进程
在 overlay 网络下:
单独的容器和 swarm 服务的行为和配置概念是不一样的
overlay 策略不需要容器具有操作系统级别的路由,因为 Docker 负责路由
macvlan
macvlan:
允许赋予容器 MAC 地址
在该网络里,容器会被认为是物理设备
none
在该策略下,容器不使用任何网络
none 常常用于连接自定义网络驱动的情况下
其它网络策略模式
要想运用其它网络策略模式需要依赖其它第三方插件
数据管理
在默认情况下,Docker 所有文件将会存储在容器里的可写的容器层 container layer:
数据与容器共为一体: 随着容器的消失,数据也会消失. 很难与其它容器程序进行数据共享
容器的写入层与宿主机器紧紧耦合: 很难移动数据到其它容器
容器的写入层是通过存储驱动 storage driver 管理文件系统: 存储驱动会使用 Linux 内核的链合文件系统 union filesystem 进行挂载,相比较于直接操作宿主机器文件系统的数据卷,这个额外的抽象层会降低性能
容器有两种永久化存储方式:
volumes: 卷
bind mounts: 绑定挂载
Linux 中可以使用 tmpfs 进行挂载, windows 用户可以使用命名管道 named pipe.
在容器中,不管使用哪种永久化存储,表现形式都是一样的
卷
卷: volumes.
是宿主机器文件系统的一部分
由 Docker 进行管理. 在 Linux 中,卷存储于 /var/lib/docker/volumes/
非 Docker 程序不应该去修改这些文件
Docker 推荐使用卷进行持久化数据
卷可以支持卷驱动 volume drivers: 该驱动允许用户将数据存储到远程主机或云服务商 cloud provider 或其它
没有名字的卷叫作匿名卷 anonymous volume. 有名字的卷叫作命名卷 named volume. 匿名卷没有明确的名字,当被初始化时,会被赋予一个随机名字
绑定挂载
绑定挂载: bind mounts
通过将宿主机器的路径挂载到容器里的这种方式,从而实现数据持续化,因此绑定挂载可将数据存储在宿主机器的文件系统中的任何地方
非 Docker 程序可以修改这些文件
绑定挂载在 Docker 早起就已经存在,与卷存储相比较,绑定挂载十分简单明了
在开发 Docker 应用时,应使用命名卷 named volume 代替绑定挂载,因为用户不能对绑定挂载进行 Docker CLI 命令操作
绑定挂载的使用场景:
同步配置文件
将宿主机的 DNS 配置文件(/etc/resolv.conf)同步到容器中
在开发程序过程中,将源代码或者 Artifact 同步至容器中. 这种用法与 Vagrant 类似
tmpfs 挂载
tmpfs 挂载: tmpfs mounts
仅仅存储于内存中,不操作宿主机器的文件系统.即不持久化于磁盘
用于存储一些非持久化状态,敏感数据
swarm 服务通过 tmpfs 将 secrets 数据(密码,密钥,证书等)存储到 swarm 服务
命名管道
命名管道: named pipes
通过 pipe 挂载的形式,使 Docker 主机和容器之间互相通讯
在容器内运行第三方工具,并使用命名管道连接到 Docker Engine API
覆盖问题
当挂载空的卷至一个目录中,目录中你的内容会被复制于卷中,不会覆盖
如果挂载非空的卷或绑定挂载至一个目录中,那么该目录的内容将会被隐藏 obscured,当卸载后内容将会恢复显示
日志
在 Linux 和 Unix 中,常见的 I/O 流分为三种:
STDIN: 输入
STDOUT: 正常输出
STDERR: 错误输出
默认配置下,Docker 的日志所记载的是命令行的输出结果:
STDOUT : /dev/stdout
STDERR : /dev/stderr
也可以在宿主主机上查看容器的日志,使用命令可以查看容器日志的位置:
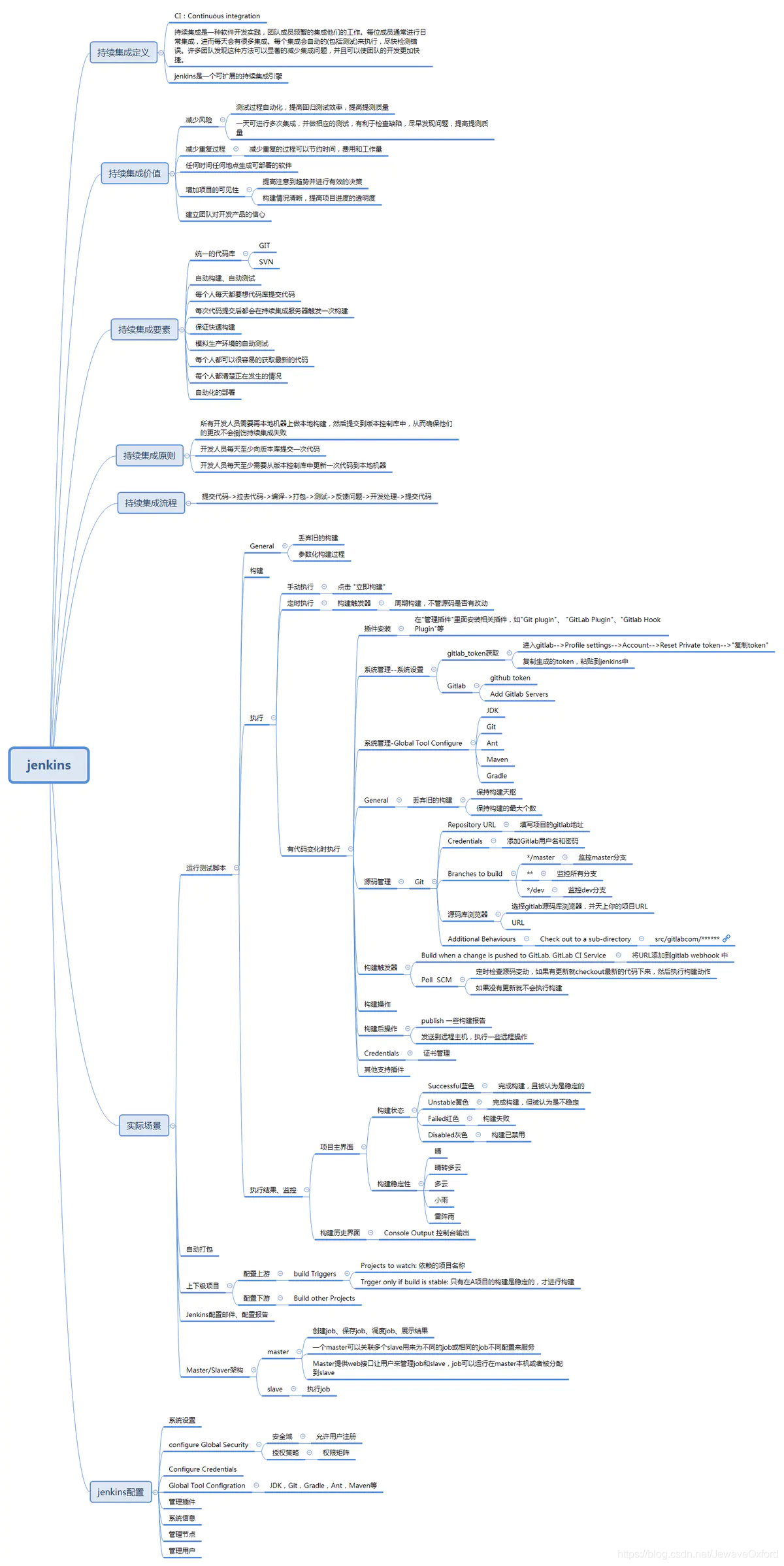
持续集成-jenkins
jenkins 基本概念
jenkins 是一个开源的,提供友好操作页面的持续集成(CI)工具
jenkins 主要用于持续,自动的构建或者测试软件项目,监控外部任务的运行
jenkins 使用 Java 语言编写,可以在 Tomcat 等流行的 servlet 容器中运行,也可以独立运行
通常与版本管理工具 SCM, 构建工具结合使用
常用的版本控制工具有 SVN,GIT
常见的构建工具有 Maven,Ant,Gradle
CI/CD
CI: Continuous integration, 持续集成
持续集成强调开发人员提交新代码之后,like 进行构建,单元测试
根据测试结果,可以确定新代码和原有代码能否正确地合并在一起
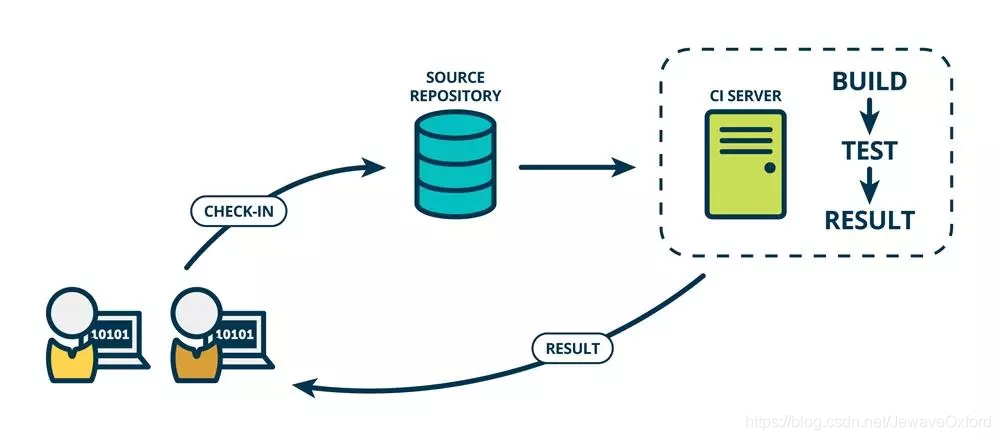
CD: Continuous Delivery, 持续交付
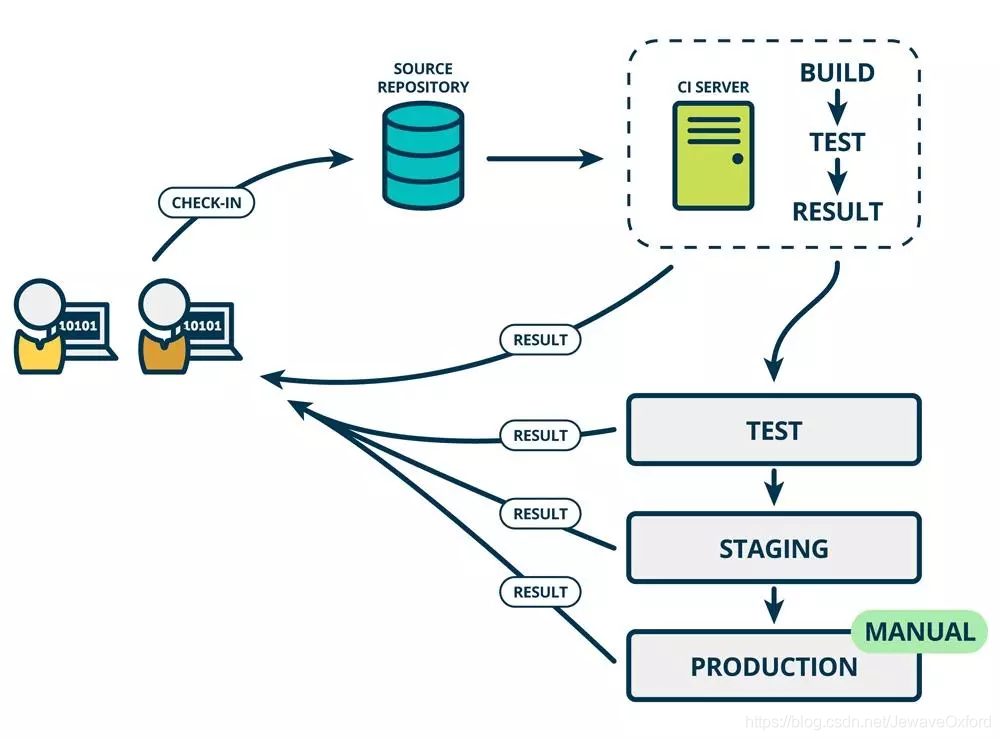
在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境中,即类生产环境中
比如在完成单元测试后,可以将代码部署到连接数据库的 Staging 环境中进行更多的测试
如果代码没有问题,可以继续手动部署到生产环境
jenkins 使用配置
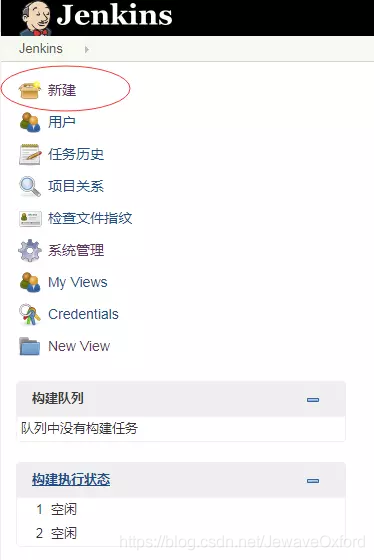
登录 jenkins,点击新建,创建一个新的构建任务:
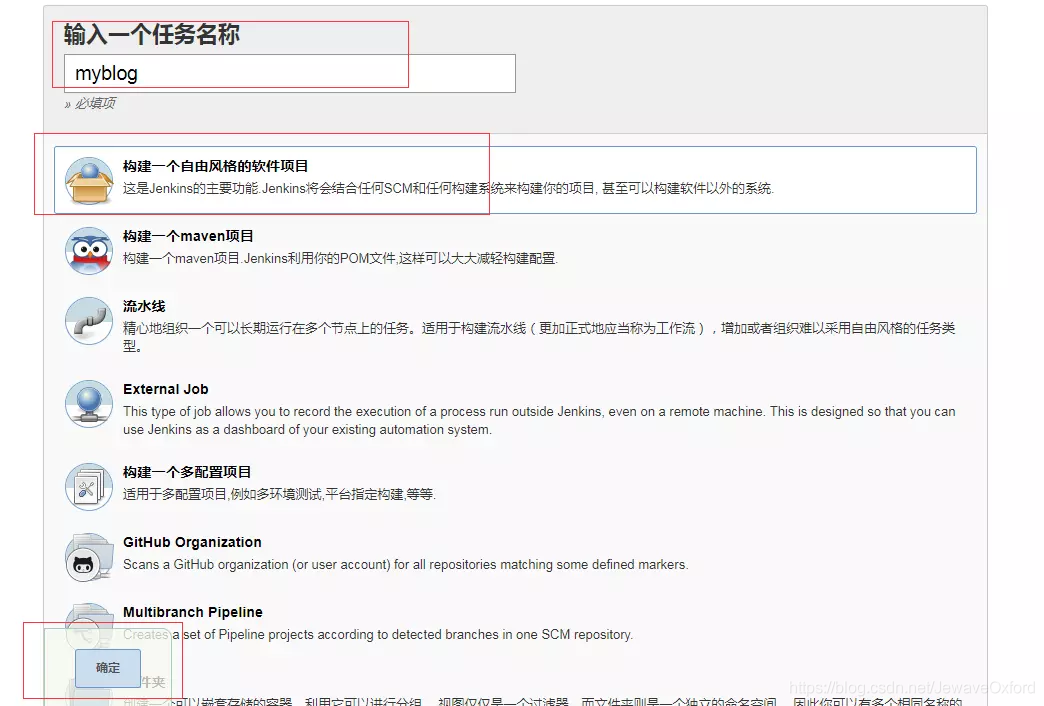
跳转到新建界面:
任务名称可以自行设定,但需要全局唯一
输入名称后,选择构建一个自由风格的软件项目
点击下方的创建按钮
这样就创建了一个构建任务,然后会跳转到该任务的配置页面
在构建任务页面,可以看到几个选项:
General
源码管理
构建触发器
构建环境
构建
构建后操作
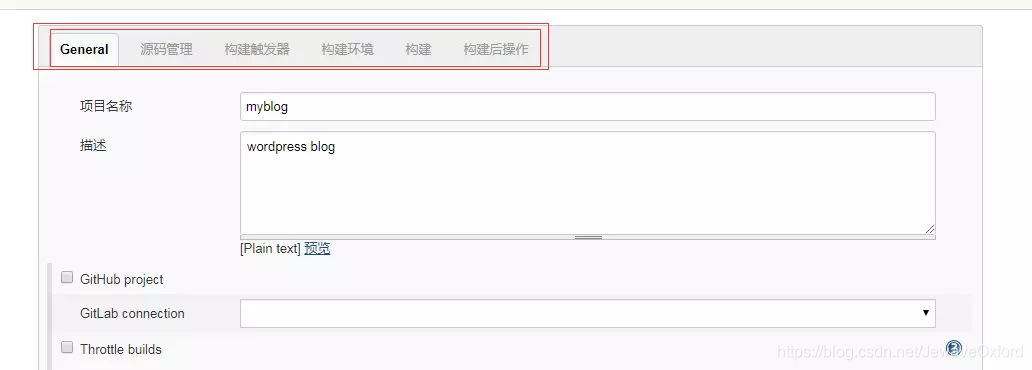
General
General 用于构建任务的一些基本配置: 名称,描述等
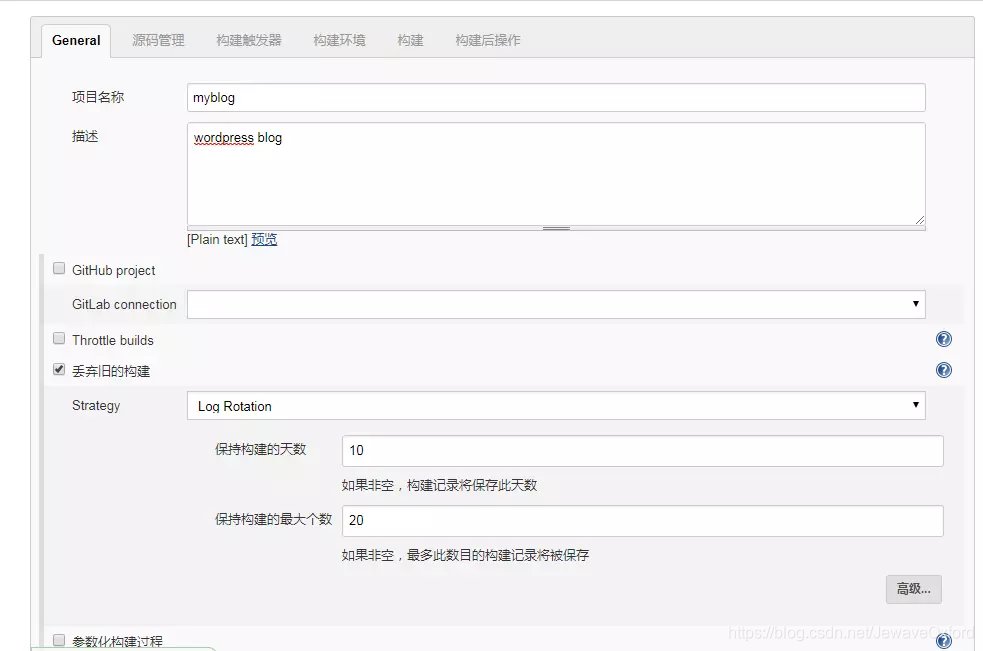

项目名称: 刚才创建构建任务设置的名称,可以在这里进行修改
描述: 对构建任务的描述
丢弃旧的构建: 服务资源是有限的,如果保存太多的历史构建,会导致 jenkins 速度变慢,并且服务器硬盘资源也会被占满
保持构建天数: 可以自定义,根据实际情况确定一个合理的值
保持构建的最大个数: 可以自定义,根据实际情况确定一个合理的值
源码管理
源码管理用于配置代码的存放位置
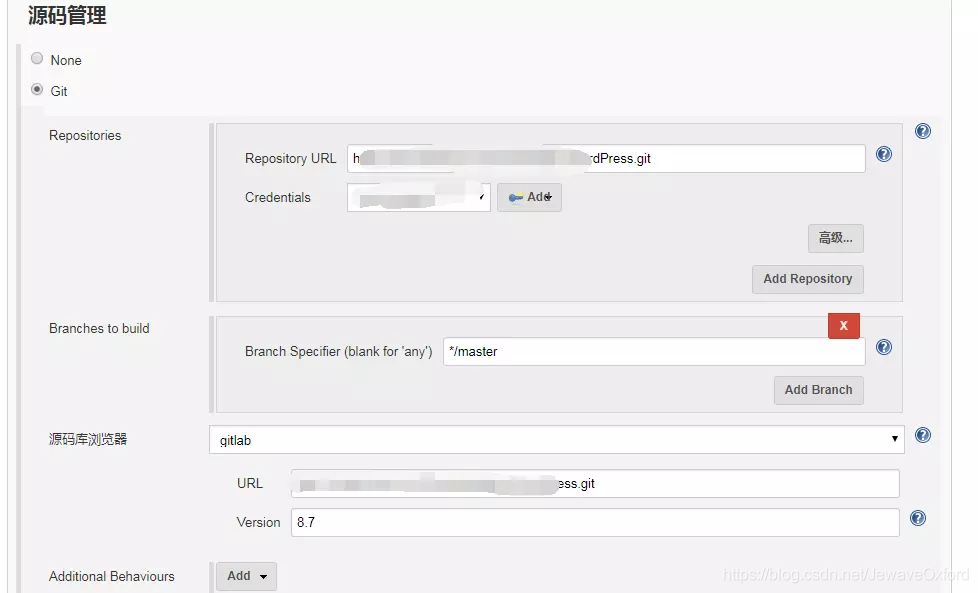
Git: 支持主流的 github 和 gitlab 代码仓库
Repository URL: 仓库地址
Credentials: 凭证. 可以使用 HTTP 方式的用户名和密码,也可以是 RSA 文件.但是要通过后面的[ADD]按钮添加凭证
Branches to build: 构建分支. */master 表示 master 分支,也可以设置为另外的分支
源码浏览器: 所使用的代码仓库管理工具,如 github,gitlab
URL: 填入上方的仓库地址即可
Version: gitlab 服务器版本
Subversion: 就是 SVN
构建触发器
构建任务的触发器
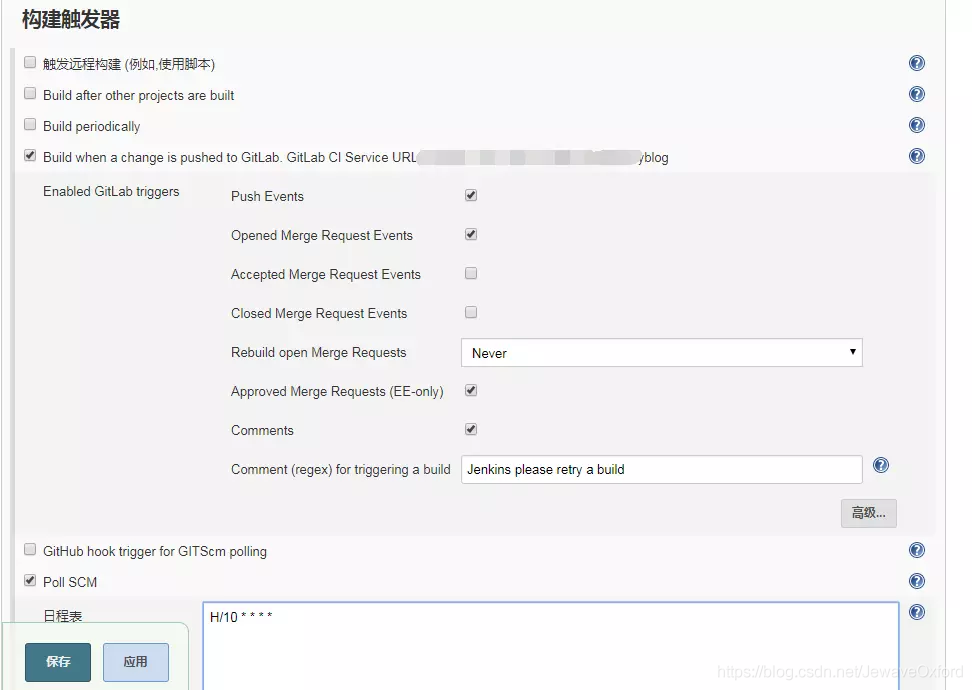
触发远程构建(例如,使用脚本): 这个选项会提供一个接口,可以用来在代码层面触发构建
Build after other project are built: 在其它项目构建后构建
Build periodically: 周期性地构建.每隔一段时间进行构建
日程表: 类似 linux cronttab 书写格式. 下图表示每隔 30 分钟进行一次构建
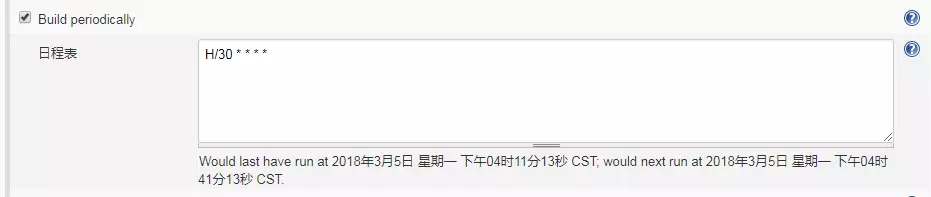
Build when a change is pushed to Gitlab: 常用的构建触发器,当有代码 push 到 gitlab 代码仓库时就进行构建
webhooks: 触发构建的地址,需要将这个地址配置到 gitlab 中
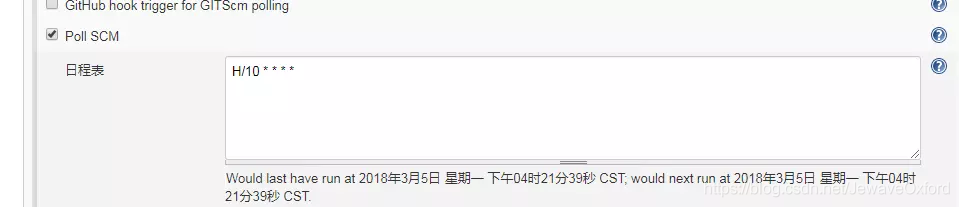
Poll SCM: 这个功能需要与上面的这个功能配合使用. 当代码仓库发生变动时,jekins 并不知道. 这时,需要配置这个选项,周期性地检查代码仓库是否发生变动
构建环境
构建环境: 构建之前的准备工作. 比如指定构建工具,这里使用 Ant
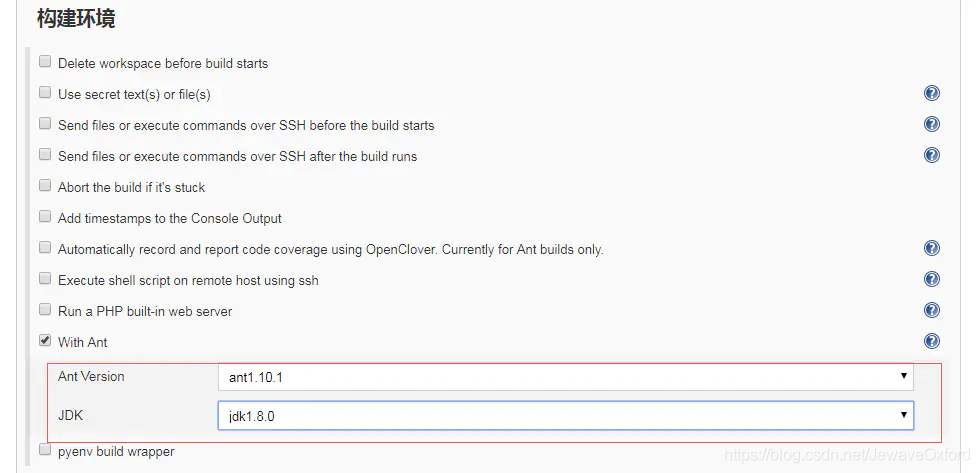
With Ant: 选择这个选项,并指定 Ant 版本和 JDK 版本. 需要事先在 jenkins 服务器上安装这两个版本的工具,并且在 jenkins 全局工具中配置好
构建
点击下方的增加构建步骤:
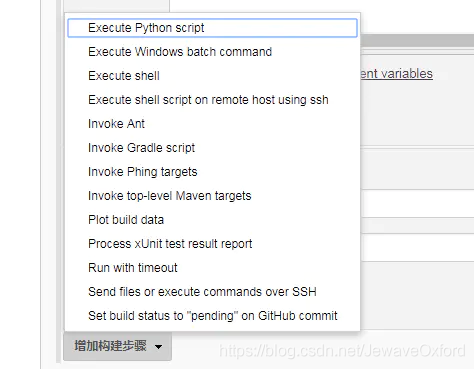
这里有多种增加构建步骤的方式,在这里介绍 Execute shell 和 Invoke Ant
Execute shell: 执行 shell 命令. 该工具是针对 linux 环境的,windows 中对应的工具是 [Execute Windows batch command]. 在构建之前,需要执行一些命令: 比如压缩包的解压等等
Invoke Ant: Ant 是一个 Java 项目构建工具,也可以用来构建 PHP
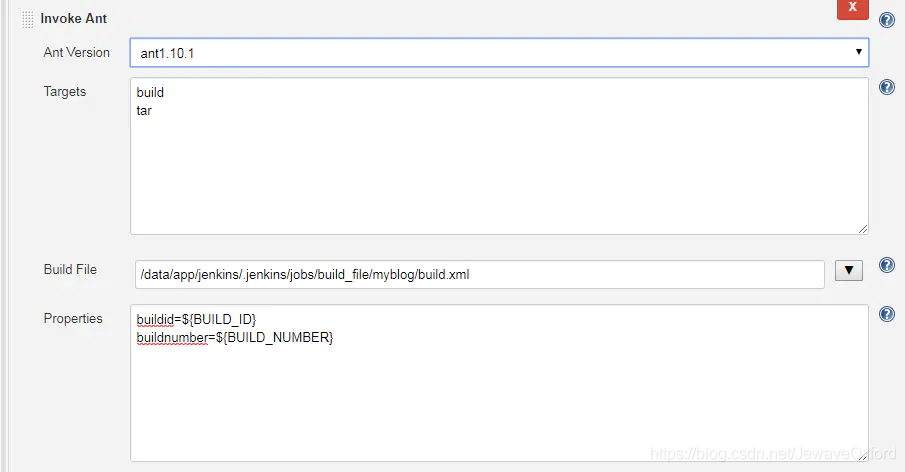
Ant Version: 选择 Ant 版本. 这个 Ant 版本是安装在 jenkins 服务器上的版本,并且需要在 jenkins[系统工具]中设置好
Targets: 需要执行的操作. 一行一个操作任务: 比如上图的 build 是构建,tar 是打包
Build File: Ant 构建的配置文件. 如果不指定,默认是在项目路径下的 workspace 目录中的 build.xml
properties: 设定一些变量. 这些变量可以在 build.l 中被引用
Send files or execute commands over SSH: 发送文件到远程主机或者执行命令脚本
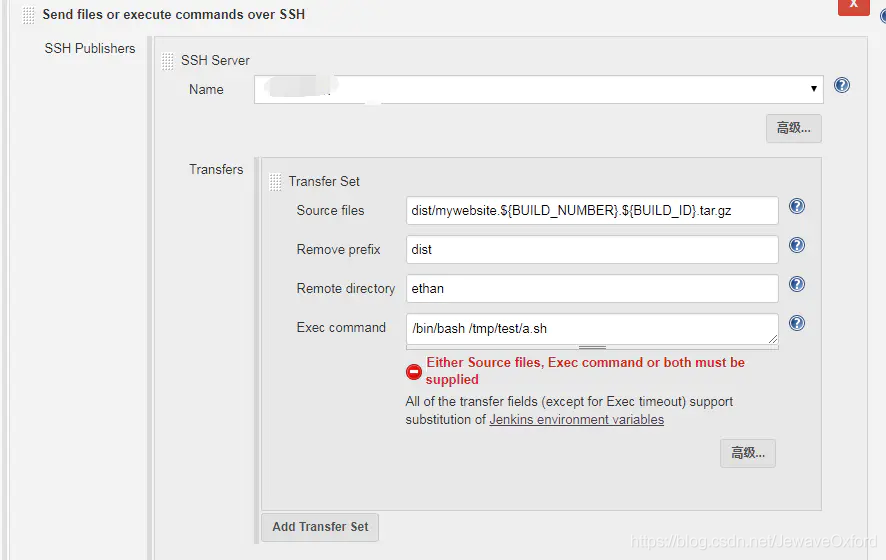
Name: SSH Server 的名称. SSH Server 可以在 jenkins[系统设置]中配置
Source files: 需要发送给远程主机的源文件
Remove prefix: 移除前面的路径. 如果不设置这个参数,默认情况下远程主机会自动创建构建源 source file 包含的路径
Romote directory: 远程主机目录
Exec command: 在远程主机上执行的命令或者脚本
构建后操作
构建后操作: 对构建完成的项目完成一些后续操作:比如生成相应的代码测试报告
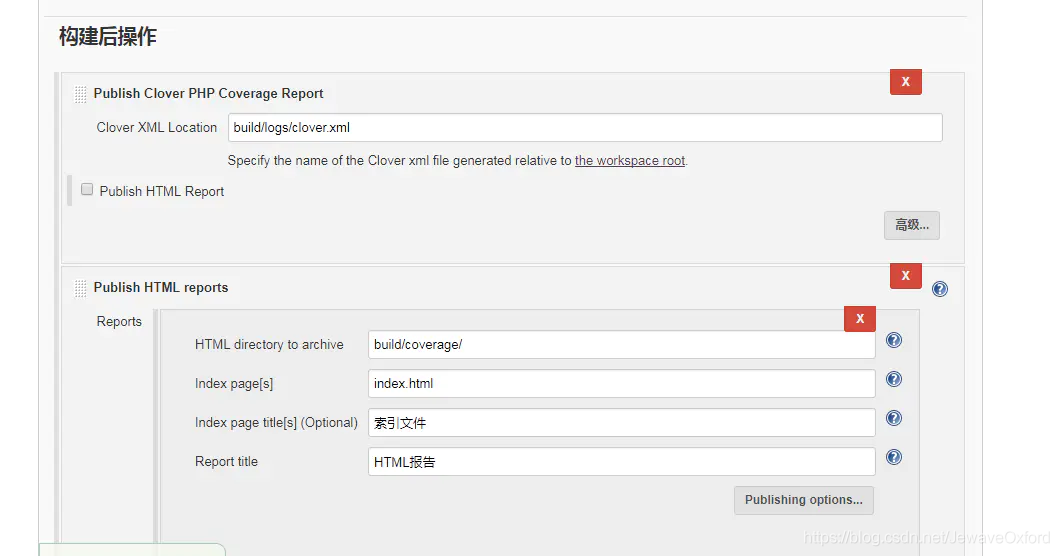
Publish Clover PHP Coverage Report: 发布代码覆盖率的 xml 格式的报告. 路径在 build.xml 中定义
Publish HTML reports: 发布代码覆盖率的 HTML 报告
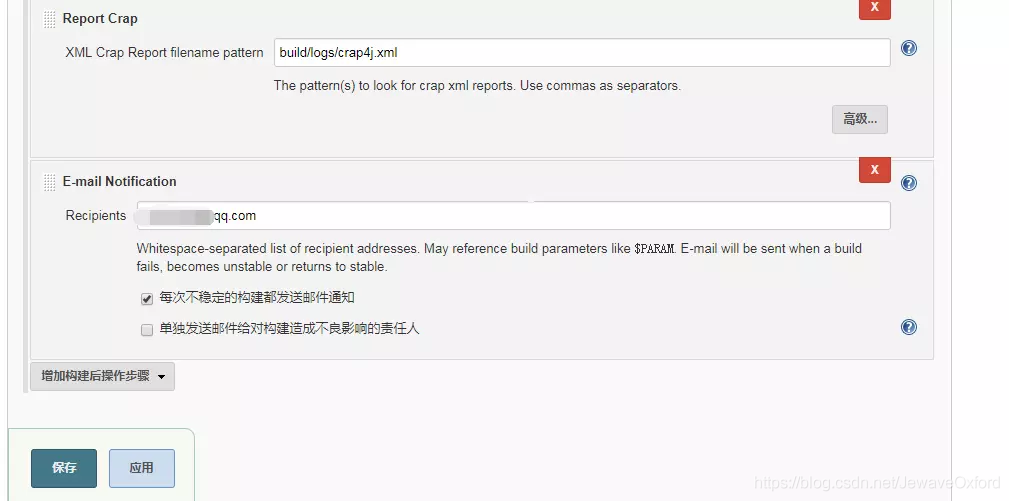
Report Crap: 发布 Crap 报告
E-mail Notification: 邮件通知. 构建完成后发送邮件到指定的邮箱配置完成后,点击[保存]
其它配置
SSH Server 配置
登录 jenkins
系统管理
系统设置
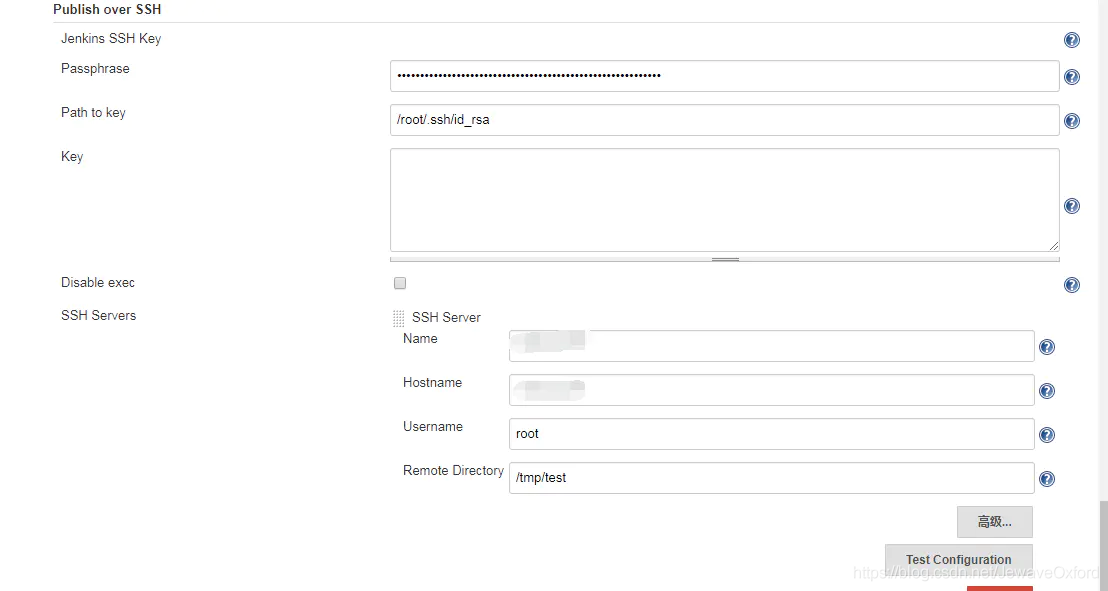
SSH Servers: jenkins 服务器公钥文件配置好之后新增 SSH Server 只需要配置这一个选项即可
name: 服务名称.自定义,需要全局唯一
HostName: 主机名. 直接使用 IP 地址即可
Username: 新增 Server 的用户名,这里配置的是 root
Remote Directory: 远程目录. jenkins 服务器发送文件给新增的 server 时默认在这个目录
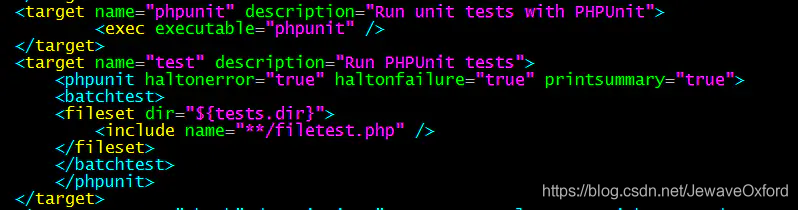
Ant 配置文件 - build.xml
Ant 构建配置文件 build.xml :
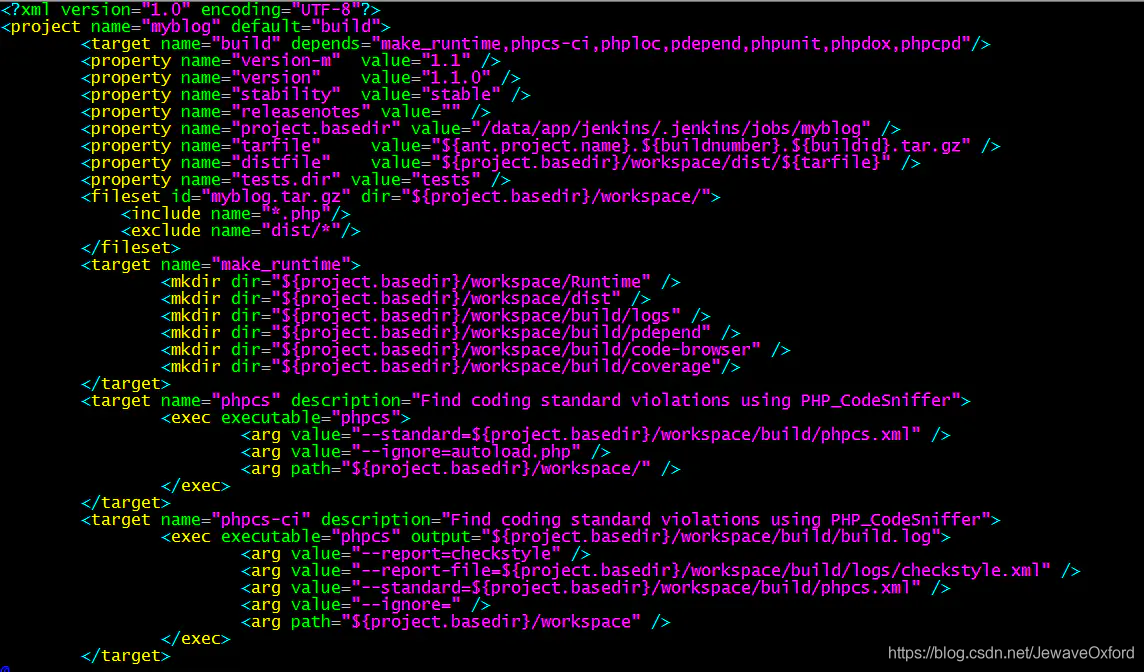
project name: 项目名称. 和 jenkins 所构建的项目名称对应
target name="build": 构建的名称. 和 jekins 构建步骤中的 targets 对应.
depends: 指明构建需要进行的一些操作
property: 用来设置变量
fileset: 指明一个文件夹
include: 指明需要包含的文件
exclude: 指明不需要包含的文件
tar: 打包这个文件夹匹配到的文件
target: 实际的操作步骤:
make_runtime: 创建一些目录
phpcs: 利用 PHP_CodeSniffer 工具对 PHP 代码规范与质量检查工具
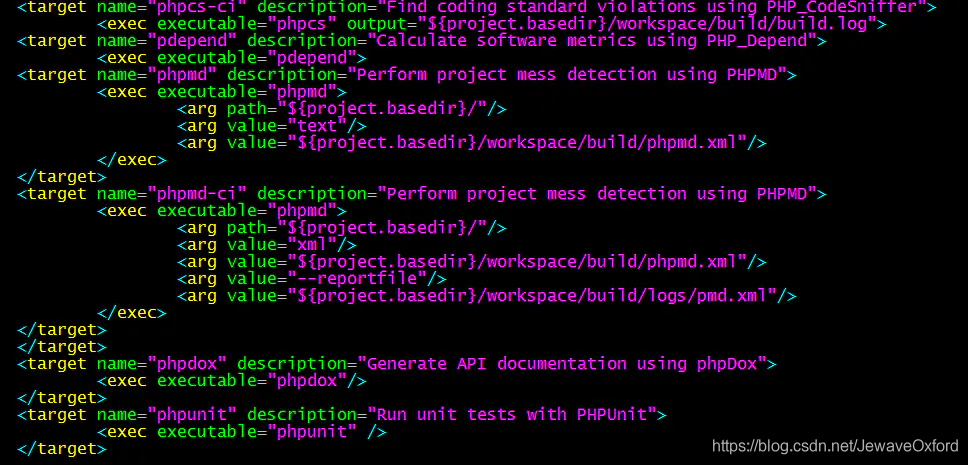
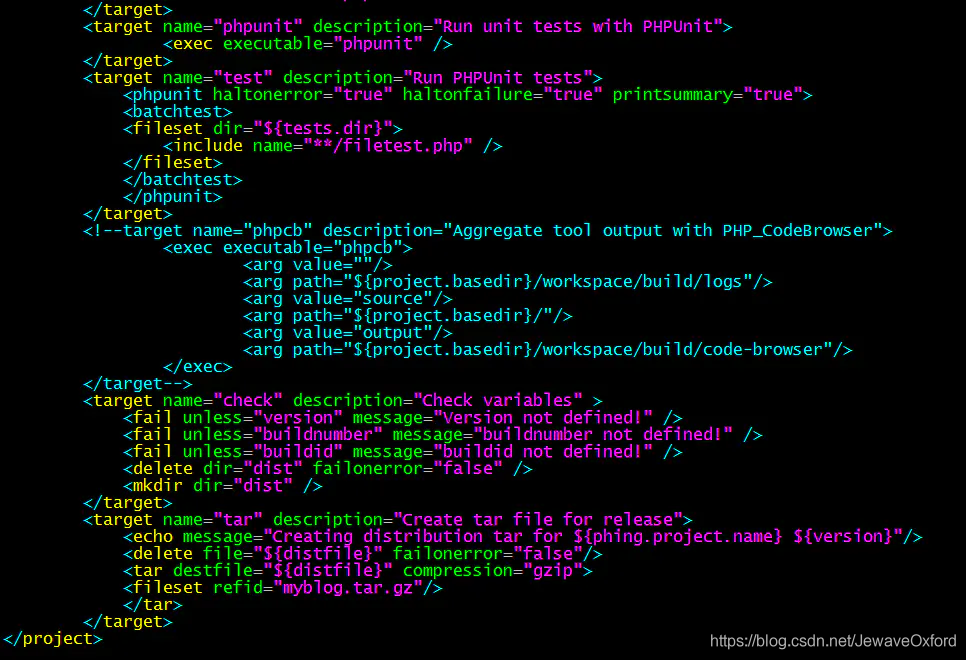
target name="tar": 打包文件
因为 build 中没有包含这个 target.所以默认情况下,执行 build 是不会打包文件的
所以在 jenkins 配置界面中 Ant 构建步骤中的[targets],才会有[build]和[tar]这两个 targets
如果 build.xml 中 build 这个 target depends 中已经包含 tar, 就不需要在 jenkins 中增加 tar 了
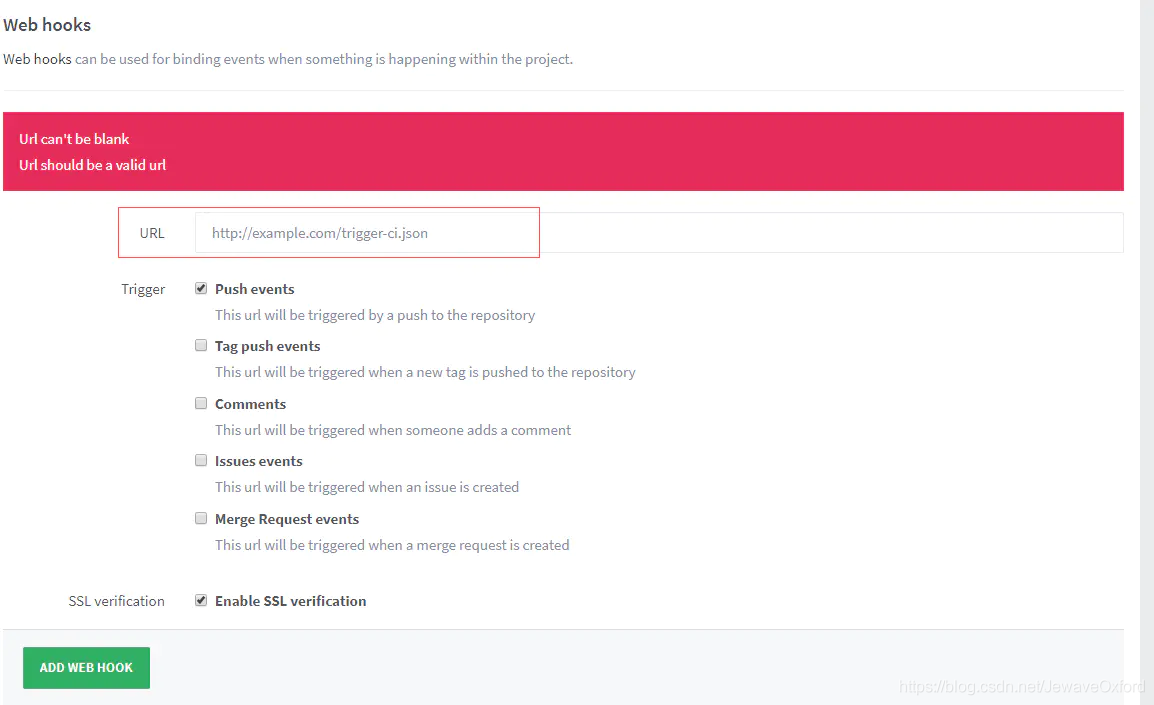
配置 Gitlab webhooks
在 gitlab 的 project 页面打开 settings
打开 web hooks
点击**[ADD WEB HOOK]** 来添加 webhook
将之前的 jenkins 配置中的 url 添加到这里
添加完成后,点击 [TEST HOOK] 进行测试,如果显示 SUCCESS 则表示添加成功
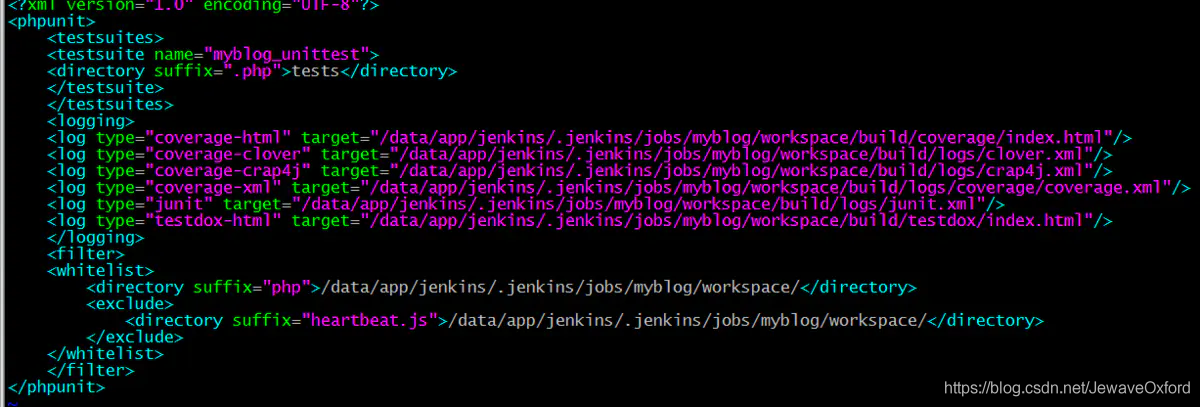
配置 phpunit.xml
phpunit.xml: 是 phpunit 工具用来单元测试所需要的配置文件
这个文件的名称是可以自定义的,只要在 build.xml 中配置好名字即可
默认情况下,如果使用 phpunit.xml, 就不需要在 build.xml 中配置文件名
fileset dir: 指定单元测试文件所在路径.
include: 指定包含哪些文件,支持通配符
exclude: 指定不包含的文件
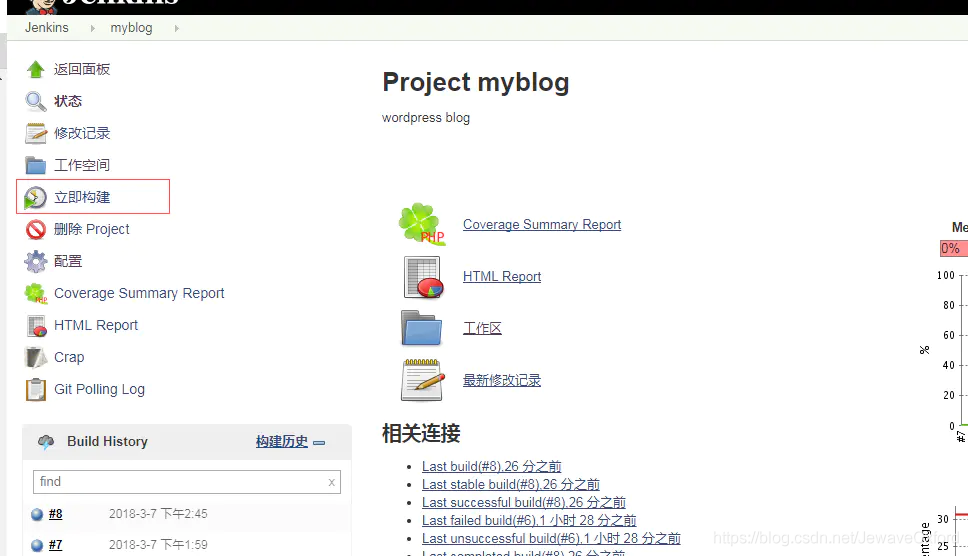
构建 jenkins project
第一次配置好 jenkins project 后,会触发一次构建
此后,每当有 commit 提交到 master 分支(根据配置中的分支触发), 就会触发一次构建
也可以在 project 页面手动触发构建: 点击 [立即构建] 即可手动触发构建
构建结果说明
构建状态
Successful: 蓝色. 构建完成,并且是稳定的
Unstable: 黄色. 构建完成,但是是不稳定的
Failed: 红色. 构建失败
Disable: 灰色. 构建已禁用
构建稳定性
构建稳定性用天气表示: 天气越好表示构建越稳定
晴
晴转多云
多云
小雨
雷阵雨
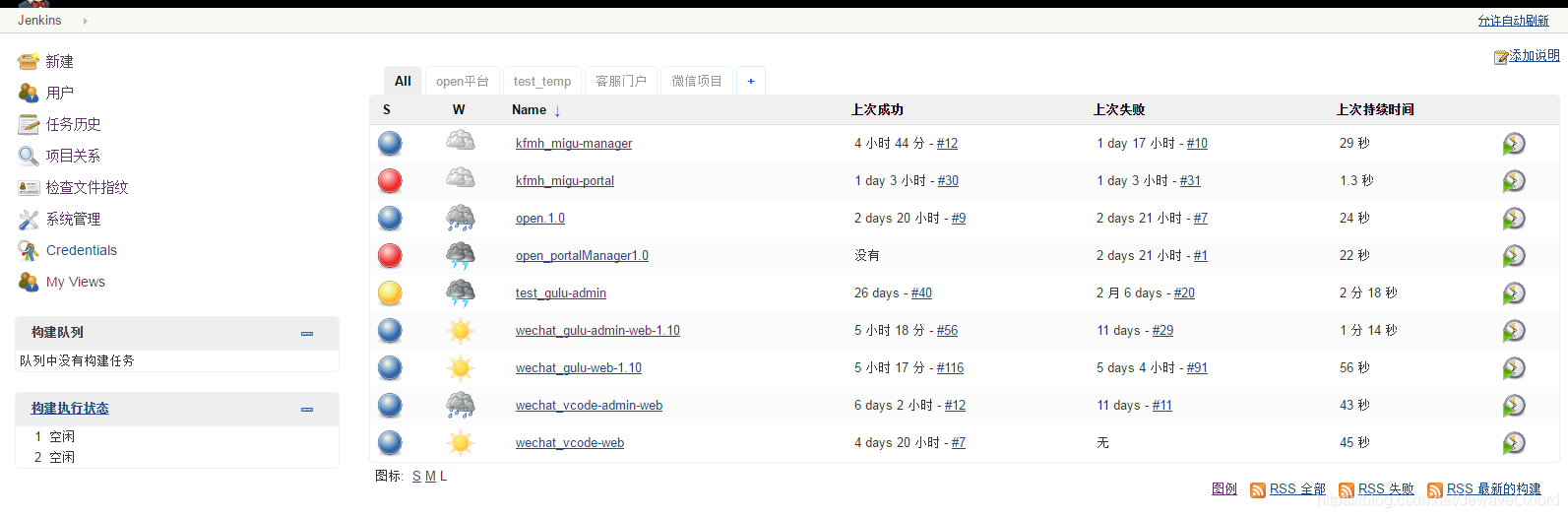
构建历史界面
console output: 输出构建的日志信息
jenkins 权限管理
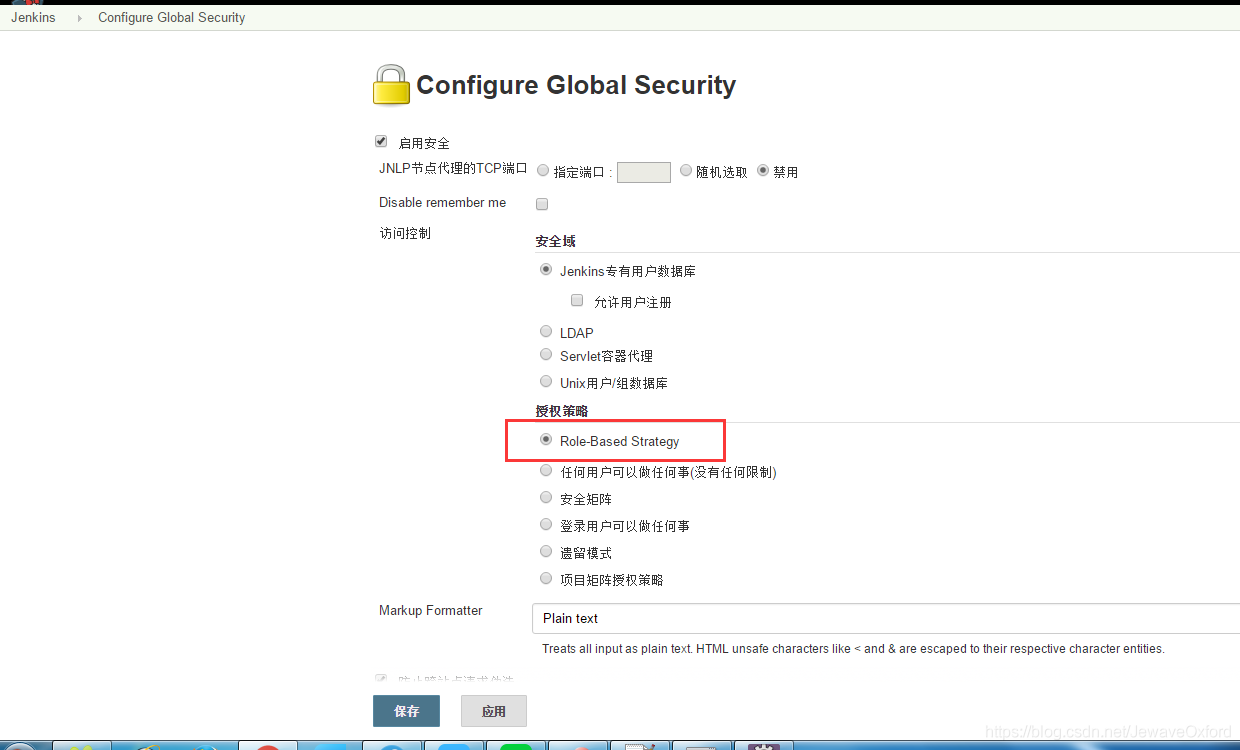
jenkins 中默认的权限管理体系不支持用户组和角色配置,因此需要安装第三方插件来支持角色的配置
使用 Role Strategy Plugin 进行权限管理:
项目视图:
安装 Role Strategy Plugin 插件
安装 Role Stratey Plugin 后进入系统设置页面,按照如下配置后,点击 [保存] :
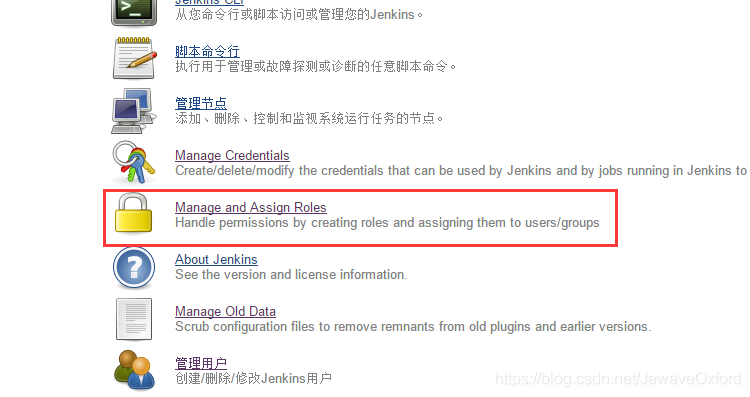
点击 [系统管理] -> [Manage and Assign Roles] 进入角色管理页面:
选择 [Manager Roles], 按照下图配置后点击 [保存]:
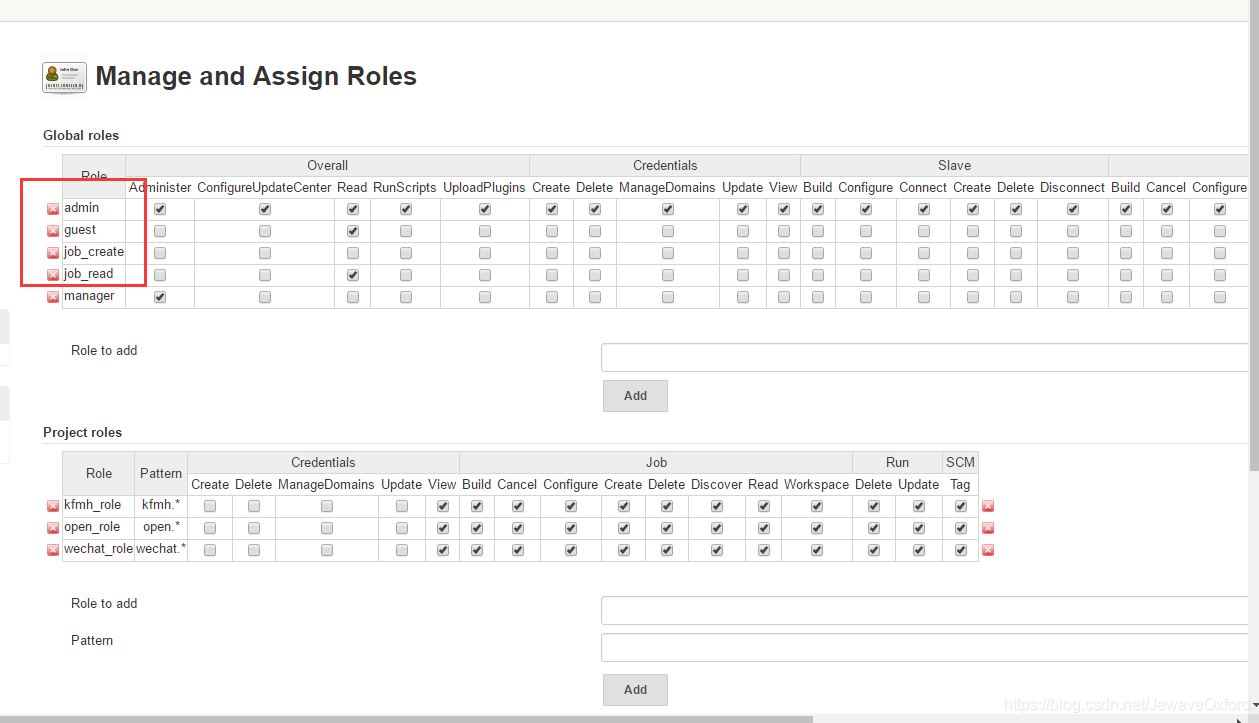
job_read 只加 overall 的 read 权限
job_create 只加 job 的 create 权限
project roles 中 Pattern 正则表达式和脚本里的是不一样的:
比如过滤 TEST 开头的 jobs,要写成 : TEST.,而不是 TEST
进入**[系统设置]** -> [Manage and Assign Roles] -> [Assign Roles] , 按照如下模板配置后,点击 [保存]
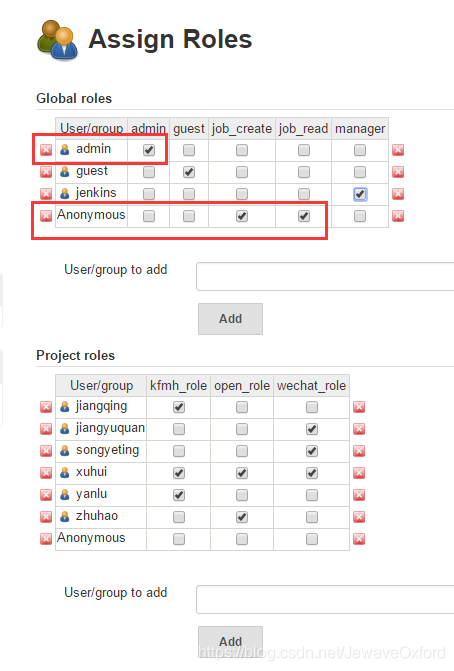
Anonymous 必须变成用户,给 job_create 组和 job_read 组权限,否则将没有 OverAll 的 read 权限
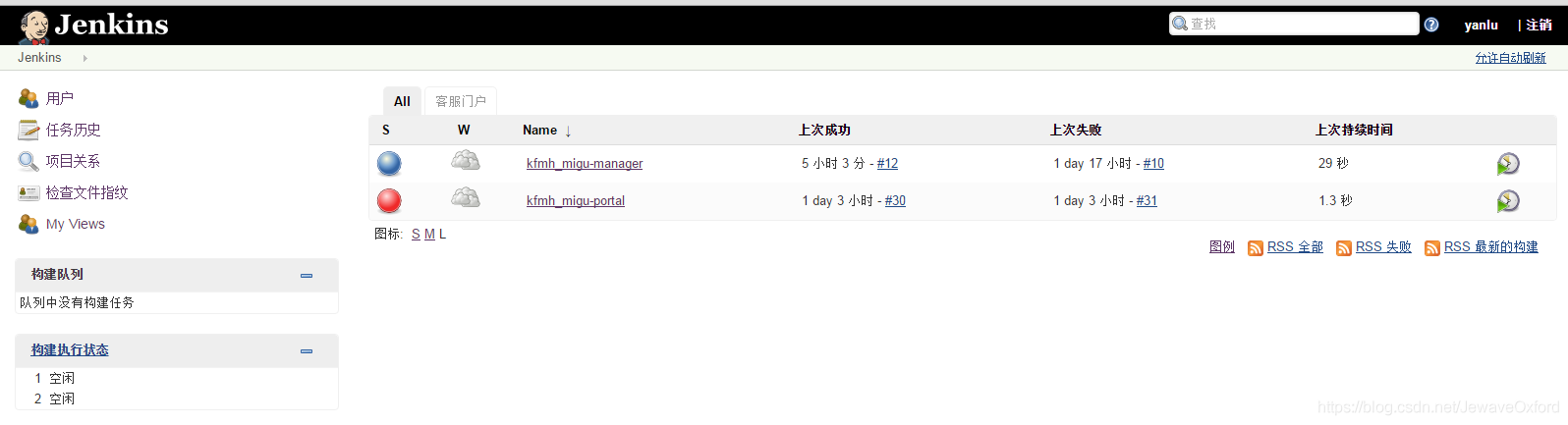
project roles: 用于对应用户不同的权限
验证: 登录对应的用户权限后查看用户相关权限
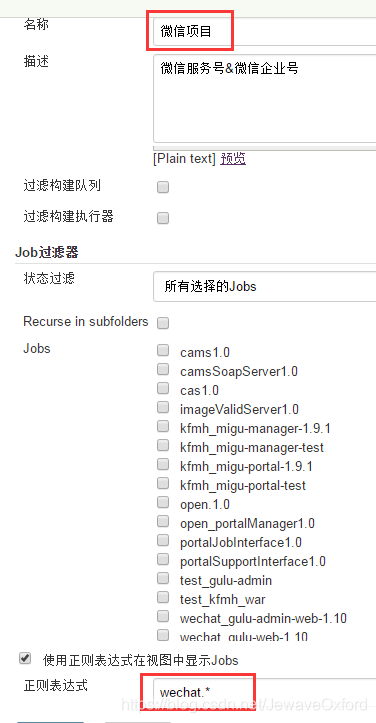
视图通过正则表达式过滤 job: 设置正则表达式为 wechat.*,表示过滤所有以 wechat 开头的项目
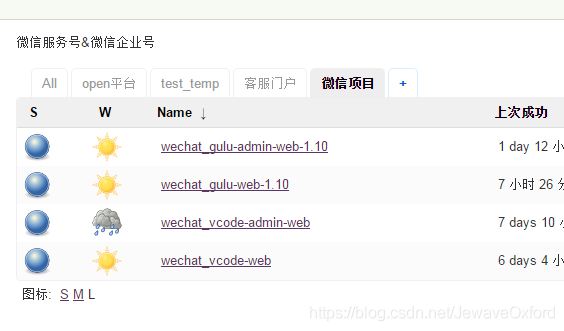
设置后的效果如图:
自动化测试-TestNG
TestNG 基本概念
TestNG 是一个 Java 语言的开源测试框架,类似 JUnit 和 NUnit,但是功能强大,更易于使用
TestNG 的设计目标是为了覆盖更广泛的测试类别范围:
单元测试
功能测试
端到端测试
集成测试
TestNG 的主要功能:
支持注解
支持参数化和数据驱动测试: 使用 @DataProvider 或者 XML 配置
支持同一类的多个实例: @Factory
灵活的执行模式:
TestNG 的运行,既可以通过 Ant 的 build.xml: 有或这没有一个测试套定义. 又可以通过带有可视化效果的 IDE 插件
不需要 TestSuite 类,测试包,测试组以及选择运行的测试. 都通过 XML 文件来定义和配置
并发测试:
测试可以运行在任意大的线程池中,并有多种运行策略可以选择: 所有方法都有自己的线程,或者每一个测试类一个线程等等
测试代码是否线程安全
嵌入 BeanShell 可以获得更大的灵活性
默认使用 JDK 运行和相关日志功能,不需要额外增加依赖
应用服务器测试的依赖方法
分布式测试: 允许在从机上进行分布式测试
TestNG 环境配置
配置好主机的 Java 环境,使用命令 java -version 查看
在 TestNG 官网,下载 TestNG 对应系统下的 jar 文件
系统环境变量中添加指向 jar 文件的路径
在 IDEA 中安装 TestNG
TestNG 的基本用法
TestNG 的基本注解
testng.xml
在 suite 中,同时使用 parallel 和 thread-count:
parallel: 指定并行测试范围 tests,methods,classes
thread-count: 并行线程数
preserve-order: 当设置为 true 时,节点下的方法按顺序执行
verbose: 表示记录日志的级别,在 0 - 10 之间取值
< parameter name="userName", value="15952031403" > : 给测试代码传递键值对参数,在测试类中通过注解 @Parameter({"userName"}) 获取
参数化测试
当测试逻辑一样,只是参数不一样时,可以采用数据驱动测试机制,避免重复代码
TestNG 通过 @DataProvider 实现数据驱动
使用 @DataProvider 做数据驱动:
数据源文件可以是 EXCEL,XML,甚至可以是 TXT 文本
比如读取 xml 文件:
通过 @DataProvider 读取 XML 文件中的数据
然后测试方法只要标示获取数据来源的 DataProvider
对应的 DataProvider 就会将读取的数据传递给该 test 方法
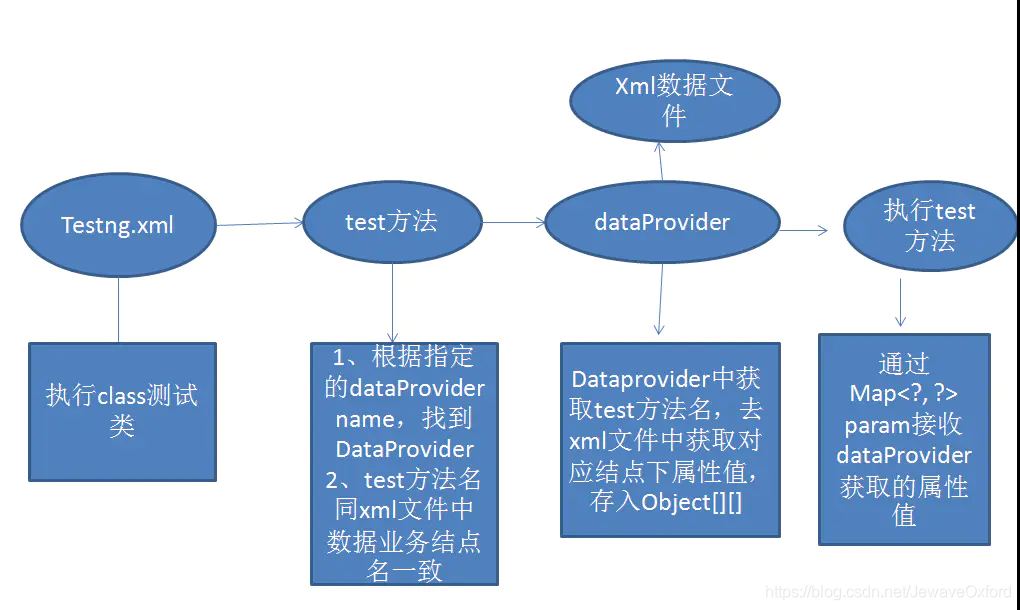
构建 XML 数据文件
读取 XML 文件
DataProvider 类
在 test 方法中引用 DataProvider
xml 中的父节点与 test 的方法名对应:
xml 中同名父节点的个数就意味着该 test 方法会被重复执行多少次
当 DataProvider 与 test 方法不在同一个类时,需要指明 DataProvider 类:
@Test(dataProvider="dataProvider", dataProviderClass= GenerateData.class)
TestNG 重写监听类
TestNG 会监听每个测试用例的运行结果.可以使用监听定制一些自定义的功能,比如自动截图,发送数据给服务器:
新建一个继承自 TestListenerAdapter 的类
重写完成后,在 test 方法前添加 @Listener(TestNGListener.class) 注解
运行测试
版权声明: 本文为 InfoQ 作者【攻城狮Chova】的原创文章。
原文链接:【http://xie.infoq.cn/article/c18cfdc85d177d7fb1902c061】。文章转载请联系作者。

一位攻城狮的自我修养 2021.04.06 加入
分享技术干货,面试题和攻城狮故事。 你的关注支持是我持续进步的最大动力! https://github.com/ChovaVea








评论