JMeter 压力测试,mysql 性能调优与架构设计
2、Keep-Alive 模式
我们知道 Http 协议采用“请求-应答”模式,当使用普通模式,即非 Keep-Alive 模式时,每个请求/应答,客户端和服务器都要新建一个连接,完成之后立即断开连接;当使用 Keep-Alive 模式时,Keep-Alive 功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive 功能避免了建立或者重新建立连接。
http1.0 中默认是关闭的,需要在 http 头加入”Connection: Keep-Alive”,才能启用 Keep-Alive;
http 1.1 中默认启用 Keep-Alive,如果加入”Connection: close “才关闭。目前大部分浏览器都是用 http1.1 协议,也就是说默认都会发起 Keep-Alive 的连接请求了,所以是否能完成一个完整的 Keep- Alive 连接就看服务器设置情况。
开启 Keep-Alive 的优缺点:
优点:Keep-Alive 模式更加高效,因为避免了连接建立和释放的开销。
缺点:长时间的 Tcp 连接容易导致系统资源无效占用,浪费系统资源。
3、自动重定向与跟随重定向
Redirect Automatically(自动重定向):只针对 Get 和 Head 请求,勾选此项则“跟随重定向”失效;自动重定向可以自动转向到最终目标页面,但是 Jmeter 是不记录重定向的过程内容,比如在察看结果树中是无法找到重定向过程内容的(A 重定向到 B,此时只记录 B 的内容不去记录 A 的内容)
Follow Redirects(跟随重定向):Http Request 取样器的默认选项,当响应 code 是 3xx 时(301 永久性转移,302 暂时性转移),自动跳转到目标地址。与自动重定向不同,Jmeter 会记录重定向过程中的所有请求响应,在查看结果树时可以看到服务器返回的内容,所以此时可以对响应的内容做关联。
四、JMeter 工具常用界面设置
1、线程组
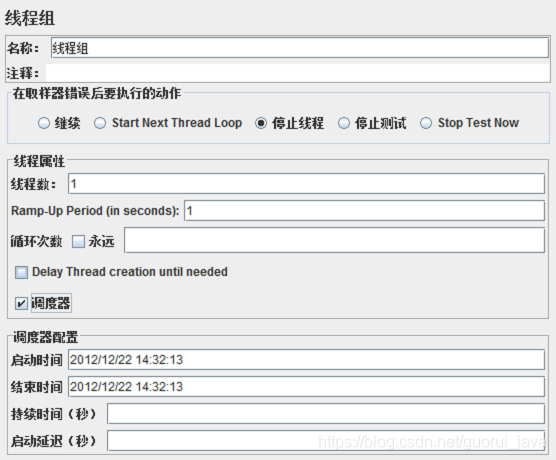
1、线程数:表示启动的线程数,也就是并发的数量。
2、Ramp-Up Period:表示 1 秒内启动 1 个线程,默认为 0,表示程序启动后,立即开启 1 个线程,设置太大或太小都不是很好,设置的最佳值,Ramp-Up Period = 线程数/吞吐量。
3、循环次数:表示每个线程要发送多少次请求。
4、调度器:顾名思义,持续时间如果设置为 60,表示持续 1 分钟,通常循环次数和调度器设置一个即可。
2、添加 HTTP 请求
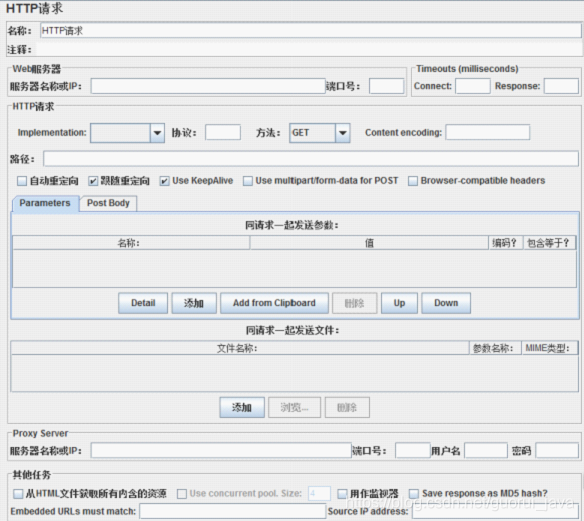
一个 HTTP 请求有着许多的配置参数,下面将详细介绍:
1、名称:本属性用于标识一个取样器,建议使用一个有意义的名称。
2、注释:对于测试没有任何作用,仅用户记录用户可读的注释信息。
3、服务器名称或 IP?:HTTP 请求发送的目标服务器名称或 IP 地址。
4、端口号:目标服务器的端口号,默认值为 80?。
5、协议:向目标服务器发送 HTTP 请求时的协议,可以是 http 或者是 https?,默认值为 http?。
6、方法:发送 HTTP 请求的方法,可用方法包括 GET、POST、HEAD、PUT、OPTIONS、TRACE、DELETE 等。
7、Content?encoding?:内容的编码方式,默认值为 iso8859
8、路径:目标 URL 路径(不包括服务器地址和端口)
9、自动重定向:如果选中该选项,当发送 HTTP 请求后得到的响应是 302/301 时,JMeter?自动重定向到新的页面。
10、Use?keep?Alive?:?当该选项被选中时,jmeter?和目标服务器之间使用?Keep-Alive 方式进行 HTTP 通信,默认选中。
11、Use?multipart/from-data?for?HTTP?POST?:当发送 HTTP?POST?请求时,使用 Use?multipart/from-data 方法发送,默认不选中。
12、同请求一起发送参数?:?在请求中发送 URL 参数,对于带参数的 URL?,jmeter 提供了一个简单的对参数化的方法。用户可以将 URL 中所有参数设置在本表中,表中的每一行是一个参数值对(对应 RUL 中的?名称 1=值 1)。
13、同请求一起发送文件:在请求中发送文件,通常,HTTP 文件上传行为可以通过这种方式模拟。/14、从 HTML 文件获取所有有内含的资源:当该选项被选中时,jmeter 在发出 HTTP 请求并获得响应的 HTML 文件内容后,还对该 HTML 进行 Parse?并获取 HTML 中包含的所有资源(图片、flash 等),默认不选中,如果用户只希望获取页面中的特定资源,可以在下方的 Embedded?URLs?must?match?文本框中填入需要下载的特定资源表达式,这样,只有能匹配指定正则表达式的 URL 指向资源会被下载。
15、用作监视器:此取样器被当成监视器,在 Monitor?Results?Listener?中可以直接看到基于该取样器的图形化统计信息。默认为不选中。
16、Save?response?as?MD5?hash:选中该项,在执行时仅记录服务端响应数据的 MD5 值,而不记录完整的响应数据。在需要进行数据量非常大的测试时,建议选中该项以减少取样器记录响应数据的开销。
3、聚合报告简介
我认为聚合报告应该是 JMeter 压力测试软件中最重要的报告。
1. #Samples:样本数,如果你看过上一篇,这个就是前面我们那个公式算出来的结果
(Loop Count(Loop Controler)*Number of Threads*Loop Count(group))
2. Average:平均
《一线大厂 Java 面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义》
【docs.qq.com/doc/DSmxTbFJ1cmN1R2dB】 完整内容开源分享
响应时间。
3. Median:中位数,50%用户响应时间。
4. Line:90%用户响应时间。
5. Min:最小响应时间。
6. Max:最大响应时间。
7. Error%:本次测试中出现错误的请求的数量/请求的总数
8. Throughput:吞吐量,表示每秒完成的请求数。
9. KB/Sec:每秒从服务器端接收到的数据量(只是接收)。
五、JMeter 压力测试时遇到的常见问题
1、Response Times Over Time 中的峰值和聚合报告中的最大值为何不一致?
因为 Response Times Over Time 中的点是一个时间的概念,表示的是一段时间内的请求的平均响应时间,而聚合报告中的最大值表示的是一个请求的最大响应时间,因此 Response Times Over Time 的峰值和聚合报告中的最大值不一致。
2、Response Times Over Time 图中有多少个点,和请求数有什么关系?
Response Times Over Time 中的点是一个时间的概念,在 setting 中可以设置,每隔 500ms 记录一个点,这个点就表示这段时间内的请求的平均响应时间。
3、压测接口时,并发一段时间后,会报 java.net.BindException: Address already in use: connect
Jmeter 里的 http sample 勾选了 keep alive,导致会话一直保持,而 windows 本身的端口有限,导致端口被占用完后,无法分配新的端口,因此会产生 java.net.BindException: Address already in use: connect 报错。
HTTP SAMPLE 不勾选 keep alive
4、internal server error 是什么意思?
internal server error 错误通常发生在用户访问网页的时候发生,该错误的意思是因特网服务错误。能够引起 internal server error 报错的原因有多个,如果你是网站主的话,可以对下列情形进行一一排查。
如果网站文件没有做过修改,最有可能的是同服务器的资源超载:即同一时间内处理器有太多的进程需要处理的时候,会出现 500 错误。借助 SSH,可以在命令行中输入以下命令查看:ps faux ps faux |grep username 如果你查到某个进程消耗过多资源,可以用 kill 命令强制关闭这个进程,只需输入该进程的进程号(Pid):kill -9 pid。
500 错误还有可能是对文件设置了不正确的权限:后台目录和文件的权限默认应该是 755,而图片,文字等 html 文件应该是 644,所以如果在刚刚上传文件后出现 500 错误,应该主要检查文件权限设置。可以使用 FTP 软件选中所有文件,然后批量修改文件权限。
在使用某些 wordpress SEO 插件的时候,插件会改写.htacess 文件,如果语法错误的话就有可能造成 500 错误!
5、Internal server error 500 问题解决思路
500 Internal Server Error
通用错误消息,服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。没有给出具体错误信息。
根据这个描述,基本可以排除客户端以及网络因素,需要重点关注服务端的状态。
我们系统服务端的架构如下图:
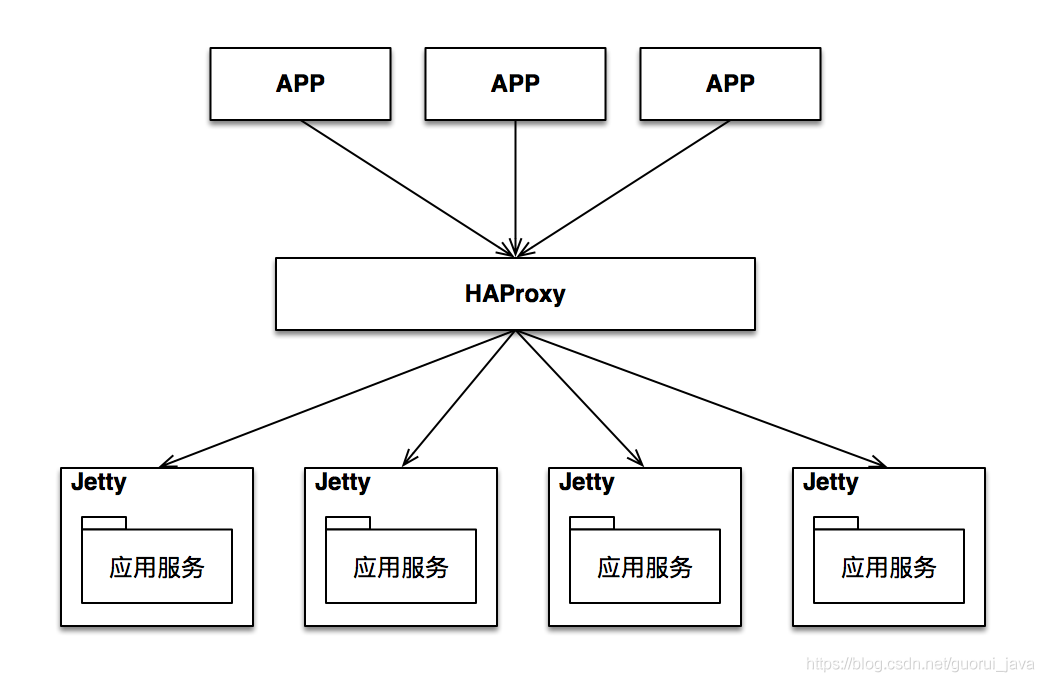
接下来就要根据这个架构由前往后一层一层排查。
重点排查 HAProxy 当前是否可用,负荷是否超标,包括下面的一些指标。
| 排查项 | 结果 |
| --- | --- |
| CPU 是否正常 | 正常 |
| 内存是否正常 | 正常 |
| 线程数是否超过配置上限 | 正常 |
| 连接数是否超过配置上限 |
正常
|
排查之后发现一切正常,与版本更新前的数据作比较,也没有出现大幅度波动。
而在查看请求日志时,发现大量 500 错误信息,说明 HAProxy 出异常的可能性较小,错误更可能来自 HAProxy 之后的环节。
(3)检查 Jetty
重点排查 jetty 的配置信息。
| 排查项 | 结果 |
| --- | --- |
| 配置是否有变动 | 正常 |
| 应用占用的线程数是否超过上限 | 正常 |
| 应用占用的线程数是否超过上限 | 正常 |
虽然 jetty 配置信息检查正常,但是在 access.log 中存在大量 500 错误,定位到这里,有两种可能的原因:
应用代码逻辑问题。部分异常信息没有被拦截住,直接抛给 Jetty,导致 500 错误。
Jetty 逻辑问题。请求没有到达应用,而是由于 Jetty 自身的某些逻辑导致请求被直接返回了。
为了验证是否第一个原因,我们继续走查了应用代码,发现所有的异常都被正确处理了,不存在继续往上抛的情况。另外,也检查了图片保存的代码,确认文件连接都正确释放了。
因此,由于应用逻辑问题导致错误的可能性很小,那么第二个原因的嫌疑最大,就是 Jetty 逻辑问题。
如果直接排查 Jetty 的源码,太费时费力,这个时候最好的办法是实时抓包,看看 Jetty 和应用服务之间到底发生了什么。
(5)使用 tcpdump 抓包
使用 tcpdump 命令抓取从 jetty 到应用服务之间所有的数据包,将结果输出到临时文件中。
tcpdump -i eth0:0 -s0 host 1X.XXX.XXX.XX -w /tmp/out1.cap
使用 wireshark 打开 out1.cap 文件,查找出现 500 错误的数据包,然后很意外的看到了下面的逻辑。

通过这段代码我们发现,jetty 对于请求数据的大小做了限制,超过 200000 byte 的时候就会报错,返回错误码 500。
App 这次更新后,上传了很多大于 200000 byte 的图片,于是便出现了大量的 500 错误。
找到问题根源,修正起来就很简单了,在 WEB-INF 目录下添加 jetty-web.xml 文件解决,文件内容如下:
<?xml version="1.0"?>
<!DOCTYPE Configure PUBLIC "-//MortBay Consulting//DTD Configure//EN"
"http://jetty.mortbay.org/configure.dtd">
<Configure id="WebAppContext"class="org.eclipse.jetty.webapp.WebAppContext">
<Set name="maxFormContentSize"type="int"> 0 </Set>
</Configure>
6、JMeter 问题总结
出现 Internal server error 500 错误,往往意味着服务端出现一些未知异常,但是在排查的时候我们不能仅仅只是关注应用服务,而是要关注从服务端接收请求开始,一直到应用服务的整条链路。
以本文中的情景为例,就是从 HAProxy 到 Jetty 再到 应用服务,中间的任何一个环节都有可能导致 500 错误。
另外,其实在一开始我们就可以采用抓包的方式去排查,因为在包数据中包含了完整请求/响应消息,比查看 CPU、线程、配置信息要更加快捷,直接。
六、Linux 查看程序运行情况
1、Top
top 命令是 Linux 下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于 Windows 的任务管理器。
top 显示系统当前的进程和其他状况,是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户 终止该程序为止. 比较准确的说,top 命令提供了实时的对系统处理器的状态监视.它将显示系统中 CPU 最“敏感”的任务列表.该命令可以按 CPU 使用.内存使用和执行时间 对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定。
在 linux 系统中,top 命令可谓是分析系统性能最方便的工具,而且 top 还是个交互式工具;通过 top 命令可以清楚地了解到正在执行的进程信息包括进程 ID,内存占用率,CPU 占用率等。其实就跟 window 的任务管理器类似。
2、查看 CPU 使用率
sar -u 1 5
表示每 1 秒采集一次,共采集 5 次。
这个命令可根据实际线程组中的设置,进行 CPU 使用率方面的查看。
[root@sss ~]# sar -u 1 5
Linux 3.10.0-957.10.1.el7.x86_64 (izuf633l0ge76tv5mzalpmz) 04/16/2019 x86_64 (1 CPU)
04:56:03 PM CPU %user %nice %system %iowait %steal %idle
04:56:04 PM all 0.00 0.00 0.00 0.00 0.00 100.00
04:56:05 PM all 0.00 0.00 0.00 0.00 0.00 100.00
04:56:06 PM all 0.99 0.00 0.99 0.00 0.00 98.02
04:56:07 PM all 0.00 0.00 0.00 0.00 0.00 100.00
04:56:08 PM all 0.00 0.00 0.00 0.00 0.00 100.00
Average: all 0.20 0.00 0.20 0.00 0.00 99.60
3、查看内存占用情况
free -m

1352/1838 即为内存占用。
4、Linux 如何统计进程的 CPU 利用率
Linux 的/proc 文件系统,可以看到自启动时候开始,所有 CPU 消耗的时间片;对于个进程,也可以看到进程消耗的时间片。这是一个累计值,可以"非阻塞"的输出。获得一定时间间隔的两次统计就可以计算出这段时间内的进程 CPU 利用率。
所以,是否存在一种简单的,非阻塞的方式获得进程的 CPU 利用率? 答案是:“没有”。这里给出一个很恰当的比喻:"这就像有人给你一张照片,要你回答照片中车子的速度一样"。
1、/proc/stat 统计总 CPU 消耗
计算 CPU 总消耗可以使用如下 shell 命令:
cat /proc/stat|grep "cpu "|awk '{for(i=2;i<=NF;i++)j+=$i;print "cpu_total_slice " j;}'
cpu_total_slice 19208187744
2、进程消耗的 CPU 时间片
在 proc 文件系统中,可以通过/proc/[pid]/stat 获得进程消耗的时间片,输出的第 14、15、16、17 列分别对应进程用户态 CPU 消耗、内核态的消耗、用户态等待子进程的消耗、内核态等待子进程的消耗(man proc)。所以进程的 CPU 消耗可以使用如下命令:
cat /proc/9583/stat|awk '{print "cpu_process_total_slice " 15+17}'
cpu_process_total_slice 1068099
3、"非阻塞"的计算进程 CPU 利用率
从这里也看到,是没有某个时刻 CPU 利用率的说法的,也就没法获得某个时刻的 CPU 利用率。这就像物理中的"速度"的概念,没有某一时刻速度的概念,速度一定是一个时间段之内的。那么要"非阻塞"计算某个进程 CPU 利用率,则需要取两次事件间隔进行计算,这两次事件间隔的操作可以是非阻塞的。计算办法如下:
时刻 A,计算操作系统总 CPU 时间片消耗 total_cpu_slice_A;计算进程总 CPU 时间片消耗;total_process_slice_A ;
时刻 B,计算操作系统总 CPU 时间片消耗 total_cpu_slice_B;计算进程总 CPU 时间片消耗;total_process_slice_B。
B 时刻就可以"非阻塞"的计算这段时间进程的 CPU 利用率了:
100%*(total_process_slice_B-total_process_slice_A)/(total_cpu_slice_B-total_cpu_slice_A)
5、CPU 使用率与 CPU 空闲时间的关系?
写在最后
学习技术是一条慢长而艰苦的道路,不能靠一时激情,也不是熬几天几夜就能学好的,必须养成平时努力学习的习惯。所以:贵在坚持!
最后再分享的一些 BATJ 等大厂 20、21 年的面试题,把这些技术点整理成了视频和 PDF(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节,由于篇幅有限,上面只是以图片的形式给大家展示一部分。

Mybatis 面试专题

MySQL 面试专题

并发编程面试专题

还未添加个人签名 2021.11.12 加入
还未添加个人简介









评论