本参考文档使用4节点机器集群进行部署,操作用户为root·部署Hadoop环境
一、机器初始化
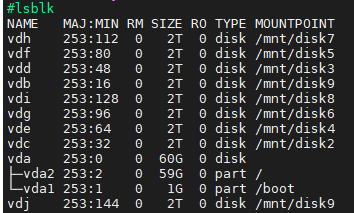
1,绑定机器的网卡和硬盘
进行初始化及挂载操作:
#初始化mkfs -t ext4 /dev/vdbmkfs.ext4 /dev/vdcmkfs.ext4 /dev/vddmkfs.ext4 /dev/vdemkfs.ext4 /dev/vdfmkfs.ext4 /dev/vdgmkfs.ext4 /dev/vdhmkfs.ext4 /dev/vdimkfs.ext4 /dev/vdjmkfs.ext4 /dev/vdk
#挂载mount /dev/vdb /mnt/disk1mount /dev/vdc /mnt/disk2mount /dev/vdd /mnt/disk3mount /dev/vde /mnt/disk4mount /dev/vdf /mnt/disk5mount /dev/vdg /mnt/disk6mount /dev/vdh /mnt/disk7mount /dev/vdi /mnt/disk8mount /dev/vdj /mnt/disk9mount /dev/vdj /mnt/disk10
复制代码
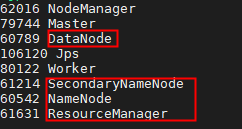
查看如图即为绑定成功。
2,配置集群间互信
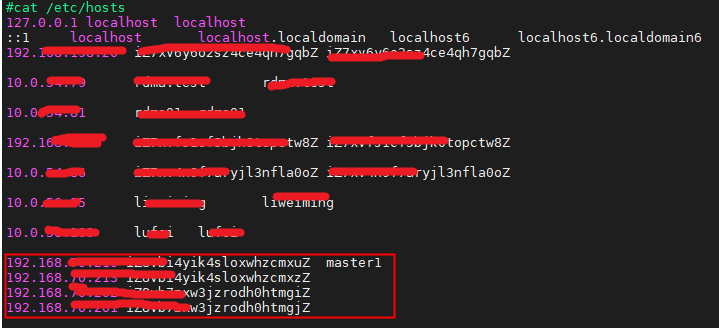
①每台节点配置/etc/hosts 文件
②各节点 ssh-keygen 生成 RSA 密钥和公钥
ssh-keygen -q -t rsa -N "" -f ~/.ssh/id_rsa
③ 将所有的公钥文件汇总到一个总的授权 key 文件中
ssh 192.168.70.210 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysssh 192.168.70.213 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysssh 192.168.70.202 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysssh 192.168.70.201 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
复制代码
④ 将该总授权 key 文件分发至其他各个机器中
scp ~/.ssh/authorized_keys 192.168.70.213:~/.ssh/scp ~/.ssh/authorized_keys 192.168.70.202:~/.ssh/scp ~/.ssh/authorized_keys 192.168.70.201:~/.ssh/
复制代码
3,下载相关资源包
下载 hadoop,jdk,spark 安装包到/opt 路径下,本文以 hadoop-2.7.7、spark-2.4.4 及 jdk1.8.0_291 为例
下载Hadoop: wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz下载spark : wget https://archive.apache.org/dist/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz下载jdk : wget https://download.oracle.com/otn/java/jdk/8u301-b09/d3c52aa6bfa54d3ca74e617f18309292/jdk-8u301-linux-x64.tar.gz下载hive : wget https://archive.apache.org/dist/hive/hive-2.3.7/apache-hive-2.3.7-bin.tar.gz
复制代码
(由于 jdk 版本众多,此下载链接仅作参考,实际可根据需求自行在官网下载 jdk 版本。配置 jdk 也需按照实际下载版本进行配置)
将 3 个压缩包分发至其余 3 个节点并解压
scp -r hadoop-2.7.7.tar.gz jdk-8u291-linux-x64.tar.gz spark-2.4.4-bin-hadoop2.7 iZ8vbi4yik4sloxwhzcmxzZ:/optscp -r hadoop-2.7.7.tar.gz jdk-8u291-linux-x64.tar.gz spark-2.4.4-bin-hadoop2.7 iZ8vb7zxw3jzrodh0htmgiZ:/optscp -r hadoop-2.7.7.tar.gz jdk-8u291-linux-x64.tar.gz spark-2.4.4-bin-hadoop2.7 iZ8vb7zxw3jzrodh0htmgjZ:/opt
复制代码
二、配置 JDK
1,解压 jdk 压缩包
在/opt 路径下解压 jdk 包。
2,配置环境变量
在/etc/profile 中增加:
export JAVA_HOME=/opt/jdk1.8.0_291/ export JRE_HOME=/opt/jdk1.8.0_291/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$SPARK_HOME/bin:$HIVE_HOME/bin
复制代码
执行 source /etc/profile 使环境变量生效
三、安装 Hadoop
1.配置 core-site.xml 文件
·需在各节点中创建此路径
2.配置 hadoop-env.sh 文件
export JAVA_HOME 环境变量
3.配置 yarn-env.sh
修改 JAVA_HOME 为本机 JAVA_HOME 路径
4.配置 hdfs-site.xml
5.配置 mapred-site.xml
配置 yarn 管理
6.配置 yarn-site.xml
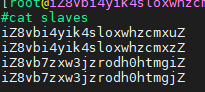
7.配置 slaves 文件
将主机名添加进 slaves 文件
hadoop3.0 之后 slaves 文件改名为 workers
8.配置 hadoop 的环境变量
在/etc/profile 中增加:
export HADOOP_HOME=/opt/hadoop-2.7.7/export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
复制代码
9.分发至各节点
将/opt/hadoop-2.7.7 分发至其余各节点
10.格式化 hdfs
主节点执行
11.开启 hadoop
在 master 节点/opt/hadoop-2.7.7/路径下执行:
sbin/start-dfs.sh
sbin/start-yarn.sh
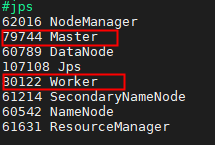
完成 后执行 jps 查询,master 如下图所示,则配置成功。
四、安装 Spark
1.配置环境变量
vi /etc/profile 中加入
export SPARK_HOME=/opt/spark-2.4.4-bin-hadoop2.7
复制代码
分发/etc/profile 文件至其余节点
2.配置 slaves 文件
将主机名添加进 slaves
vi /opt/spark-2.4.4-bin-hadoop2.7/conf/slaves
3.配置 spark-env.sh
在/opt/spark-2.4.4-bin-hadoop2.7/conf 路径下执行
cp spark-env.sh.template spark-env.sh
复制代码
在 spark-env.sh 中增加:
export SPARK_MASTER_HOST=iZ8vbi4yik4sloxwhzcmxuZexport SPARK_LOCAL_IP=`/sbin/ip addr show eth0 | grep "inet\b" | awk '{print $2}' | cut -d/ -f1`export SPARK_LOCAL_DIRS=/mnt/data/spark_tmpexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/export SPARK_DAEMON_MEMORY=10g
复制代码
4.配置 spark-defaults.conf
## Licensed to the Apache Software Foundation (ASF) under one or more# contributor license agreements. See the NOTICE file distributed with# this work for additional information regarding copyright ownership.# The ASF licenses this file to You under the Apache License, Version 2.0# (the "License"); you may not use this file except in compliance with# the License. You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.#
# Default system properties included when running spark-submit.# This is useful for setting default environmental settings.
# Example:# spark.master spark://master1:7077# spark.eventLog.enabled true# spark.eventLog.dir hdfs://namenode:8021/directory# spark.serializer org.apache.spark.serializer.KryoSerializer# spark.driver.memory 5g# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"spark.master yarnspark.deploy-mode client#driverspark.driver.cores 4spark.driver.memory 10gspark.driver.maxResultSize 10g##executorspark.executor.instances 45spark.executor.memory 13gspark.executor.cores 4#shufflespark.task.maxFailures 4spark.default.parallelism 180spark.sql.shuffle.partitions 180spark.shuffle.compress truespark.shuffle.spill.compress true#otherspark.task.maxFailures 4spark.kryoserializer.buffer 640kspark.memory.storageFraction 0.5spark.shuffle.file.buffer 32kspark.kryoserializer.buffer.max 2000mspark.serializer org.apache.spark.serializer.KryoSerializerspark.memory.fraction 0.6spark.network.timeout 3600spark.sql.broadcastTimeout 3600spark.locality.wait=0s
#speculation#spark.speculation=true#spark.speculation.interval=300s#spark.speculation.quantile=0.9#spark.speculation.multiplier=1.5
#aqespark.sql.adaptive.enabled truespark.sql.autoBroadcastJoinThreshold 128mspark.sql.adaptive.advisoryPartitionSizeInBytes 128MBspark.sql.adaptive.coalescePartitions.minPartitionNum 1spark.sql.adaptive.coalescePartitions.initialPartitionNum 180spark.sql.adaptive.forceApply truespark.sql.adaptive.coalescePartitions.enabled truespark.sql.adaptive.localShuffleReader.enabled truespark.sql.adaptive.skewJoin.enabled truespark.sql.adaptive.skewJoin.skewedPartitionFactor 5spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 256m
#DF#spark.sql.optimizer.dynamicPartitionPruning.enabled false#spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly truespark.sql.optimizer.dynamicDataPruning.pruningSideThreshold 10GB#spark.sql.optimizer.dynamicDataPruning.enabled false
#cbo#spark.sql.statistics.histogram.enabled true#spark.sql.statistics.histogram.numBins 32spark.sql.cbo.enabled truespark.sql.cbo.joinReorder.enabled truespark.sql.cbo.planStats.enabled truespark.sql.cbo.starSchemaDetection truespark.sql.cbo.joinReorder.card.weight 0.6spark.sql.cbo.joinReorder.ga.enabled truespark.sql.autoBroadcastJoinRowThreshold 500000
#logspark.eventLog.enabled truespark.eventLog.dir hdfs://master1:9000/sparklogsspark.eventLog.compress truelog4j.logger.org.apache.storage.ShuffleBlockFetcherIterator TRACE
复制代码
在 hdfs 中创建/sparklogs 目录
hadoop fs -mkdir /sparklogs
复制代码
分发/opt/spark-2.4.4-bin-hadoop2.7 至其余节点
5.启动 spark
在/opt/spark-2.4.4-bin-hadoop2.7 路径下执行:
sbin/start-all.sh
jps 执行如下图,则启动成功。
五、安装 Mysql
1,下载安装包(以 8.0.21 版本为例)
#下载wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysql-8.0.21-linux-glibc2.12-x86_64.tar.xz#解压tar -xf mysql-8.0.21-linux-glibc2.12-x86_64.tar.xz
复制代码
2,设置 mysql 目录
#将解压的文件移动到/usr/local下,并重命名为mysql mv mysql-8.0.21-linux-glibc2.12-x86_64 /usr/local/mysql
复制代码
3.创建 data 文件夹,并授权
cd /usr/local/mysql/# 创建文件夹mkdir data# 给文件夹授权chown -R root:root /usr/local/mysqlchmod -R 755 /usr/local/mysql
复制代码
4,初始化数据库
/usr/local/mysql/bin/mysqld --initialize --user=root --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
复制代码
5.配置 my.cnf
cd /usr/local/mysql/support-files/touch my-default.cnfchmod 777 my-default.cnfcp /usr/local/mysql/support-files/my-default.cnf /etc/my.cnfvi /etc/my.cnf#my.cnf中添加:---------------------------------------------------------------------------------------------------------------------------------------------# Remove leading # and set to the amount of RAM for the most important data# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.# innodb_buffer_pool_size = 128M
# Remove leading # to turn on a very important data integrity option: logging# changes to the binary log between backups.# log_bin
# These are commonly set, remove the # and set as required.[mysqld]basedir = /usr/local/mysqldatadir = /usr/local/mysql/datasocket = /tmp/mysql.sock#socket =/var/lib/mysql/mysql.socketlog-error = /usr/local/mysql/data/error.logpid-file = /usr/local/mysql/data/mysql.piduser = roottmpdir = /tmpport = 3306#skip-grant-tables#lower_case_table_names = 1# server_id = .....# socket = .....#lower_case_table_names = 1max_allowed_packet=32Mdefault-authentication-plugin = mysql_native_password#lower_case_file_system = on#lower_case_table_names = 1log_bin_trust_function_creators = ON# Remove leading # to set options mainly useful for reporting servers.# The server defaults are faster for transactions and fast SELECTs.# Adjust sizes as needed, experiment to find the optimal values.# join_buffer_size = 128M# sort_buffer_size = 2M# read_rnd_buffer_size = 2M
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
复制代码
6.设置开机自启
cd /usr/local/mysql/support-filescp mysql.server /etc/init.d/mysqlchmod +x /etc/init.d/mysql
复制代码
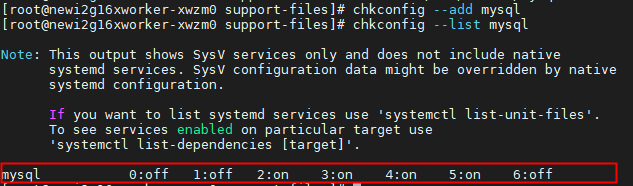
7. 注册服务并检测
#注册chkconfig --add mysql#检测chkconfig --list mysql
###UBUNTUecho 'deb http://archive.ubuntu.com/ubuntu/ trusty main universe restricted multiverse' >>/etc/apt/sources.listsudo apt-get updatesudo apt-get install sysv-rc-confsysv-rc-conf --list
复制代码
8. 配置/etc/ld.so.conf
vim /etc/ld.so.conf# 添加如下内容:/usr/local/mysql/lib
复制代码
9. 配置环境变量
vim /etc/profile# 添加如下内容:# MYSQL ENVIRONMENTexport PATH=$PATH:/usr/local/mysql/bin:/usr/local/mysql/lib
source /etc/profile
复制代码
10.启动 mysql
11.登录 mysql
使用临时密码登录,修改 root 用户密码,设置 root 远程登录
#报错:Your password does not satisfy the current policy requirements#可设置弱口令(mysql8.0)set global validate_password.policy=0;set global validate_password.length=1;之后再修改密码
复制代码
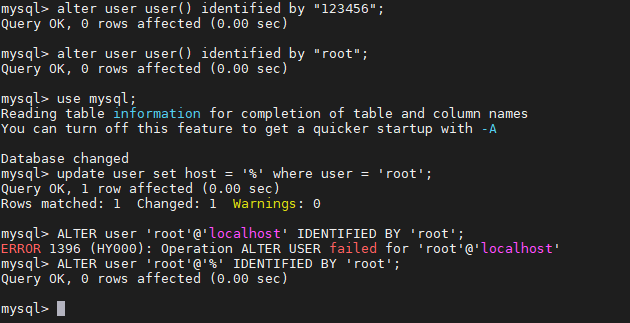
mysql> alter user user() identified by "123456";Query OK, 0 rows affected (0.01 sec)
mysql> ALTER user 'root'@'localhost' IDENTIFIED BY '123456';Query OK, 0 rows affected (0.00 sec)
mysql> use mysql;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -A
Database changedmysql> update user set host = '%' where user = 'root';Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0
mysql> FLUSH PRIVILEGES;Query OK, 0 rows affected (0.00 sec)
用户授权grant all privileges on *.* to 'hive'@'%';
复制代码
六、安装 Hive
以 hive-2.3.7 为例
1.将压缩包解压至/opt 下
2. 配置环境变量
vim /etc/profile
#hiveexport HIVE_HOME=/opt/apache-hive-2.3.7-bin
复制代码
3. 配置 hive-site.xml
vim /opt/apache-hive-2.3.7-bin/conf/hive-site.xml
4.拷贝 mysql 的驱动程序
#下载mysql-connector-java-8.0.21.ziphttps://dev.mysql.com/downloads/file/?id=496589
复制代码
将下载的 mysql-connector-java-8.0.21.zip 解压后拷贝至/opt/apache-hive-2.3.7-bin/lib 下
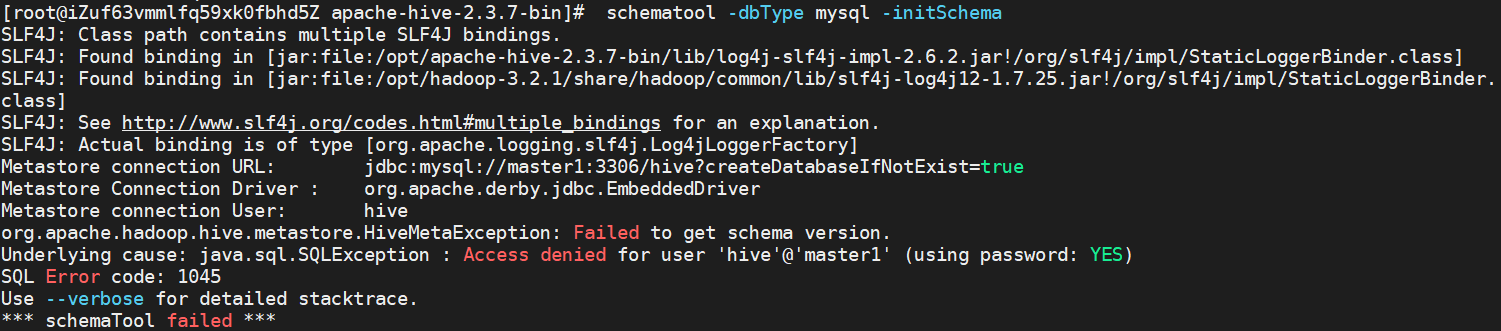
5.hive 初始化
执行
schematool -dbType mysql -initSchema
复制代码
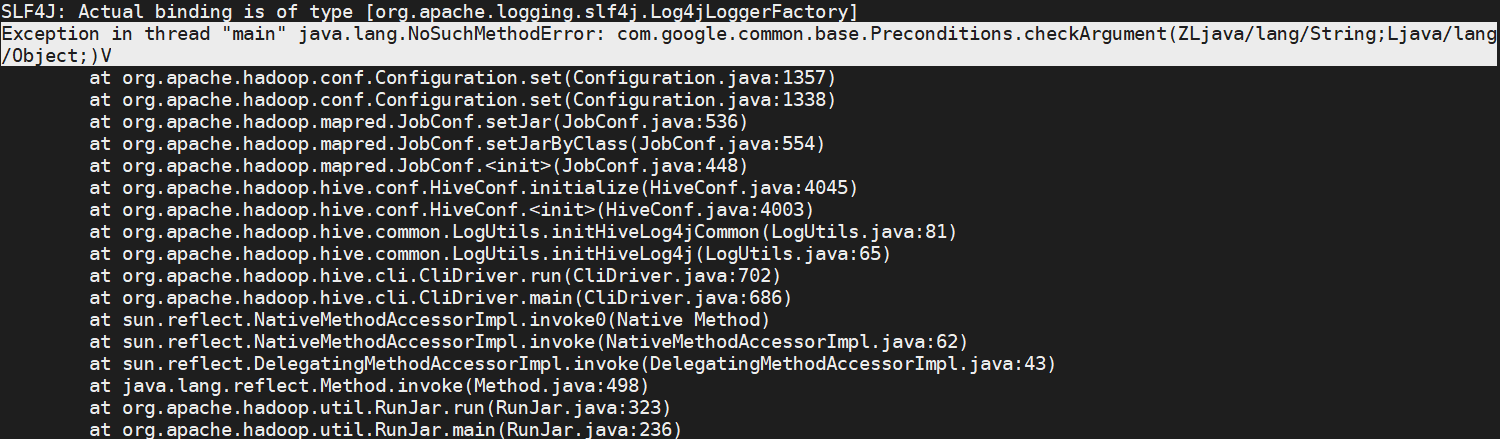
[报错]
[解决]
一,java.lang.NoSuchMethodError
原因:1.系统找不到相关 jar 包
2.同一类型的 jar 包有不同版本存在,系统无法决定使用哪一个
二,com.google.common.base.Preconditions.checkArgument
根据百度可知,该类来自于 guava.jar
三,查看该 jar 包在 hadoop 和 hive 中的版本信息
hadoop-3.2.1(路径:/opt/hadoop-3.2.1/share/hadoop/common/lib)中该 jar 包为 guava-27.0-jre.jar
hive-2.3.6(路径:hive/lib)中该 jar 包为 guava-14.0.1.jar
四,解决方案
删除 hive 中低版本的 guava-14.0.1.jar 包,将 hadoop 中的 guava-27.0-jre.jar 复制到 hive 的 lib 目录下即可
[报错]
[解决]
修改 hive-site.xml 配置
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
6.在 mysql 增加 hive 用户
mysql> create user 'hive'@'localhost' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> grant all privileges on *.* to 'hive'@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> create user 'hive'@'%' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> grant all privileges on *.* to 'hive'@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
7.启动 hive
执行 hive ,启动成功


























评论