强!上线 3 天获 10w 浏览量,京东 T8 纯手码 Redis 缓存手册,我粉了
Hello,今天给各位童鞋们分享 Redis 缓存,赶紧拿出小本子记下来吧!

简介
什么是 Redis?
Redis 是一种存储系统,像 MongoDB 一样,都是键值对存储,也就是 key-value 结构。也就是说,Redis 其实是一种数据库,它可以跨平台使用,本系列整合 SpringBoot+Redis。
Redis 本身是由 C 语言编写,是符合 ANSI C 标准的开源系统。Redis 是 Remote Dictionary Server 的缩写,现在常用于分布式数据库以及高可用缓存系统。实际上,学会 Redis 整合了 SpringBoot 后,再整合 SpringCloud 就是水到渠成了。
为什么要用 Redis?
有朋友可能要问,既然 Redis 和 MongoDB 这么像,那我用后者不就行么,干嘛学前者?实际上 MongoDB 和 Redis 是有很大区别的,他们只是在存储方式上有相似点。下面列出二者的不同之处:
数据存储位置
MongoDB 存储的数据存放在磁盘,少部分数据存放在内存中。为啥数据库数据还要存放在内存呢?是因为数据库的缓存系统会判断热点数据,频繁存取的数据要放在内存达到高效处理。
Redis 的数据全部存放在内存,并定期写入磁盘,也因此造就了 Redis 的高性能。当内存不够用,Redis 会利用 LRU(Least Recently Used)算法取代数据,没错,就是操作系统西面置换算法。
数据存储方式
MongoDB 利用了 mmap 函数,将文件数据映射的内存进行增删查改,修改完之后操作系统会将内存数据 flush 到磁盘。问题是二者并非一个事务,因此两个事务间宕机的话,数据自然丢失。
Redis 有两种存储模式,RDB 与 AOF 模式,这个我们后面会说到。
数据处理速度
MongoDB 比 Redis 慢,这也是 Redis 属于内存存储系统的最大优势。当然,我们暂时不考虑内存不够用的情况。
除此之外,目前分布式是大厂主流技术栈,Redis 是大厂会采用的分布式缓存方式。并且在应对高并发的场景上,比如阿里双十一,腾讯游戏新皮肤的出场或者过年红包等,利用 Redis 和消息队列是主流的方法。
入门是什么程度?精通是什么程度?
入门就是对 Redis 完全不了解,但是你要有基础的知识,比如基础的数据结构,基础的类型,基础的内存知识,基础的分布式知识,
基础的 Java/Spring 知识和 linux 的基本操作。这个大可放心,我水平也一般般,所以我说的基础一定是基础。
精通并不是说最后能自己写一个 Redis,或者说自己能成为 Redis 的稳定开发维护者,我自己也做不到,所以这里的精通是能够了解 Redis 的各种机制、算法,了解 Redis 提供的常用方法,了解 Redis 使用场景,自己能排坑,并且能够自己整合 SpringBoot 框架。实际上,这个整合 SpringBoot 框架最简单,官网写的很详细。最好能在 Redis 基础上进行二次开发,实际上理解了原理,会写 C 语言,二次开发还是不难的。
既然是系列文章,我就不能全写在一篇里,内容太多对于我的排版和学习者的体验也不好,所以我会尽量把每一篇文章压缩在一个可以接受的长度范围,当然,我尽量在每一篇文章都给出系列所有文章的链接,供大家,也供我日后方便查阅。如果文章能帮到你,希望给个赞鼓励下,虽然不是靠这个生存,但是得到认可还是很高兴的。
缓存以及使用场景
什么是缓存?
缓存实际上就是某个程序利用内存来优化频繁读取的数据的一种方式。缓存就是内存的一部分。之前我们写到,数据库操作往往是存储在磁盘中的,但是磁盘的 IO 又慢的不得了,怎么办?程序猿们想了一种方法,就是利用好内存。不是磁盘 IO 慢么,那就利用内存好了,内存 IO 很快的,但是东西太多,放不进内存怎么办?那就把常用的数据放在内存吧。
现在是 2021 年,熟悉 NBA 的朋友都知道,今年威少的数据又爆炸,所以球迷可能会时常看威少的数据,加上威少的粉丝也不少,可能就存在高并发的问题。但是每次从磁盘拿数据也太慢了,那就把单独把威少的数据放在内存中,别人的数据继续躺在磁盘里,这样大大加快了系统响应的速度,这就是缓存。
但是,NBA 可不止有一个球星,库里,詹姆斯,约基奇等都是很出色的球员,拥有球迷的数量不比威少少,那就把他们的数据都放在缓存中吧,这样就快了。但是我们发现,NBA 球星太多了,内存放不下,怎么办?这就引出了我们的常见的缓存淘汰算法,对操作系统有了解的朋友可能知道,什么 LRU,LFU,FIFO,FILO 等等,我把这个放在后面的 Redis 算法机制里说。
本地缓存与分布式缓存
先看看例子,还是 NBA 球员,现在我的内存太小了啊,每个计算机只能存放一名 NBA 球员的数据,但是我现在有 3 名球员数据需要存放在计算机里面怎么办?
本地缓存
本地缓存就是将数据存放在本地内存中,由于不需要通过网络连接到其他主机,自然速度也最快,当然缺点也是有的。比如 Mybatis 一二级缓存,Caffeine,Guava 都是本地缓存的典型范例。回到之前的例子,3 名球员放在 3 台不同的主机,如果用本地缓存的架构就是这样的:
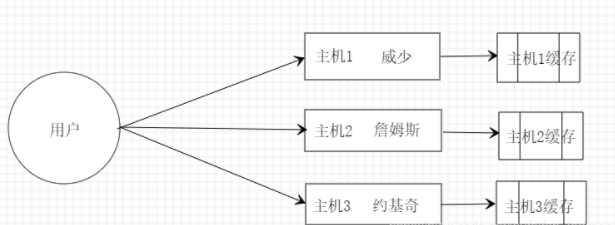
优点:
速度快,不用经过网络传输
缺点:
每台主机可用缓存容量有限
多节点无法共享数据
分布式缓存
分布式缓存就是利用网络,将缓存放在某一台主机上,这样缓存的容量限制就是缓存机的内存大小,其 IO 瓶颈就是网速。Redis 就是典型的分布式缓存,当然,我们也可以让 Redis 变成彻头彻尾的本地缓存,不经网络调用即可。
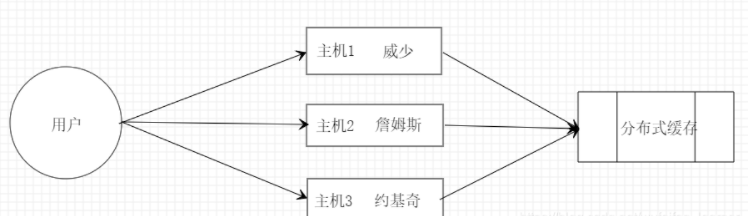
当然,上图并不准确,既然缓存的分布式了,当然不能只部署在一台缓存机上,往往都是集群的方式部署缓存机的。
热点 Key 问题
什么是热点 key 呢?很简单,我们看到微博时常会宕机,除了用户量大,信息量多以外,往往是某个明星又宣布“我们有个孩子”这类的事情,无数用户访问该资源,该资源对应的 key 就被称为热点 key,突然间的高并发,使得某一个热点被高频访问,从而导致服务器缓存资源耗竭,怎么处理?
解决方法有很多,但是咱们今天说到缓存问题了,就只说缓存解决方案。拿明星有了孩子举例子,从原因分析到解决方案,其实原因有了,解决方案就是信手拈来的事情了。
原因分析:某明星 A 与某明星 B 有了孩子,A 和 B 在分布式缓存服务器上,但是当这种爆炸性新闻发生的时候,大量用户访问分布式缓存服务器,即使缓存资源没有耗尽,网络 IO 也无法承载。由于我们的假设是 key 在一台机器,那么暂时不考虑拆分 key 的情况,就是缓存暂时能顶得住,但是网络 IO 崩了,分布式缓存服务器承受不了那么大的数据量,怎么办?
解决方法:既然解决不了网络的问题,那就不解决了,干脆不用,毕竟扩大网络带宽这种外行都懂的方法入不了咱们的法眼。怎么不用?那就是本地缓存+分布式缓存。网络受不了,就把高频资源放在本地服务器上,外界访问相关资源,直接从本地服务器取,和分布式缓存服务器无关。只有当新来的高频资源访问,且老高频资源热度下去时,取代即可。
好啦,今天的文章就到这里,希望能帮助到屏幕前迷茫的你们

还未添加个人签名 2021.04.28 加入
分享、普及java相关知识









评论