
深入解析分布式文件系统的一致性的实现
本文作者为中国移动云能力中心大数据团队软件开发工程师冯永设,文章从分布式系统 CAP 理论出发,详细介绍了分布式一致性共识系统的功能架构、选举机制,以及三种可以实现一致性的数据复制机制,供大家参考。
背景
随着摩尔定律遇到瓶颈,越来越多的系统要依靠分布式集群架构来实现海量数据和计算能力的扩展,因此分布式系统相关的技术越来越重要。分布式系统是由一个硬件或者软件分布在不同的网络计算机上,彼此之间通过消息传递进行通信和协调的系统,在分布式领域中 CAP 理论是基本起点,其三个基本需求如下:
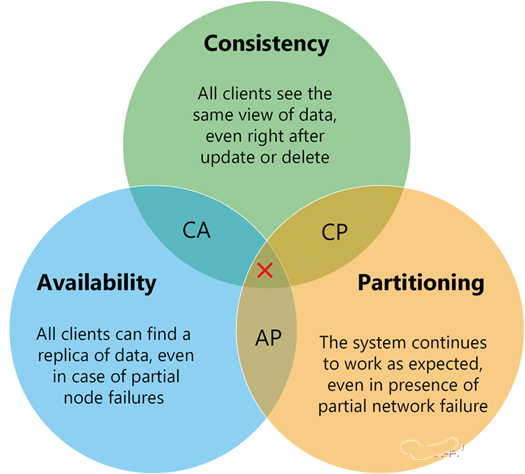
•Consistency(一致性),所有节点在同一时间的数据完全一致,这个一致性是指强一致性,后面在介绍一致性概念的时候会详述•Availability(可用性),要求系统内的节点在接收到读写请求后都能正确处理并返回结果•Partition Tolerance(分区容错性),在分布式系统中节点都是不可靠的,当某些节点出现故障(网络或者节点本身的故障)时,仍然能够对外提供满足一致性和可用性的服务
对于分布式系统而言无法同时满足这三个特性,分区容错性(P)是一个基本要求,在分布式环境中网络波动、丢包或者硬件故障是必须会发生的,因此要确保节点故障时另一些节点(网络分区形成多个独立集群)仍然可以提供服务。在保证分区容错性的基础上,根据不同的使用场景在一致性(C)和可用性(A)两者之间进行取舍。
对于分布式数据库或者文件系统,在发生极端情况下要优先保证数据的一致性,任何时刻对系统的访问需求都能得到一致的数据结果,同时系统对网络异常具有容错性,在这种情况下系统会丢弃部分请求,为了补偿这种机制通常可以通过客户端重试机制来请求的最终被处理。
在一些场景下需要优先保证系统的可用性,例如分布式文章推荐系统中并不需要保证每个节点的数据一致,某些节点返回旧数据也不会有很大的影响,但是不可用降低用户体验,这就需要降低数据的一致性需求。
当选择 CP 时,满足一致性而牺牲可用性意味着在网络异常出现多个节点孤岛时为了保证各个节点的数据一致性会停止服务,反之选择 AP 即满足可用性牺牲一致性时网络时系统仍可工作,但会出现各节点数据不一致的情况。
在分布式系统中不管选择 AP 还是选择 CP,最终都要实现一致性,区别仅在于一致性的时效性要求不同,在 CP 中要所有节点中的状态完全一致才对外提供服务,而 AP 以保证可用性为前提,不同节点之间数据在规定的时间内达到一致性即可。在分布式存储系统中数据以多副本的存在,当某个进程更新当前副本的数据,如果没有其他客户端更新这个副本的数据,系统最终一定能够保证后续进程能够读到客户端写进的最新值。但是这个操作存在时间不一致性的窗口,在最终一致性的要求下这个窗口主要受通信延迟、系统负载和副本个数的影响。
分布式系统需要所有节点对外提供的状态是一致的,即集群中所有服务节点中的数据完全相同,并且能够使分布式系统在约定协议的保障下,给定一系列的操作后对外呈现的状态仍然是一致的,这就是分布式系统的一致性。
这个约定协议即共识,描述了在分布式系统中多个节点之间,彼此对某个状态达成一致性结果的过程。要保障系统满足不同程度的一致性,核心过程往往需要通过共识算法来达成。共识算法解决的是对某个请求(提案),多个节点达成一致意见的过程。提案的含义在分布式系统中十分广泛,如多个事件发生的顺序、更改某个键对应的值、选主请求等等。一致性描述的是分布式系统的结果状态,而共识则是一种手段,达到某种共识并不意味着保证一致性。
业界中有很多的共识算法,大部分的分布式系统基本上都会基于标准的共识算法自定义分布式系统框架,例如 TiDB、Etcd、Kudu 等实现 Raft 协议;Zookeeper 自定义 ZAB 协议;Spanner,Chubby 及 OceanBase 实现 Paxos 算法等。开源社区也有很多通用的一致性共识基础库,例如 Apache Ratis、Ali X-Paxos 及 openGauss DCF 等,对于分布式一致性共识系统的功能架构可以抽象:算法模块、日志存储模块、网络通信模块及服务层等几个模块,作用如下所示:
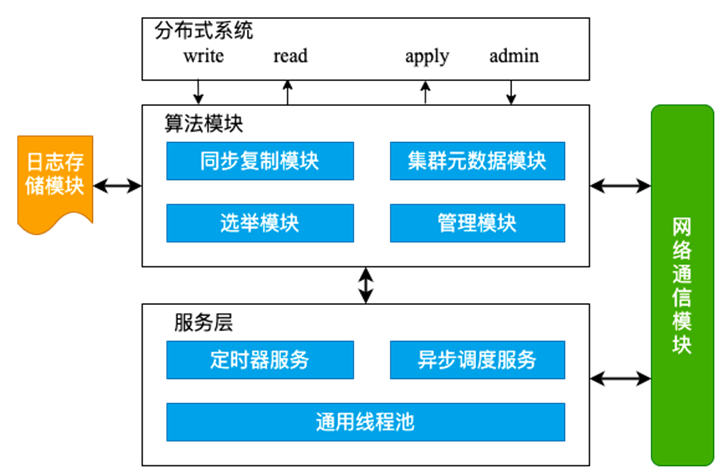
•算法模块
分布式系统运行的核心机制,分为选举模块、同步复制、集群元数据及集群关系管理模块,具体作用下文会重点介绍下选举及同步复制两个模块。
•日志存储模块
在分布式系统中不管是选举还是请求,都要经过共识协议达到一致,这些请求都要先存储到操作日志中,由于操作日志是通用的功能,因此通常将其抽象成独立的日志模块,也可以结合已有的日志系统(BookKeepr、WAL 等)来获取更高的性能和更低的成本。
•网络通信模块
实现分布式各节点之间的消息交互,目前常用的通信模块基于 Java NIO、Netty 等常用网络方案。
•服务层
驱动整个分布式一致性系统的运行,提供各种程序运行所需要的各种基础服务,包括分布式异步调度、线程池、定时任务管理等,服务层对集群运行的性能和稳定性密切相关。
选举机制
该模块是基于共识协议来实现,可以根据不同的业务场景、性能及生态的需求,选择合适的协议,目前大部分都采用成熟的 Paxos、Raft 等算法。这些算法大多数是基于“过半数学”原理,在这个原理中过半的节点集合组成法定集合,由于网络问题导致集群“分裂”成两个法定集合则必须存在非空交集(至少有一个公共进程),肯定可以对某个值达成一致,使用”过半”的概念可以解决 2PC/3PC 协议的效率低及阻塞等问题,并且具有很好的容错性。
在 P2P 去中心化的集群架构中基本上采用 Gossip 协议(或者变体),该协议中使用的共识算法采用的理论是“六度分隔理论”,即任何人通过 6 个中间人就可以认为世界上的任何人,在每个节点上中维护集群中其他节点的信息列表,在需要发送消息时通常以随机的形式选择要发送的节点。Cassandra、Redis、Consul 及比特网络等分布式系统使用这种协议进行集群管理,其缺点也比较明显,发送的消息往往要经过多轮的传播从能达到全网,不适应于消息延迟要求高的场景,而且同步的过程中消息冗余。
目前开源的大部分分布式系统是基于主从模式,完全意义上的 P2P 分布式系统多见于区块链领域,在主从模式的分布式系统主节点(Leader)进行元数据和集群的管理,从节点进行数据和任务的执行,下图是 Zookeeper 的集群架构图:
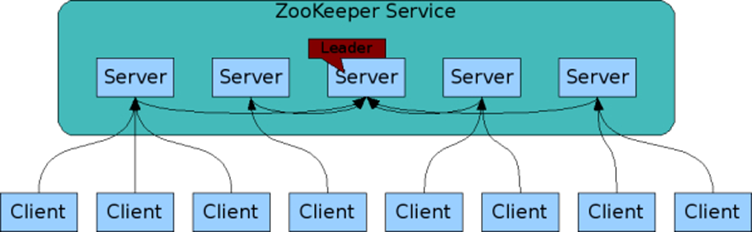
在集群中节点启动后选举出 Leader 节点,该节点负责接收事务性请求并将数据同步给其他节点。选举基于 Zab 协议来进行,选举过程如下图所示:
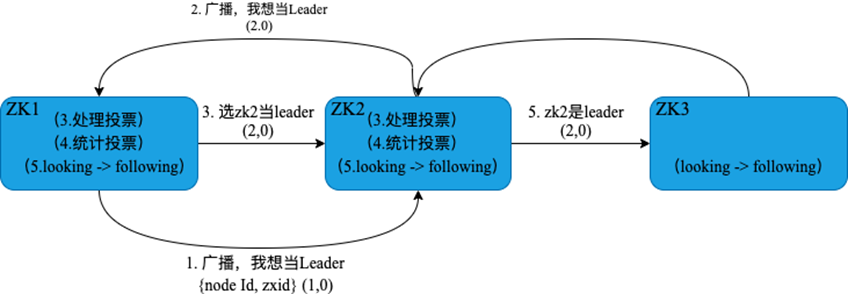
当节点收到其他节点发送过来的选举投票信息,对所有的投票进行统计,超过半数节点接受来自相同的投票信息则选举该投票信息中的节点为 Leader。
数据同步
在 CAP 理论中唯一确定要满足的是分区容错性,当集群失去部分节点不会导致分布式系统停止服务。分区容错性的核心是将数据以副本的方式分布在多个节点,以达到丢失少了节点仍然可以为客户端提供数据查询,在 HDFS 中数据默认以三副本的方式存放到不同的节点上,因此保证数据的高可用性。
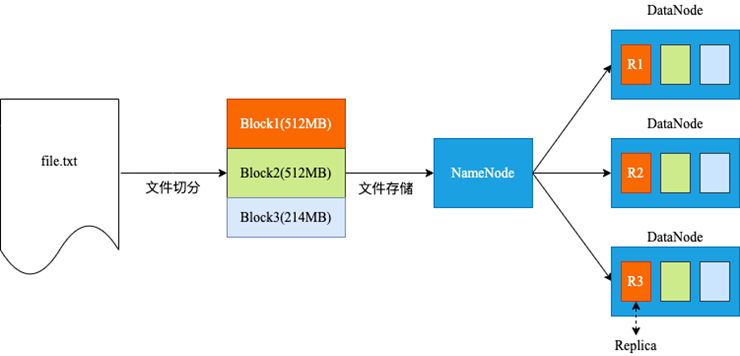
这里涉及到两个概念:
•分区(分片)
为了实现分布式文件系统可靠的存储超大文件,需要将每个文件切分成多个数据块(Block/Split),通过这种方式可以解决单块盘无法存储超大文件的问题,同时可以实现文件的并发读写的功能,提高系统的吞吐量。除了 HDFS,Swift、Ceph、Lustre 等分布式存储技术均采用分区(分片)来实现存储系统的扩展性。当然分区与分布式文件系统的高可用性没有相互作用关系。
•副本(Replica)
在分布式集群中多个节点存储多份相同的数据,相互备份,也称为副本。副本机制是分布式存储系统高可用性的基础,当部分节点故障仍然有可用的副本来保证可用性,但是目前大多数分布式文件系统是最大努力实现可用性,不保证 100%的能力,在极端情况下可能会出现所有副本都丢失的情况,例如 Hadoop 的三副本可以达到的高可用性是 99.99%,增加副本可以提高可用性,但是边际收益太低。
数据的同步模块是为了解决当有数据事务性请求(写、修改等)时所有的副本保存一致性的机制,根据对可用性的需求可以对一致性分为:强一致性和弱一致性,强一致性要保证所有副本写入成功后才能响应读操作,而弱一致性是为了不影响客户体验提高可用性,在某些副本上没有完全同步成功写入则响应读写操作。但是所有的分布式系统都不能完全牺牲一致性,否则就会失去分布式系统的意义,因此最终一致性(经过一段时间后要求能够访问到更新的数据)是底线。
这里以实际的分布式系统作为案例介绍几种实现多副本一致性的机制。
链式(流水线)复制机制
之所以将这种机制放在最前面,并不是最常用的方式,而且本人最先接触到到这种复制机制。在链式复制机制中,副本按照一定的顺序关系组织成副本复制链,数据有写请求时先写入到某个副本然后依次传播到其他副本,当所有副本写入成功后才会允许客户端读,如下图所示:

上图是 HDFS 的链式(流水线)复制机制,若干个 DataNode 串联成整条链,数据由客户端流向 Pipeline,依次传输。当最后一个 DataNode 接收到 Packet 后向前一个 DataNode 发送 ACK 响应,表示已经收到 Packet,当客户端收到第一个 DataNode 的 ACK,表示此次 Packet 传输成功。这种方式提供了写入数据的强一致性。
Quorum 复制机制
分布式系统最常用来保证数据冗余和最终一致性的投票算法,Zookeeper 及 BookKeeper 一致性都是基于 Quorum 复制机制来实现,数学思想来源于鸽巢原理,定义如下:
分布式系统中的每一份数据复制对象都被赋予一票。每一个操作必须要获得最小的读票数(Vr)或者最小的写票数(Vw)才能读或者写。如果一个系统有 V 票(意味着一个数据对象有 V 份冗余拷贝),那么这最小读写票必须满足:Vr + Vw > V,Vw > V/2。
第一条规则保证了一个数据不会被同时读写。当一个写操作请求过来的时候,它必须要获得 Vw 个冗余拷贝的许可。而剩下的数量是 V-Vw 不够 Vr,因此不能再有读请求过来了。同理,当读请求已经获得了 Vr 个冗余拷贝的许可时,写请求就无法获得许可了。
第二条规则保证了数据的串行化修改。一份数据的冗余拷贝不可能同时被两个写请求修改。
当分布式集群中数据在 5 个节点上有副本,通常写操作要对所有副本数据都更新完成才能认为写入成功,对于写操作频繁的系统很容易产生瓶颈。但是使用 Quorum 算法后,写操作只要写完 3 个副本就可以返回,剩余的副本由系统内部缓慢同步完成即可,而读操作也同样需要至少读 3 台来保证可以读到一个最新的数据。Quorum 的读写的票数可以是可调节的参数,写票数 Vw 越大,而读票数越小,系统的写开销就大。在选举机制中介绍的过半数学思想与鸽巢算法是相同的含义,可以不用区分。
下面是 Apache BookKeeper 的基于 Quorum 复制机制的基本原理图:
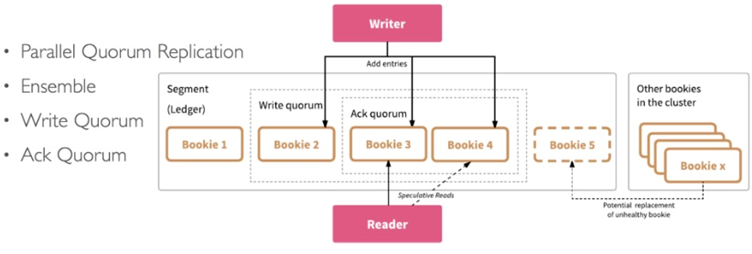
在 BookKeeper 中 Ledger 是一组追加有序的记录,客户端创建后可以对其进行追加写操作,Ensemble Size 是 Ledger 所涉及到的 Bookie 集合; Write Quorum 是写入要求的副本数;Ack Quorum 是客户端写入 Write Quorum 后返回确认的集合,当超过 ACK 要求的个数则认为写入成功,客户端可以进行数据的读取。
当发起一条 Entry 的写请求后,Entry 会被赋予一个严格递增的 Id,对于所有的追加操作都是异步的,第二条记录不用等写第一条记录返回,但是写操作操作是按照递增顺序 Ack 给 Writer,然后更新 LAC 指针,记录确认写入成功的记录。
PacificA 复制机制
Quorum 复制机制的优势是写数据响应快,但是难点是如何维护数据历史版本,吞吐率也不够高,通常用于元数据存储。PacificA 复制是微软提出的一种主从复制机制,Kafka 就是采用这种复制机制,写入过程如下图所示:
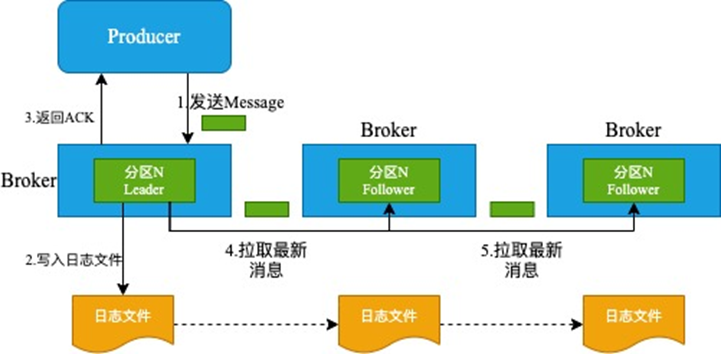
生产者向 Leader 副本发起写请求,写入成过后即返回成功,Follower 节点从 Leader 副本所在的节点同步数据,由于副本之间是异步同步不保证数据一致性,因此读客户端仅从 Leader 读数据来保证数据永远是最新的值。这种复制机制的优势是实现简单,写吞吐量较高,而且容忍更多节点故障,但是可用性较差当 Leader 故障需要一定的时间重新进行选主,而且由于读操作只能从主节点进行,因此读吞吐率较差。
以上介绍了几种常用的为了实现一致性而采用的数据复制机制,强弱一致性的选用是基于分布式系统对可用性的需求,但是对于客户端来说,写请求要保证数据要最终同步到所有副本、读请求要获取最新的值,还有其他问题需要考虑,例如节点故障后如何保证数据的副本数量及数据的恢复等,这里不再详述,可以在后续文章中进行解析。
参考链接
•https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
•https://wingsxdu.com/posts/database/zookeeper/•https://mp.weixin.qq.com/s/S_8AbIOaWNmRMxOWNLQSHw

移动云,5G时代你身边的智慧云 2019.02.13 加入
移动云大数据产品团队,在移动云上提供云原生大数据分析LakeHouse,消息队列Kafka/Pulsar,云数据库HBase,弹性MapReduce,数据集成与治理等PaaS服务。 微信公众号:人人都学大数据









评论