基于 Web 引擎扩展技术的 RTC 混合开发框架实践
为什么我们要独立开发 WEBRTC 框架

现在市面上缺失好的基于 WEBRTC 的框架,我们希望做的框架能够充分利用原生平台的自由拓展能力、安全性、以及 WEB 的一些优良开发特性及生态等等。像传统原生的音视频应用,一般在针对特定平台系统的客户端,都会做特殊的技术优化,比如 window 平台会使用 MFC 或 WCF 等技术,能做到 16/32/64 路视频的高清解码等等。像一些内容分发型应用,就需要突出内容更新及布局拓展能力,比如我们经常使用的桌面版微信,就是利用了前面提到的特性,除了内容渲染,为了保证传输的安全性,在实现方面将网络通信部分放在了原生平台去做。
未来 Web 应用是什么样的呢?2007 年谷歌 CEO 的对 web3.0 下定义的时候,他提到,希望未来的应用非常小,可以快速访问,并且能够支持跨平台。今天,就像我们现在经常使用的微信、支付宝里面的小程序,华为的快应用等,我们通过扫二维码或者点击链接的方式,就直接可以跳转到目标平台的应用,这就是一些 WEB 应用的优势,我们前端要发扬这些长处!
基于 WebRTC 的 Web 应用面临的问题

目前,针对 WebRTC 来说,最大的问题就是使用体验不理想,经常卡顿,主要问题我们可以简单从下面三点分析:
Web 平台碎片化严重。WebRTC 官方正式标准一直到最近两年才被确定下来,而且标准的迭代非常迅速,比如国外的 chrome、Firefox,国内的 360 浏览器、QQ 浏览器等等,都有基于自己想法上的可选性实现。
WebRTC 实现细节不可控。对于很多 Web 的开发者而言,我们往往比较关注的是 Media、Vedio 这些 HTML5 标签本身,但比如我要想控制里面的一些网络传输 FEC、弱网对抗、带宽估计、优先级保障等算法、使用特殊的编码解码,依赖纯 Web 是做不到的,这不是浏览器的使命,如果想要做这种更底层的控制,就只能要想其他办法参与到里面去。
计算密集型算法可选项少。我们很多时候需要对视频进行一些预处理的动作,比如美颜功能,现在通用的做法是首先需要获取到用户本地的一些原始的视频采集数据,然后绘制到 canvas 上,通过 canvas 接口获取到 imagedata,将 imagedata 传递到 Web Assembly,然后再对它进行进一步的算法运算,比如磨皮、提亮等等这些操作,然后重新绘制到 canvas 里面,这个过程链路本身比较长。还有一点就是 Web Assembly 技术本身,也是一直在不停发展,他本身有自己的限制,比如 Web Assembly 的实现是基于 chrome 本身的一个 render 主线程驱动。虽然后续出现了 Web worker 的工作线程实现以及并行计算等,但是执行性能也不是特别好,如果我们希望能够充分利用的计算资源,在这种情况下就很难实现。
另外,对于 GPU 部分,WebGl 实现的细节上是有侧重点的,因为浏览器 WEB 本身是要面向整个标签页的渲染,而不仅是视频窗口这一小块,所以相比专业的视频渲染性能方面的表现并不太好。
声网的一些实践解决思路分享

统一渲染引擎。针对 Web 平台碎片化问题,我们提供了一致的渲染引擎,让用户使用一个统一的运行渲染环境,以此来解决厂商、版本等差异引入的碎片化问题。
对于 WebRTC 的实现细节、算法这一块,属于应用可扩展部分,我们会尽量想办法,将这些能力封装到原生平台内部去实现。
PC 端应用的框架选型
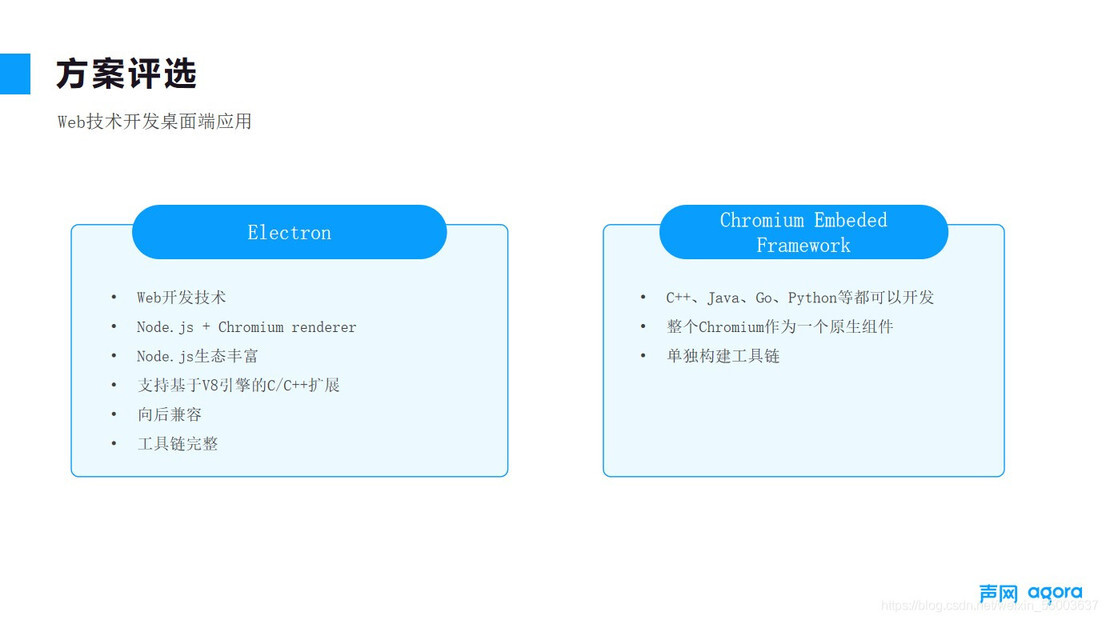
在最开始我们做技术评估的时候,可选框架有几大类,Electron、CEF、Qt 等等,但很多的开发框架,像 CEF 和 Qt 基础技术栈比较偏向 C、C++、Java 等等,开发习惯和生态上和我们前端开发体验不一致,尤其是它的开发工具链是需要独立构建,所以最终我们选择了 Electorn,它是基于 Nodejs 的一个技术方案,前端在开发的时候,我们可以使用熟悉的开发环境,比如说 Npm、yarn,还有包括后续的测试打包等整个构建过程。
扩展能力混合注入时的一些问题
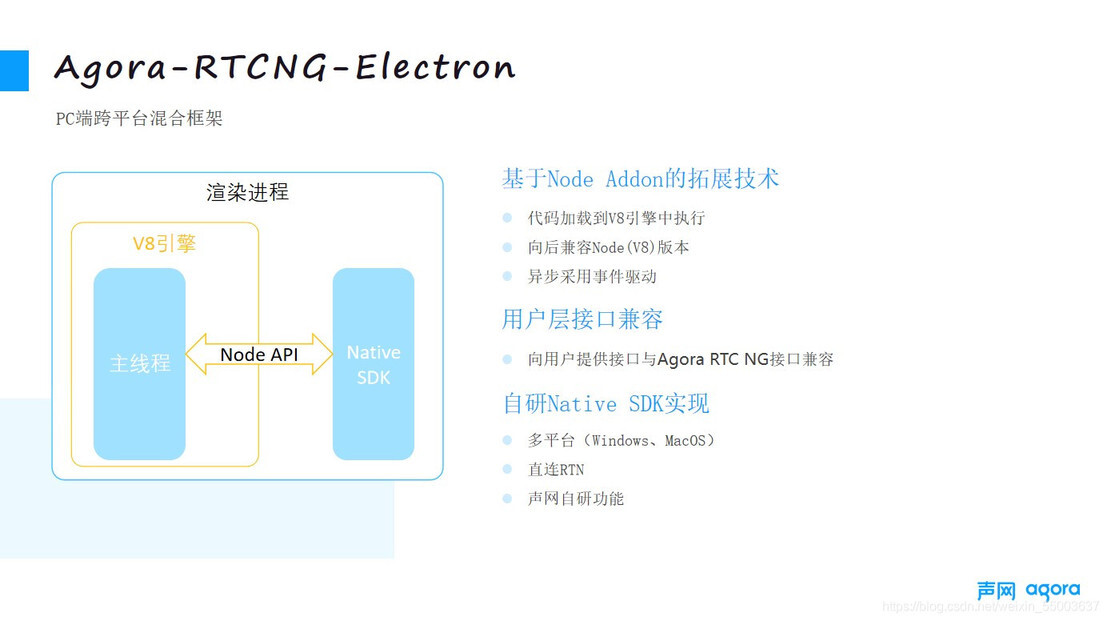
原生扩展能力问题
对于原生扩展能力的注入,我们将一些关键的业务逻辑的实现,通过用 C++代码放到 V8 引擎里与原生能力结合起来的,后续通过 bridge,将能力暴露给上层。这里最大的问题在于每一个 V8 引擎版本,底层 C++的接口并不一致,并且,随着 nodejs 版本的升级,每个版本里面的接口实现也略微不同的,这也是长期以来让社区比较诟病问题。这里我们的解决方案是,采用 nodejs 提供的 node api 实现,它是向后兼容的,以此来保持底层接口一致性,解决开发插件接口和 node 版本依赖的问题。
当我们的 js 层调用通过 bridge 注入到 native 后,驱动我们另外一个团队开发的 native SDK,包含了声网主要的功能和算法,比如我们的 RTN 网络接入、AI 降噪算法、背景分割、超分算法等等。另外从前端开发体验上,用户只需要改动少量的代码,就可以完成基于 agora sdk ng 开发的自有 APP 的适配,这也是我们框架的初衷之一,保持外部开发用户的体验的基础上,能够提升它里面的应用能力。

异步事件驱动
音视频应用的特点就是它的数据体积比较大,每一帧数据根据用户视频分辨率的不同,从几 K 到几十 M 都有可能,同时,我们还必须对这些数据进行解码、编码等等操作,这就要求我们能够去充分使用用户本地的计算能力,这里就涉及到子线程相关的调度操作,通过异步事件驱动,我们可以设计异步事件的队列管理,原生平台生产、主线程消费的模式。另外因为单个数据体积比较大,如果渲染线程和异步线程数据交互通过 copy 进行交互,内存开销可想而知,这里就必须使用到一些 node api 提供的 external-ArrayBuffer 技术,类似智能指针引用的解决方案,我们只需要保证 Buffer 的生命周期即可,即在 js 层调用期间可用,指针销毁时同时销毁 buffer,避免内存泄漏。

动态分辨率问题
受限于网络风暴等等问题,我们用户很多时候分辨率很难保持 1080P 不变,这个时候我们就需要一些平衡算法,在帧率和分辨率之间做平衡,这种情况下,视频宽窄就有可能发生变化,那我们就需要针对这种情况做一些特殊处理,canvas 是可以通过更新 texture 的方式,适配视频数据帧的宽高、步长等,然后通过 CSS 样式控制整体页面渲染比例及布局即可,不需要再做重采样来保证宽高比,这个做法也是和传统原生视频应用渲染方面有明显差异的地方。
音频播放
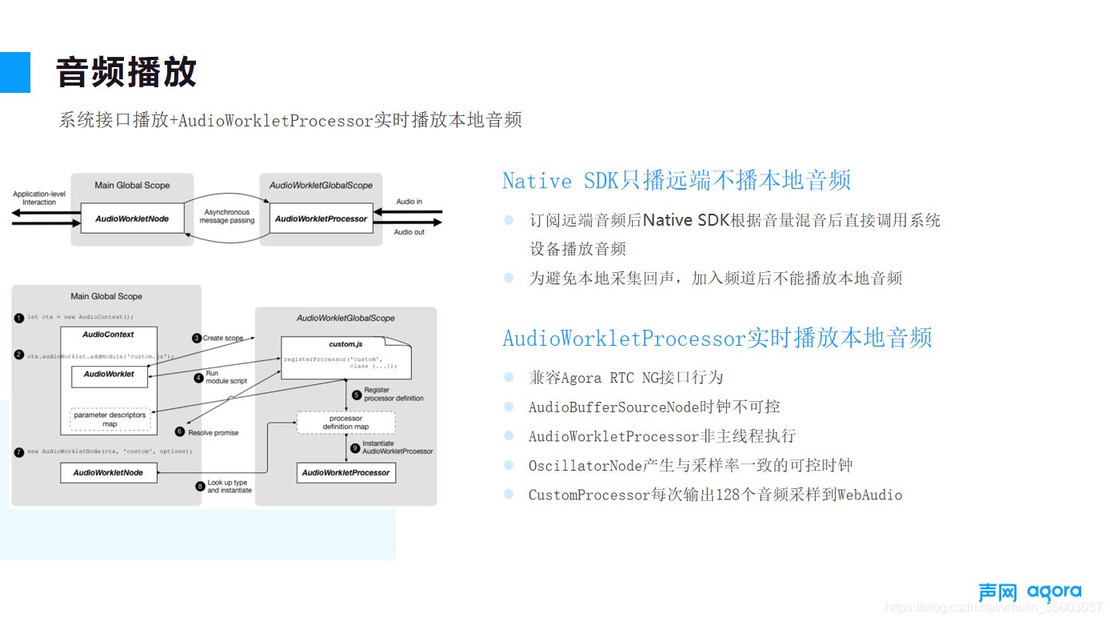
本地音频采集完一般不需要本地回放,但在一些业务场景下,我们的用户希望能够根据自己的声音反馈做一些特殊处理,比如用户会希望可以通过直观的听到自己的音量来调整麦克风的相对位置等等。而且这也算是我们为了能够保证与 agora sdk ng 这一致性功能。由于浏览器音频播放是异步执行的,即主线程将音频数据转发给音频线程,音频线程播放结束后通知主线程,主线程再处理下一个音频数据段,这个过程本身是会有始终消耗的,所以在实时音频播放场景中的直观体验就是,随着时间增长,时延累加明显,并且数据播放间隔出现有明显噪音。
我们的解决方案比较简单直接,采用 audio workletprocessor 接口,由我们来控制音频传递给音频播放线程的频率,流式传递音频数据到异步线程,这样就避免线程间反馈造成的时延累加,听起来会很顺滑,加上每次数据段比较短,约 10ms 左右,用户听起来就感觉自己的声音变大了,没有明显的回音感。
未来展望

未来我们希望能够把更多声网 nativeSDK 能力暴露到上层应用中,比如我们的桌面共享、AI 降噪、美声、vp9 编码解码、背景分割、美颜、超分等等,我们声网内部已经进入到测试环节,后续也希望能够赋能给我们的用户更加方便、强大的 Web 应用开发能力。

上海白玉兰开源开放研究院 2017.10.23 加入
由上海交通大学牵头,联合电子中国电子技术标准化研究院、北京大学、机器之心、复旦大学、华东师范大学、开源社、上海人工智能研究院有限公司等单位成立上海白玉兰开源开放研究院 http://www.baiyulan.org.cn/









评论