
YOLOX-PAI: 加速 YOLOX, 比 YOLOV6 更快更强
作者:忻怡、周楼、谦言、临在
导言
目标检测(object detection)旨在定位并识别出图像中的目标物体,一直以来都是计算机视觉领域研究的热点问题,也是自动驾驶、目标追踪等任务的基础。近年来,优秀的目标检测算法不断涌现,其中单阶段的 YOLO 系列以其高效、简洁的优势,始终是目标检测算法领域的一个重要分支。2021 年,旷视提出 YOLOX[1]算法,在速度和精度上构建了新的基线,组件灵活可部署,深受工业界的喜爱。本文基于阿里云 PAI-EasyCV 框架复现 YOLOX 算法,探究用以实际提升 YOLOX 精度的实用技巧,并进一步结合阿里巴巴计算平台 PAI 自研的 PAI-Blade 推理加速框架优化模型性能。经过我们对社区诸多 YOLOX 改进技巧的复现和探索,进一步提升了 YOLOX 的性能,在速度和精度上都比现阶段的 40~50mAP 的 SOTA 的 YOLOv6 更胜一筹。同时,PAI-EasyCV 提供高效简洁的模型部署和端到端推理接口,供社区快速体验使用 YOLOX-PAI 的功能。
总结一下我们的工作贡献:
我们提供了一套 Apache License 训练/优化/推理的代码库以及镜像,可以实现当前社区 40+MAP 量级最快(相比 YOLOV6 +0.4mAP/加速 13~20%)的目标检测模型。
我们调研了 YOLOX 相关的改进技术和消融实验,挑选了其中一些相对有帮助的改进,补齐了 40/0.7ms(YOLOXS)~47.6/1.5ms(YOLOXM) 之间的模型,并以配置的方式提供出来。
我们对目标检测的端到端推理进行灵活封装及速度优化,在 V100 上的端到端推理为 3.9ms,相对原版 YOLOX 的 9.8ms,加速接近 250%,供用户快速完成目标检测推理任务。
本文,我们将逐一介绍所探索的相关改进与消融实验结果,如何基于 PAI-EasyCV 使用 PAI-Blade 优化模型推理过程,及如何使用 PAI-EasyCV 进行模型训练、验证、部署和端到端推理。欢迎大家关注和使用 PAI-EasyCV 和 PAI-Blade,进行简单高效的视觉算法开发及部署任务。
PAI-EasyCV 项目地址:https://github.com/alibaba/EasyCV
PAI-BladeDISC 项目地址:https://github.com/alibaba/BladeDISC
YOLOX-PAI-算法改进
YOLOX-PAI 是我们在阿里云机器学习平台 PAI 的开源计算机视觉代码库 EasyCV(https://github.com/alibaba/EasyCV)中集成的 YOLOX 算法。若读者不了解 YOLOX 算法,可以自行学习(可参考:链接),本节主要介绍我们基于 YOLOX 算法的改进。
通过对 YOLOX 算法的分析,结合检测技术的调研,我们从以下 4 个方向对原版的 YOLOX 进行优化,
Backbone : repvgg backbone
Neck : gsconv / asff
Head : toods / rtoods
Loss : siou / giou
在算法改进的基础上,利用 PAI-Blade 对优化后的模型进行推理优化,开发了如下的 PAI-YOLOX 模型。筛选有效改进与现有主流算法的对比结果如下:
( -ASFF 代表使用了 NeckASFF, -TOODN 代表使用 N 个中间层的 TOODHead 取代原有的 YOLOXHead)
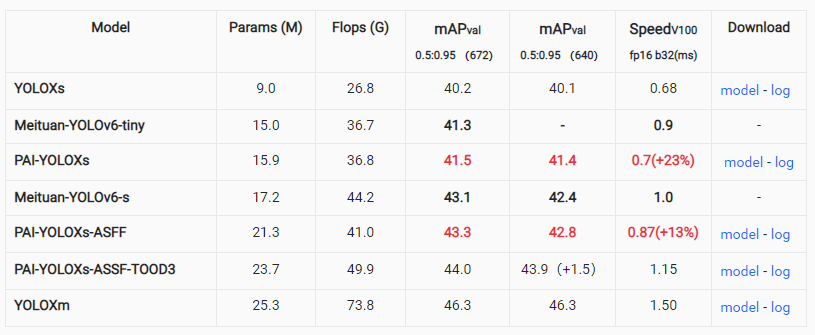
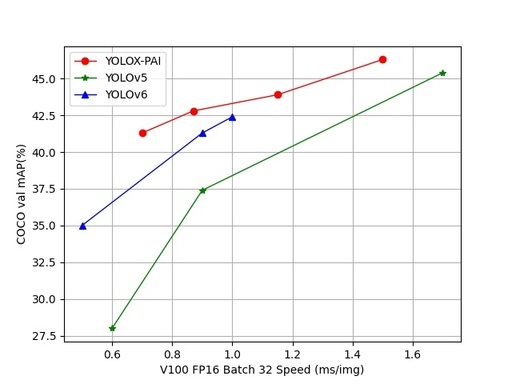
从结果中可以看到,相比目前同水平(1ms 以内)SOTA 的 YOLO6 模型,融合上述改进的 YOLOX-PAI 在同等精度/速度的条件下有一定的速度/精度优势。
有关测评需要注意以下几点:
YOLOV6 release 测试速度不包含 decode 和 nms,所以我们为了公平对比,也进行了相关测速设置的关闭。(上表所示结果计算了 Blade 优化后的对应模型在 bs32 下平均一张图像模型前向推理所用时间,关于端到端推理的时间(包含图像前、后处理的总用时)见 PAI-EasyCV Export 一节)
YOLOV6 release 的精度是在训练过程中测试的,会出现部分 shape=672 的情况,然而测速是在导出到 image_size=(640, 640) 的完成,实际上社区也有相关同学补充了 YOLOV6 在 640 下的测试精度,所以上表放了两个测试精度。
使用 EasyCV 的 Predictor 接口加载相关模型预测进行从图片输入到结果的预测,由于包含了预处理和 NMS 后处理,相对应的时间会变慢一些,详细参考端到端优化结果。
下面我们将详细介绍每一个模块的改进和消融实验。
Backbone
RepConv
近期 YOLO6 [2],PP-YOLOE [3]等算法都改进了 CSPNet[4]的骨干网络,基于 RepVGG[5]的思想设计了可重参数化的骨干网络,让模型在推理上具有更高效的性能。我们沿用了这一思想,利用 YOLO6 的 EfficientRep 代替 YOLOX 原来的 CSPDarkNet-53 骨干网络。得到的实验结果与 YOLO6 相关模型对比如下(YOLOX-Rep 表示使用了 EfficientRep 作为骨干网络的 YOLOX 模型):
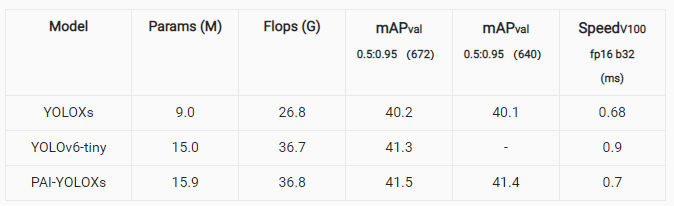
RepVGG 结构的网络设计确实会增大参数量和计算量,但实际推理速度都更有优势,所以我们选择 YOLO6 EfficientRep 作为可以配置的 Backbone。
Neck
在更换了骨干网络的基础上,我们对 Neck 部分分别进行了两方面的探究。
ASSF[6]:基于对 PAN 输出特征维度变换后基于 SE-Attention 特征融合的特征增强,大幅提升参数量和精度,部分降低推理速度。
ASSF-Sim : 我们选取了参数量更低的特征融合实现,用较少的参数量(ASFF:5M -> ASFF-Sim:380K)来保留了 84%的精度精度提升(+0.98map->+0.85map)。然而,这一改进会让推理速度变慢,未来我们会针对这个 OP 实现对应的 Plugin 完成推理加速。
GSNeck[7] :基于 DW Conv 对 Neck 信息融合,降低 Neck 参数量,轻微提升精度,也会会降低推理速度。
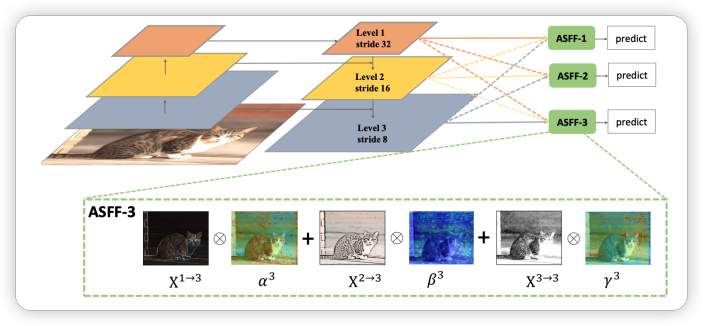
ASFF 信息融合
ASFF,通过进行不同 PAN 不同特征图之间的信息交互,利用 attention 机制完成 Neck 部分的信息融合和增强,具体思想如下图。
ASFF-SIM 轻量版
参考 YOLO5[8]中的 Fcous 层的设计,PAI-EasyCV 利用切片操作进行特征通道的增加和特征图的缩小。同时,利用求平均操作进行通道的压缩,基于这种实现的 ASFF,我们简单区分为 ASFF-Sim。我们进行特征图统一的核心操作(通道扩展和通道压缩)如下:
针对不同的特征图,其融合机制如下:


GSConvNeck
采用 DWConv 降低参数量是一种常用技巧,在 YOLOX 中,GSconv 设计了一种新型的轻量级的卷积用来减少模型的参数和计算量。为了解决 Depth-wise Separable Convolution (DSC)在计算时通道信息分离的弊端,GSConv(如下图所示)采用 shuffle 的方式将标准卷积(SC)和 DSC 得到的特征图进行融合,使得 SC 的输出完全融合到 DSC 中。
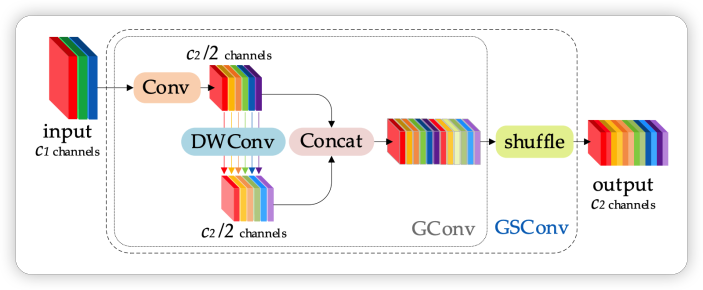
此外,GSConv 原文指出,如果在整个网络都使用 GSconv,则会大大加深网络的深度,降低模型的推理速度,而仅在通道信息维度最大,空间信息维度最小的 Neck 处使用 GSConv 是一种更优的选择。我们在 YOLOX 中利用 GSConv 优化模型,特别的我们采用了两种方案分别进行实验(a: 仅将 Neck 的部分用 GSConv,b: Neck 的所有模块均使用 GSConv):
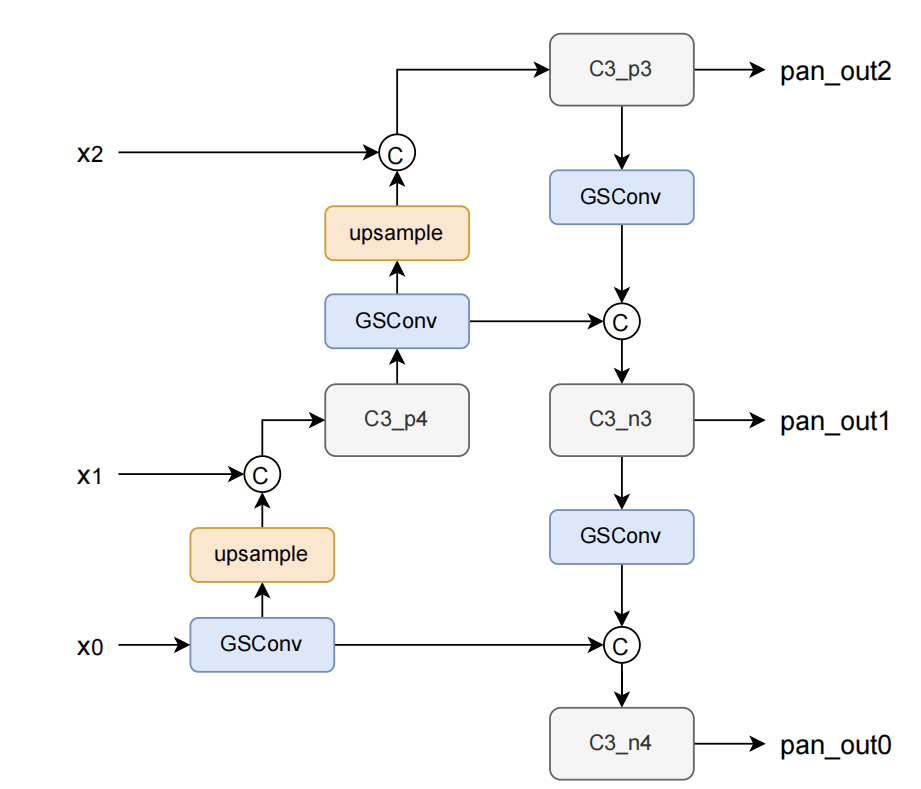
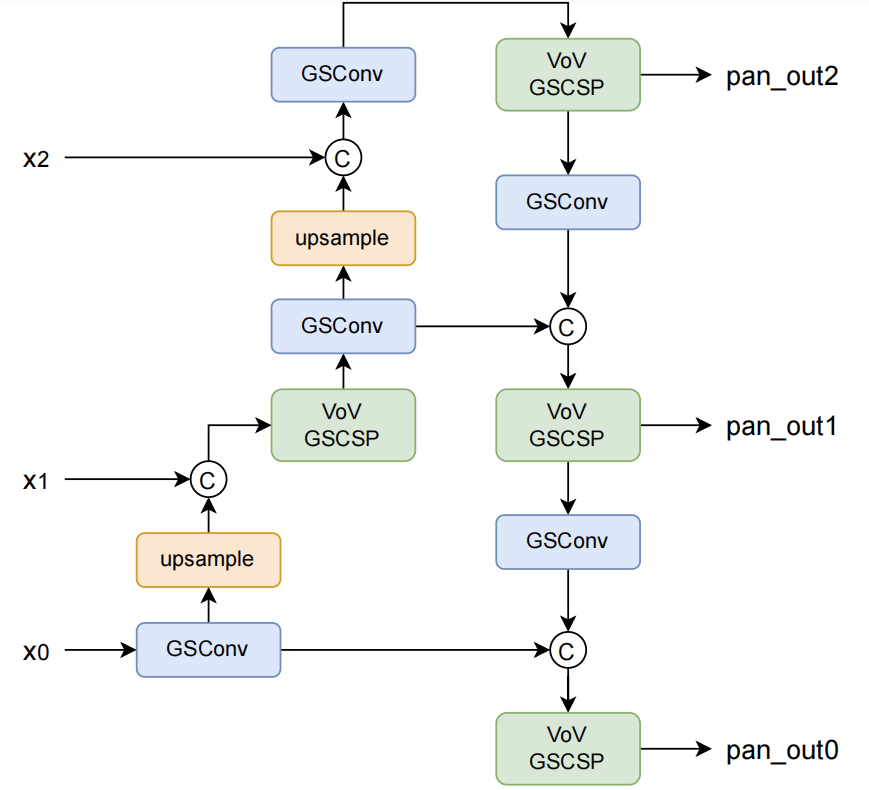
所得到的实验结果如下(仅统计 Neck 部分的 Params, Flops)。可以看到 GSConv 对参数量进行了优化,且提升了模型的性能,降低 3%的推理速度可以换来 0.3mAP 的提升。

Head
TOOD
参考 PPYOLOE,我们同样考虑利用 TOOD[9]算法中的 Task-aligned predictor 中的注意力机制(T-Head)分别对分类和回归特征进行增强。如下图所示,特征先通过解耦头的 stem 层(1x1)进行通道压缩,接着由通过堆叠卷积层得到中间的特征层,再分别对分类和回归分支利用注意力机制进行特征的增强,来解耦两个任务。
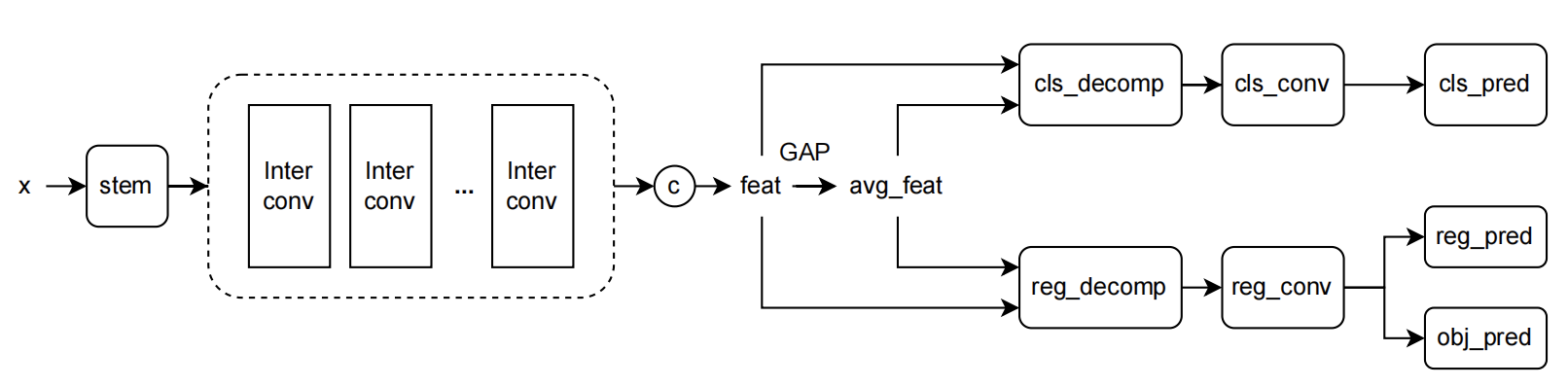
我们对堆叠的中间层个数进行消融实验,每堆叠可以进一步提升一定的精度,并带来速度上的一些损失。(下表的 Params 和 Flops 只统计了检测头部分。测速及精度基于的基线方法为以 EfficientRep 为 backbone + ASFF 进行特征增强。)
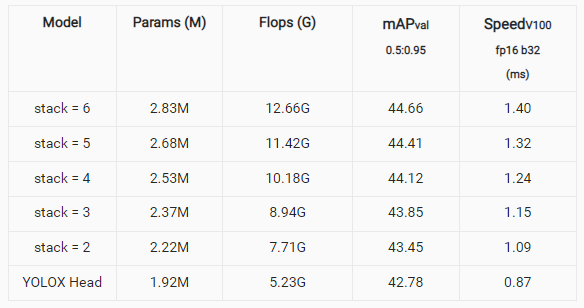
此外,我们利用 RepVGGBlock 分别优化 inter_conv,cls_conv/reg_conv 层。实验结果表明用 RepVGGBlock 实现 inter_conv 层会带来性能上的下降,而 RepVGGBlock 实现的 cls_conv/reg_conv 层与原始卷积层在 stack 较大时效果相当,在 stack 比较小时,RepVGGBlock 能起到优化作用。
Loss function
S/G/D/E/CIou
PAI-EasyCV 实现了社区常用的集中 IOU 损失函数,用户可以通过 config 自行选择,特别的,对于最新提出的 SIoU[10],在实验过程中发现原公式中的反三角函数会使得模型训练不稳定,且计算开销相对较高,我们对原公式利用三角函数公式化简可得(符号与论文原文一致,详见原论文):

实验结果显示,在 YOLOX 上引入 SIoU 训练模型的确能加快模型的收敛速度,但在最终精度上使用 GIoU[11]性能达到最优。
综合上述 Backbone/Neck/Head/Loss 方向的改进,我们可以获得如上的 YOLOX-PAI 模型。进一步,我们采用 PAI-Blade 对已经训练好的模型进行推理优化,实现高性能的端到端推理。
YOLOX-PAI-推理优化
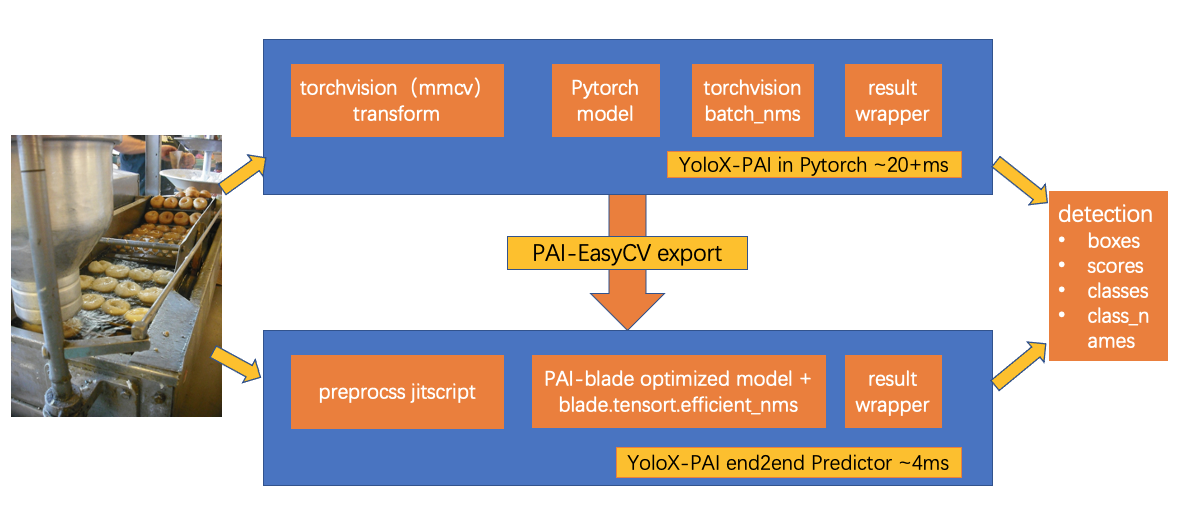
PAI-EasyCV Predictor
针对使用 PAI-EasyCV 训练的 YoloX-PAI 模型,用户可以使用 EasyCV 自带的导出(export)功能得到优化后的模型,并使用 EasyCV Predictor 进行端到端的推理。 该导出功能对检测模型进行了如下优化:
使用 PAI-Blade 优化模型推理速度,简化对模型的推理加速(TensorRT/编译优化)开发流程。
支持 EasyCV 配置 TorchScript/PAI-Blade 对图像前处理、模型推理、图像后处理分别优化,供用户灵活使用
支持 Predictor 结构端到端的模型推理优化,简化图片预测过程。
也可以参考[EasyCV detector.py] 自行组织相应的图像前处理/后处理过程,或直接使用我们导出好的模型和接口):我们这里提供一个已经导出好的检测模型,用户下载三个模型文件到本地 [preprocess, model, meta]
PAI-EasyCV Export
下面我们简单介绍如何通过 PAI-EasyCV 的配置文件,导出不同的模型(具体的模型部署流程即相应的配置文件说明介绍见链接),并展示导出的不同模型进行端到端图像推理的性能。
为导出不同的模型,用户需要对配置文件进行修改,配置文件的说明如下:
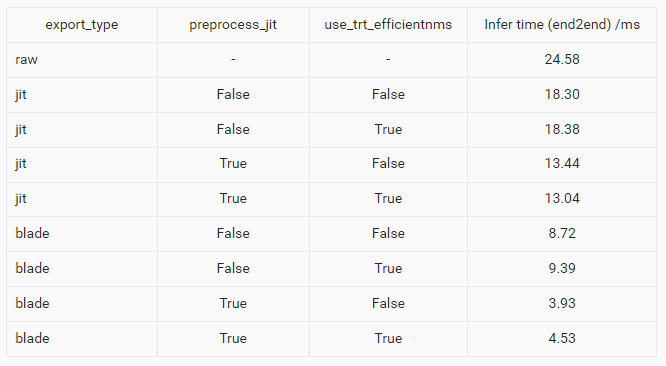
根据不同的模型配置,我们在单卡 V100 上测试 YOLOX-s 所有配置下模型的端到端推理性能 (1000 次推理的平均值):
下图,我们展示了由 PAI-EasyCV 中集成的使用 PAI-Blade/JIT 优化的模型端到端推理速度与 YOLOX 官方原版的 不同模型(s/m/l/x)的推理速度对比:
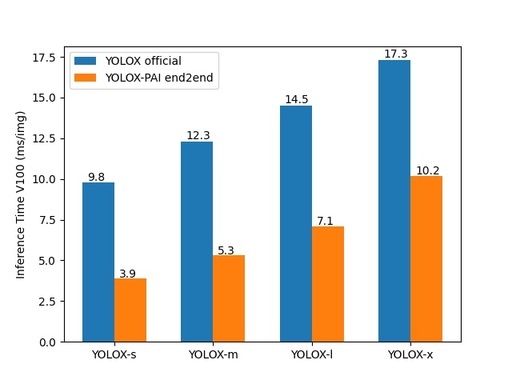
可以看到 PAI-EasyCV 导出的模型,极大程度的优化了原模型的端到端推理速度,未来我们将进一步优化 blade 接入 trt_efficientnms 的速度,提升端到端性能。
PAI-Blade 推理优化
PAI-Blade 是由阿里云机器学习平台 PAI 开发的模型优化工具,可以针对不同的设备不同模型进行推理加速优化。PAI-Blade 遵循易用性,鲁棒性和高性能为原则,将模型的部署优化进行高度封装,设计了统一简单的 API,在完成 Blade 环境安装后,用户可以在不了解 ONNX、TensorRT、编译优化等技术细节的条件下,通过简单的代码调用方便的实现对模型的高性能部署。更多 PAI-Blade 相关技术介绍可以参考 [PAI-Blade介绍]。
PAI-EasyCV 中对 Blade 进行了支持,用户可以通过 PAI-EasyCV 的训练 config 中配置相关 export 参数,从而对训练得到的模型进行导出。
这里我们提供一个 PAI-Blade + PAI-EasyCV 社区版 V100 对应的镜像(cuda11.1/TensorRT8/cudnn8):用户也可以基于 Blade 每日发布的镜像自行搭建推理环境 [PAI-Blade社区镜像发布]
用户执行如下导出命令即可
值得注意的是上文所有的模型的推理速度都限定在 V100 BatchSize=32 静态 Shape (end2end=False)的 PAI-Blade 优化设置结果。Blade 中已经集成了常见 OP 的优化,针对用户自定义的 op 可以参考 PAI-EasyCV 中的 easycv/toolkit/blade/trt_plugin_utils.py 自行实现。
YOLOX-PAI-训练与复现
我们在 PAI-EasyCV 框架中复现了原版的 YOLOX,及改进的 YOLOX-PAI,并利用 PAI-Blade 对模型进行推理加速。为了更好的方便用户快速体验基于 PAI-EasyCV 和 PAI-Blade 的 YOLOX,接下来,我们提供利用镜像对 YOLOX-PAI 进行模型的训练、测试、及部署工作。更多的关于如何在本地开发环境运行,可以参考该链接安装环境。若使用 PAI-DSW 进行实验则无需安装相关依赖,在 PAI-DSW docker 中已内置相关环境。
拉取镜像
启动容器
数据代码准备
模型训练
模型测试
模型导出
写在最后
YOLOX-PAI 是 PAI-EasyCV 团队基于旷视 YOLOX 复现并优化的在 V100BS32 的 1000fps 量级下的 SOTA 检测模型。整体工作上集成和对比了很多社区已有的工作:通过对 YOLOX 的替换基于 RepVGG 的高性能 Backbone, 在 Neck 中添加基于特征图融合的 ASFF/GSConv 增强,在检测头中加入了任务相关的注意力机制 TOOD 结构。结合 PAI-Blade 编译优化技术,在 V100Batchsize32 1000FPS 的速度下达到了 SOTA 的精度 mAP=43.9,同等精度下比美团 YOLOV6 加速 13%,并提供了配套一系列算法/训练/推理优化代码和环境。
PAI-EasyCV(https://github.com/alibaba/EasyCV)是阿里云机器学习平台深耕一年多的计算机视觉算法框架,已在集团内外多个业务场景取得相关业务落地成果,主要聚焦在自监督学习/VisionTransformer 等前沿视觉领域,并结合 PAI-Blade 等自研技术不断优化。欢迎大家参与进来一同进步。
YOLOX-PAI 未来规划:
基于 CustomOP(ASFFSim, EfficientNMS (fp16))实现的加速推理
[1] Ge Z, Liu S, Wang F, et al. Yolox: Exceeding yolo series in 2021[J]. arXiv preprint arXiv:2107.08430, 2021.
[2] YOLOv6, https://github.com/meituan/YOLOv6.
[3] Xu S, Wang X, Lv W, et al. PP-YOLOE: An evolved version of YOLO[J]. arXiv preprint arXiv:2203.16250, 2022.
[4] Wang C Y, Liao H Y M, Wu Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2020: 390-391.
[5] Ding X, Zhang X, Ma N, et al. Repvgg: Making vgg-style convnets great again[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 13733-13742.
[6] Liu S, Huang D, Wang Y. Learning spatial fusion for single-shot object detection[J]. arXiv preprint arXiv:1911.09516, 2019.
[7] Li H, Li J, Wei H, et al. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles[J]. arXiv preprint arXiv:2206.02424, 2022.
[8] YOLOv5, https://github.com/ultralytics/yolov5.
[9] Feng C, Zhong Y, Gao Y, et al. Tood: Task-aligned one-stage object detection[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE Computer Society, 2021: 3490-3499.
[10] Gevorgyan Z. SIoU Loss: More Powerful Learning for Bounding Box Regression[J]. arXiv preprint arXiv:2205.12740, 2022.
[11] Rezatofighi H, Tsoi N, Gwak J Y, et al. Generalized intersection over union: A metric and a loss for bounding box regression[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 658-666.

还未添加个人签名 2020.10.15 加入
分享阿里云计算平台的大数据和AI方向的技术创新和趋势、实战案例、经验总结。








评论