一,为什么要用内存池
C++程序默认的内存管理(new,delete,malloc,free)会频繁地在堆上分配和释放内存,导致性能的损失,产生大量的内存碎片,降低内存的利用率。默认的内存管理因为被设计的比较通用,所以在性能上并不能做到极致。
因此,很多时候需要根据业务需求设计专用内存管理器,便于针对特定数据结构和使用场合的内存管理,比如:内存池。
【干货篇】为什么不推荐做mcu与qt开发,c++后台很香吗?
【纯干货】耗时数月吐血大整理十万字《深入理解Linux内核》要点笔记总结(高级程序员必备)
二,内存池原理
内存池的思想是,在真正使用内存之前,预先申请分配一定数量、大小预设的内存块留作备用。当有新的内存需求时,就从内存池中分出一部分内存块,若内存块不够再继续申请新的内存,当内存释放后就回归到内存块留作后续的复用,使得内存使用效率得到提升,一般也不会产生不可控制的内存碎片。
三,内存池设计
算法原理:
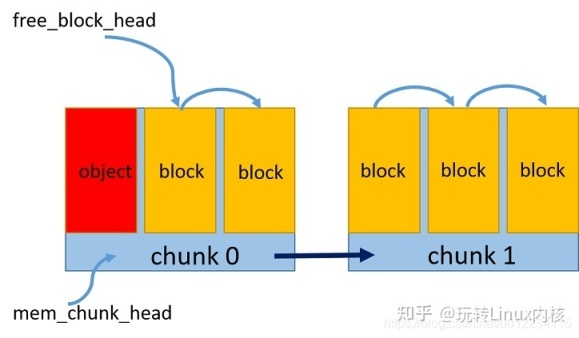
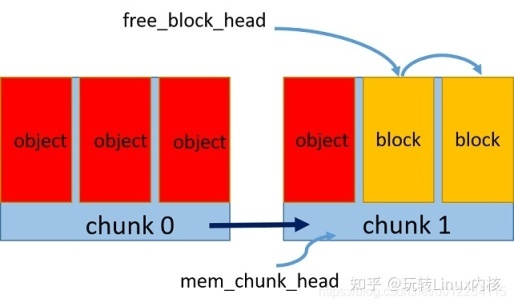
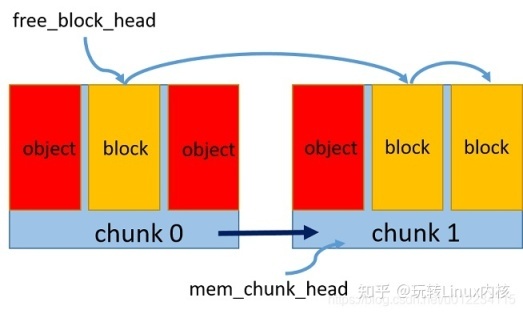
预申请一个内存区 chunk,将内存中按照对象大小划分成多个内存块 block
维持一个空闲内存块链表,通过指针相连,标记头指针为第一个空闲块
每次新申请一个对象的空间,则将该内存块从空闲链表中去除,更新空闲链表头指针
每次释放一个对象的空间,则重新将该内存块加到空闲链表头
如果一个内存区占满了,则新开辟一个内存区,维持一个内存区的链表,同指针相连,头指针指向最新的内存区,新的内存块从该区内重新划分和申请
如图所示:
内存池实现
memory_pool.hpp
#ifndef _MEMORY_POOL_H_#define _MEMORY_POOL_H_
#include <stdint.h>#include <mutex>
template<size_t BlockSize, size_t BlockNum = 10>class MemoryPool{public: MemoryPool() { std::lock_guard<std::mutex> lk(mtx); // avoid race condition
// init empty memory pointer free_block_head = NULL; mem_chunk_head = NULL; }
~MemoryPool() { std::lock_guard<std::mutex> lk(mtx); // avoid race condition
// destruct automatically MemChunk* p; while (mem_chunk_head) { p = mem_chunk_head->next; delete mem_chunk_head; mem_chunk_head = p; } }
void* allocate() { std::lock_guard<std::mutex> lk(mtx); // avoid race condition
// allocate one object memory
// if no free block in current chunk, should create new chunk if (!free_block_head) { // malloc mem chunk MemChunk* new_chunk = new MemChunk; new_chunk->next = NULL;
// set this chunk's first block as free block head free_block_head = &(new_chunk->blocks[0]);
// link the new chunk's all blocks for (int i = 1; i < BlockNum; i++) new_chunk->blocks[i - 1].next = &(new_chunk->blocks[i]); new_chunk->blocks[BlockNum - 1].next = NULL; // final block next is NULL if (!mem_chunk_head) mem_chunk_head = new_chunk; else { // add new chunk to chunk list mem_chunk_head->next = new_chunk; mem_chunk_head = new_chunk; } }
// allocate the current free block to the object void* object_block = free_block_head; free_block_head = free_block_head->next;
return object_block; }
void* allocate(size_t size) { std::lock_guard<std::mutex> lk(array_mtx); // avoid race condition for continuous memory
// calculate objects num int n = size / BlockSize;
// allocate n objects in continuous memory // FIXME: make sure n > 0 void* p = allocate();
for (int i = 1; i < n; i++) allocate();
return p; }
void deallocate(void* p) { std::lock_guard<std::mutex> lk(mtx); // avoid race condition
// free object memory FreeBlock* block = static_cast<FreeBlock*>(p); block->next = free_block_head; // insert the free block to head free_block_head = block; }
private: // free node block, every block size exactly can contain one object struct FreeBlock { unsigned char data[BlockSize]; FreeBlock* next; };
FreeBlock* free_block_head;
// memory chunk, every chunk contains blocks number with fixed BlockNum struct MemChunk { FreeBlock blocks[BlockNum]; MemChunk* next; };
MemChunk* mem_chunk_head;
// thread safe related std::mutex mtx; std::mutex array_mtx;};
#endif // !_MEMORY_POOL_H_
复制代码
运行结果:
p1 00000174BEDE0440 1
p2 00000174BEDE0450 2
p3 00000174BEDE0450 3
p4 00000174BEDE0460 4
p5 00000174BEDD5310 5
p6 00000174BEDD5320 6
可以看到内存地址是连续,并且回收一个节点后,依然有序地开辟内存对象先开辟内存再构造,先析构再释放内存
注意
在内存分配和释放的环节需要加锁来保证线程安全
还没有实现对象数组的分配和释放











评论