
【精通内核】计算机程序的本质、内存组成与 ELF 格式
前言
📫作者简介:小明java问道之路,专注于研究计算机底层/Java/Liunx 内核,就职于大型金融公司后端高级工程师,擅长交易领域的高安全/可用/并发/性能的架构设计📫
🏆CSDN 专家博主/Java 领域优质创作者、阿里云专家博主、华为云享专家、51CTO 专家博主🏆
🔥如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主~
本文导读
精通真正的高并发编程,不仅仅是 API 的使用和原理!计算机最基础的程序是怎么组成的呢?这个都不知道,又如何能证明你的程序是高并发的?本文深入浅出,讲解程序的本质(编译的过程)、组成(程序所需的内存)与格式(ELF),希望读者可以构建计算机从写代码到编译到执行的链路的底层思维。
一、计算机程序的组成
1、程序执行的本质
我们先了解下我们平时写的程序都怎么写?怎么执行的?Java、Python、GO、C/C++等等语言,我们需要通过 IDE(Integrated Development Environment )中编写,Java 有 JDK、各个语言都有自己的集成开发环境,然后在 idea 或者 eclipse 等等开发工具,通过集成开发环境 IDE 中的编译器或者内置编译器,变成 CPU 能工作执行的格式来执行。
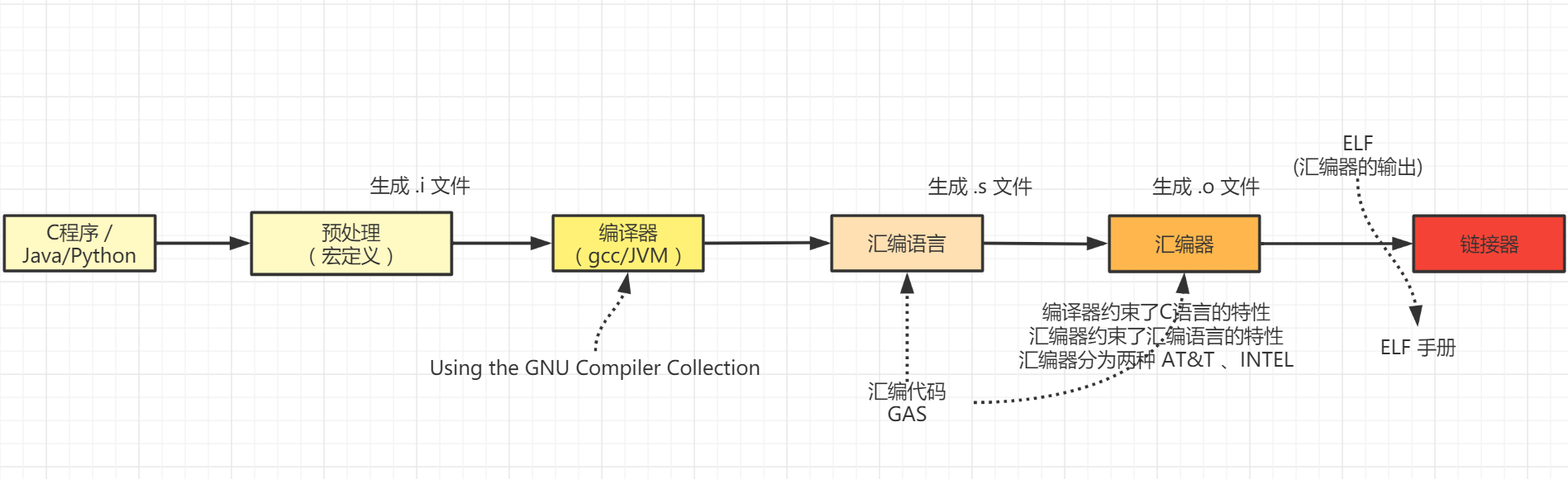
举一个简单的 C 语言的小例子,printf(''); 是操作硬件打印字符,由于只有 OS 才能操作硬件,所以这个函数调用,一定调用了系统调用的接口,由于系统调用的接口约定较为复杂,且每个 OS 都不一样,而 C 语言需要可移植性,所以推理得出 有个东西包装了系统调用过程,提供统一接口,给应用程序使用,那么其就会调用 GLIBC 的函数库函数。
<stdio.h> 等价于 java(其他语言的)import ,将函数定义导入,为什么导入?因为编译器需要这些东西,虽然不知道具体的函数地址、变量地址在哪里,但是知道调用的什么东西,编译器才能对其记录,并且在某个时候将它所需要的东西给出。
2、程序保存在哪里
上面说的,这些编译好的数据保存在我们的电脑上,具体在我们的计算机哪里,我们需要了解计算机有哪些存储器,存储器系统(memory system)是一个需要考虑多元因素存储设备的层次结构,例如容量、成本和访问时间。

这些编译好的数据就保存在磁盘上(local disks),然后我们用过系统调用告诉操作系统(OS),由操作系统来获取编译好的数据并进行解析,将这些数据从磁盘加载到内存(DRAM)。
然后在内存中创建一个进程来代表你写的这个程序,最后 CPU 执行。在这个过程中最重要的两个方面,一方面是上一小结的编译原理,另一方面就是这些编译好的数据是如何存储的,以及他们的格式是什么样的,这个格式就是操作系统(下属说操作系统都是 Linux)如何正确的解释汇编代码。
3、计算机程序的组成
计算机程序保存的位置我们知道了,程序在内存的细节就需要了解了,程序组成不是凭空而来的,我们在了解编译及编译器和计算机内存体系之后,看看程序应该由哪几部分组成
栈区(stack,用于存储函数的参数值、局部变量值等)编译器可以自动分配和释放。
堆区(heap)由程序员进行分配和释放(一些编译器中也会自动管理,例如 JVM 的 GC),若程序员不释放,程序结束由 OS 进行回收。
可执行程序包括 BSS 段、数据段、代码段:
数据段(data 段),初始化的全局变量和静态变量的区域,程序结束由 OS 释放。
BSS 段(Block Started bySymbol 以符号开始的块,BSS 是 Linux 链接器产生的未初始化数据段),未初试化的全局变量和静态变量的区域,只记录需要的内存大小并不实际存放数据,同样结束由 OS 释放。
代码段(text 段)存储程序的二进制代码和场景等。
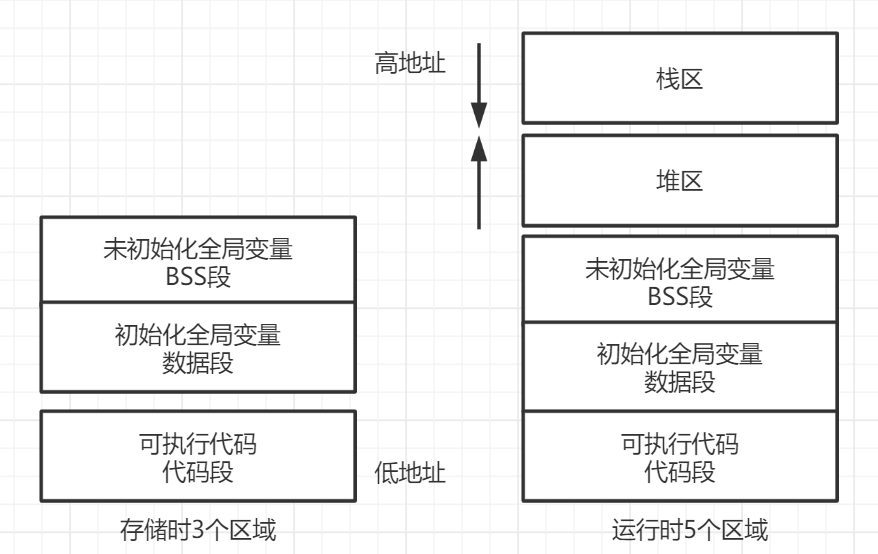
一个进程在运行过程中,代码是根据方法依次执行的,当然跳转和递归有可能使代码执行多次,而数据一般都需要访问多次,因此需要单独开辟空间以方便访问和节约空间。
临时数据及需要再次使用的代码在运行时放入栈区中,生命周期短。全局数据和静态数据有可能在整个程序执行过程中都需要访问,因此单独存储管理。堆区由用户自由分配,以便管理。
4、程序的格式(ELF)
ELF(Executable and Linkable Format,可执行链接的格式),这里的格式说的就是程序的格式,程序的格式分为 3 类:
可执行文件,文件保存着一个用来执行的程序(如 bash、gcc 等)。
可重定向文件,文件保存着代码和适当的数据,用来和其他的目标文件一起来创建一个可执行文件或者是一个共享目标文件(目标文件或者静态库文件,即 Linux 通常后缀为 .a 和 .o 的文件)。
共享目标文件,共享库文件保存着代码和合适的数据,用来被下连接编辑器和动态链接器链接(Linux 中后缀为 .so 的文件)。
本节用一个简单的例子,用 C 语言生成一个可执行文件,然后根据这个可执行文件分析和理解 ELF 格式下的 可执行文件的组成
用 gcc demo.c 命令执行后,将会得到一个 a.out 的文件,这个文件就是 ELF 文件可执行文件,当我们运行 ./.a,out 文件后,将会在控制台打印。
现在就通过这个得到的 a.out 文件来分析 ELF 文件的格式。这段代码的第一行 #include <stdio.h>,引入它是为了调用 printf 函数,底层通过调用 OS 提供的函数,向控制台打印,这不是我们自己实现的,这个步骤需要依赖 C 语言函数库 Glibc,而 stdio 就是含数据中包含的基本输入输出的定义。
但是我们编译后,可以看到并没有 Glibc->printf 的实现文件,那这个文件在哪里呢?
就在共享目标文件(共享链接库)中,并以 .so 结尾,在 Linux 中真正执行文件的输出操作的代码,已经在文件中了,接下来如何调用,这里面就涉及动态链接的知识
二、计算机程序的可执行文件
1、动态连接
我们再看上面代码,代码中包含的 stdio.h 会告诉编译器,我们需要依赖这个函数定义的函数。因此编译器编译好的 a.out 文件中包含一个动态的链接符好 printf,当运行 ./.a,out 时,OS 中动态链接器会发现该符不完整,还需要一个函数的地址,即 printf 的地址,这时链接器就会加载动态链接库,找到它的符号表,并发现文件中包含了 printf 函数,于是就把原来调用 printf 的符号地址修改为动态链接库中的真实地址。

通过上图可以看到,gcc demo.c 命令默认是使用动态链接的方式来生成可执行文件,这时的文件中不完整,因为它需要的 printf 函数是没有执行体的,只有一个符号, 称之为符号地址,当它被 OS 加载到内存中后,会通过动态链接器将符号地址修改为指向动态链接库的 printf 函数地址。通过 ll -h 命令,我们可以看到 a.out 文件的大小为 8KB。
2、静态连接
此时,读者肯定在想,为什么要在加载后由链接器找到真实的地址,而不是在编译生成 aout 文件时就将 动态链接库的代码包含其中呢?
相信这是大部分读者的想法。不过别着急,我们确实有办法让 a.out 在编译时就包含 printf 代码。这种方式被称为静态链接,可以通过可重定向文件 libc.a 实现,这个文件里同样包含 printf 的符号定义,但我们一般不这么做,我们看下静态编译的效果。

通过上图,描述了通过 gcc-static demo.c 命令生成可执行文件件,这时的文件就是完整的可执行程序,它不包含符号地址,并且都是指向真实函数执行地址,当 OS 将它加载进入内存后,可以直接执行,不需要通过动态链接器对它进行链接。
但是,我们却发现它的大小居然有 841KB。这个大小远大于使用动态链接生成的可执行程序。
此时,读者就知道二者之间的区别和使用选择了,假设有 100 个程序,都使用动态链接库函数,如果用动态链接,这 100 个线程可以共享这一个动态链接库。换而言之,内存里只会存在一份 printf 代码,100 个线程共享。但如果我们选择静态链接呢?将会造成内存里存在 100 份相同的 printf 代码。这肯定不好,占用内存,还得不到什么好处。
动态链接这么好,我们是否可以在任何场景下都用它呢?肯定不可以。静态链接虽然有缺点,但存在即合理。当开发者不想让使用者提供动态链接库时,可以直接给它一个静态链接生成的应用程序,这样使用者就不用再去安装依赖的动态链接库,直接执行即可。同时,也可以避免使用者发现开发者依赖了哪些动态链接库,进而推敲代码的功能和特点。
三、ELF 原理解析
1、ELF 格式及其原理
在了解了程序执行本质、程序的内存区域和格式、ELF 文件的 3 种体现形式、动态链接和静态链接的概念后
我们看看 ELF 文件格式到底是什么样子的,如下图所示。
ELF 文件可分为两部分来看待,即链接节(linkable section)和执行段(exectable segment)。
从链接器的角度看,看到的是一堆 section,也称之为节。
从 CPU 调度执行的角度看,看到的是一堆 segment,也称之为段。还记得前面学习的段寄存器吗?那是将内存分段,这里是将一个可执行程序按功能分如代码段、数据段等。
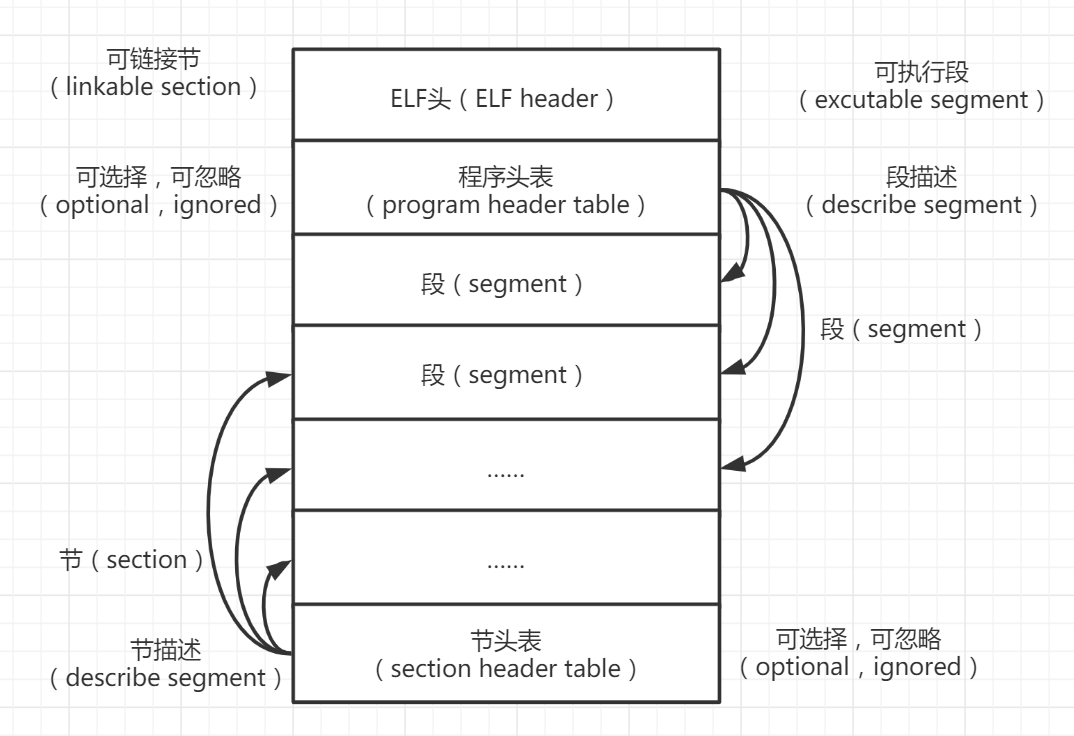
同 Java 语言编译后的 class 文件一样,它也有自己的头部,上图中 ELF header 头部的下方存在 program header table,用于告诉 OS 在加载这个可执行文件后,这些段在哪里。
文件末尾的 section header table 则由链接器识别使用,用寻找这个文件的用于链接的节处于文件的哪个位置。
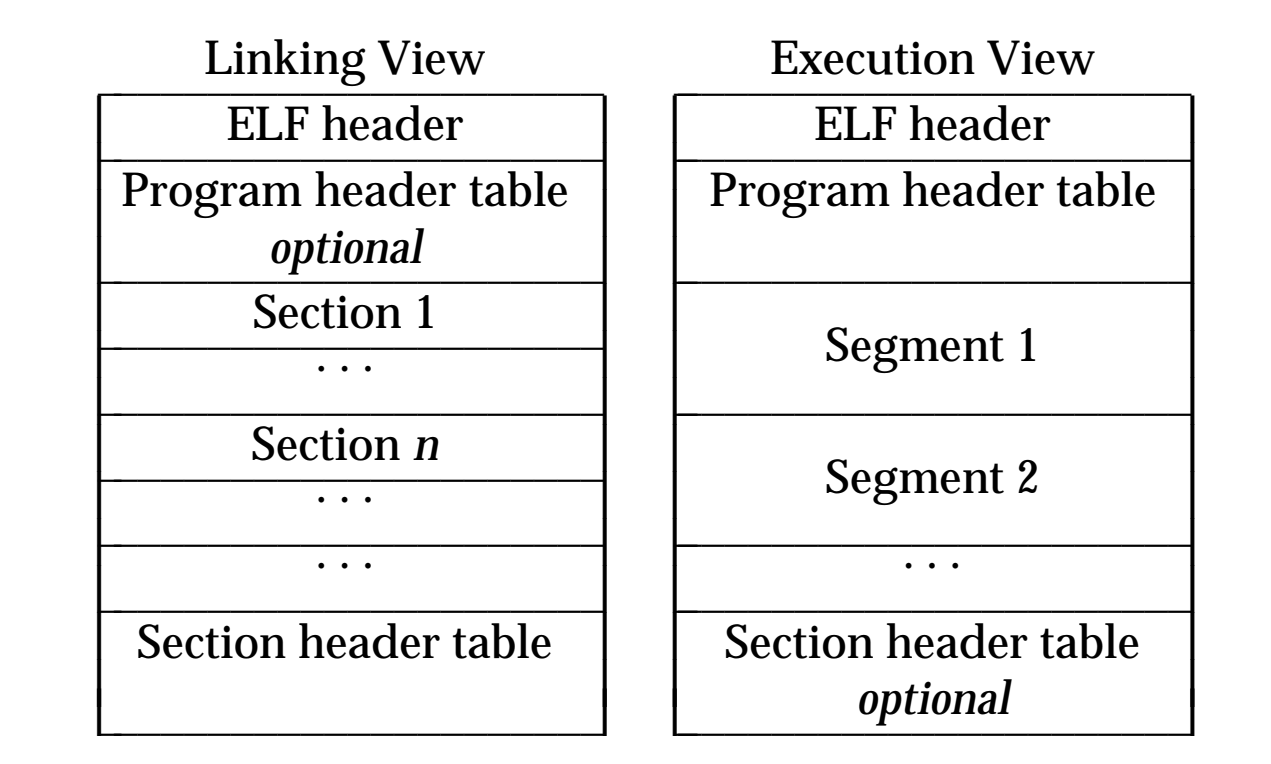
这时,我们可以给出结论,在动态链接器执行时,将忽略掉 program header table,只使用 section header table;而当程序被执行时,将忽略掉 section header table,只使用 program header table,同时一个 segment 段可以由多个 section 节组成。下图描述了 ELF 文件的不同视图。
2、ELF 文件内部实现
2.1、ELF header 文件头分析
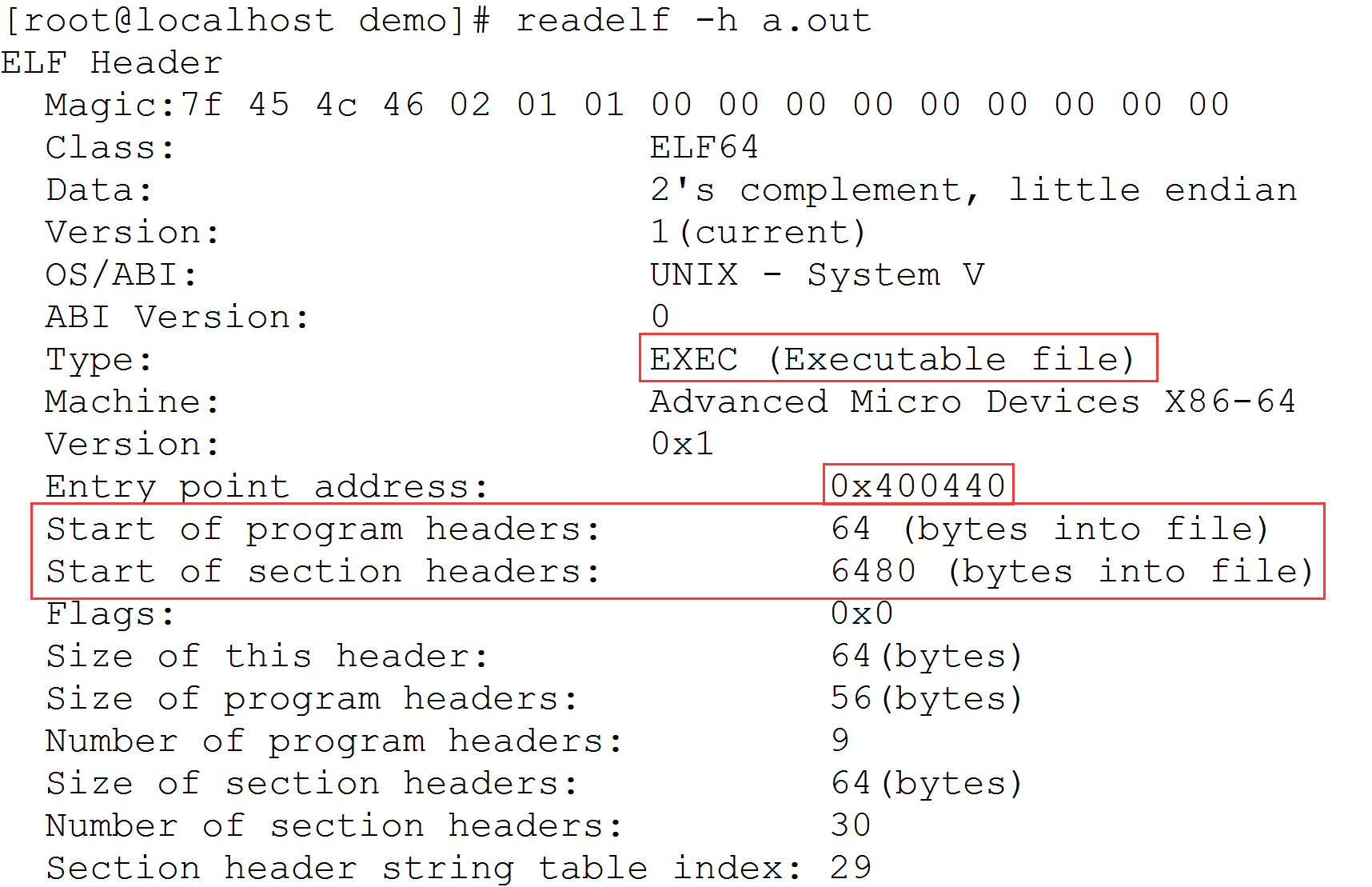
ELF header 开始了解 ELF 文件格式,仍然用 hello world 的例子,用 gcc demo.c 生成使用动态连接的可执行文件。
使用 readelf -h a.out 指令输出 a.out 执行程序的 ELF 头部信息。同 Java 中的 .class 文件一样,ELF 也需要 magic 变量来表明它是一个 ELF 文件,且类别为 ELF64。此外,ELF 还需要使用版本信息和数据信息。这里,只需要关注以下几条信息。
MELF 类型为 EXEC,表明为可执行文件。
Entry point address 程序开始执行点为 0x400440。
program headers 程序头部表在 64byte 偏移处。
section headers 节头部表处于 6480byte 偏移处。
此时,链接器或者 OS 就可以通过这些信息在内存中加载、链接、执行这个程序了。
当我们使用 gcc -static demo.c 、 readelf -h a.out 后可以看到,动态链接器的 INTERP 不见了,证明静态链接包含了所有需要的信息,所以不需要动态链接器的参与
2.2、ELF 文件 header table 头部表分析
接下来,看看这个程序的 Program headers table 信息。
使用 readelf -l a.out 命令输出其 Program headers 信息,从下图可以看出以下信息。
PHDR,表明程序头部表的虚拟地址信息(偏移量为 0x40,十进制为 64byte,即 Program headers
地址)。
INTERP,表明程序被 OS 加载到内存中后,必须调用的解释器,它通过链接其他库来满足未解析的符号引用,用于在虚拟地址空间中映射当前程序运行所需的动态链接库的函数,如程序中使用的 printf 函数。
LOAD,表明当前程序文件映射到虚拟地址空间的段,其中保存了常量数据(如字符串)、程序目标代码等。另外,还可以通过后面跟着的权限位来判断是代码段还是数据段,其中 RE 表明为可读、可执行的段,则为代码段;RW 表明可读、可写的段,则为数据段。
DYNAMIC,表明保存了由动态连接器,即 INTERP 段中指定的解释器使用的信息。
Section to Segment mapping,表明,这些段由 section 节组成。

2.3、ELF 文件 section 节信息分析
接下来,我们来分析程序的 section 节信息。通过 readelf -S a.out 命令,可得到 section 节信息。包含了当前程序的节表信息,包括每个节的大小、类型、虚拟地址信息和偏移量。通过这些信息我们可以在动态链接时组合成相应的段信息。对于每个节的标志位,Key to Flags 中已经给出,这里不再赘述。通常我们可以看到以下节信息。
.hash:符号哈希表。
.dynsym、.dynstr:动态链接符号表,动态链接字符串表。
.rel.dyn、.rel.plt:节区中包含了重定位信息。
.init:此节区包含了可执行指令,是进程初始化代码的一部分。当程序开始执行时,系统要在开始调用主程序入口之前(通常指 C 语言的 main 函数)执行这些代码。
.plt:此节区包含过程链接表(procedure linkage table)。
.text、.fini:此节区包含程序的可执行指令。fini 是进程终不止代码的一部分,程序正常退出时,系统将安排执行这里的代码。
.rodata:这些节区包含只读数据,这些数据道通常参与进程映像的只读代码段。
.init_array、.fini_array:进程初始化、退出时时所运行的函数指针数组。
.dynamic:此节区包含动态链接信息。
.got:此节区包含全局偏移表,其与 plt 一起协作完成符号的动态查找。
.data:节区包含初始化了的数据,将出现在程序的内存映像中。
.bss:包含将出现在程序的内存映像中的为初始化数据。根据定义,当开始执行程序时,系统将把这些数据初始化为 0。此节区不占用文件空间。
.comment、.debug_*:符号调试信息。
2.4、ELF 文件分析总结
对于 ELF 的文件描述和程的组成信息就描述到这里。这里读者只需要对程序组成有个基本印象,为后续的学习铺路,形成计算机思维。
读者可以看到,实际上程序分为 3 类,即共享目标文件、动态链接库和可执行文件。其中,可执行文件又分为可动态链接的执行文件和静态连接的执行文件。这里只分析了可动态链接的执行文件对比了静态连接的执行文件的程序头部表,看了看段信息,并没有去分析另外两类文件。这里给出了方法和相应的命令。
读者只需要通过本节了解如下信息即可,什么是 ELF,ELF header 的了解,什么是 section 节和 segment 段信息。
本文总结
本文深入浅出,讲解程序的本质(编译的过程),通过 C 语言代码的例子,分析程序从运行到 CPU 执行的整个过程和其中流转的原理。通过这个过程,我们开始了解程序的组成(程序所需的内存),程序保存在磁盘、内存,程序在内存中的由那几部分组成,堆区栈区代码段等等。最终通过这个保存,引申出程序的格式(ELF),分析了程序的动态连接、静态链接,什么是 ELF、ELF header 、section 节和 segment 段信息。相信这里读者对程序组成有个基本印象,为后续的学习铺路,形成完整的计算机思维。
版权声明: 本文为 InfoQ 作者【小明Java问道之路】的原创文章。
原文链接:【http://xie.infoq.cn/article/8f738c08e409b011e92acb03f】。文章转载请联系作者。

🏆博客专家 2020.03.20 加入
🏆 CSDN专家博主/Java领域优质创作者、阿里云专家博主、华为云享专家、51CTO专家 📫就职某大型金融互联网公司后端高级工程师 👍专注于研究计算机底层/Java/架构/设计模式/算法









评论 (3 条评论)