下拉推荐在 Shopee Chatbot 中的探索和实践

摘要
在主流的搜索引擎、购物 App 和 Chatbot 等应用中,下拉推荐可以有效地帮助用户快速检索所需要的内容,已经成为一项必需且标配的功能。本文将介绍 Shopee Chatbot 团队在 Chatbot 中从 0 到 1 构建下拉推荐功能的过程,并分享模型迭代优化的经验。
特别地,针对东南亚市场语种繁多的挑战,我们探索了多语言和多任务的预训练语言模型,并将其应用于下拉推荐中的向量召回,以优化召回效果。另一方面,为了使下拉推荐尽可能帮助用户,并解决用户的问题,我们针对用户点击与问题解决这两个目标进行了同时建模,在多目标优化方面也做了探索。
本文首发于微信公众号“Shopee技术团队”。
1. 业务背景
1.1 Shopee Chatbot
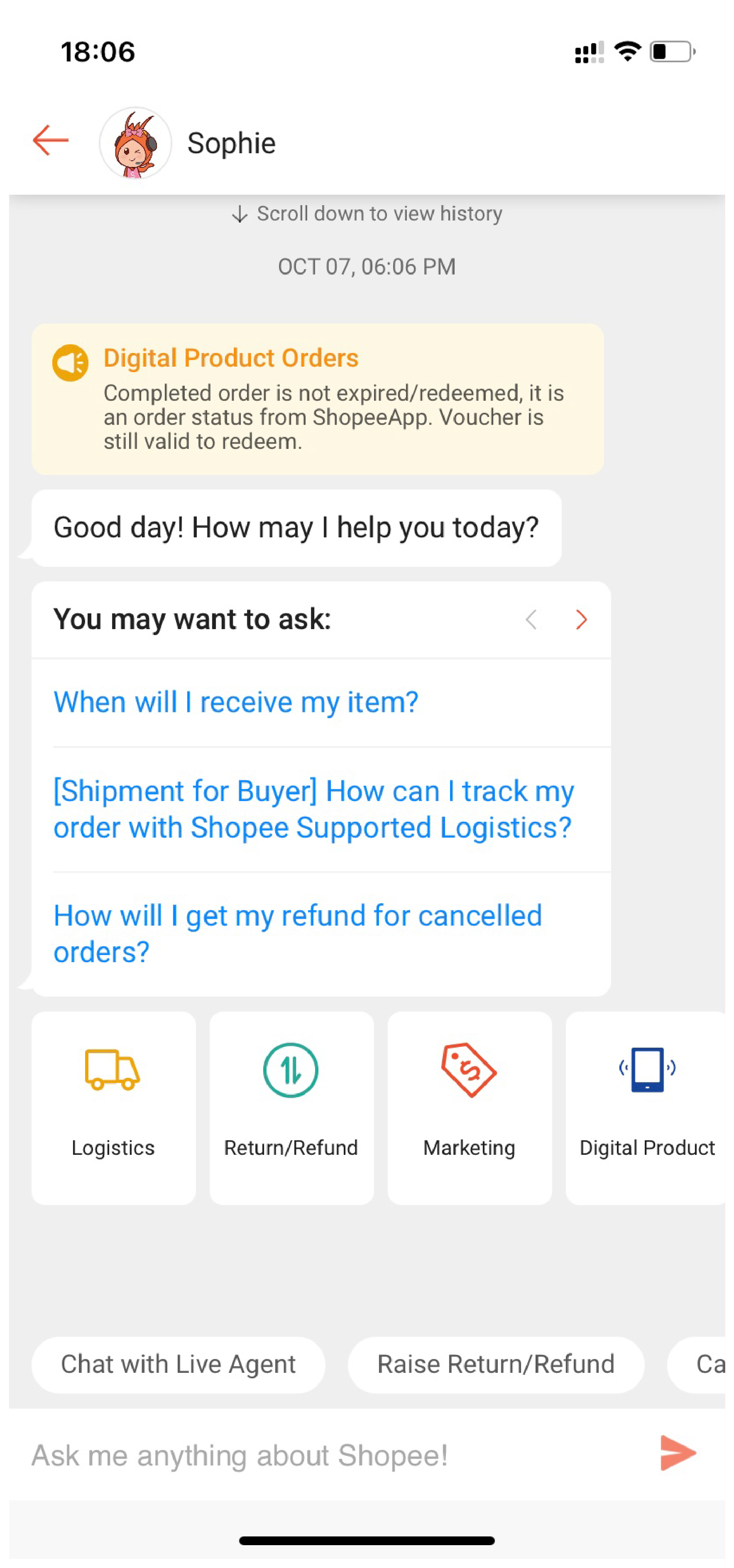
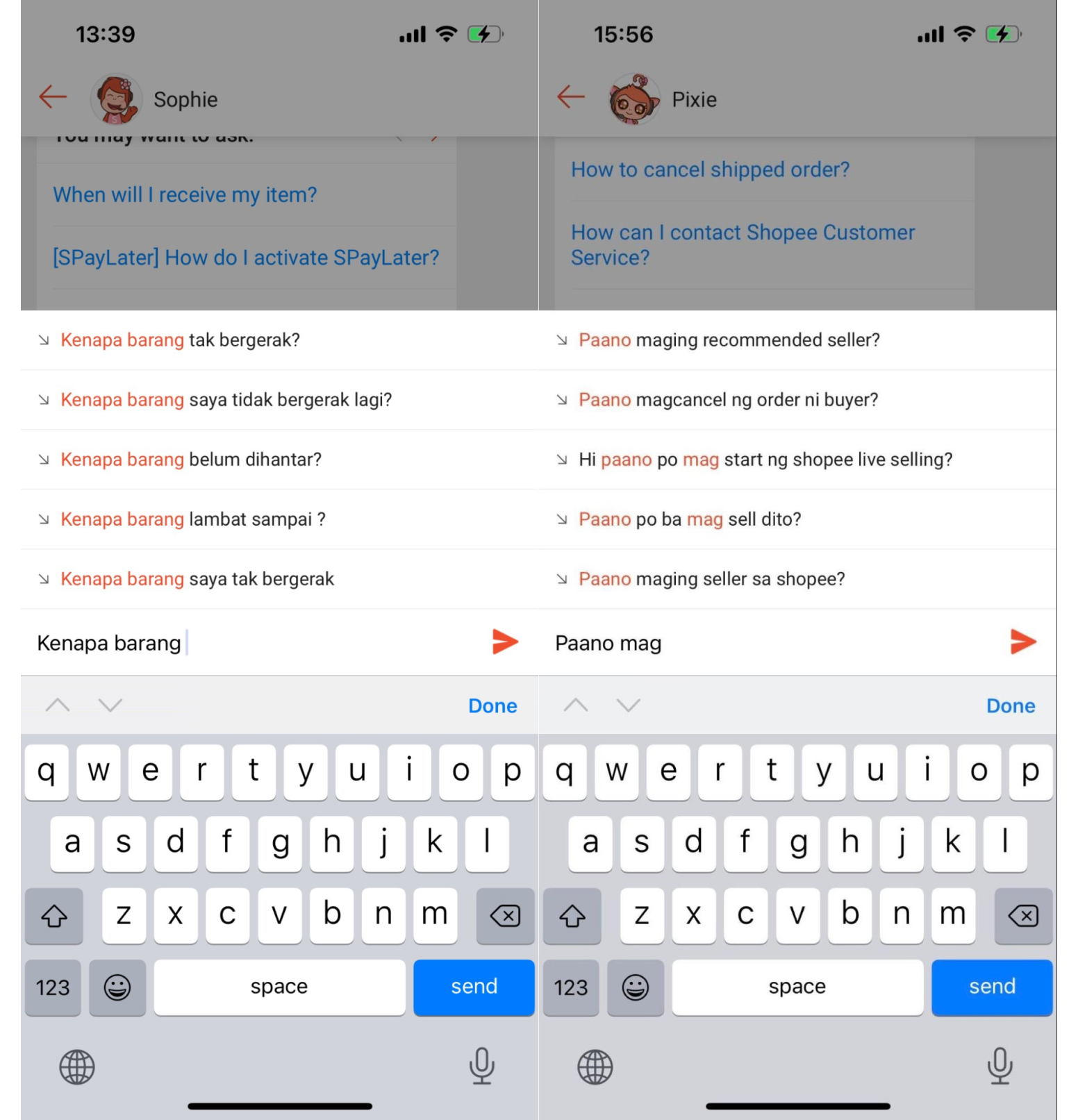
随着 Shopee 业务的扩张,消费者对客服咨询的需求不断攀升。Shopee Chatbot 团队致力于基于人工智能技术打造 Chatbot 与人工客服 Agent 的有机结合,通过 Chatbot 来解决用户日常的咨询诉求,给用户提供更好的体验,缓解和减轻人工客服的压力,也帮助公司节省大量人力资源成本。目前,我们已经在多个市场上线了 Chatbot。如上图所示,用户可以通过 Shopee App 中的 Mepage 体验我们的 Chatbot 产品。
我们也在持续不断地打磨 Shopee Chatbot 产品,增强其功能,给用户提供更好的体验,帮助用户解决购物过程中所遇到的问题。在 Shopee Chatbot 的众多功能中,下拉推荐是其中一个重要的功能。
1.2 下拉推荐
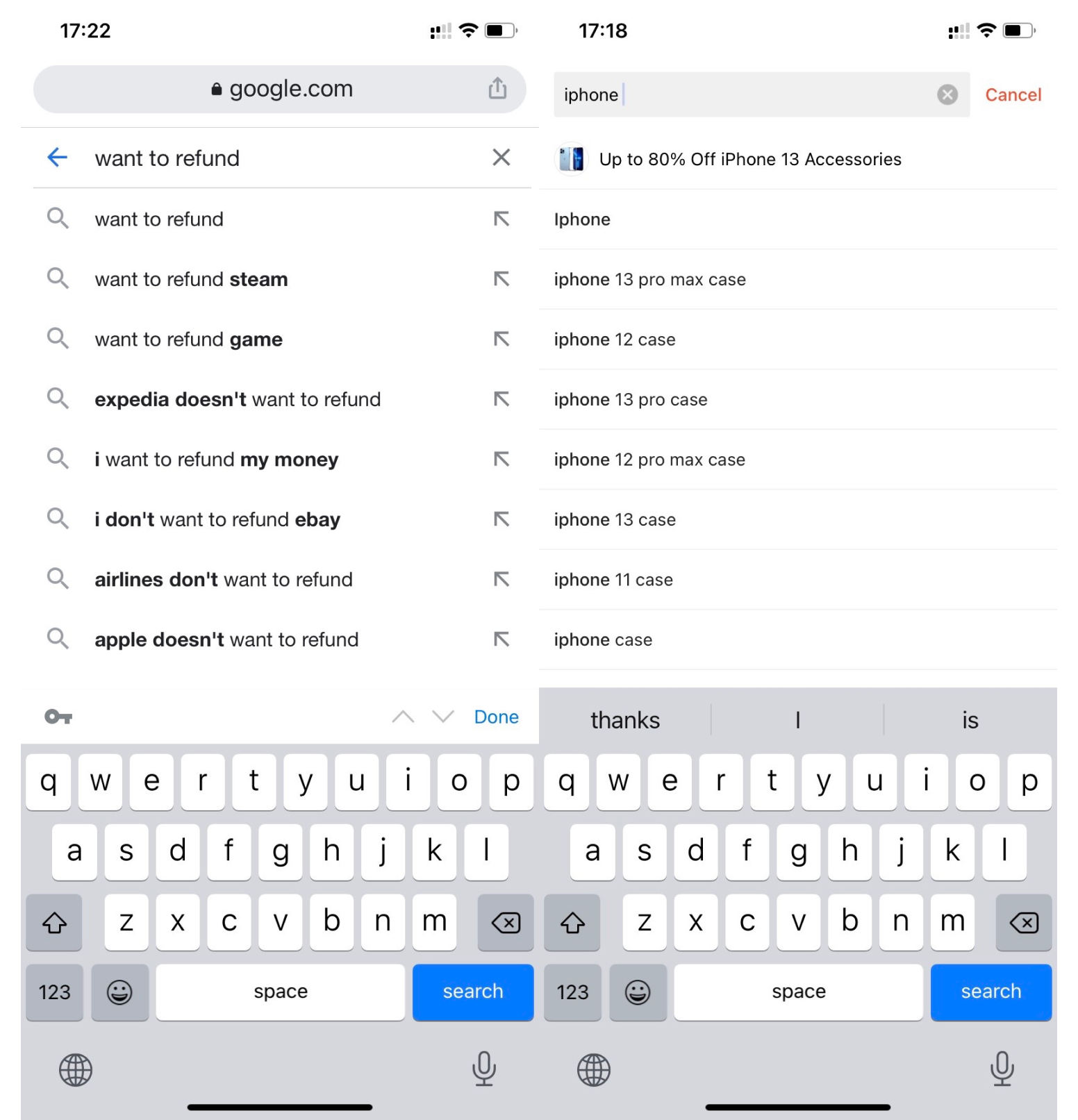
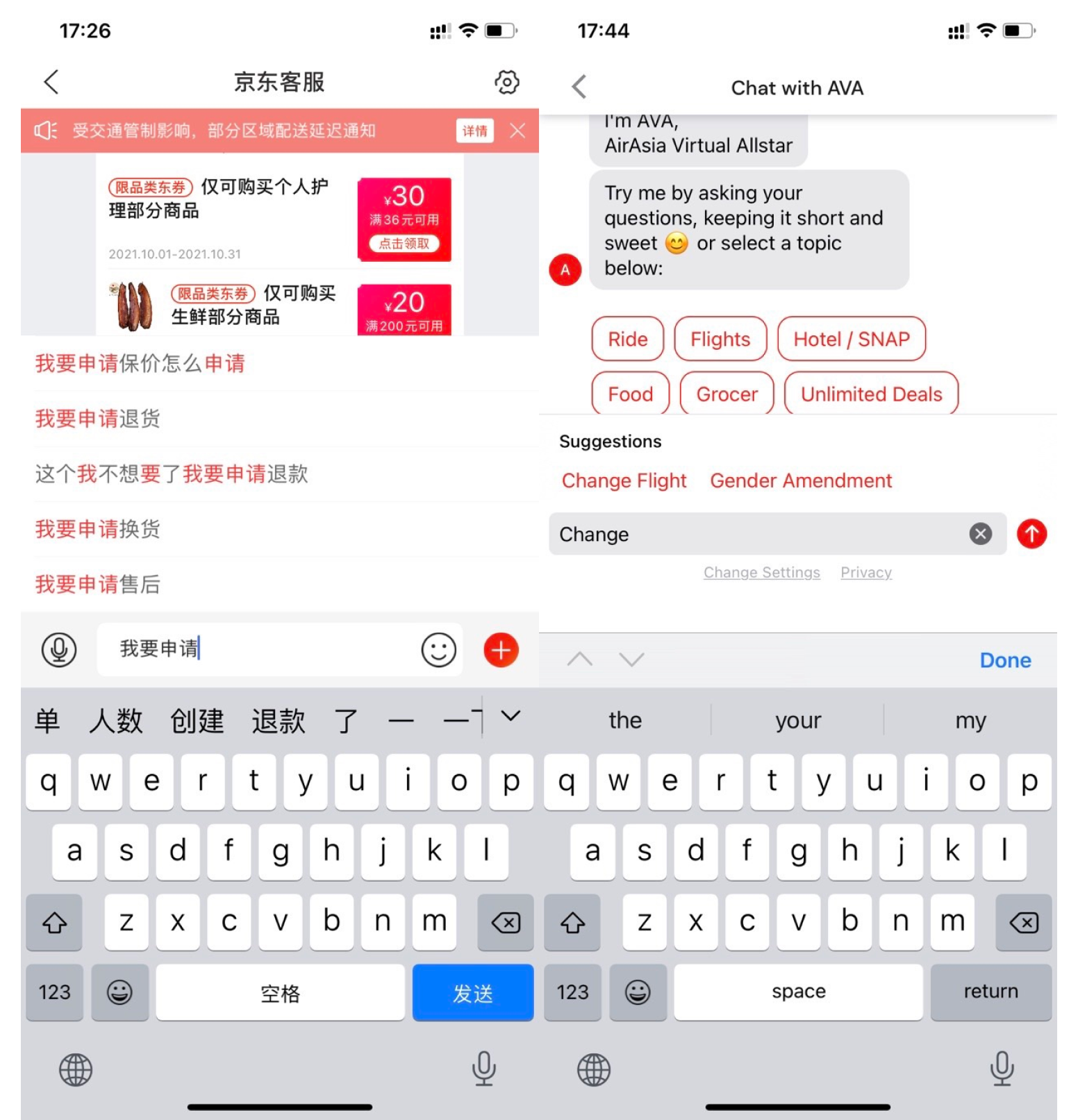
下拉推荐,又名输入建议、搜索建议、自动补全或问题推荐等,已经成为主流搜索引擎、购物 App 和 Chatbot 等众多产品里的一项必需且标配的功能。其大致功能为:在用户输入查询词的时候,显示与输入 query 语义相关的推荐 suggestion,供用户选择。通过这种方式,它可以协助用户更快地表达其想要检索的内容,进而帮助用户快速检索到所需要的内容。
在 Shopee Chatbot 中,我们也希望 Chatbot 具有下拉推荐的功能,从而能更快更好的解决用户的问题,提升用户的购物体验。
2. 整体方案
针对目前 Chatbot 的场景,为了使它具备下拉推荐的功能,我们借鉴搜索和推荐的场景,使用召回+排序的流程,如下图所示。针对用户当前的搜索输入,找到最相似和最相关的 suggesiton,作为推荐建议。为此,我们需要搭建推荐候选池、多路召回以及排序模块。
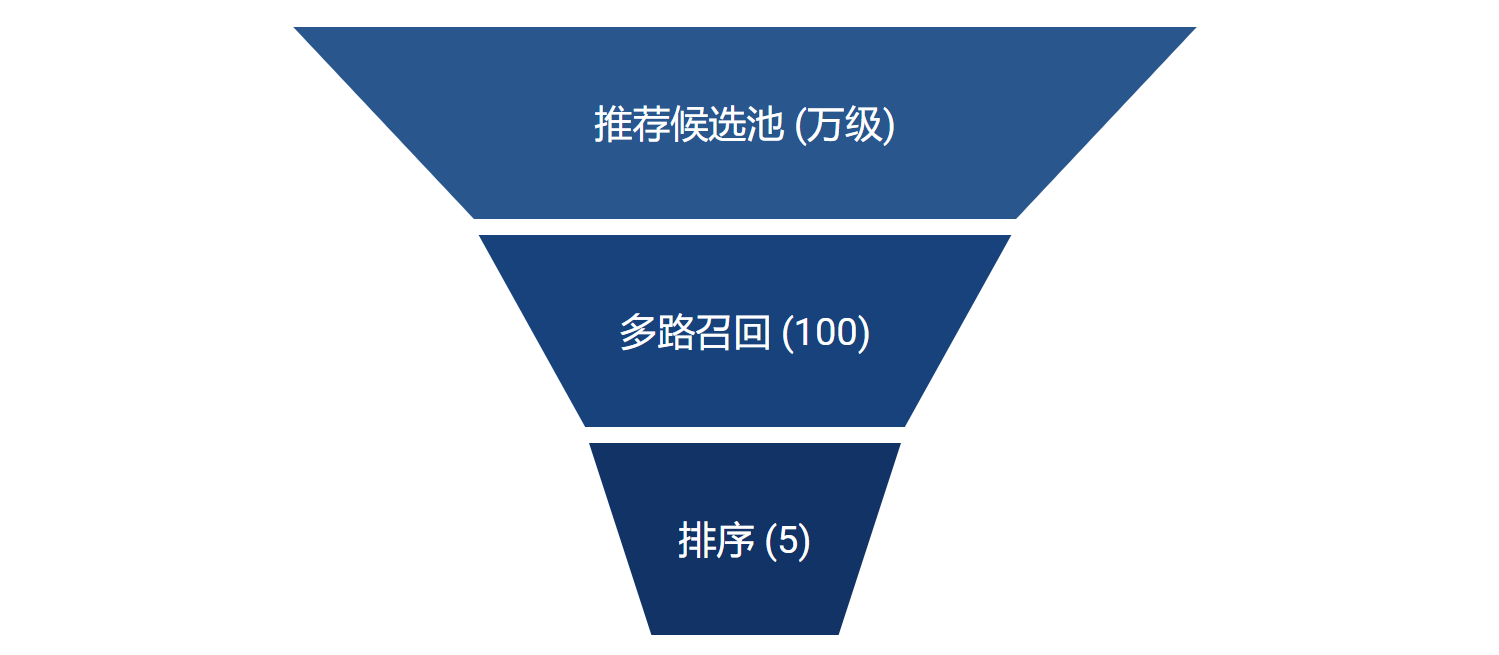
2.1 推荐候选池
2.1.1 构建流程

目前,我们构建推荐候选池的方式比较简单,包括 3 个步骤:
使用多种来源的数据,包括解决方案的标题、用于意图识别的标注数据以及大量的聊天日志;
然后进行一些预处理,例如删除太短或太长的消息,并使用编辑距离或聚类删除一些重复的 query;
最后,为了控制建议的质量,我们要求各市场当地的业务审查这些 query,或将它们改写为标准化的 query。譬如,我们会进行纠错,并删除脏字。
2.1.2 推荐样例
以下是我们推荐候选池中的一些推荐样例。对于每一个 suggestion,我们也有相应的解决方案。当用户点击该推荐 suggestion 时,我们会给用户相应的解决方案作为答案。

2.2 多路召回
对于召回,我们采用了多路召回再合并的方式,目前包括文本召回和向量召回两种方式。
2.2.1 文本召回
对于文本召回,我们采用了业界标准的方案,使用 Elasticsearch (ES) 来进行关键词匹配召回。除了基于 ES 的 BM25 分数[1] 进行排序外,我们还用解决方案的 CTR 来作为加权因子,以进一步提升召回的效果。
2.2.2 向量召回
文本召回容易理解和实现,但其效果依赖于 query 跟 suggestion 是否有匹配的关键词。为了召回和 query 用词不同但是表达语义相同的 suggestion,往往需要对 query 进行纠错、丢词、同义词替换和改写等处理,尤其是当字面完全匹配的 suggestion 不多的时候。
在我们的场景中,用户输入 query 较长,表述偏口语化,因此挖掘停词和同义词成本较高。另外,Shopee Chatbot 面向不同的地区和不同的语种,场景和数据的多样性也增加了算法工作的成本。
考虑到这点,我们采用了向量召回[2] 的方式,从大量的弱监督、用户行为日志来训练向量召回模型,用 query 向量和 suggestion 向量来衡量两者的语义相似性,以隐式的同义改写召回来作为文本召回的补充,在一定程度上缓解这种问题。
向量召回的方案对于多地区和多语言均适用,降低了适配成本。另外也能进行跨语言召回,譬如输入 query 是中文,召回英文的 suggestion。
由于目前的推荐候选池都是单一语种的,例如英文,如果用户输入中文,仅依靠文本召回,无法返回合适的推荐 suggestion 给用户。而依靠跨语言的向量召回,则也能推荐语义相关的 suggestion,如“where to use my voucher”和“哪里可以用优惠券”,具有相似的语义。
另外,对于某些多语言市场,例如 MY 和 PH,我们也只需准备一个多语言的向量召回模型,就能实现不同语言的理解和召回,而无需针对各单一语种分别训练召回模型。
为了实现向量召回,我们需要有一个文本编码器,能对文本进行编码,得到对应的向量,再进行向量召回。通常有以下两种方法:
1)基于双塔模型
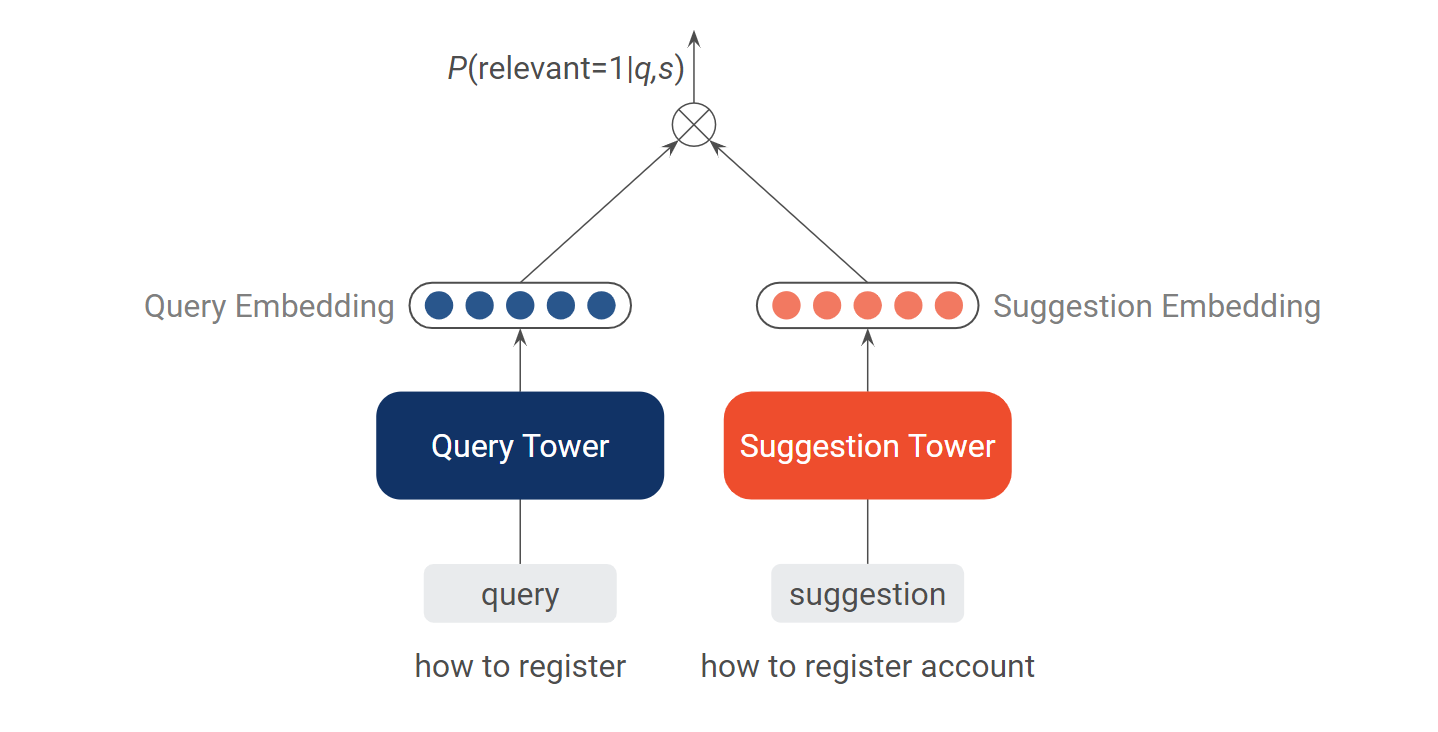
在双塔模型[2] 中,我们分别有 query 塔和 suggestion 塔分别对用户输入 query 和推荐 suggestion 进行编码,映射到稠密向量。基于 query 和 suggestion 的向量,可以计算两者的相似度,如余弦相似度。对于相关的 query 和 suggestion,我们希望两者的相似度越大,反之希望其相似度越小。因此根据该相似度与 query 和 suggestion 是否相关,可以计算损失,训练模型。
2)基于预训练语言模型
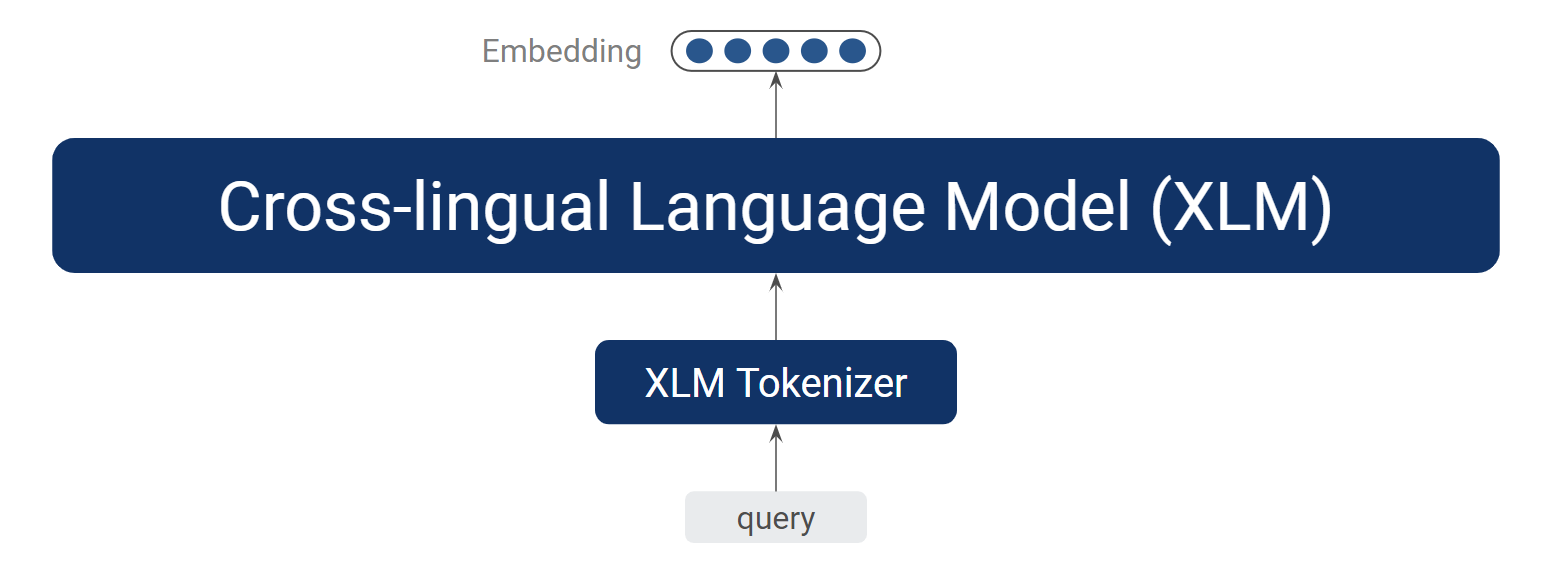
另一种方法是使用一些预训练的模型作为文本编码器,例如预训练的语言模型。该方法现在被广泛应用在诸多 NLP 场景,并且是目前许多 NLP 应用中的 state-of-the-art 方法。具体在我们的应用中,我们使用 Facebook 的跨语言预训练语言模型 XLM[3],结合对应的分词器,它可以处理 100 多种语言。
2.2.3 基于多语言和多任务预训练的向量召回
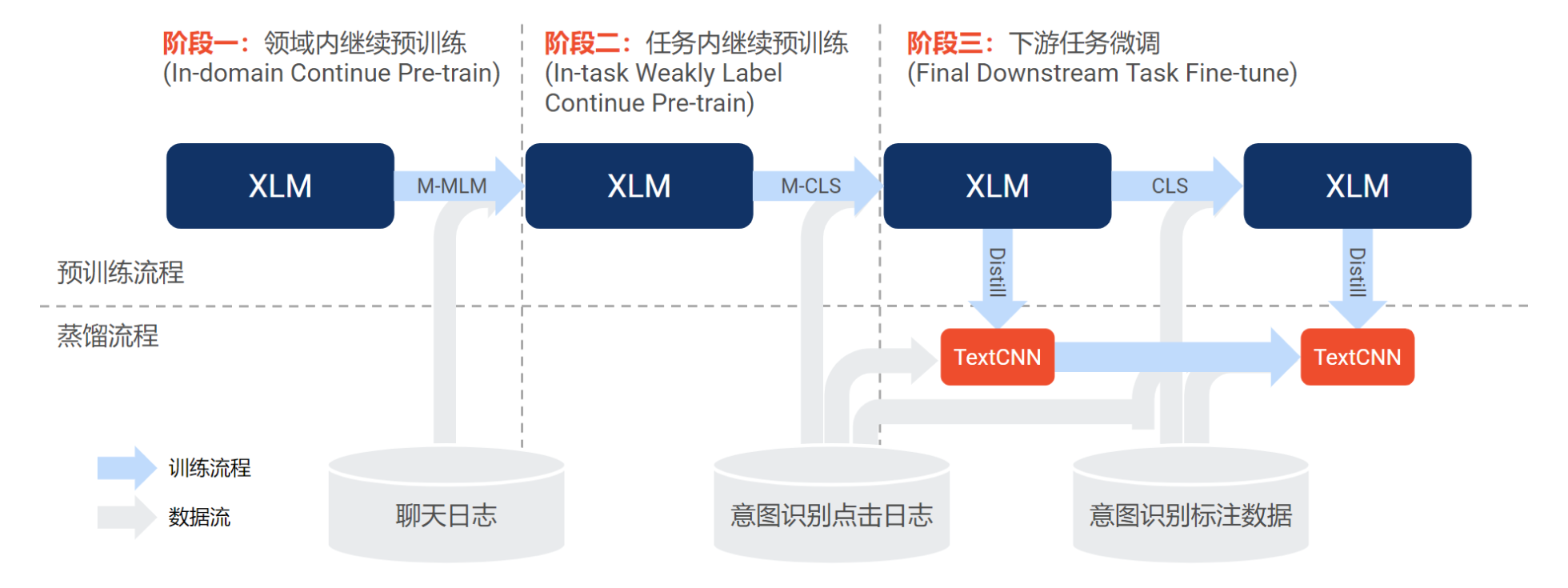
1)继续预训练(Continue Pre-train)
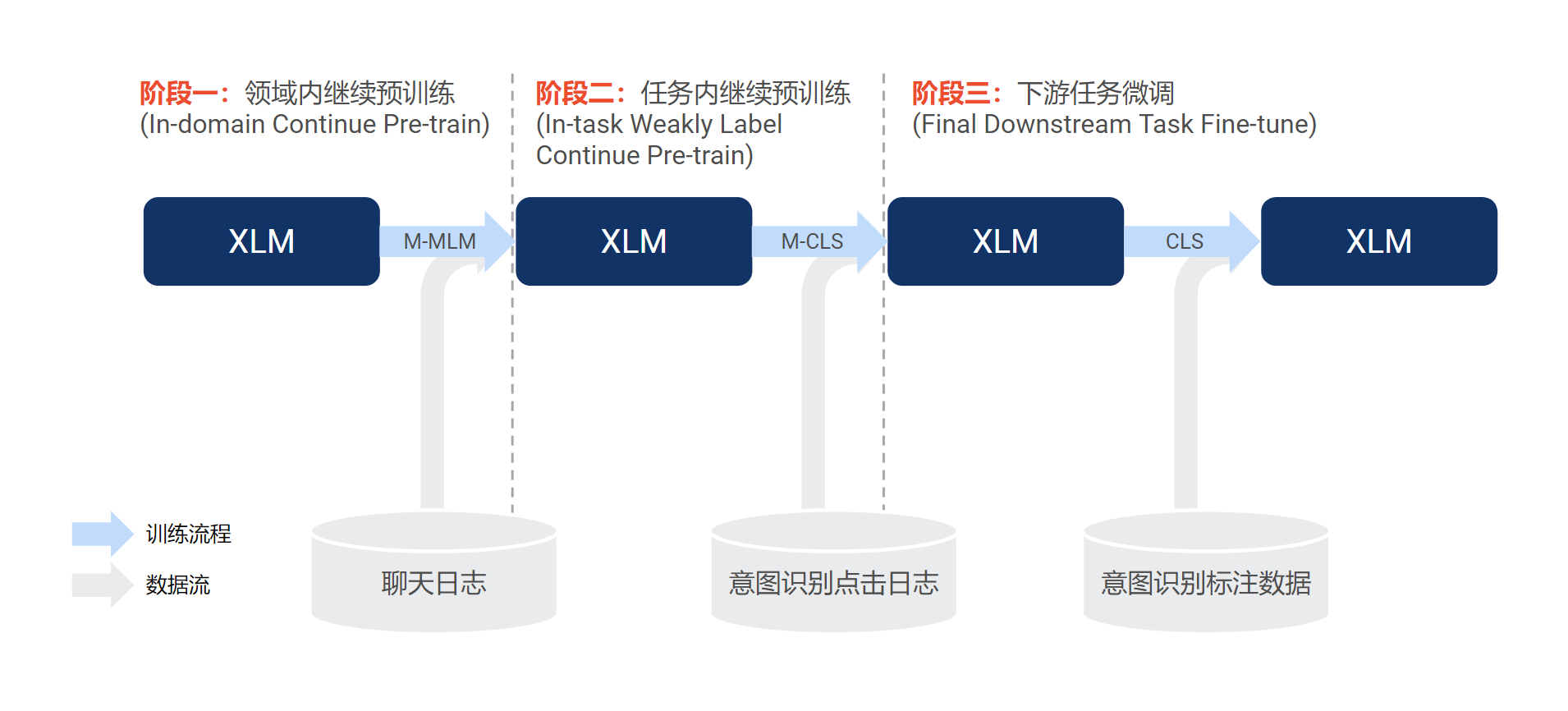
由于 Facebook 的 XLM 基于公开数据进行训练,为了使其能更好地适配我们的场景和数据,我们通过继续使用领域内和任务内的语料库进行继续预训练(continue pre-train)来提升模型性能。具体来说,参考文献[4],我们使用 3 阶段方法:
阶段一:使用来自不同市场、不同语言的大量聊天日志作为无标注数据,训练多语言的 Masked Language Modelling 任务(M-MLM)[3];
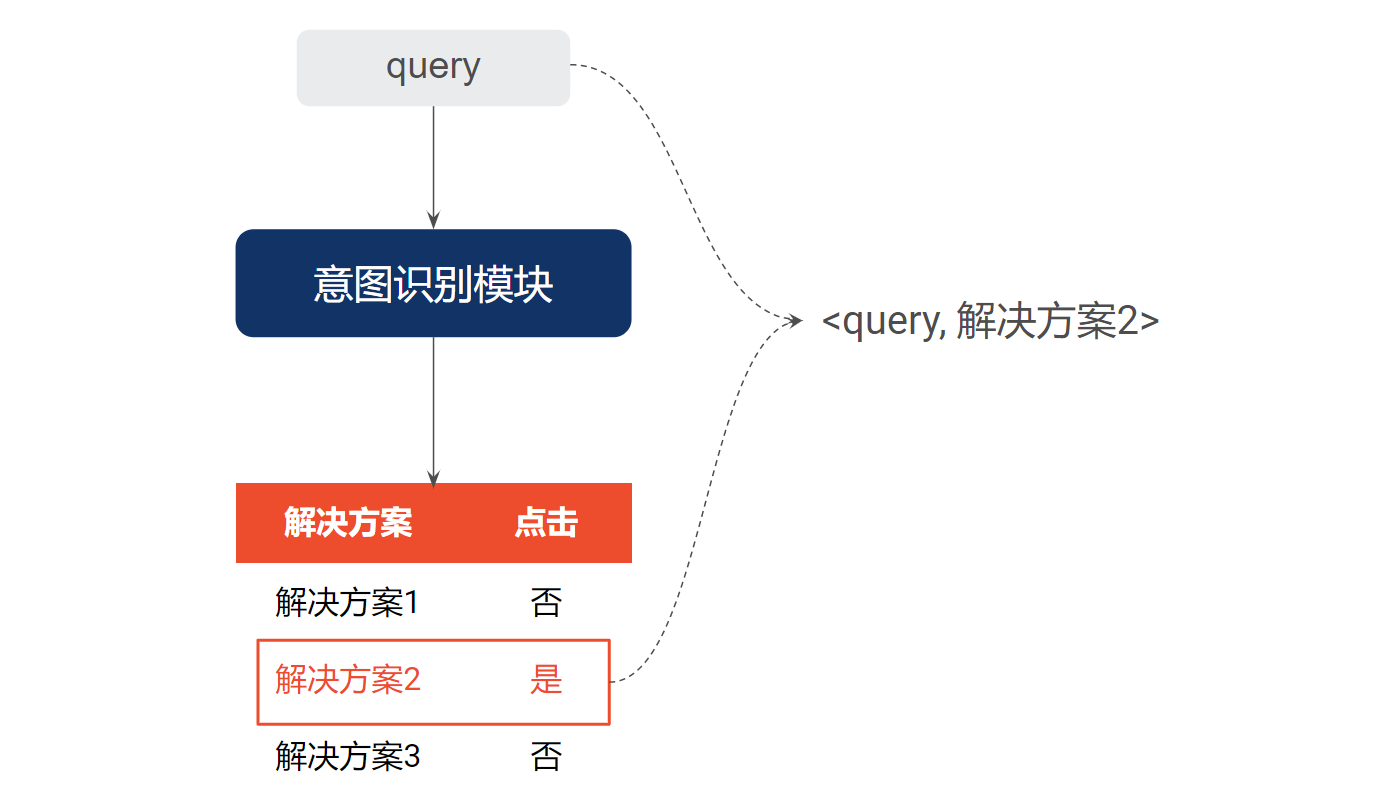
阶段二:使用来自意图识别模块的点击日志作为弱标注数据(构造方式如下图所示),训练多语言的意图分类任务(M-CLS)。跟阶段一类似,我们也采用不同市场的数据来进行多任务训练;
阶段三:使用来自意图识别模型的标注数据,使用意图分类任务(CLS)来进一步微调 XLM。对于不同市场的意图分类任务,我们分别使用相应的语料进行单独微调。
2)知识蒸馏(Knowledge Distillation)

为了使大型预训练语言模型可用于在线服务,我们进一步对其进行知识蒸馏[5],将大模型(teacher)变成更小的模型(student),如 TextCNN,示意图如上图所示。
在实践中,我们使用了以下 3 项技术来提升蒸馏的效果:
引入 noise:参考文献[6],我们在蒸馏的过程中,引入 noise 来提升模型学习特征表示的鲁棒性,同时也提升样本的利用效率,使得其能覆盖更全面的数据输入分布;
利用大量的半监督数据:参考文献[6],我们利用聊天记录的无标注数据以及点击日志的弱标注数据等大量的半监督数据,充分学习 teacher 大模型 XLM 在更全面的数据输入分布上的特征表示分布;
2 阶段蒸馏:为了最大限度保留和学习 teacher 大模型 XLM 的知识,我们也采用了和领域预训练类似的 2 阶段的方法进行蒸馏,分别从领域预训练的第二阶段和第三阶段的所得到的 teacher 大模型 XLM 依次蒸馏。
下图所示为完整的继续预训练和蒸馏过程。
2.2.4 实验效果
1)实验一:意图识别任务
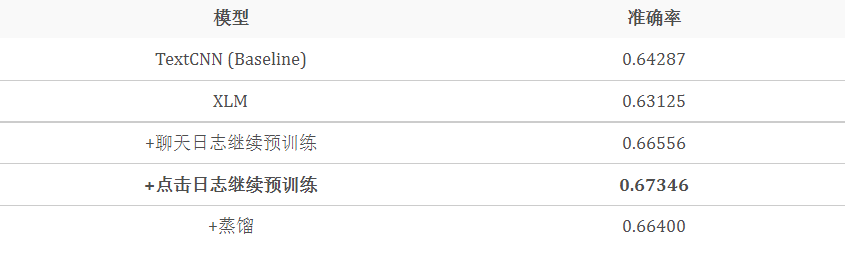
由于我们的 XLM 模型是基于意图识别的数据和任务进行训练的,我们首先在意图识别的任务中对比不同方法的效果。其中,TextCNN (Baseline) 表示采用 FastText 预训练词向量和 TextCNN 的基准模型,XLM 为使用公开的 XLM 进行微调得到的意图识别模型。
如上表所示,基于领域内和任务内数据进行继续预训练,可以提升预训练模型的效果 3%~4%,而经过蒸馏之后,模型效果只有 1% 的下降。
2)实验二:下拉推荐任务

接着,在下拉推荐中,进一步验证预训练模型应用于向量召回的效果。基于离线数据集,我们比较了文本召回和向量召回的效果。对于向量召回,我们分别使用了基于公开的 SentBERT[7] 的文本编码器以及对 teacher 大模型 XLM 蒸馏得到的 TextCNN。
如上表所示,向量召回整体效果比文本召回要好,而且使用领域预训练和蒸馏的 TextCNN,相比 SentBERT 有 4% 的提升。
3)蒸馏前后对比

由实验一可以看到,XLM 模型经过蒸馏之后,效果只有 1% 的下降。上表进一步了展示蒸馏前后的模型大小以及计算时间。可以看到,两者分别有较大幅度的下降,尤其是计算时间的缩减,使得蒸馏之后的 TextCNN 模型可以应用于在线推理。
2.3 排序模块
2.3.1 问题背景
基于多路召回,我们能对召回的 suggestion 有一个初步的排序。在此基础上,一般也会需要一个排序的环节,原因如下:
召回分数,例如 BM25 或者向量相似度,不足以获得更好的性能;
除了输入 query 和推荐 suggestion 之外,我们还希望包含其他特征(例如,用户特征)以获得更好的排序效果;
我们还想针对多种目标进行联合优化,例如点击率(CTR)或解决率(类似于转化率 CVR)。
2.3.2 基于 DeepFM 的 CTR 预估模型
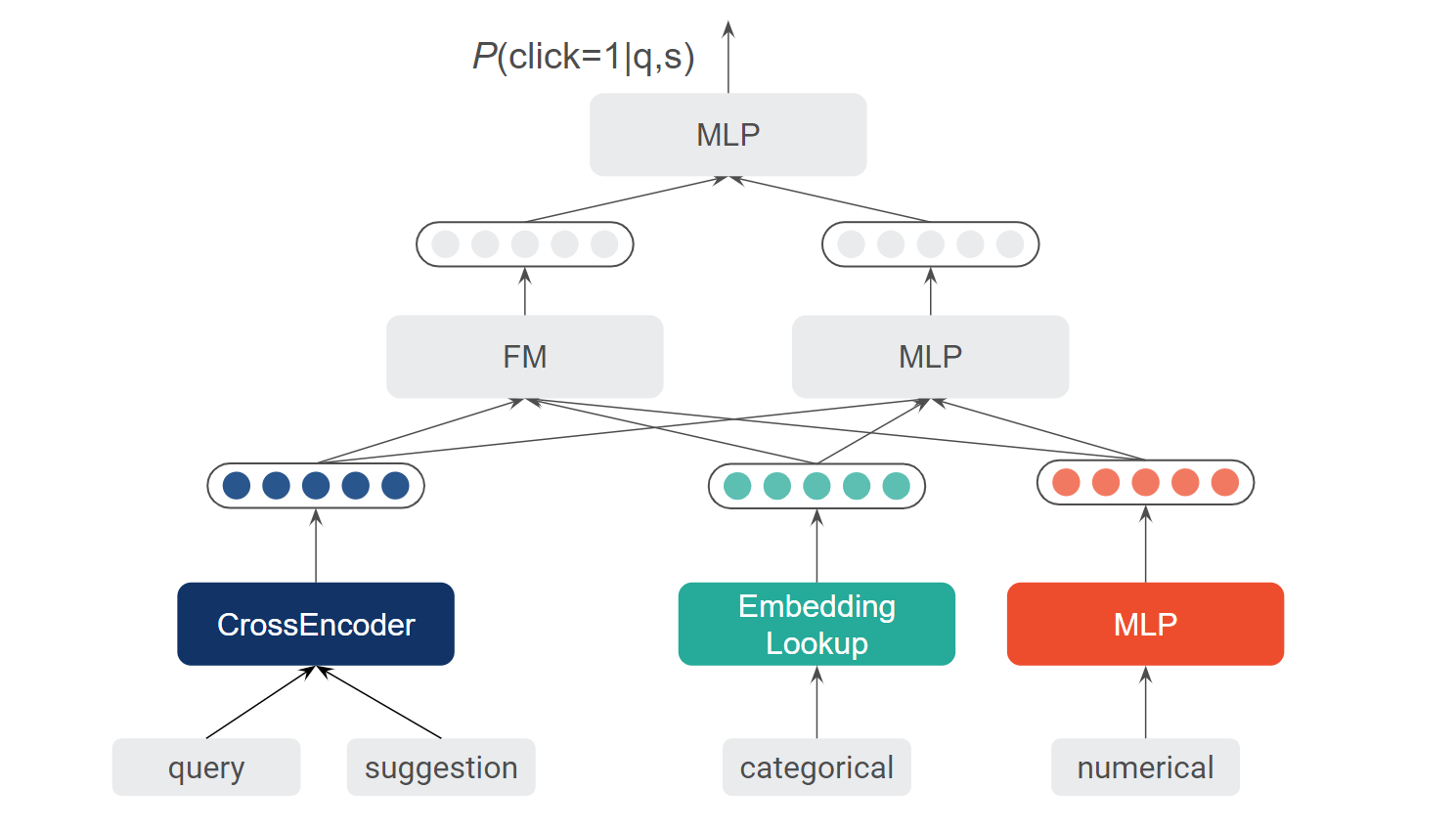
基于下拉推荐积累的曝光和点击数据,我们构建了 CTR 预估模型用于对下拉推荐进行排序。具体而言,我们采用了被广泛使用的 DeepFM[8]。
在上图底部所示的输入层中,我们有各种类型的特征,包括输入 query 和推荐 suggestion 等文本特征,解决方案的 id 等类别型特征,以及解决方案的一些统计信息等数值型特征。在中间层,我们为每种类型的输入设计了不同的处理单元,如针对文本输入的 CrossEncoder(例如 ALBERT[9]、RE2[10] 和 ESIM[11] 等)。
2.3.3 基于 ESMM 的多目标排序模型
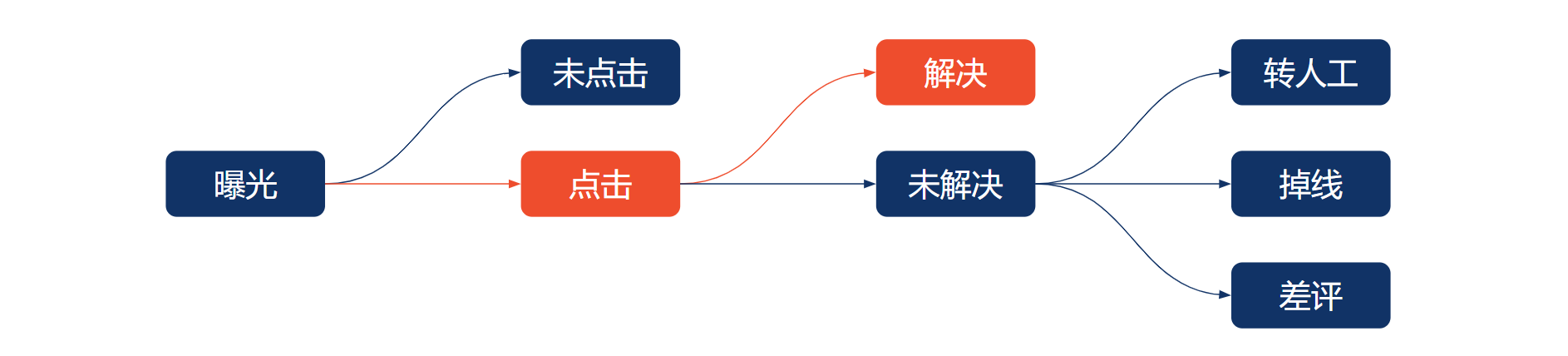
同时,我们也进行了多目标的优化尝试。具体到 Chatbot 的场景,我们希望用户能点击 suggestion,也希望该 suggestion 所对应的解决方案能够解决用户的问题。对于是否解决用户的问题,我们的定义是,如果该用户没有转人工 & 没有掉线 & 没有差评,就认为是解决,用户路径如下图所示。
借鉴搜索推荐广告场景,可以将解决率预估类比成转化率预估(CVR)问题。因此,我们尝试了基于 DeepFM 的多目标优化模型 ESMM[12],并进一步探索采用 MMoE[14] 和注意力机制的 ESMM 模型,两个模型结构分别如下图所示。
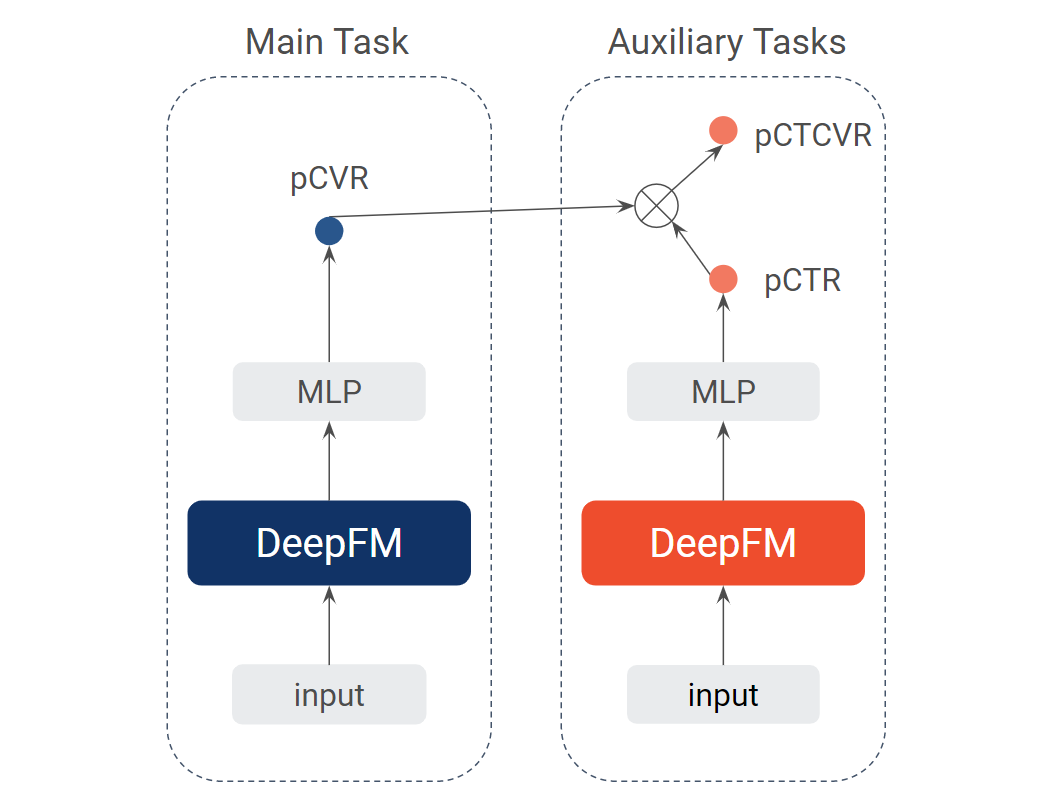
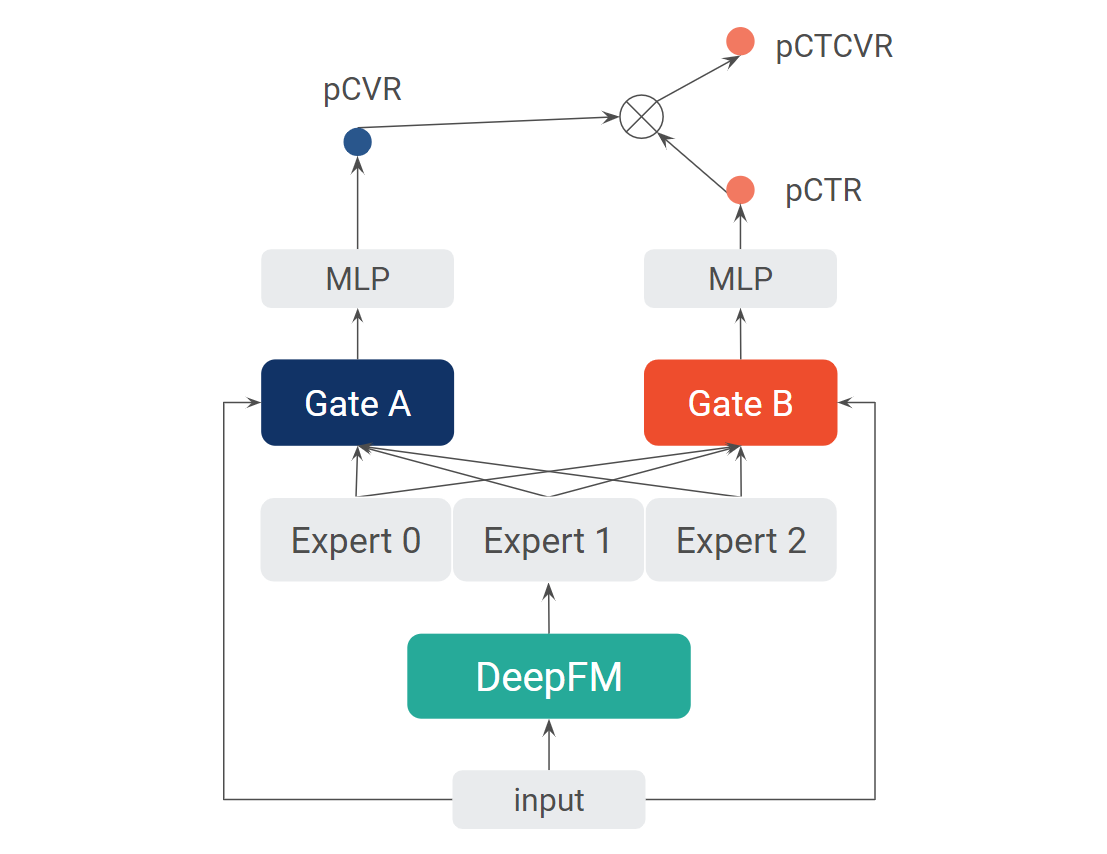
上图中的概率存在以下关系:
其中, 代表输入 query, 代表推荐 suggestion,并且
最终模型的损失包含 CTR 和 CTCVR 两个任务在全体数据样本上的损失。
2.3.4 实验效果
1)实验一:CTR 预估
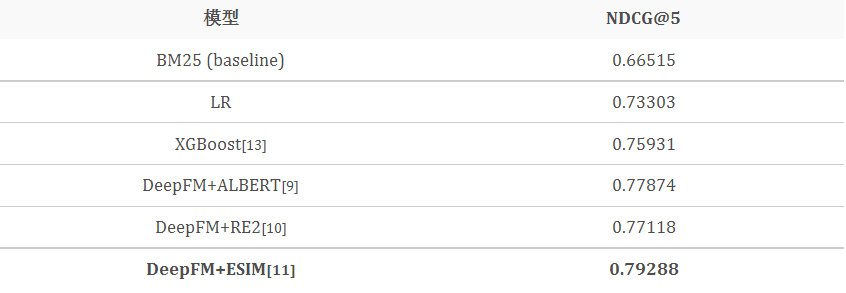
基于下拉推荐积累的曝光和点击数据,我们比较了不同 CTR 预估模型的性能。如上表所示,带有不同 CrossEncoder 的 DeepFM 具有最优的效果。
2)实验二:多目标优化
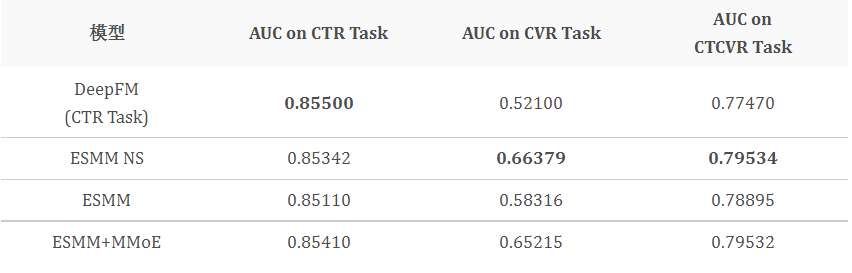
基于下拉推荐积累的曝光、点击以及解决数据,我们比较了不同多目标排序模型的效果,其中 ESMM 为共享 DeepFM 的模型(Shared-Bottom),ESMM NS 为不共享 DeepFM 的模型。如上表所示,基于 ESMM 的多目标模型相比纯 CTR 模型,在 CTR 和 CVR(在我们的场景中,对应解决率)两个任务中,均有较好的效果。
我们还可以看到,ESMM NS 的效果比 ESMM 要好,这个跟 ESMM 原论文[12] 的结果刚好相反。
对于这个结果,我们的猜想是:在我们的场景中,解决率一般都比较高(如 70% 以上),因此对于解决率预估任务,其样本数量不会像 CVR 任务那么稀疏,在这种情况下,Shared-Bottom 模型不一定能带来效果提升。反而各任务使用不同的 DeepFM,可以学习不同任务之间不同的特性,取得更好的效果。但是 ESMM NS 的内存占用和计算时间也比 ESMM 要高。
我们进一步尝试在 ESMM 的框架中融入 MMoE 和注意力机制,学习任务之间的特异性,性能有进一步提升,而其相比 ESMM NS,在 CVR 任务上面只有 1% 的降低。由于 ESMM+MMoE 具有共享的 DeepFM,因此其在内存占用/计算时间与效果之间,取得了较好的平衡。
3. 系统实现
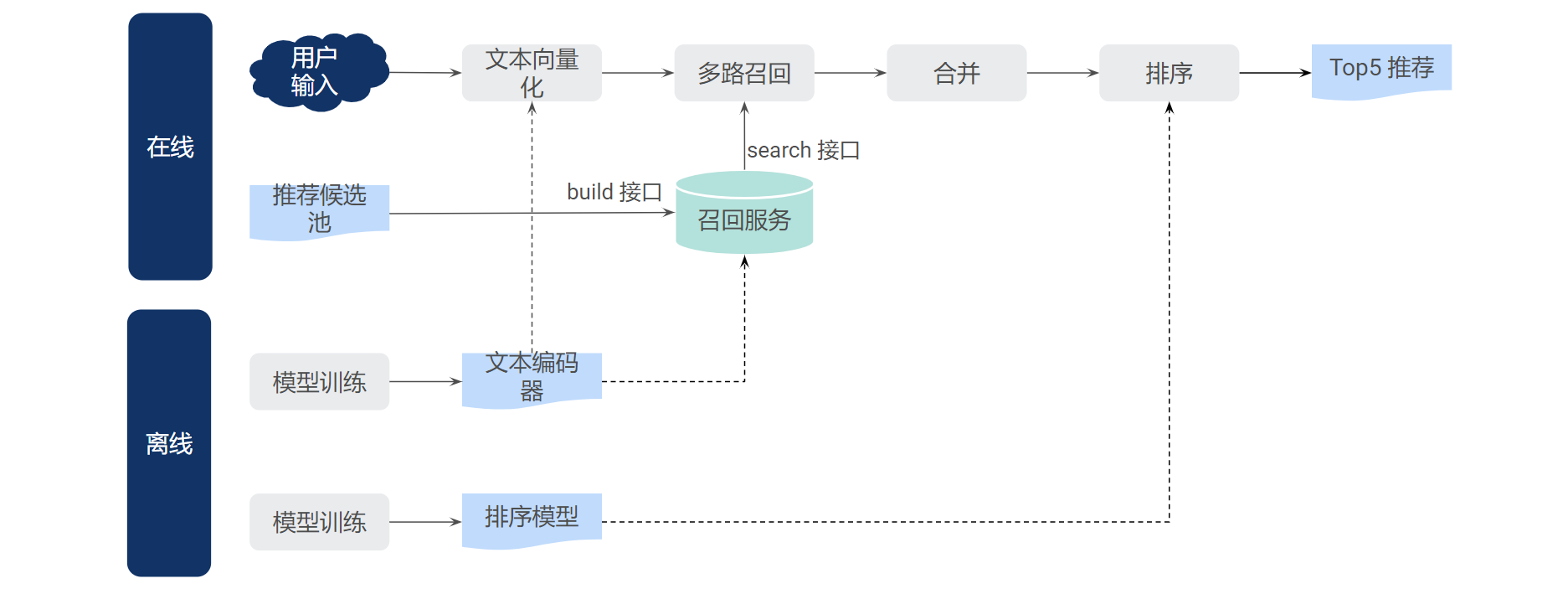
在第 2 章中,我们介绍了 Shopee Chatbot 下拉推荐的整体方案。在本章中,我们再介绍下整体的系统架构(如上图所示),包括离线部分和在线部分。
3.1 离线部分
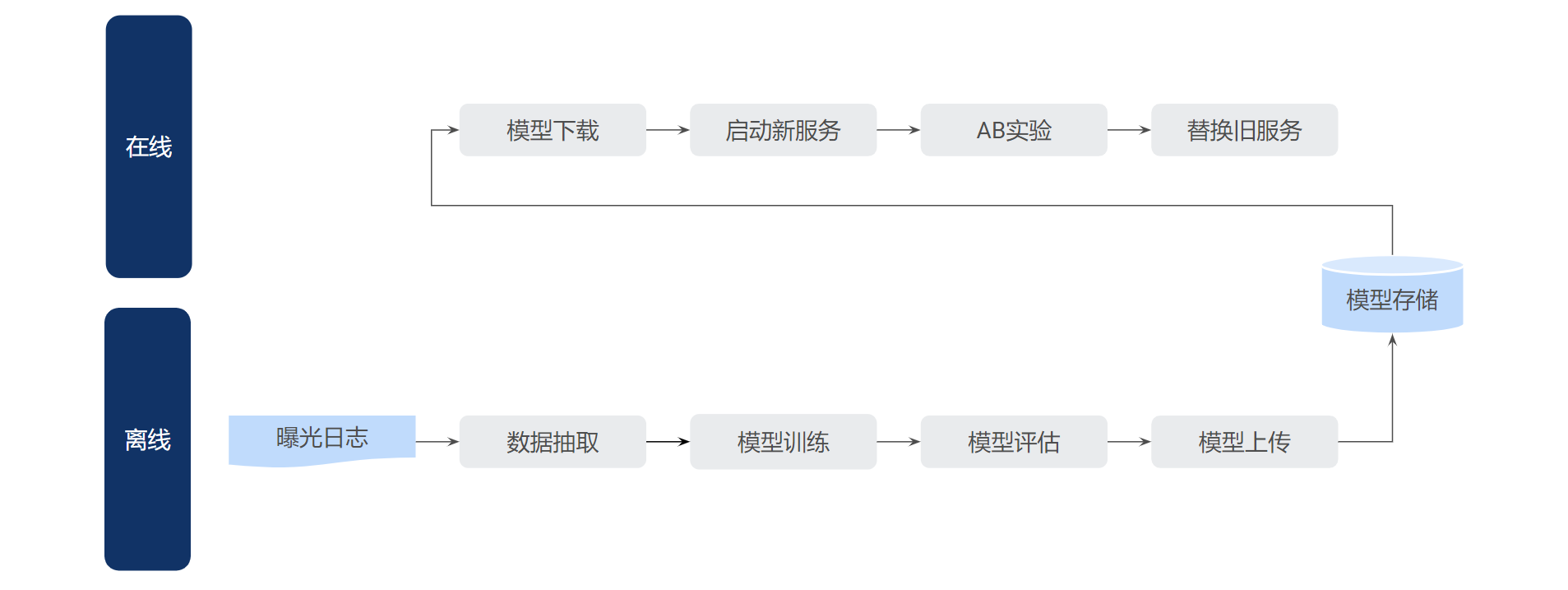
3.1.1 模型训练
针对其中的两个核心模型,即向量召回中的文本编码器以及排序模型,我们会使用曝光和点击日志,定期训练和更新模型,以使模型能保持较好的效果。其流程如下图所示。
3.2 在线部分
3.2.1 模型推理
模型推理部分就是把多个环节串接起来。对于用户的输入 query,先调用文本编码器得到其文本向量,再并行请求文本召回和向量召回,然后对召回结果进行合并,最后调用排序模型,输出排序的 Top5 推荐作为 suggestion 展示给用户。
为了加快模型推理速度,我们使用 ONNX 来部署文本编码器以及排序模型(均使用 PyTorch 训练)。同时,使用 Redis 来缓存高频输入 query 的多路召回的结果,减少重复计算和召回请求。由于后续排序模型会使用用户和场景等的特征,我们目前并不直接缓存最终的 Top5 推荐结果,而由排序模型动态决定最终排序输出。
3.2.2 召回服务
在获得推荐候选池后,或者推荐候选池发生更新后,我们基于 Elasticsearch 构建文本召回服务。
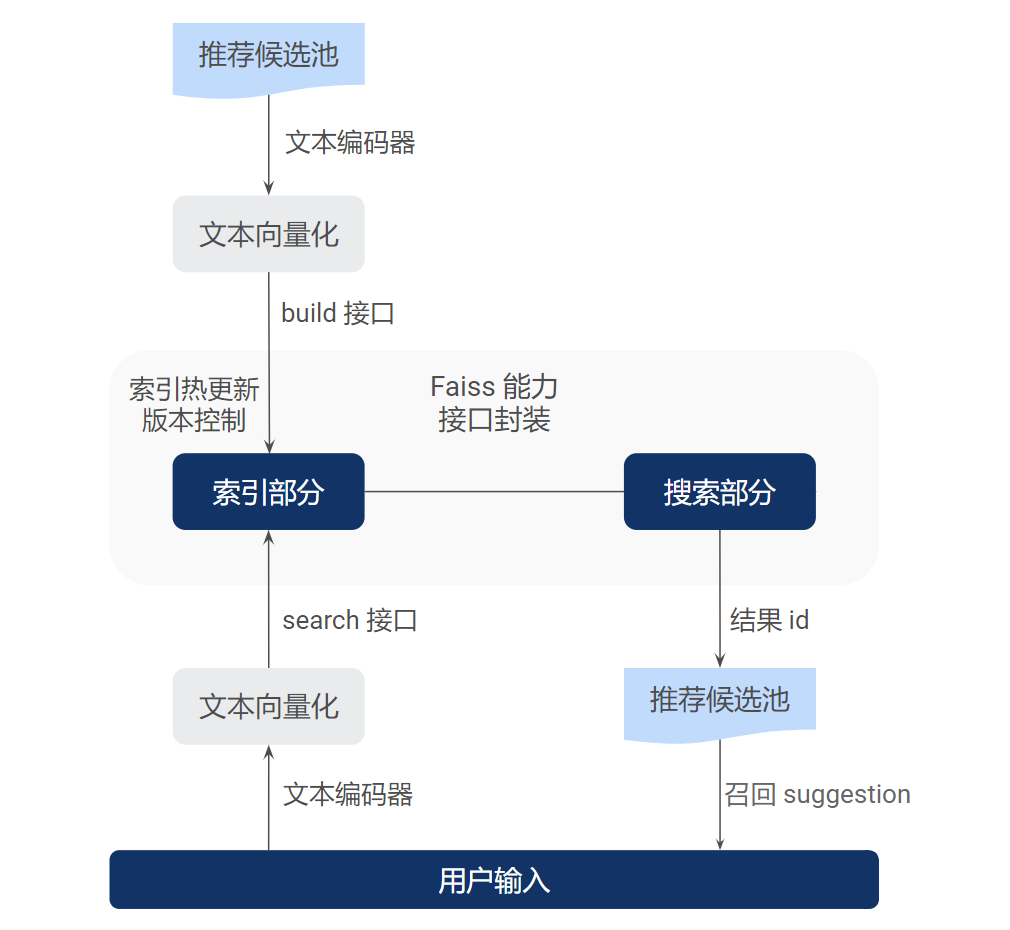
对于向量召回,我们使用 Shopee Chatbot 工程团队基于 Faiss 搭建的向量召回服务,流程如下图所示。
由于目前下拉推荐的候选池依赖于人工标注产生,数量还比较小,在万级左右,因此我们选择了 HNSW 的方式[15]。对于 5W 左右的 suggestion,512 维度向量,整体索引占内存大小为 800M 左右。
同时,我们对比了 IndexIVFFlat 和 HNSW 两种索引的在线检索效果,HNSW 在 CPU 资源消耗更低的情况下,能够提供更快的检索效果,满足下拉推荐在线服务的需求。
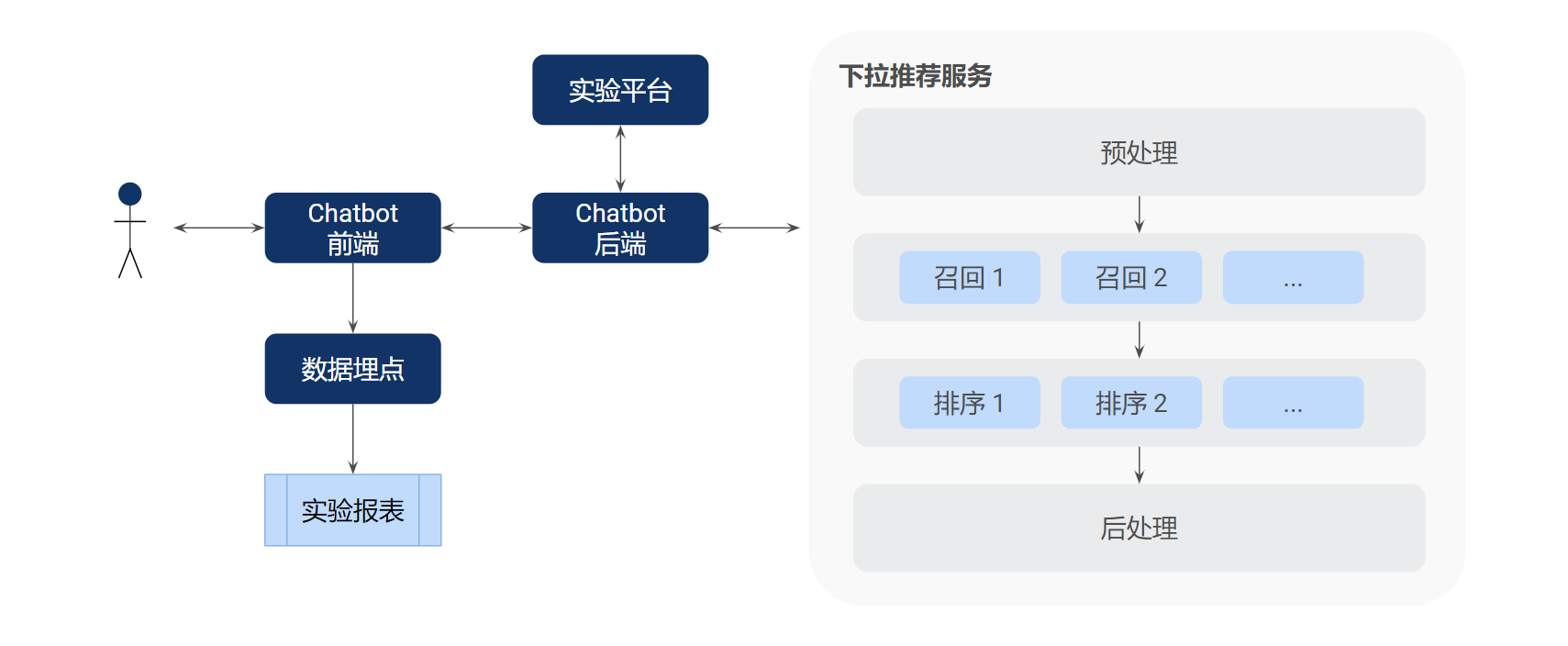
3.2.3 模型实验
为了方便 AB 实验,我们在设计和实现该下拉推荐系统的时候,使得其内部可以轻松组装不同的模块来构建可用的在线服务,譬如组合不同的召回和排序模型。此外,结合日志数据和实验报表,我们可以进一步分析实验效果。
4. 业务效果
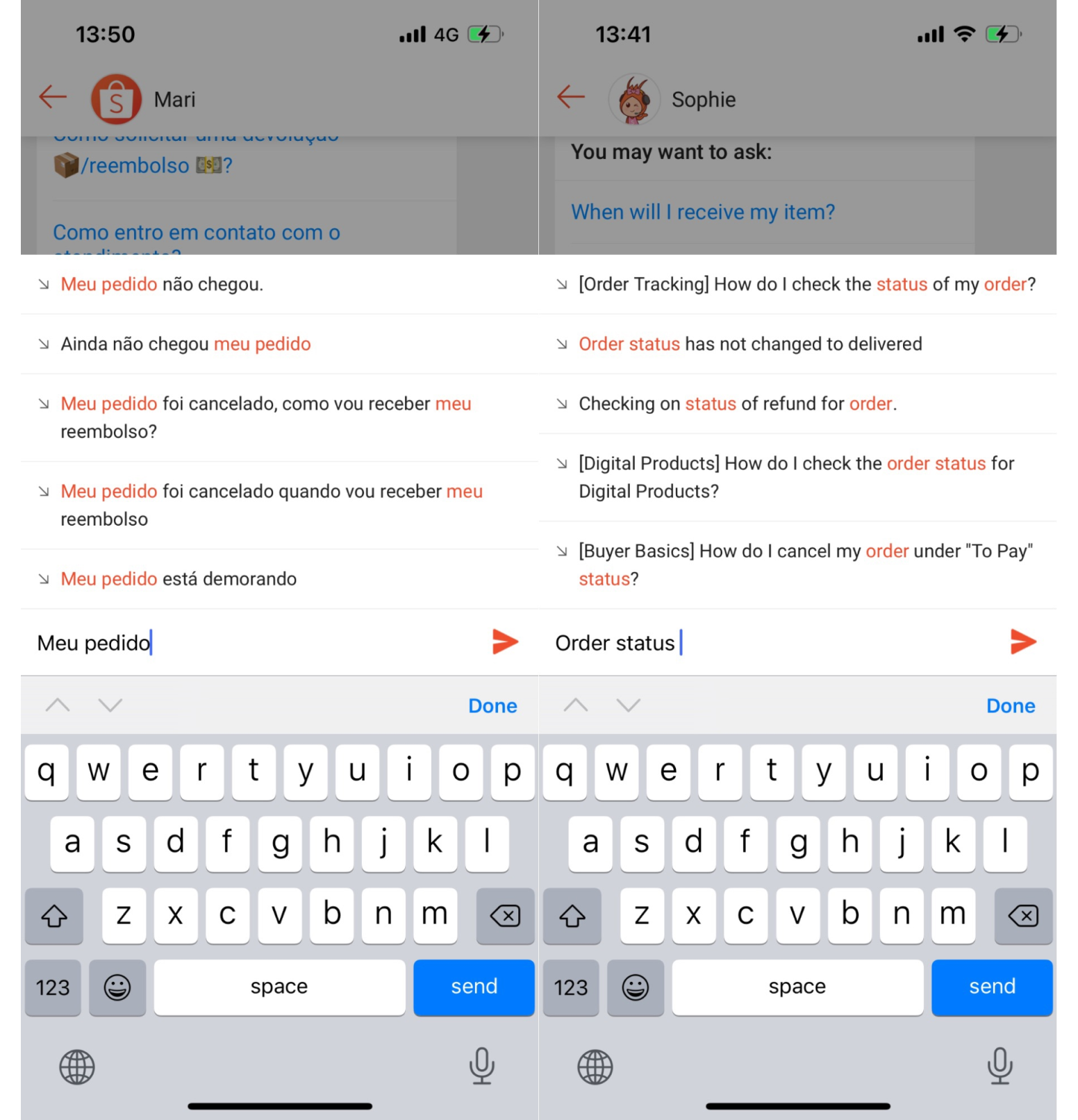
经过业务、产品、工程和算法等多个团队的通力合作,我们于 2021 年 6 月首次上线了下拉推荐功能,并于 2021 年 9 月推广到目前 Shopee Chatbot 所覆盖的所有市场上,并且带来了不错的业务成果。截至目前,我们大概有 3 个主要的版本,效果分别如下:
功能上线:在 Shopee Chatbot 覆盖的所有市场上线,整体解决率提升 1%;
召回优化:上线基于文本召回和向量召回的多路召回,线上 CTR 提升 2%;
排序优化:上线基于 LR 和 DeepFM+ESIM 的 CTR 预估模型,线上 CTR 分别提升 2% 和 6%。
5. 未来展望
经过一段时间的优化,Shopee Chatbot 下拉推荐取得了初步的成果。未来,我们希望可以从以下几方面来进一步提升其效果,以帮助用户能更好地使用 Chatbot 产品。
1)数据方面
扩大推荐池的数量,覆盖更多的用户问法;
提高推荐池的质量,提供更好的用户体验。
2)召回方面
利用下拉推荐本身积累的曝光和点击数据优化目前向量召回模型;
探索多语言召回,解决多语言场景下的下拉推荐问题[16]。
3)排序方面
引入更多的用户和场景特征,提升排序效果,探索个性化用户推荐;
评估多目标排序模型上线效果,同时也尝试其他的多任务和多目标优化方法[17]。
4)产品方面
引入探索和利用机制,解决知识点冷启动问题,持续优化效果;
探索新的产品形态,如自动补全机制等。
6. 参考文献
[1] https://en.wikipedia.org/wiki/Okapi_BM25
[2] Embedding-based Retrieval in Facebook Search
[3] Unsupervised Cross-lingual Representation Learning at Scale
[4] Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
[5] Distilling the Knowledge in a Neural Network
[6] Self-training with Noisy Student improves ImageNet classification
[7] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
[8] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
[9] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
[10] Simple and Effective Text Matching with Richer Alignment Features
[11] Enhanced LSTM for Natural Language Inference
[12] Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
[13] XGBoost: A Scalable Tree Boosting System
[14] Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
[15] https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
[16] Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
本文作者
Qinxing、Yihong、Yiming、Chenglong,来自 Shopee Chatbot 团队。
致谢
Lennard、Hengjie,来自 Shopee Chatbot 团队。


Shopee官方技术号 2020.11.30 加入
如何在海外多元、复杂场景下实践创新探索,解决技术难题?Shopee技术团队将与你一起探讨前沿技术思考与应用。









评论