我们前面已经说了,GPDB 是一个列式数据库,数据库都有什么特性呢?都能做什么呢?熟悉 MySQL,Oracle 的同学可能就比较清楚关系型数据库的管理,下面我们就来说下 GPDB 的一些管理和常用操作。
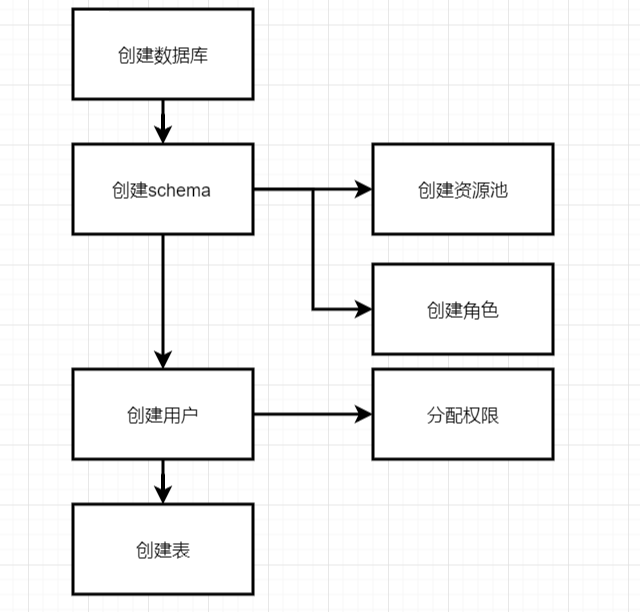
数据库常用操作分为:创建数据库、创建 schema、创建资源池、创建角色、创建用户、创建表。下面我们一一来说下 GPDB 这些常用操作,和关系型数据库 MYSQL 有什么不同呢?
创建数据库
gp_sydb=# CREATE DATABASE GPTEST;CREATE DATABASE
删除数据库
gp_sydb=# DROP DATABASE GPTEST;DROP DATABASE
复制代码
你也可以通过 createdb 创建数据库
[gpadmin@mpp01 ~]$ createdb -h mpp01 -p 5432 GPTEST
复制代码
查看创建的数据库:
gp_sydb=# \l List of databases Name | Owner | Encoding | Access privileges -----------+---------+----------+--------------------- GPTEST | gpadmin | UTF8 | gp_sydb | gpadmin | UTF8 | postgres | gpadmin | UTF8 | template0 | gpadmin | UTF8 | =c/gpadmin : gpadmin=CTc/gpadmin template1 | gpadmin | UTF8 | =c/gpadmin : gpadmin=CTc/gpadmin(5 rows)
复制代码
创建 schema
创建 schema
GPTEST=# CREATE SCHEMA bdp;CREATE SCHEMA
复制代码
查看 schema
GPTEST=# \dn List of schemas Name | Owner --------------------+--------- bdp | gpadmin gp_toolkit | gpadmin information_schema | gpadmin pg_aoseg | gpadmin pg_bitmapindex | gpadmin pg_catalog | gpadmin pg_toast | gpadmin public | gpadmin(8 rows)
复制代码
查看当前的 schema
GPTEST=# SELECT current_schema(); current_schema ---------------- public(1 row)
复制代码
可以看到当前 schema 是 public,这是创建用户的时候,我们没有给它分配 schema,那就是用默认的 schema public。把新建的 schema 赋给数据库 gptest
gptest=# \dn List of schemas Name | Owner --------------------+--------- bdp | gpadmin gp_toolkit | gpadmin information_schema | gpadmin pg_aoseg | gpadmin pg_bitmapindex | gpadmin pg_catalog | gpadmin pg_toast | gpadmin public | gpadmin(8 rows)
gptest=# ALTER DATABASE GPTEST SET search_path TO bdp, public, pg_catalog;ALTER DATABASEgptest=# SELECT current_schema(); current_schema ---------------- bdp(1 row)
复制代码
可以看到赋了新的 schema。3. 创建角色
创建角色,如果有很多用户对于一批表都有一样的权限,这时候可以创建一个角色,把这些权限先赋给角色,然后把角色赋权给各个用户。
gptest=# create role selectbdp;CREATE ROLEgptest=# \du List of roles Role name | Attributes | Member of -----------+---------------------------------------------------------------------------------------------------------------------------------+----------- bdp01 | | {} gpadmin | Superuser, Create role, Create DB, Ext gpfdist Table, Wri Ext gpfdist Table, Ext http Table, Ext hdfs Table, Wri Ext hdfs Table | {} selectbdp | Cannot login | {}
gptest=#
复制代码
可以看到角色已经创建成功。赋权角色。
gptest=# grant selectbdp to gpadmin; GRANT ROLE
复制代码
角色其实就是一个用户组。4. 创建用户:
gptest=# create user bdp01 WITH PASSWORD 'passwd123';NOTICE: resource queue required -- using default resource queue "pg_default"CREATE ROLEgptest=#
复制代码
使用用户登录:
psql -Ubdp01 -d gptest -w 'passwd123'
复制代码
发现报错了:
[gpadmin@mpp01 gpseg-1]$ psql -Ubdp01 -d gptest -w 'passwd123'Password for user bdp01: psql: FATAL: no pg_hba.conf entry for host "[local]", user "bdp01", database "gptest", SSL off
复制代码
GPDB 登录需要在 pg_hba.conf 文件中添加信任的用户:
添加后,使配置文件生效,再次登录:
[gpadmin@mpp01 gpseg-1]$ psql -Ubdp01 -d gptest -w 'passwd123'psql: warning: extra command-line argument "passwd123" ignoredpsql (8.3.23)Type "help" for help.
gptest=>
复制代码
登录成功!5. 创建资源队列
为什么要创建资源队列呢?我们知道一个数据库肯定不是给一个用户使用的,通常是有 ETL 用户,进行数据加载,数据清洗。还有 WEB 端用户进行查询,还有个人用户进行开发查询使用等等。这么多用户,如果不进行资源队列管控,那么就会出现资源争抢现象,影响线上应用功能。比如一个新手开发人员写了一个比较菜的查询语句,占用了大量资源,此时数据库的其他查询用户都需要排队等待了。再比如加载数据是需要使用大量资源,那么也会影响查询性能,以上你会发现,你需要把不同类型的操作进行资源隔离,这就是为什么要有资源队列了。查看已有的资源队列:
gptest=> SELECT rolname, rsqname FROM pg_roles, gp_toolkit.gp_resqueue_statusgptest-> WHERE pg_roles.rolresqueue=gp_toolkit.gp_resqueue_status.queueid; rolname | rsqname -----------+------------ bdp01 | pg_default selectbdp | pg_default gpadmin | pg_default(3 rows)
复制代码
创建一个新的资源队列:
gptest=# create resource queue load_queue with (active_statements=3,MEMORY_LIMIT='1024MB',PRIORITY=LOW); CREATE QUEUE
复制代码
把创建的资源队列赋权给刚才创建的用户 bdp01:
gptest=# ALTER USER bdp01 resource queue load_queue; ALTER ROLE
复制代码
再次查询资源池分配情况:
gptest=# SELECT rolname, rsqname FROM pg_roles, gp_toolkit.gp_resqueue_status WHERE pg_roles.rolresqueue=gp_toolkit.gp_resqueue_status.queueid; rolname | rsqname -----------+------------ bdp01 | load_queue selectbdp | pg_default gpadmin | pg_default(3 rows)
复制代码
可以看到 bpd01 已经使用了新的资源池了。
分区是把一张大表按照适合的维度进行分割,通过表的继承,规则,约束实现。并不是每个表都适合分区,只有很大的表才适合分区,应为分区多了会增加表的元数据信息,特别是多级分区。如果一个表被按照日和城市划分并且有 1000 个日以及 1000 个城市,那么分区的总数就是一百万。列存表会把每一列存在一个物理表中,因此如果这个表有 100 个列,系统就需要为该表管理一亿个文件。一方面 Linux 的 iNode 可能不会有这么大,就会出现文件查询报错等,分区过多了,对于数据库停止和恢复也会造成很大影响的。所以建立分区表的时候,对分区进行自动的创建和删除,以保障合适的数据周期很重要。
以上就是 GPDB 简单的管理流程,后面我们会再介绍更深入的查询优化和管理知识。











评论