作业:架构实战营模块 2
题目
分析一下微信朋友圈的高性能复杂度
作业要求
对照模块 2 讲述的复杂度分析方法,分析微信朋友圈的复杂度;
针对各个复杂度,画出你的架构设计方案(无需做备选方案,只需要最终的方案即可);
给出你的架构方案中关键的设计理由。
3~5 页 PPT 即可,涵盖复杂度分析、架构设计、设计理由。
提示
1. 分析过程可以参考模块 2 第 5 课的实战案例,但是不需要将分析过程一一列举出来。
2. 如果某个地方被卡主了,请及时联系助教或者老师讨论。
作业
复杂度总体分析
微信朋友圈业务场景主要分为:发朋友圈、刷朋友圈、点赞、评论、权限控制等。
总体来看业务复杂度不高,质量复杂度主要在于存储高性能。
性能业务指标
每天有 7.8 亿用户进入朋友圈,每天有 1.2 亿用户发表朋友圈,其中照片 6.7 亿,短视频 1 亿条。
性能复杂度分析
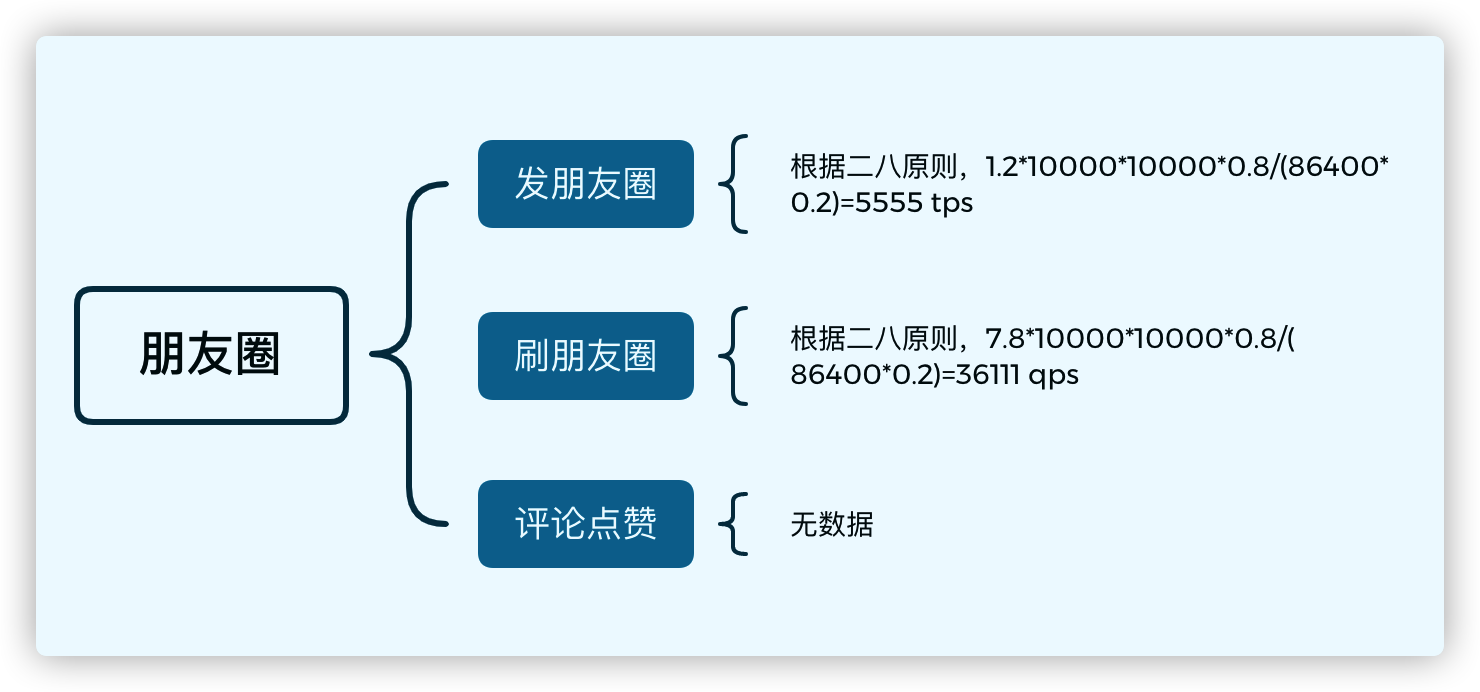
本文内容中未考虑,发朋友圈时,单独设计权限的业务场景。该场景需要额外增加群组表,用于过滤群组用户。
性能复杂度应对思路
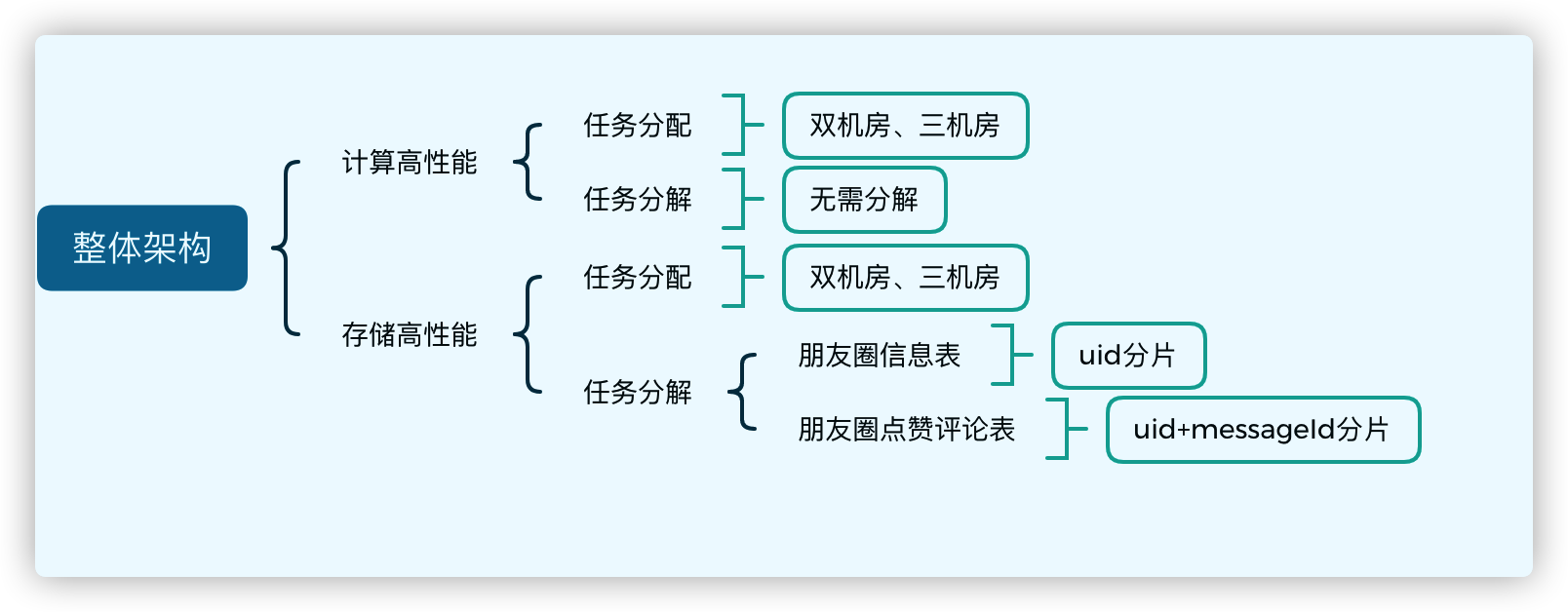
发/刷朋友圈


单机计算高性能:需要在本地对朋友圈内容进行过滤。可以对当天的数据增加本地缓存。
存储模型:
朋友圈信息表
并发不高 -- 每个人的通讯录好友是有限的
查询条件及排序方式十分单一 -- 只有 uid+分页条件+按时间倒序
写少读多,没有修改功能,无需支持事物 -- 因此不必使用关系型数据库
因此采用 mongoDB 就可以满足需求,并且很容易使用 uid 进行分片,优化性能优化。
多媒体内容,由 OSS+CDN 提供访问能力。
数据量大
要求带宽高
因此和业务数据拆分,使用 OSS 进行存储,且可以加 CDN 来进行优化。
朋友圈权限需要访问用户设置表进行查询。
评论点赞

朋友圈评论点赞表:查询条件异常单一 -- 只有通过消息 id 进行查询
因此在朋友圈信息表中的子文档进行存储即可。
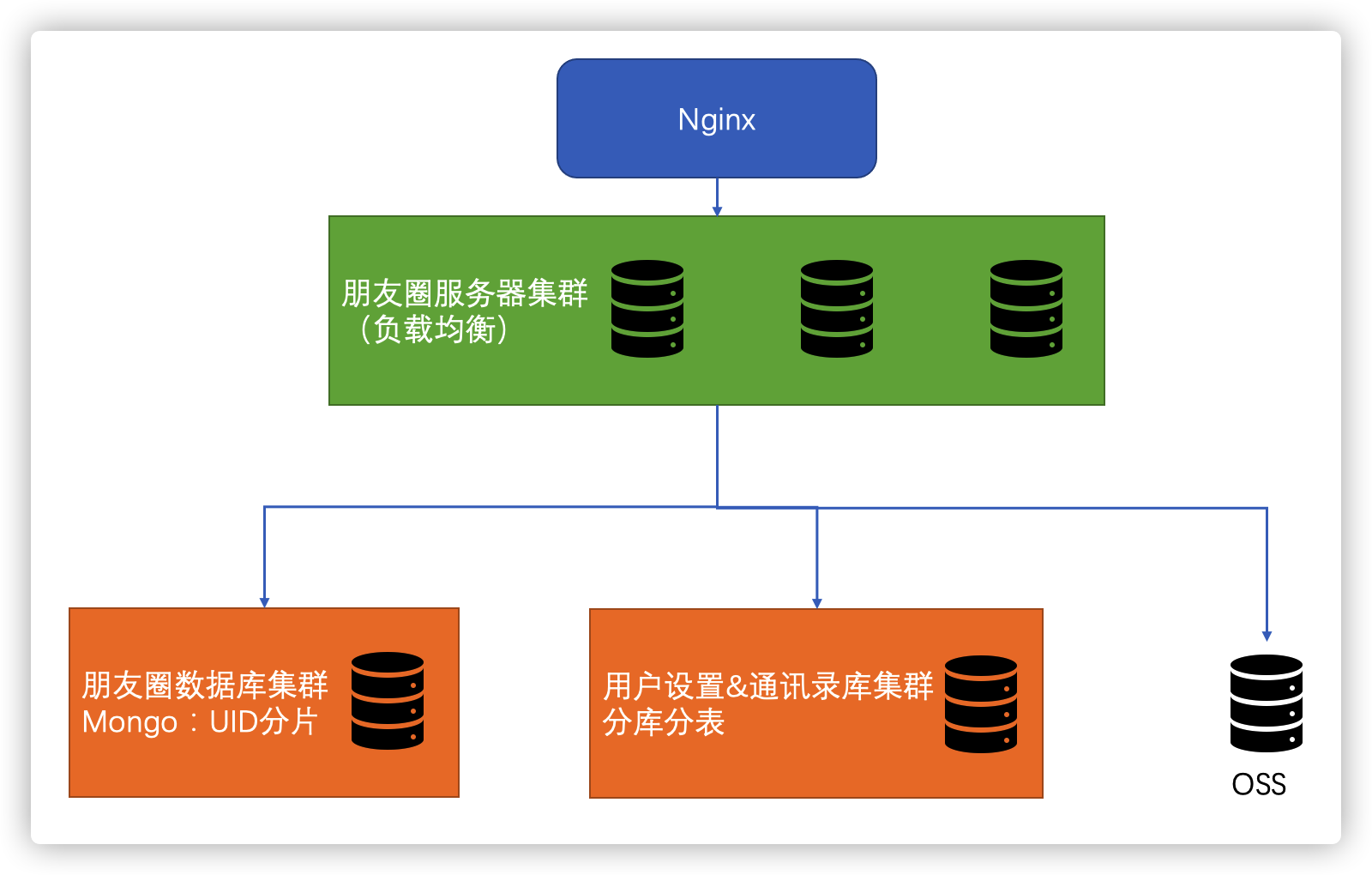
整体架构
架构图
设计理由
采用负载均衡的方式,将流量转发给不同的服务器实例进行处理,提升性能。
朋友圈消息因为业务场景单一,数据读写模式单一,因此采用能支持排序及索引的数据库即可满足需求,并且采用 uid hash 的方式,提升读写性能。
因为没有过多的写操作,数据复制格式采用命令形式即可。
数据复制方式,采用多数同步。
状态决策,采用民主式即可。因为对一致性有一定要求。
用户设置及通讯录集群表,采用关系型数据库,并分库分表,以提升读写性能。
版权声明: 本文为 InfoQ 作者【Poplar89】的原创文章。
原文链接:【http://xie.infoq.cn/article/75324a6a963e640e67f6a9e63】。未经作者许可,禁止转载。

还未添加个人签名 2018.12.07 加入
还未添加个人简介









评论