万字长文,Spark 架构原理和 RDD 算子详解一网打进!

一、Spark 架构原理
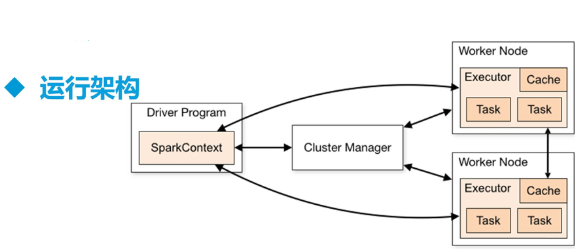
SparkContext 主导应用执行
Cluster Manager 节点管理器
把算子 RDD 发送给 Worker Node
Cache : Worker Node 之间共享信息、通信
Executor 虚拟机 容器启动 接任务 Task(core 数 一次处理一个 RDD 分区)
1.1 Spark 架构核心组件

1.2 各部分功能图
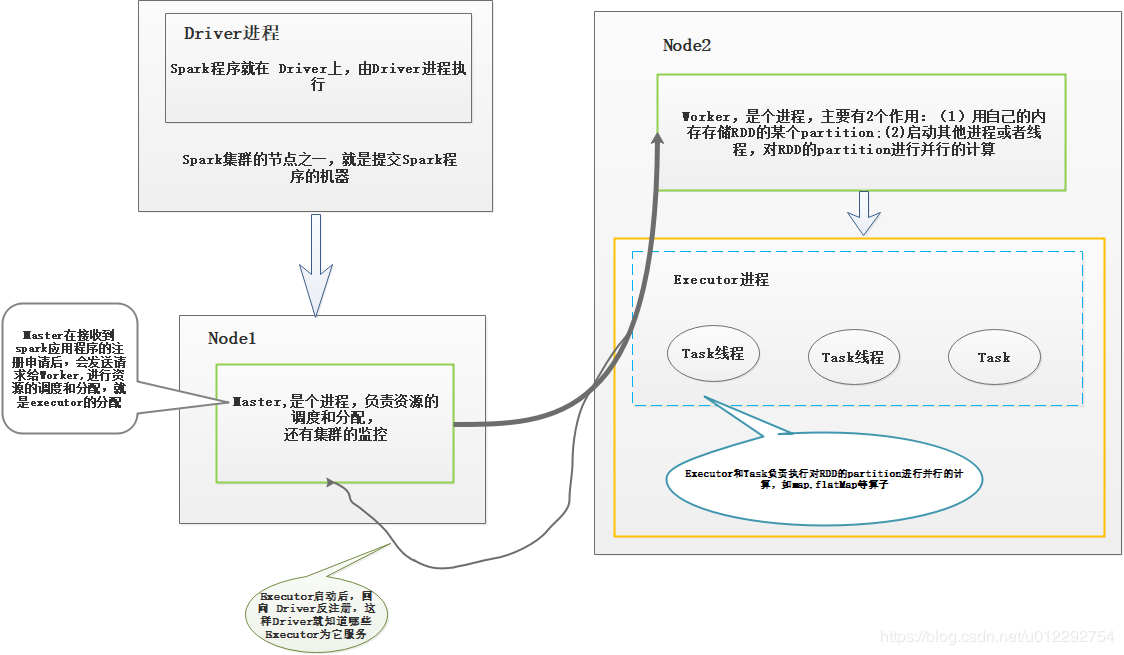
Driver 注册了一些 Executor 后,就可以开始正式执行 spark 应用程序了。第一步是创建 RDD,读取数据源;
HDFS 文件被读取到多个 Worker 节点,形成内存中的分布式数据集,也就是初始 RDD;
Driver 会根据程序对 RDD 的定义的操作,提交 Task 到 Executor;
Task 会对 RDD 的 partition 数据执行指定的算子操作,形成新的 RDD 的 partition;
二、RDD 概述
2.1 什么是 RDD?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,<font color=#FF0000>是 Spark 中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD 具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
2.2 RDD 具体包含了一些什么东西?
RDD 是一个类,它包含了数据应该在哪算,具体该怎么算,算完了放在哪个地方。它是能被序列化,也能被反序列化。在开发的时候,RDD 给人的感觉就是一个只读的数据。但是不是,RDD 存储的不是数据,而是数据的位置,数据的类型,获取数据的方法,分区的方法等等。
2.3 RDD 的五大特性
(1)一组分片(Partition),即数据集的基本组成单位。对于 RDD 来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建 RDD 时指定 RDD 的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的 CPU Core 的数目。
(2)一个计算每个分区的函数。Spark 中 RDD 的计算是以分片为单位的,每个 RDD 都会实现 compute 函数以达到这个目的。compute 函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)RDD 之间的依赖关系。RDD 的每次转换都会生成一个新的 RDD,所以 RDD 之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark 可以通过这个依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算。
(4)一个 Partitioner,即 RDD 的分片函数。当前 Spark 中实现了两种类型的分片函数,一个是基于哈希的 HashPartitioner,另外一个是基于范围的 RangePartitioner。只有对于于 key-value 的 RDD,才会有 Partitioner,非 key-value 的 RDD 的 Parititioner 的值是 None。Partitioner 函数不但决定了 RDD 本身的分片数量,也决定了 parent RDD Shuffle 输出时的分片数量。
(5)一个列表,存储存取每个 Partition 的优先位置(preferred location)。对于一个 HDFS 文件来说,这个列表保存的就是每个 Partition 所在的块的位置。按照“移动数据不如移动计算”的理念,Spark 在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
2.4 RDD 可以从哪来
通过序列化集合的方式

通过读取文件的方式
通过其他的 RDD 进行 transformation 转换而来
2.5 WordCount 粗图解 RDD
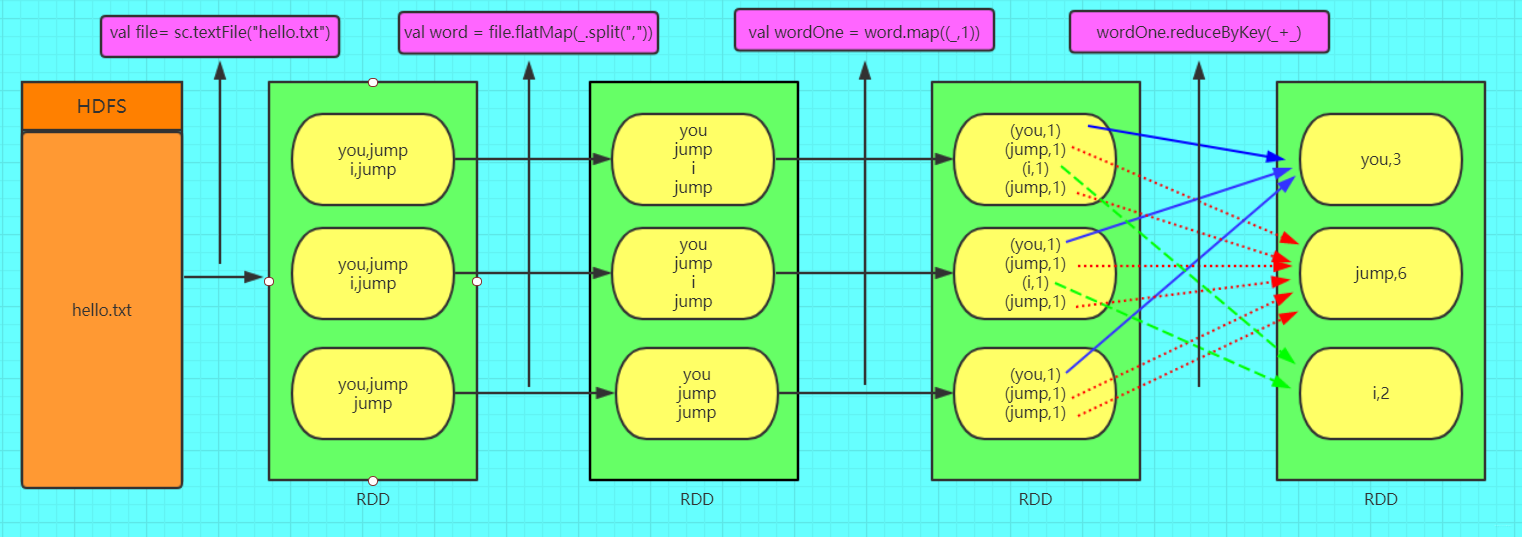
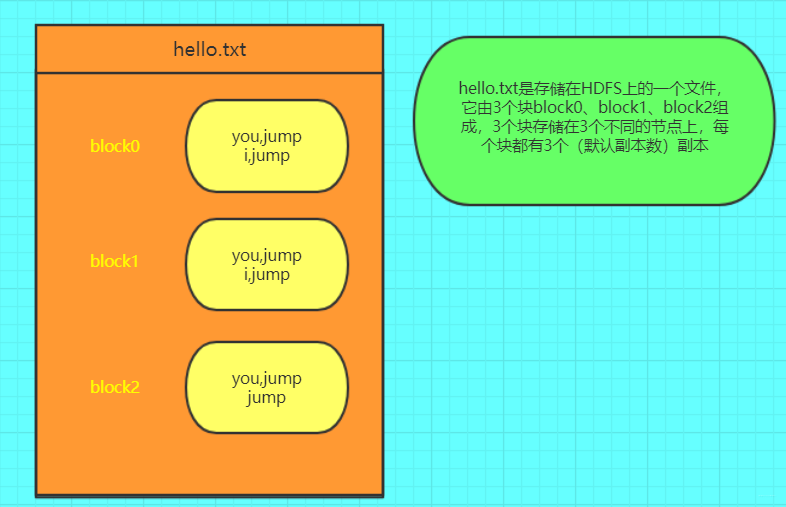
其中 hello.txt
三、RDD 的创建方式
3.1 通过读取文件生成的
由外部存储系统的数据集创建,包括本地的文件系统,还有所有 Hadoop 支持的数据集,比如 HDFS、Cassandra、HBase 等

3.2 通过并行化的方式创建 RDD
由一个已经存在的 Scala 集合创建。

3.3 其他方式
读取数据库等等其他的操作。也可以生成 RDD。
RDD 可以通过其他的 RDD 转换而来的。
四、RDD 编程 API
Spark 支持两个类型(算子)操作:Transformation 和 Action
4.1 Transformation
4.2 Action
触发代码的运行,我们一段 spark 代码里面至少需要有一个 action 操作。
常用的 Action:
4.3 Spark WordCount 代码编写
使用 maven 进行项目构建
(1)使用 scala 进行编写
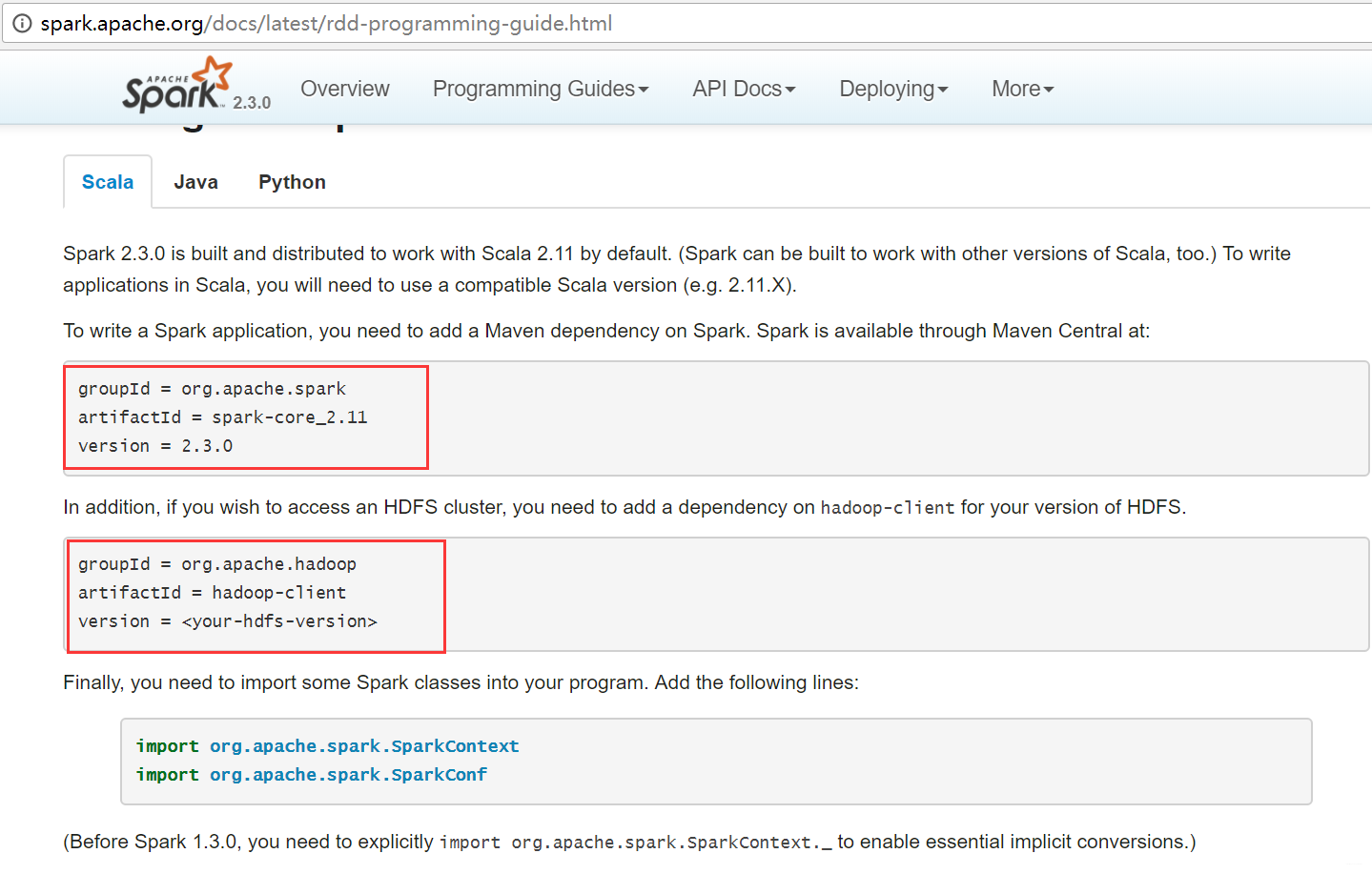
查看官方网站,需要导入 2 个依赖包
详细代码
SparkWordCountWithScala.scala
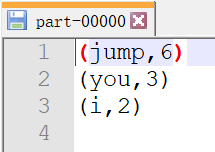
运行结果
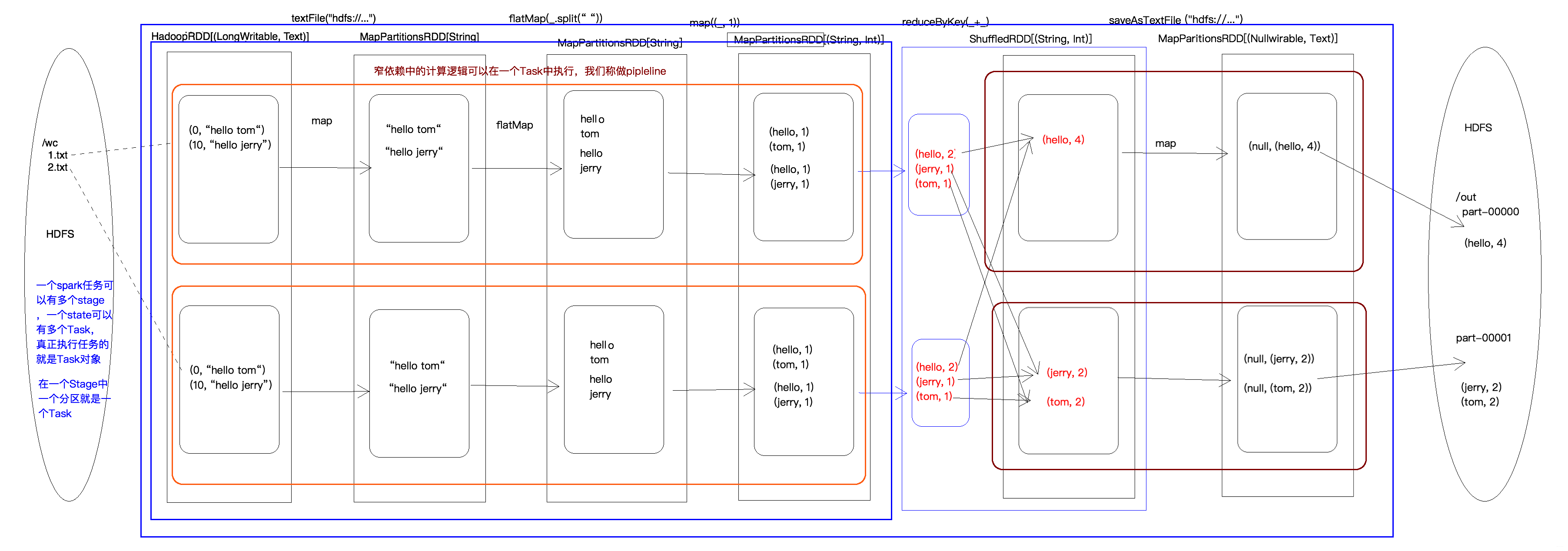
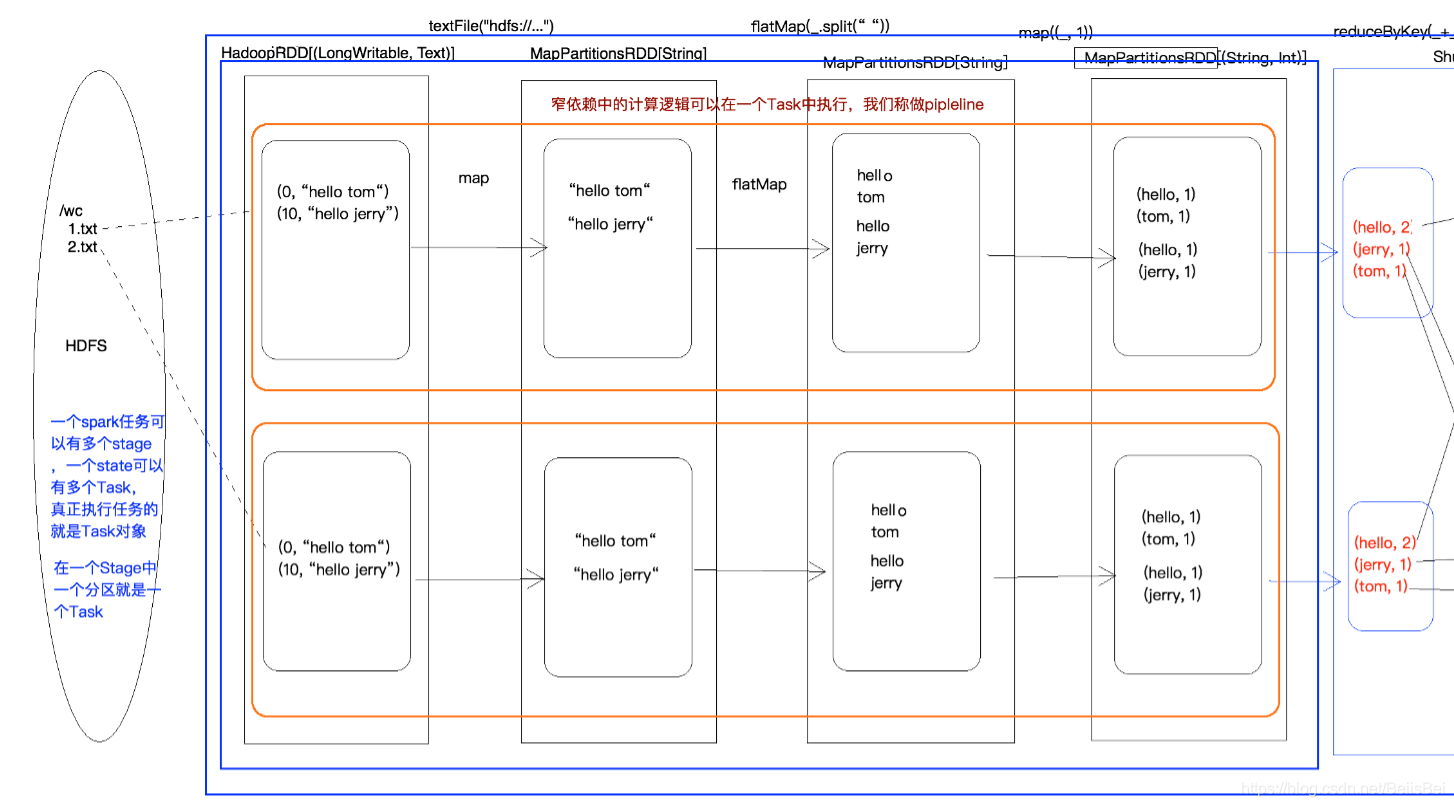
4.4 WordCount 执行过程图
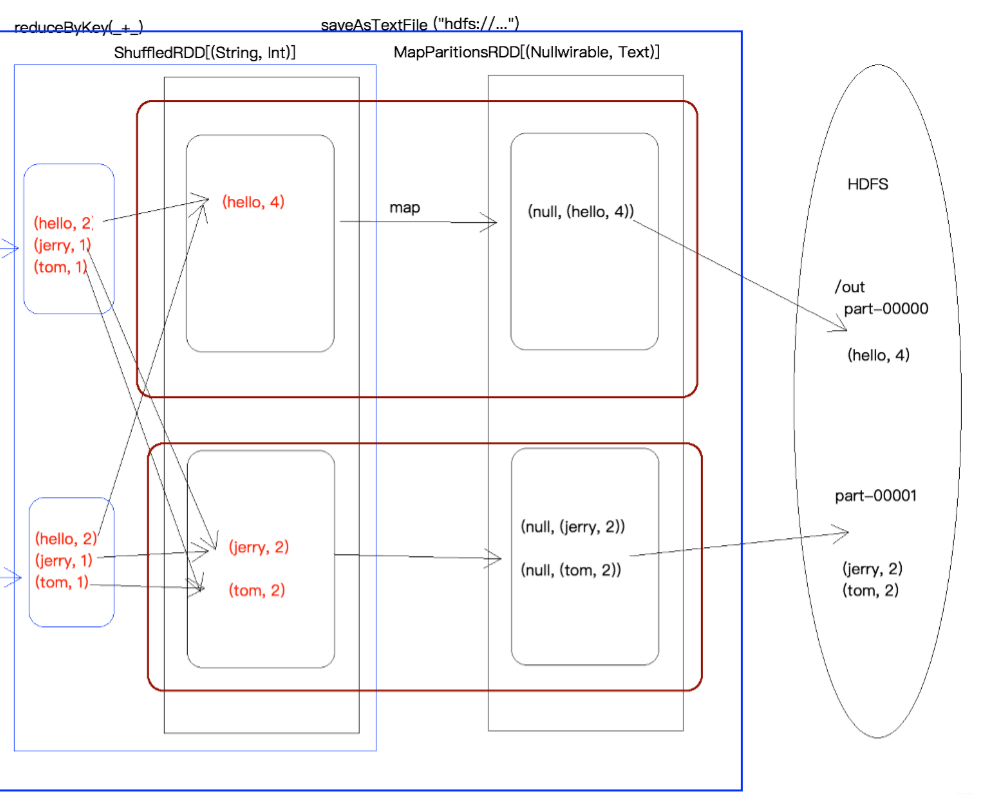
五、RDD 的宽依赖和窄依赖
5.1 RDD 依赖关系的本质内幕
由于 RDD 是粗粒度的操作数据集,每个 Transformation 操作都会生成一个新的 RDD,所以 RDD 之间就会形成类似流水线的前后依赖关系;RDD 和它依赖的父 RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。如图所示显示了 RDD 之间的依赖关系。
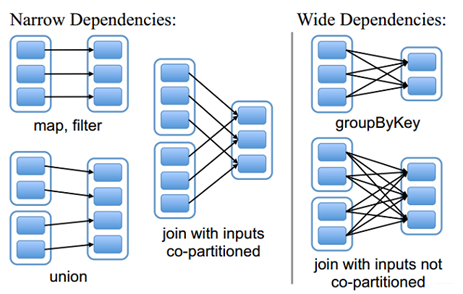
从图中可知:
窄依赖:是指每个父 RDD 的一个 Partition 最多被子 RDD 的一个 Partition 所使用,例如 map、filter、union 等操作都会产生窄依赖;(独生子女)
宽依赖:是指一个父 RDD 的 Partition 会被多个子 RDD 的 Partition 所使用,例如 groupByKey、reduceByKey、sortByKey 等操作都会产生宽依赖;(超生)
需要特别说明的是对 join 操作有两种情况:
(1)图中左半部分 join:如果两个 RDD 在进行 join 操作时,一个 RDD 的 partition 仅仅和另一个 RDD 中已知个数的 Partition 进行 join,那么这种类型的 join 操作就是窄依赖,例如图 1 中左半部分的 join 操作(join with inputs co-partitioned);
(2)图中右半部分 join:其它情况的 join 操作就是宽依赖,例如图 1 中右半部分的 join 操作(join with inputs not co-partitioned),由于是需要父 RDD 的所有 partition 进行 join 的转换,这就涉及到了 shuffle,因此这种类型的 join 操作也是宽依赖。
总结:
在这里我们是从父 RDD 的 partition 被使用的个数来定义窄依赖和宽依赖,因此可以用一句话概括下:如果父 RDD 的一个 Partition 被子 RDD 的一个 Partition 所使用就是窄依赖,否则的话就是宽依赖。因为是确定的 partition 数量的依赖关系,所以 RDD 之间的依赖关系就是窄依赖;由此我们可以得出一个推论:即窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖。
一对固定个数的窄依赖的理解:即子 RDD 的 partition 对父 RDD 依赖的 Partition 的数量不会随着 RDD 数据规模的改变而改变;换句话说,无论是有 100T 的数据量还是 1P 的数据量,在窄依赖中,子 RDD 所依赖的父 RDD 的 partition 的个数是确定的,而宽依赖是 shuffle 级别的,数据量越大,那么子 RDD 所依赖的父 RDD 的个数就越多,从而子 RDD 所依赖的父 RDD 的 partition 的个数也会变得越来越多。
5.2 依赖关系下的数据流视图
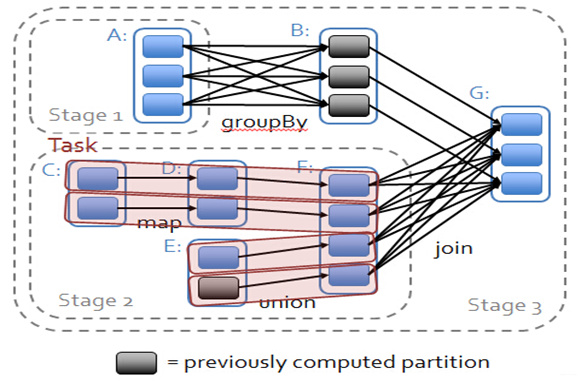
在 spark 中,会根据 RDD 之间的依赖关系将 DAG 图(有向无环图)划分为不同的阶段,对于窄依赖,由于 partition 依赖关系的确定性,partition 的转换处理就可以在同一个线程里完成,窄依赖就被 spark 划分到同一个 stage 中,而对于宽依赖,只能等父 RDD shuffle 处理完成后,下一个 stage 才能开始接下来的计算。
因此 spark 划分 stage 的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个 stage;遇到窄依赖就将这个 RDD 加入该 stage 中。因此在图 2 中 RDD C,RDD D,RDD E,RDDF 被构建在一个 stage 中,RDD A 被构建在一个单独的 Stage 中,而 RDD B 和 RDD G 又被构建在同一个 stage 中。
在 spark 中,Task 的类型分为 2 种:ShuffleMapTask 和 ResultTask:
简单来说,DAG 的最后一个阶段会为每个结果的 partition 生成一个 ResultTask,即每个 Stage 里面的 Task 的数量是由该 Stage 中最后一个 RDD 的 Partition 的数量所决定的!而其余所有阶段都会生成 ShuffleMapTask;之所以称之为 ShuffleMapTask 是因为它需要将自己的计算结果通过 shuffle 到下一个 stage 中;也就是说上图中的 stage1 和 stage2 相当于 mapreduce 中的 Mapper,而 ResultTask 所代表的 stage3 就相当于 mapreduce 中的 reducer。
在之前动手操作了一个 wordcount 程序,因此可知,Hadoop 中 MapReduce 操作中的 Mapper 和 Reducer 在 spark 中的基本等量算子是 map 和 reduceByKey;不过区别在于:Hadoop 中的 MapReduce 天生就是排序的;而 reduceByKey 只是根据 Key 进行 reduce,但 spark 除了这两个算子还有其他的算子;因此从这个意义上来说,Spark 比 Hadoop 的计算算子更为丰富。
版权声明: 本文为 InfoQ 作者【云祁】的原创文章。
原文链接:【http://xie.infoq.cn/article/71e6677d03b59ce7aa5eec22a】。文章转载请联系作者。

公众号:云祁QI 2020.06.23 加入
我是「云祁」,一枚热爱技术、会写诗的大数据开发猿,专注数据中台和 Hadoop / Spark / Flink 等大数据技术,欢迎一起交流学习。生命不是要超越别人,而是要超越自己!加油 (ง •_•)ง









评论