
elasticsearch 安装和使用 ik 分词器

欢迎访问我的 GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
在使用 elasticsearch 的时候,如果不额外安装分词器的话,在处理 text 字段时会使用 elasticsearch 自带的默认分词器,我们来一起看看默认分词器的效果;
环境信息
本次实战用到的 elasticsearch 版本是 6.5.0,安装在 Ubuntu 16.04.5 LTS,客户端工具是 postman6.6.1;
如果您需要搭建 elasticsearch 环境,请参考《Linux环境快速搭建elasticsearch6.5.4集群和Head插件》;
Ubuntu 服务器上安装的 JDK,版本是 1.8.0_191;
Ubuntu 服务器上安装了 maven,版本是是 3.5.0;
elasticsearch 为什么要用 6.5.0 版本
截止发布文章时间,elasticsearch 官网已经提供了 6.5.4 版本下载,但是 ik 分词器的版本目前支持到 6.5.0 版本,因此本次实战的 elasticsearch 选择了 6.5.0 版本;
基本情况介绍
本次实战的 elasticsearch 环境已经搭建完毕,是由两个机器搭建的集群,并且 elasticsearch-head 也搭建完成:
一号机器,IP 地址:192.168.150.128;
二号机器:IP 地址:192.168.150.128;
elasticsearch-head 安装在一号机器,访问地址:http://192.168.150.128:9100
数据格式说明
为了便于和读者沟通,我们来约定一下如何在文章中表达请求和响应的信息:
假设通过 Postman 工具向服务器发送一个 PUT 类型的请求,地址是:http://192.168.150.128:9200/test001/article/1
请求的内容是 JSON 格式的,内容如下:
对于上面的请求,我在文章中就以如下格式描述:
读者您看到上述内容,就可以在 postman 中发起 PUT 请求,地址是"test001/article/1"前面加上您的服务器地址,内容是上面的 JSON;
默认分词器的效果
先来看看默认的分词效果:
创建一个索引:
查看索引基本情况:
收到响应如下,可见并没有分词器的信息:
查看分词效果:
收到响应如下,可见每个汉字都被拆分成一个词了,这样会导致词项搜索时收不到我们想要的(例如用"我们"来搜索是没有结果的):
为了词项搜索能得到我们想要的结果,需要换一个分词器,理想的分词效果应该是"我们"、"是"、"软件"、"工程师",ik 分词器可以满足我们的要求,接下来开始实战;
注意事项
下面的所有操作都使用 es 账号来进行,不要用 root 账号;
编译 ik 分词器需要用到 maven,如果您有 docker,但是不想安装 maven,可以参考《没有JDK和Maven,用Docker也能构建Maven工程》来编译工程;
下载 IK 分词器源码到 Ubuntu
登录 ik 分词器网站:https://github.com/medcl/elasticsearch-analysis-ik
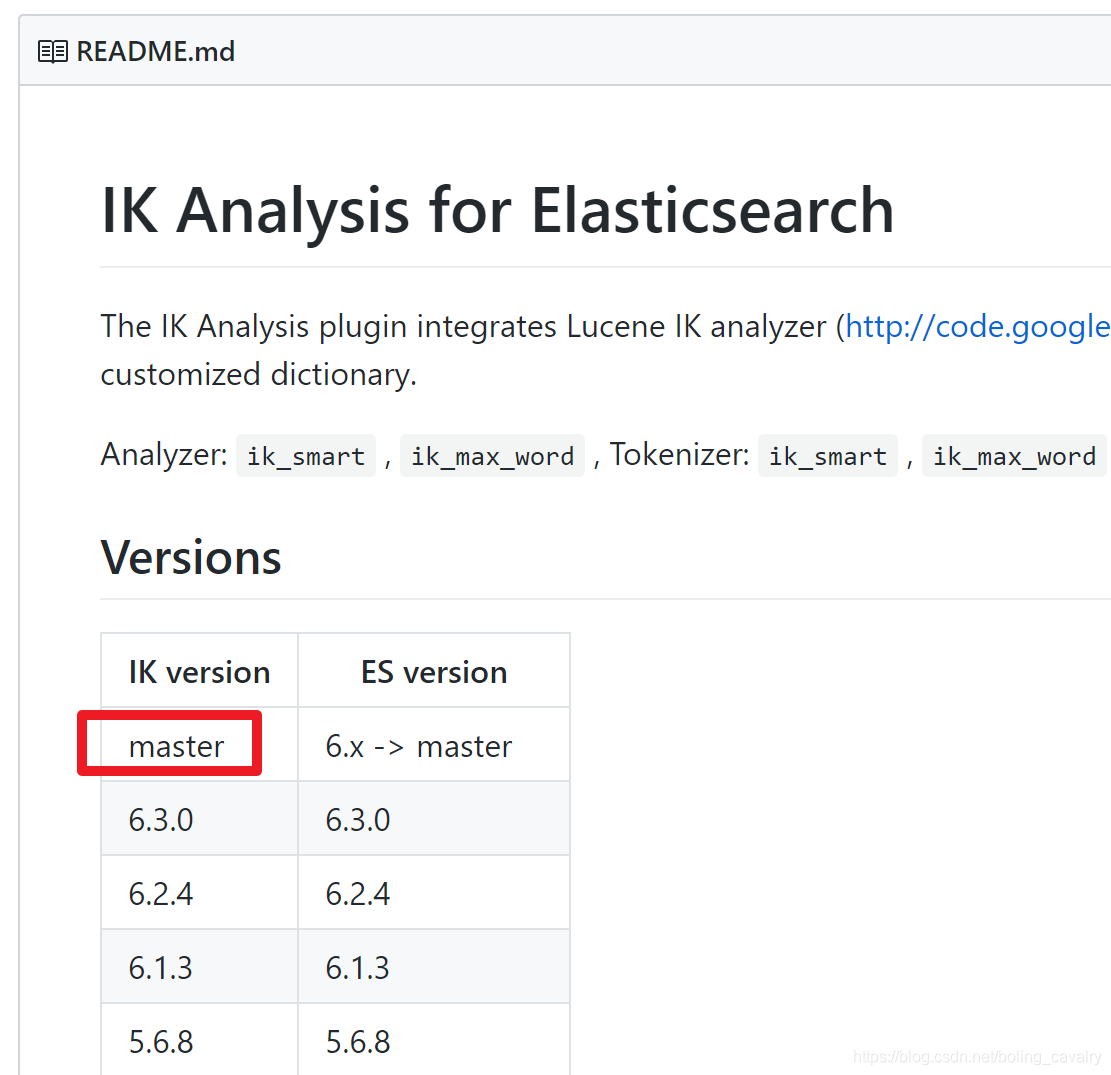
按照网站提供的版本对应表,确认我们要使用的分词器版本,很遗憾写文章的时候还没有匹配 elasticsearch-6.5.0 的版本,那就用 master 吧,也就是下图中的红框版本:
如下图,点击下载 zip 文件:
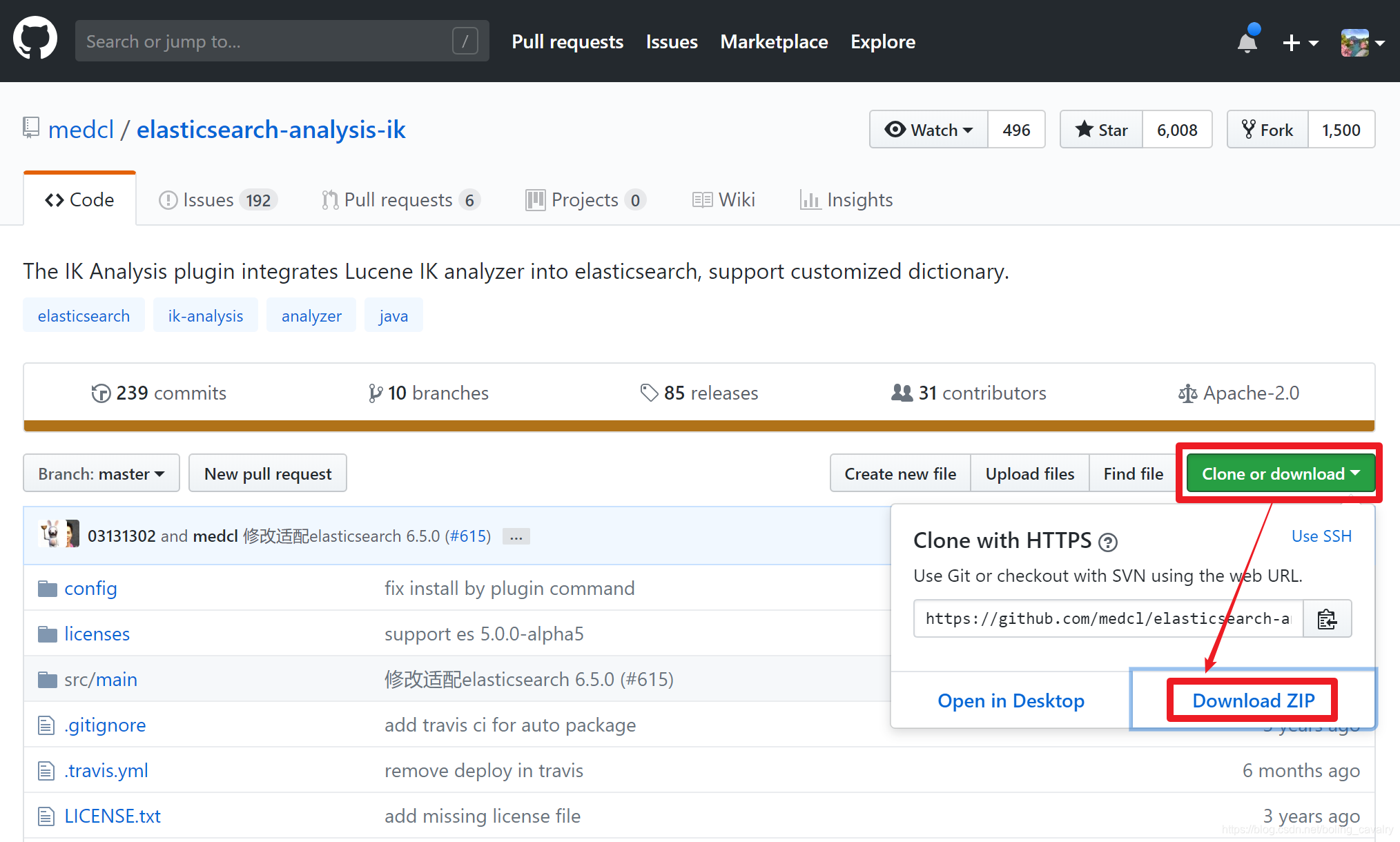
将下载的 zip 包放到 Ubuntu 机器上,解压后是个名为 elasticsearch-analysis-ik-master 的文件夹,在此文件夹下执行以下命令,即可开始构建 ik 分词器工程:
等待编译完成后,在 target/release 目录下会生产名为 elasticsearch-analysis-ik-6.5.0.zip 的文件,如下所示:
停止集群中所有机器的 elasticsearch 进程,在所有机器上做这些操作:在 elasticsearch 的 plugins 目录下创建名为 ik 的目录,再将上面生成的 elasticsearch-analysis-ik-6.5.0.zip 文件复制到这个新创建的 ik 目录下;
在 elasticsearch-analysis-ik-6.5.0.zip 所在文件夹下,执行目录 unzip elasticsearch-analysis-ik-6.5.0.zip 进行解压;
确认 elasticsearch-analysis-ik-6.5.0.zip 已经复制到每个 elasticsearch 的 plugins/ik 目录下并解压后,将所有 elasticsearch 启动,可以发现控制台上会输出 ik 分词器被加载的信息,如下图所示:

至此,ik 分词器安装完成,来验证一下吧;
验证 ik 分词器
在 postman 发起请求,在 json 中通过 tokenizer 指定分词器:
这一次得到了分词的效果:
可见所有可能形成的词语都被分了出来,接下试试 ik 分词器的另一种分词方式 ik_smart;
使用 ik_smart 方式分词的请求如下:
这一次得到了分词的效果:
可见 ik_smart 的特点是将原句做拆分,不会因为各种组合出现部分的重复,以下是来自官方的解释:
验证搜索
前面通过 http 请求验证了分词效果,现在通过搜索来验证分词效果;
通过静态 mapping 的方式创建索引,指定了分词器和分词方式:
创建成功会收到以下响应:
创建一个文档:
用工程师作为关键词查询试试:
搜索成功:
至此,ik 分词器的安装和使用实战就完成了,希望本文能在您的使用过程中提供一些参考;
欢迎关注 InfoQ:程序员欣宸
版权声明: 本文为 InfoQ 作者【程序员欣宸】的原创文章。
原文链接:【http://xie.infoq.cn/article/6ef0b394d57e5ccd6cbd6bd6f】。文章转载请联系作者。

搜索"程序员欣宸",一起畅游Java宇宙 2018.04.19 加入
前腾讯、前阿里员工,从事Java后台工作,对Docker和Kubernetes充满热爱,所有文章均为作者原创,个人Github:https://github.com/zq2599/blog_demos









评论