Redis 哨兵模式原理剖析,监控、选主、通知客户端你真的懂了吗?
哨兵每隔 10 秒会向每个 master 节点发送?info?命令,?info?命令返回的信息中,包含了主从拓扑关系,其中包括每个 slave 的地址和端口号。有了这些信息后,哨兵就会记住这些节点的拓扑信息,在后续发生故障时,选择合适的 slave 节点进行故障恢复。
那么有小伙伴会问,哨兵之间是如何通信的呢?
基于 Redis 提供的发布(pub)/订阅(sub)机制完成的。哨兵节点不会直接与其他哨兵节点建立连接,?而是首先会和主库建立起连接?,然后向一个名为"?sentinel?:hello"频道发送自己的信息(IP 和端口),其他订阅了该频道的哨兵节点就会获取到该哨兵节点信息,从而哨兵节点之间互知。
2.心跳检测
======
每一秒,每个 Sentinel 对 Master、Slave、其他哨兵节点执行 PING 命令,检测它们是否仍然在线运行,如果有节点在规定时间内没有响应 PING 命令,那么该哨兵节点认为此节点"主观下线"。
3.主观下线和客观下线
===========
为什么需要客观下线机制?
因为当前哨兵节点探测对方没有得到响应,很有可能这两个机器之间的网络发生了故障,而 Master 节点本身没有任何问题,此时就认为 Master 故障是不正确的。
为了解决上述问题,客观下线应运而生,Sentinel 一般会集群部署,引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。
假设我们有 N 个哨兵实例,如果有 N/2+1 个实例判断主库“主观下线”,此时把节点标记为“客观下线”,此时就可以做主从切换了。
4.选举哨兵领导者?
==========
假设 Sentinel 判断主库“主观下线”后,就会给其他 Sentinel 实例发送 is-master-down-by-addr 命令,接着,其他 Sentinel 实例会根据自己和主库的连接情况,做出赞成和反对决定。
假设我们有 N 个哨兵实例,如果有 #{quorum}个实例赞成,此时这个 Sentinel 就会给其他 Sentinel 发送主从切换请求,其他 Sentinel 会进行投票,如果投票通过,这个 Sentinel 就可以进行主从切换了,?这个投票过程被称为 Leader 选举?。其实整体思想和 Zookeeper 一样
的。
在投票过程中,任何一个想成为 Leader 的哨兵,要满足两个条件:第一,拿到半数以上的赞成票;第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。
quorum 一般我们都会配置成?实例数量/2+1
此时会有小伙伴问,如果所有 Sentinel 都想成为 Leader 执行主从切换怎么办?
哨兵选举领导者的过程类似于 Raft 算法,每个哨兵都设置一个?随机超时时间?,超时后向其他哨兵发送申请成为领导者的请求,把超时时间都分散开来, 在大多数情况下只有一个服务器节点先发起选举,而不是同时发起选举,这样就能减少因选票瓜分导致选举失败的情况 。
后期我会专门写一个专栏为大家介绍所有一致性算法,例如:Paxos、Raft、Gossip、ZAB 等,到时候具体给大家讲解 Sentinel 是如何解决上述问题的。
5.谁来做新的 Master?
==============
选择新 master 过程也是有优先级的,在多个 slave 的场景下,优先级按照:slave-priority 配置 > 数据完整性 > runid 较小者进行选择。
用户可以通过 slave-priority 配置项,给不同的从库设置不同优先级。如果所有从节点的 slave-priority 值一致,那就看谁的数据更完整。
如何判断谁的数据更完整呢?
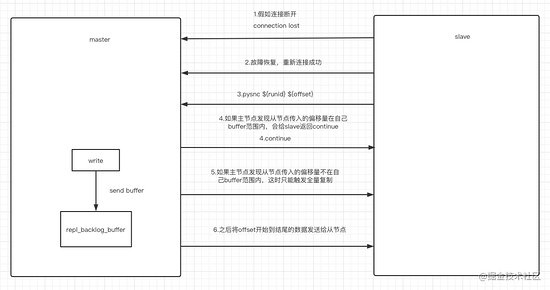
主库会用 master_repl_offset 记录当前的最新写操作在 repl_backlog_buffer 中的位置,而从库会用 slave_repl_offset 这个值记录当前的复制进度。此时,哪个从库的 slave_repl_offset 最接近 master_repl_offset。那么谁就可以作为新主库。
如果 slave_repl_offset 都一致,那就比 runid,选择 runid 最小的 Slave 节点作为新主库。

还未添加个人签名 2021.11.08 加入
还未添加个人简介









评论