TDSQL 核心架构
TDSQL 系统总览

1.1 资源池
这张图从下往上看,首先最底层是资源池,属于 IaaS 层服务,可以是物理机,也可以是虚拟机,只要是给 TDSQL 添加机器就好,TDSQL 是在一个机器的资源池上实现了数据库实例的管理。当然,这里推荐的还是物理机,如果增加一层虚拟机服务,无疑在稳定性和性能方面都会引入一些隐患。
1.2 存储节点
从资源池再往上是存储节点。存储节点要强调的是 TDSQL 的两种存储形态,一种是 Noshard 数据库,一种是分布式数据库(也叫 Shard 版 TDSQL)。简单来说,Noshard 就是一个单机版的 TDSQL,在 MySQL 的基础上做了一系列的改造和改良,让它支持 TDSQL 的一系列特性,包括高可用,数据强一致、7×24 小时自动故障切换等。第二种是分布式数据库,具备水平伸缩能力。所以 TDSQL 对外其实呈现了两种形态,呈现一种非分布式形态,一种是分布式的形态。至于这两种形态的区别,或者说什么场景更适合于哪种数据库,后面我们有专门的章节去分析。
1.3 计算节点
再看计算节点。计算节点就是 TDSQL 的计算引擎,做到了计算层和存储层相分离。计算层主要是做一些 SQL 方面的处理,比如词法解、语法解析、SQL 改写等。如果是分布式数据库形态,还要做分布式事务相关的协调,所以我们看到计算层不存储数据,只运行 SQL 方面的实时计算,所以它更偏 CPU 密集型。此外,TDSQL 计算节点还具备 OLAP 的能力,对一些复杂的计算可以进行算法上的优化——什么时候该下推到存储引擎层,什么时候需要在计算层做汇总等,这是计算节点需要做的事情。
1.4 赤兔运营管理平台
再往上,是赤兔运营管理平台,如果说把下面这一套东西比作一个黑盒,我们希望有一个用户界面操纵这个黑盒,这个界面就是赤兔运营管理平台。通过这个平台,DBA 可以操纵 TDSQL 后台黑盒,所以相当于是一套 WEB 管理系统。让所有 DBA 的操作都可以在用户界面上完成,而不需要登陆到后台,不需要关心计算节点是哪个,存储节点是哪个,或者怎么样管理它,要加一些节点或者减一些节点,或者把这个节点从哪里要迁到哪里……这些都可以通过界面化完成。DBA 操作界面不容易出错,但如果登陆到后台很容易一个误操作,不小心把机器重启了,就可能会造成一定的影响。
1.5 “扁鹊”智能 DBA 平台
有了赤兔之外,为什么还有一个“扁鹊”智能 DBA 平台呢?可能正常情况下,我们机器是好的,但是,机器如果发生了故障,或者说哪天磁盘有坏块了,或者是 IO 性能越来越差……SSD 其实有一个衰老的过程,到了后期的话,吞吐量和 IOPS 可能会有一定下降,导致数据库的响应速度变慢。这种情况如果 DBA 要排查,得先去看到是哪一个实例、涉及到哪一台机器、这个机器有什么问题、检测机器的健康状态……这些都是机械性的工作,有了扁鹊智能管理平台,当出现故障的时候就可以自动分析故障的原因,举个例子,可以找出是因为什么导致 SQL 变慢了,或者又是因为什么原因发生了主备切换,突然 IO 异常了或者其他什么原因导致机器故障。
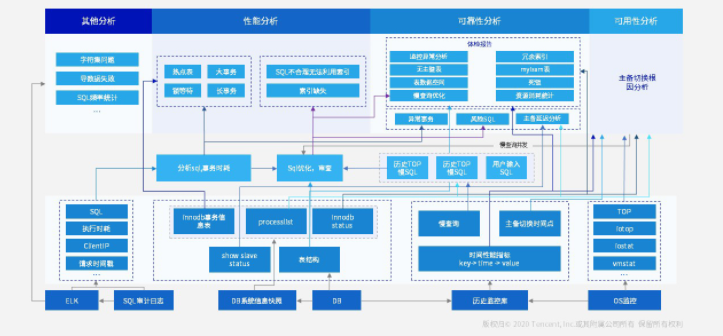
此外,扁鹊智能 DBA 平台还有一个智能诊断系统,可以定期由 DBA 发起对实例进行的诊断。比如有些数据库实例,CPU 常年跑得很高,其实是一些比较差的 SQL 导致的。这个时候扁鹊智能 DBA 系统,可以很方便地到用户实例上做巡检,得到一个健康状况图,并对它进行打分,发现这个实例比如他的 CPU 超用了,需要扩容,但是没有扩容,就会减分;然后其他表的索引没有建好,要减分……以此生成一个诊断报告。所以,有了扁鹊,再加上赤兔运营管理平台,DBA 的工作其实是非常轻松的,可能每天只需要点几下按纽,然后就解决了一系列的麻烦,包括高可用,性能分析,锁分析等,完全把 DBA 从繁杂的工作中解放出来。
此外,我们看到这里其实还有几个小的模块。调度系统,调度系统主要是负责整体的资源调度,比如说数据库实例的增加删除、过期作废,还有一些容量的调度,即扩容、缩容,还有一些多租户的管理。也就是说这是整个管理台的调度器。
另外还有一个备份系统,这个是冷备中心,后面有一个专门的章节去讲,这里就不再赘述。此外,我们还提供了一些服务模块作为辅助,比如审计,还有数据库之间的迁移服务——我们 TDSQL 怎么能够帮助异地数据库迁进来,或者从 TDSQL 再迁出。此外,还包括数据校验、数据订阅、SQL 防火墙、注入检测等安全方面的模块,以及一个辅助模块——帮助我们的 DBA 也好,用户也好,完成一些个性化的丰富的需求。
以上是 TDSQL 系统总览。
TDSQL 架构模块及其特性
我们再看一下核心架构。核心架构其实是上一个图的缩览,我们把核心的模块挑选出来。
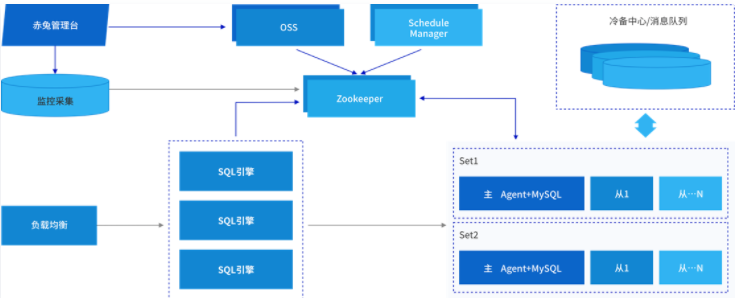
**首先用户的请求通过负载均衡发往 SQL 引擎。然后,SQL 引擎作为计算接入层,根据这个 SQL 的要求从后端的存储节点去取数据。**当然,无论是 SQL 引擎还是后端的数据库实例都存在一个元数据来管理调度。举个例子,计算引擎需要拿到一个路由,路由告诉 SQL 引擎,这个 SQL 该发往哪一个后端的数据节点,到底是该发往主节点还是发往备节点。所以我们引入了 ZK(Zookeeper)来储存类似于路由这类元数据信息。当然 ZK 只是静态的存储元数据,维护和管理这些元数据信息,还需要有一套调度以及接口组件,这里是 OSS、Manager/Schedule。所以我们这张图可以看到是 TDSQL 整体来说就分为三部分:管理节点、计算节点和存储节点。当然这里还有一个辅助模块,帮助完成一些个性化需求的,比如备份、消息队列,数据迁移工具等。另外,这里的负载均衡其实不是必需的,用户可以选用自身的硬件负载,也可以用 LVS 软负载,这个负载均衡根据实际的用户场景可自定义。
了解了整体架构以后,我们继续再看一下每个节点的特性是什么、对机器的依赖程度如何,要求机器有哪些特性,等等。
2.1 管理模块:轻松通过 web 界面管理整个数据库后台
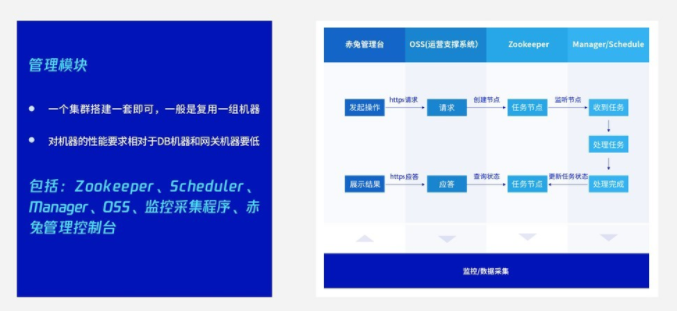
先,我们要看的是管理模块。作为一个集群只搭建一套的管理模块,一般可以复用一组机器。同时,管理模块对机器的要求相对来说比较低,比如资源紧张的时候,我们用虚拟机就可以代替。在我们内部,一套管理模块承载最大的管理单集群近上万实例。
管理模块包含前文说的几个关键模块:Zookeeper(ZK)、Scheduler、Manager、OSS 和监控采集程序、赤兔管理控制台。那么它们是怎么联合工作的呢?首先,DBA 用户在赤兔管理台——这一套 WEB 前台发起一个操作——点了一个按纽,这个按纽可能是对实例进行扩容,这个按纽会把这个 https 的请求转移到 OSS 模块,这个 OSS 模块有点像 web 服务器,它能接收 web 请求,但是它可以把这个转发到 ZK。所以,OSS 模块就是一个前端到后台的桥梁,有了 OSS 模块,整个后台的工作模块都可以跟前台、跟 web 界面绑定在一起。
好,捕捉到这个请求之后,在 ZK 上创建一个任务节点,这个任务节点被调度模块捕获,捕获之后就处理任务。处理完任务,再把它的处理结果返回到 ZK 上。ZK 上的任务被 OSS 捕获,最后也是 https 的请求,去查询这个任务,最后得到一个结果,返回给前端。
这是一个纯异步的过程,但是有了这套管理模块,让我们可以轻松的通过 web 界面去管理整个 TDSQL 的后台。当然,这整个过程都有一个监控采集模块去采集,对整个流程的审计及状态进行获取。
2.2 DB 模块:数据库无损升级

DB 模块,即数据节点,数据存取服务属于 IO 密集型的服务,因此,数据节点也是我们的存储节点,它对 IO 的要求比较高,一般建议配置 SSD 硬盘,最好是 PCI-E 的 SSD。因为对数据库服务来说,CPU 再高,如果 IO 跟不上,仍然是小马拉大车。比如只有 1 千的 IOPS,CPU 根本就跑不起来,用不起来。所以这里一般建议至少 IPS 要达到 1 万以上。
**我们再看一下 SET 的概念。SET 就是数据库实例,一个 SET 包含数据库的——比如我们默认要求的是一主两备,一个 Master 节点和两个 Slave 节点。**当然在 DB 节点上有一个 Agent 的模块。MySQL 在执行中,我们要监控它的行为,以及进行操作。如果把这些东西做到 MySQL 里面为什么不可以呢?这其实存在一个问题,如果对数据节点进行升级,可能就要涉及到重启,一旦重启就影响用户的业务,影响服务。这个时候我们就考虑,在它上面加一个模块 Agent,它来完成对所有集群对 MySQL 的操作,并且上报 MySQL 的状态。有了它之后,对 TDSQL 数据节点的大部分升级,都会转变为对 Agent 的升级,而升级 Agent,对业务没有任何影响,这就实现了无损升级。相比于 Agent 我们对数据节点 MySQL 不会频繁升级,一般情况下一年、半年都不会动它。这是我们 DB 模块,也是存储节点。
2.3 SQL 引擎模块:分布式复杂 SQL 处理
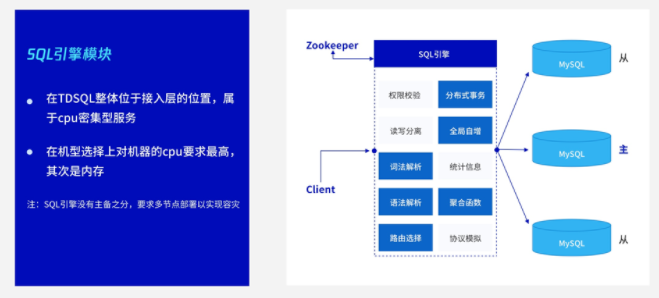
接下来再看另外一个比较重要的模块:SQL 引擎模块。SQL 引擎处于计算层的位置,本身属于 CPU 密集型,所以我们在选机型上尽量要求 CPU 高一些。其次是内存,作为计算接入层,它要管理链接,如果是大量的短链接或者长链接,非常占内存,所以它对 CPU 和内存的要求比较高。此外,它本身不存储数据,也没有主备之分,所以对硬盘没有太大要求。
我们看一下 SQL 引擎的特性。SQL 引擎首先还是从 ZK 上拉取到元数据,作为 SQL 引擎,包括权限校验、读写分离,以及统计信息、协议模拟等相关的操作。
可能有些人会问,其实这个 SQL 引擎岂不是一种中间件?其实并不是这样,SQL 引擎如果是一个中间件,它都可以脱离 MySQL。但是我们这个 SQL 引擎,需要做词法、语法分析,以及作为查询引擎等工作。而且在分布式的场景下,SQL 引擎复杂的功能性就会凸显,比如要处理分布式事物,还要维护全局自增字段,保证多个数据、多个存储节点共享一个保证全局自增的序列;如果是分布式的话,要限制一些语法,包括词法和语法的解析;还有在一些复杂计算上,它还要做一些 SQL 下推,以及最后数据的聚合。所以 SQL 引擎还是一个相对来说比较复杂的模块,作为计算层,并不是一个简单的中间件那么简单。这就是一个 SQL 引擎。

还未添加个人签名 2018.12.08 加入
还未添加个人简介









评论