
面试官:你理解的互联网高性能 Web 架构是咋样的?
在互联网业务中,我们经常会面临流量巨大的复杂的分布式场景。这就要求我们在设计系统的时候保证系统具有承载高并发(High Concurrency)的能力,同时能够保证系统的高可用性(High Availability)。所以,具备高性能 Web 架构通常是指,通过稳健的系统设计能力,来保证系统能够同时处理复杂的业务场景,并保证性能、稳定性、可用性的架构体系。。高性能 Web 常用的一些衡量指标有响应时间(Response Time),吞吐量(Throughput),每秒请求数 QPS(Query Per Second),并发用户数等。
响应时间(RT) 响应时间是指系统对请求作出响应的时间,如一个请求从发送 request 到 response 的时间是 500ms,这就是请求的响应时间。吞吐量(Throughput) 吞吐量是指系统在单位时间内处理请求的数量。并发用户数 并发数是指系统同时能处理的请求数量,这个也是反映了系统的负载能力。
与吞吐量相比,并发用户数是一个更直观但也更笼统的性能指标。实际上,并发用户数是一个非常不准确的指标,因为用户不同的使用模式会导致不同用户在单位时间发出不同数量的请求。
QPS 每秒查询率(Query Per Second) 每秒查询率 QPS 是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准 TPS 每秒事务数(Transactions Per Second) 是吞吐量的常用量化指标
2 如何提升系统的性能指标
在互联网分布式架构设计,我们常常用两种方式来提高系统的性能,一种是横向扩展(Scale Out),一种是纵向扩展(Scale Up)。对于横向纵向扩张我们在 微服务系列、MySQL系列、Redis系列 中已经多次 讨论过了。纵向扩展主要提高单机的性能,让其算力不断提升。横向扩展就是典型的分治思维,单机的内存、CPU、连接数、吞吐量始终是有限的,多实例化的集群支撑才是解决大型分布式场景的保障。
2.1 纵向扩展(Scale Up): 提升单机算力
1、单机硬件水平提升,如 CPU(多线程计算服务消耗大)、内存(缓存等)、GPU(音视频、直播类)、SSD 磁盘(数据存储等),升级到更高的配置;2、提升单机架构性能,很多时候不是服务器硬件水平低,而是架构的不合理。如:
服务模块化分层不合理,导致调用互相影响,请求链路过长。
未合理地使用缓存,导致系统计算时间过长,IO 操作频率过高。
存储服务,如数据库可优化空间大,如 索引使用不当,单表容量过大,单表字段过多,查询未优化等。
这些都是在架构设计的时候需要谨慎对待的。
但是正如上面说的,不论是单机硬件性能,还是单机架构性能,优化都有一个极限,互联网分布式架构设计高并发终极解决方案还是横向扩展。
2.2 横向扩展(Scale Out):
典型的分治思维,单机的内存、SSD、CPU、GPU、连接、吞吐量始终是有限的,总不能无限制的扩展。所以我们需要追求横向扩展,在架构的各个层面做水平扩容,增加实例数量,比如 Services Cluster、Redis Cluster、MySQL Cluster,并在长期的业务实践中不断优化。相对于 Scale Up,他有哪些优势:
理论上的性能无限扩充,单机的扩容总是有限制的,但是集群是可以持续扩张。bat 大厂核心服务的成千上万的服务集群就是很好的业内范例。
提高可用性,水平扩容最终会把计算能力和数据能力分摊在不同的实例、甚至不同的服务、甚至不同机房。某个分区出问题不会导致整个系统崩塌,这个单体系统是不能保障的,哪怕他硬件再牛。
3 业内常见的系统分层架构如下:
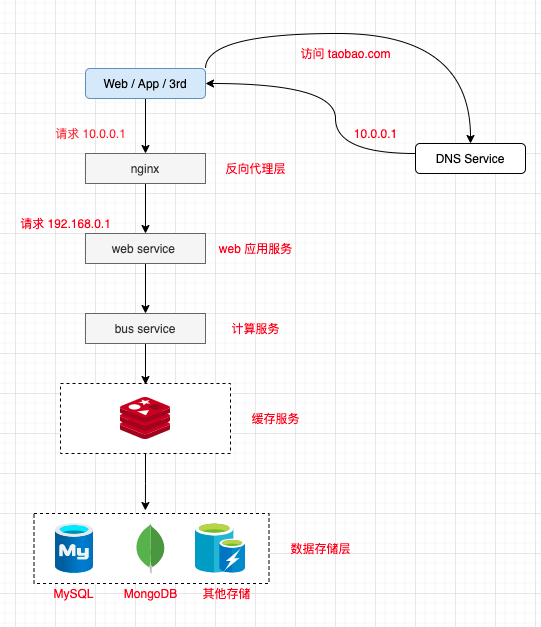
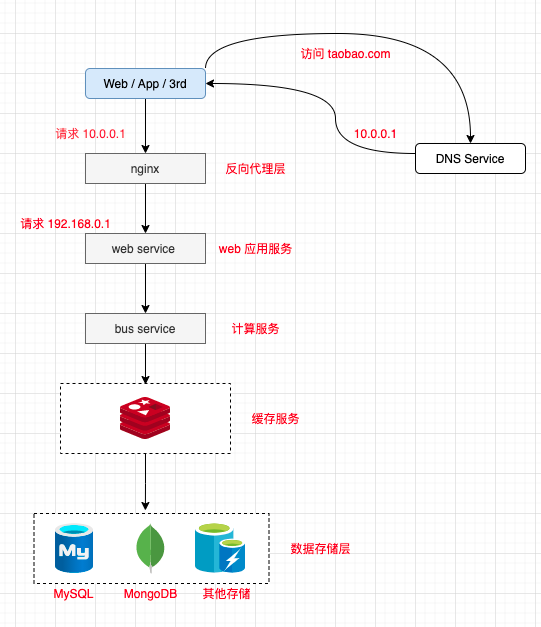
Client: 包括 Web 浏览器、App 应用、还有第三方请求。
Reverse Proxy:流量的入口,提供 反向代理、负载均衡 等能力的支持
Web Services: Web 服务层,处理业务逻辑,直接面向用户视觉,返回 HTML 页面、文档、Json 信息等
Computing Services:提供计算能力,所有繁琐的业务计算、数据存取、缓存存取。
Cache:缓存层,主要消耗内存,提供高效率数据存取。
Data:数据层,将数据持久化到硬盘。
如果要保证整个系统的高性能,那不是单纯对缓存层或数据层进行扩容的事情,就要求各层都可以水平扩展,下面我们一一来拆解下。
4 分层水平扩展架构实践
4.1 Reverse Proxy 的 Scale Out
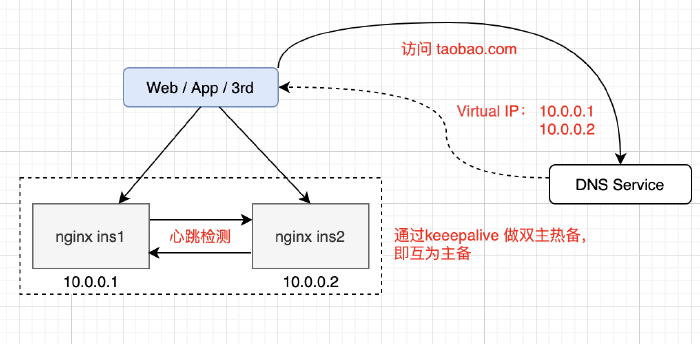
一般情况下,我们使用 Nginx 来实现 Load Balance(Random、Round Robin、Hash 等),但是单台 Nginx 照样存在宕机的风险。这时候我们就使用 DNS 轮询在 Nginx 上层做反向代理,一般会在一个域名上配置多个 IP 解析。当我们访问 DNS 服务的时候,他会轮询的返回 IP。而我们增加 Nginx 实例的时候,同时也在 DNS 服务上增配解析 IP,这样就达到理论上的无限扩容了。如图中,当我们有多个 Nginx 实例的时候,我们还可以配置 keepalive 做探活,以保证可用性。
4.2 Web Services 的 Scale Out
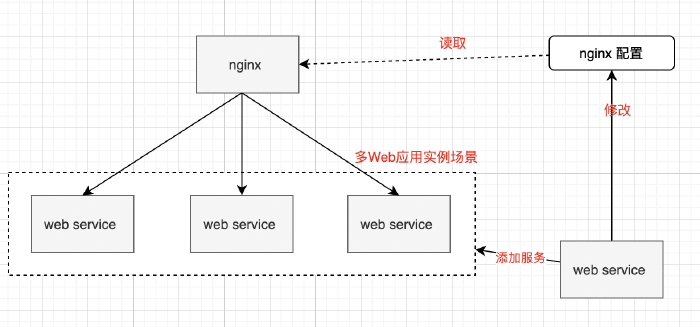
Web Services 的上层是 Nginx,他本身就是出色的负载均衡利器。当我们有多个服务实例的时候,只要在 Nginx 上 conf 文件上进行配置,就可以实现强大而稳定的负载了。而且对服务实例的新增和缩减,可以达到高效配置和快速扩缩的能力。Nginx 可以调度足够多的 Web Services 实例,实现互联网系统高并发运行。
4.3 Computing Services 的 Scale Out
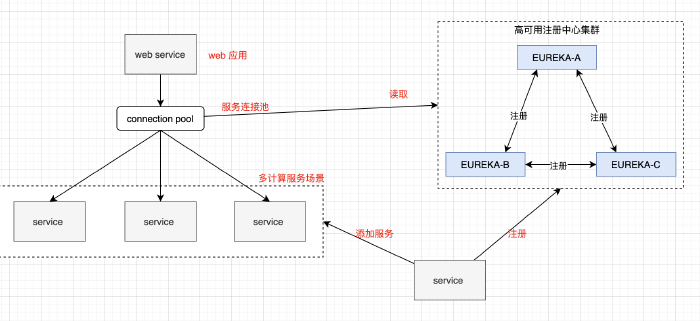
计算服务这一层的横向扩展,可以使用 命名服务(Name Server)模式进行处理。比如我们建立一个高可用的服务注册与发现中心。Alive 的计算服务实例都注册到服务中心去,Web 服务层则订阅服务中心,获取可用的计算服务,并执行调用。无论是使用 Rest API 调用,还是使用 RPC 调用,当你明显发现计算服务无法支撑逐渐上升的流量的时候(比如用户量暴涨、请求暴增),可以部署新的计算服务实例,并自动地注册到服务中心。实现平滑的动态的计算服务扩容相当优雅。另外,目前的服务间调用一般是去中心化的,会把订阅到的注册服务实例信息保存在本地(比如 Web 服务 把 计算服务地址 列表保存在本地),哪怕服务中心挂了,短时间内,也不影响请求的正常运转。
4.4 数据层 的 Scale Out
这个算老生长谈了,我们在 MySQL系列 和 Redis系列 中中已经不厌其烦的讨论过 缓存层 和 数据库层水平扩容的方式了。在互联网高速发展的今天,巨量的数据已经覆盖我们生活的每个角落,我们的衣食住行都是海量的数据进行支撑和管理。当我们的数据过于庞大的时候,一般会通过分库分表,来将数据库拆分到不同的实例,甚至服务器上,来达到存储层系统性能扩展的目的。《MySQL分库分表》中我们有详细说拆分的原理和方式,以 MySQL 为例,这边我们再做一下整理。一般有以下三种拆分方式:
4.4.1 按照 Range 水平拆分
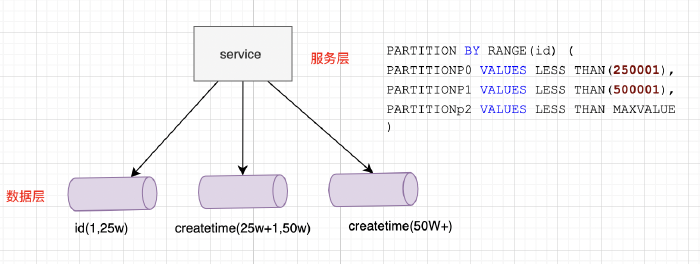
上面的示例,使用了范围 RANGE 函数对岗位编号进行分区,共分为 3 个分区,岗位编号为 1 ~ 25w 的对应在分区 P0 中,25w+1 ~ 50w 编号在分区 P1 中,依次类推即可,类别编号大于 50w 的数据统一存放在分区 P3 中即可。这种模式的优势是:
判断简单,只要对值进行判断一下,就能找到对应的存储分区;
区间自定义的情况下,可以比较均匀的分布数据。
扩展简单,当超过 50w 的数据比较多的时候,可以再加一个 id(50w,75w) 的分区。
可能存在的问题就是,各 Range 之间的请求压力可能不均衡,比如访问频率最高的用户数据可能都落在第 2 区间。
4.4.2 按照 HASH 水平拆分
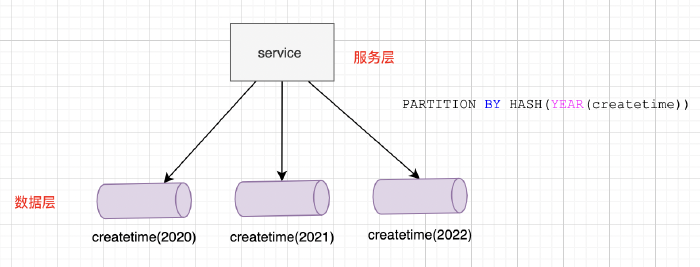
上面的例子,使用 HASH 函数对 createtime 日期进行 HASH 运算,并根据这个日期来分区数据,这里按照 年 为单位共分为 3 个分区。建表语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回整数的表达式,它可以是字段类型为 MySQL 整型的一列的名字,也可以是返回非负数的表达式。这种模式的优势是:
同样的,判断简单,只要对相应字段进行 hash 计算一下就可以了。
大部分情况下,数据分布也比较均匀,请求分布都可以比较均匀。比如你使用日期、性别等来 hash,得到的结果一般是比较均衡的。
缺点是:扩展性不佳,扩增一个数据实例,或者 hash 属性对应改变的时候,意味着你的数据所属区要重新划定,数据迁移是个不可缺少的成本。
4.4.3 按照 LIST(预定义列表)拆分

上面的例子,使用了列表匹配 LIST 函数对位置编号进行分区,共分为 2 个分区,编号为 46,77,89 的对应在分区 P0 中,106,125,177 类别在分区 P1 中。不同于 RANGE 的是,LIST 分区的数据必须匹配列表中的岗位编号才能进行分区,所以这种方式只是适合比较区间值确定并少量的情况。
不管是哪种模式,我们通过水平扩展,将数据分摊到不同的实例甚至服务器上,以此提升了数据库单实例的性能和稳定性。
5 总结
在大型互联网分布式系统的架构设计中,High Concurrency (高性能)、High Availability(高可用) 是构成的关键因素,我们通过精妙的设计,来保证系统能够同时并行处理足够多的请求、能够提高稳定持久服务的时间(n 个 9)、能够大幅降低事务处理时间。提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。Scale Up 是指单机硬件水平提升,如 CPU(多线程计算服务消耗大)、内存(缓存等)、GPU(音视频、直播类)、SSD 磁盘(数据存储等),升级到更高的配置,来提高并发性和可用性,但单机性能终归是有限的,不可能无限扩展。在我们上面的讨论中,我们通过对各层逐层的水平扩容来实践互联网系统保持高性能高可用性的可能性。
Reverse Proxy 通过 DNS 轮询 的方式实现 IP 解析的增配,以保证快速的扩容。
nginx 通过配置 conf 实现对上游 Web Services 的扩容和负载均衡。
Computing Services 通过服务注册中心实现新增服务实例的自动发现,保证水平扩容的高效和稳定。
数据层可以使用 数据库分区 来实现水平扩展。
原文链接:https://www.cnblogs.com/wzh2010/p/15730040.html
如果感觉本文对你有帮助,点赞关注支持一下,想要了解更多 Java 后端,大数据,算法领域最新资讯可以关注我公众号【架构师老毕】私信 666 还可获取更多 Java 后端,大数据,算法 PDF+大厂最新面试题整理+视频精讲

领取资料添加小助理vx:bjmsb2020 2020.12.19 加入
Java领域;架构知识;面试心得;互联网行业最新资讯








评论