
【大厂面试真题解析】虾皮 Shopee 后端一面十四问

关于我:微信公众号:面试官问,原创高质量面试题,始于面试题,但不止于面试题。【大厂面试真题解析】面试系列文章将会对大家实际面试中遇到的面试题进行汇总分析,以飨读者。
本文是作者 gopherhiro 近期面试 Shopee 被问到的问题,本文节选了其中通用的部分进行了解析,欢迎读者将面试中遇到的问题私信我,可以帮大家整理出回答的要点。
MySQL
1. 为什么要分库分表
单个数据库实例能够承载的并发访问量和数据量是有限的,当系统的并发访问量或者数据量超过这个限制时,就需要考虑使用分库分表来优化系统的架构设计,使其能够承载更大的并发量和数据量,并给用户提供良好的使用体验。当然,分库和分表其实是两个事情,两者并不是都会同时出现。
2. 分库解决了什么问题
分库主要解决的是并发量大的问题,因为单个数据库实例能够提供的连接数是有限的,当系统并发量不断增加,我们势必需要增加更多的微服务实例来承载更多的业务请求,而每个微服务实例都会占用一定量的数据库连接,因此,当数据库连接数不够用了,就只能通过增加数据库实例的方式来提供更多的数据库连接,进而提升系统整体的并发度。
3. 分表解决了什么问题
分表主要解决的是数据量大的问题,因为单表的数据量很大时,即使并发访问量不大,但单表的存储和查询的性能已经遭遇了瓶颈,通过索引优化等手段虽然能够一定程度上提升效率,但当单表数据量超过 500 万行或者单表存储容量超过 2GB(经验值,实际要看业务的具体情况) 之后,分表就应该提上日程了。一般都是将数据拆分到多张表中,来减少单表的数据量,从而提升查询的速度。
4. 乐观锁与悲观锁?在实践中是否用过,可否举例说明一下。
乐观锁实际上并没有加锁,只是一种锁思想,一般通过在行数据上添加版本号字段实现,在更新数据前,先查询出当前行数据的版本号,更新数据时,将版本号加 1,并判断数据库中版本号是否等于前面我们读取出来的版本号,如果不一致,说明数据被修改过,更新失败。乐观锁的核心语句是:update table set ... version=version+1 where id=#{id} and version=#{version};
乐观锁使用场景:比较适合读多写少的场景,因为如果出现大量的写入操作,version 字段值发生冲突的可能性就会增大,更新失败后,应用层需要不断的重新获取最新 version 字段数据,并重试操作,这样会增加大量的查询操作,降低了系统的吞吐量。
悲观锁一般是使用 select ... for update; 语句锁定行数据,更新完提交事务后自动释放行数据,在此期间,其他事务无法更新这一行数据。
悲观锁使用场景:比较适合写多读少的场景,因为如果出现大量的读取操作,每次读的时候都进行加锁,会增加大量的锁的开销,降低了系统的吞吐量。
5. 主键索引和唯一索引的区别?
MySQL 数据库索引按照功能进行划分,可以分为:
普通索引:没有任何的约束作用,它存在的主要意义就是提高查询效率。
唯一索引:在普通索引的基础上,增加了唯一性约束,要求索引列的值必须唯一,但可以为空值,一张表中可以同时存在多个唯一性索引
主键索引:在唯一性索引的基础上又增加了不为空的约束,而且一张表里最多只能有一个主键索引,但一个主键索引中可以包含多个字段。
全文索引:实际上用的不多,不做介绍
Redis
1. Redis 崩溃时,如何保证数据不丢失?
Redis 是一个内存键值对数据库,如果服务器进程挂掉,内存中的数据就会丢失,为了避免数据丢失,Redis 提供了三种持久化方案:
RDB 持久化:Redis DataBase,将内存中的数据以快照(二进制)的形式保存到磁盘上,是 Redis 默认的持久化方式。执行完 RDB 持久操作后,会在指定的目录中生成一个
dump.rdb文件,在 Redis 重启时,会加载dump.rdb文件来恢复数据到内存中。RDB 持久化可以通过手动和自动两种方式触发:手动方式:同步方式 save,会阻塞 Redis 主线程;异步方式 bgsave,会 fork 一个子进程,由子进程负责 RDB 文件的操作,避免阻塞 Redis 服务主进程
自动方式:save m n,当 m 秒内数据集发生 n 次修改时,自动触发 bgsave
AOF 持久化:Append Only File,基于日志来记录 Redis 的每个写操作,每个操作会追加到文件的末尾。Redis 默认不开启 AOF。需要注意的是,AOF 是在执行完 Redis 命令才记录日志的,而不是执行之前,因为 Redis 是不会对输入的命令进行语法检查的,因此,只有真正执行完命令后,才能避免将非法的命令写入 AOF 文件中。AOF 持久化方案有三种日志写回策略
appendfsync:always:同步执行日志写回,也就是在每个命令执行完之后,立即将日志写入 AOF 文件末尾
everysec:每隔一秒将 AOF 内存缓冲区中的日志刷新到磁盘中
no:Redis 只负责将日志写入到 AOF 内存缓冲区中,由操作系统的刷盘机制决定什么时候写入磁盘
混合持久化:RDB 方式的优点是文件相比 AOF 小,数据恢复快,适合大规模数据恢复场景,例如数据备份等;AOF 的优点是数据一致性和完整性相比 RDB 高,通常使用 everysec 写回策略保证只有秒级的数据丢失。为了中和两者的优缺点,Redis 4.0 引入了混合持久化,也就是在两次 RDB 持久化中间,会增加 AOF 操作来记录这段时间的日志。
2. Redis 基本数据类型及其使用场景有哪些?
Redis 有五种常用的基本数据类型:
字符串 String:不同微服务实例之间 session 共享,分布式锁、ID 生成器、计数器、限速器等
列表 List:实现消息队列功能,缓存文章列表信息等
哈希 Hash:缓存用户信息 UserInfo(可能包含 userId、userName、password、email 等字段)、实现短网址生成程序
集合 Set:存储用户的标签信息、唯一计数器、点赞等功能
有序集合 ZSet:实现排行榜、时间线等功能
3. Redis zset 数据类型底层是如何实现的?
Redis zset 底层数据结构有两种选型:压缩列表 ziplist 和跳表 skiplist,具体选择哪种数据结构要看当前存储的数据量和数据大小。当满足如下两个条件时,Redis 选择 ziplist 来实现 zset 值的存储:
所有数据的大小都要小于 64 字节
元素个数小于 128 个
当不满足以上两个条件时,则会选择使用 skiplist 来实现 zset 值的存储。
压缩列表是 Redis 自己设计的一种数据存储结构。它有点儿类似数组,通过一片连续的内存空间,来存储数据。不过,它跟数组不同的一点是,它允许存储的数据大小不同。

关于压缩列表更详细介绍可以参考极客时间的这篇文章:52 | 算法实战(一):剖析Redis常用数据类型对应的数据结构。
跳表 skiplist 是在单链表基础上增加了多级索引实现的一个数据结构,能够实现 O(logn) 时间复杂度的查找、插入和删除操作。
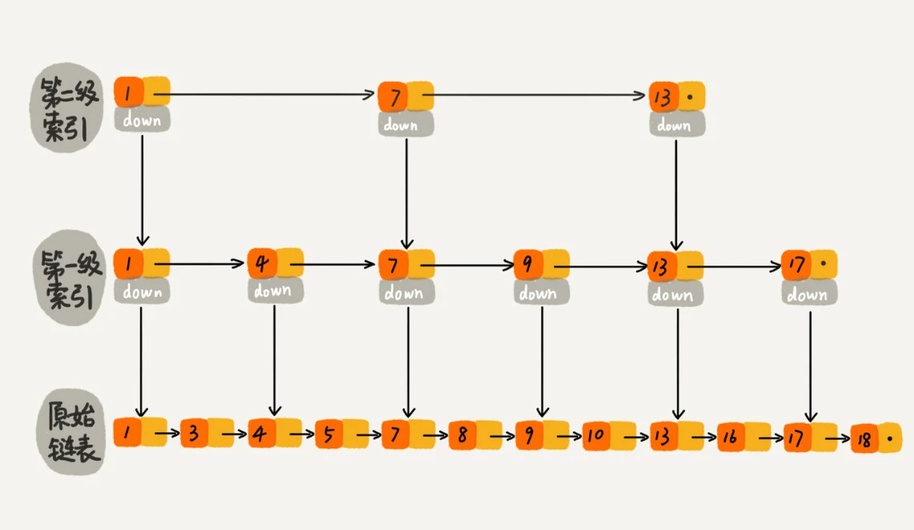
关于跳表更详细介绍可以参考极客时间的这篇文章:17 | 跳表:为什么Redis一定要用跳表来实现有序集合?。
4. Redis 分布式锁是如何实现的?
通过调用 Redis 命令 SETNX+EXPIRE 实现,同时为了保证原子性,可以通过 lua 脚本来实现锁的设置和过期时间设置的原子性。在 Redis 2.6.12 版本后,SETNX 命令增加了过期时间参数,也可以直接使用这个重载方法,SETNX 返回 1 表示获得 key 所代表的锁,返回 0 表示获取锁失败。
更多关于分布式锁的问题,可以参考场景化面试:关于分布式锁的十问十答这篇文章。
5. Redis 分布式锁过期了但业务还没有执行完,怎么办?
这种情况可以通过锁续约机制来解决,也就是通过另外一个线程使用心跳机制来不断延长锁的超时时间。
业务监控相关
1. 所做业务接口性能耗时是多少?
按你的系统实际回答即可,针对一般 OLTP 系统来说,接口耗时应该小于 500ms,对于高频接口,应该保证在 200ms 以内,具体还是要针对具体业务进行分析。
2. 所做业务 QPS 大致是多少?
这个主要是了解你的项目的并发情况,看你是否有高并发的相关经验,即使你的项目本身 QPS 不高,也应该准备下高并发相关的知识以便应对。
3. 如何理解 p 分位?如 p99,p95。
响应时间是指从前端发出请求开始到最后收到响应所需要的时间,对于互联网服务来说,响应时间我们更应该关注分位线,也就是常说的 TP95、TP99 或 95 线、99 线。
对于 TP95 而言,就是将对应接口所有请求的响应时间从小到大排序,位于 95% 这个位置的请求的响应时间,它表示至少有 95% 的请求响应时间小于等于这个值。
系统设计
1. 如何设计一个分布式 ID 生成器?
分布式 ID 必须保证全局唯一性,常见的方案有 UUID 和雪花算法(Snowflake)两种方案,但 UUID 相比雪花算法存在如下缺点,所以一般来说,我们都会选择雪花算法,并根据具体的业务场景进行改造:
UUID 生成的 id 是无序的,而 Snowflake 生成的 id 是有序的,id 有序能够支持排序,也能够提升数据的写入性能
UUID 不具备业务含义,但 Snowflake 具备业务含义,Snowflake 的核心思想是将 64bit 的二进制数字分成若干部分,每一部分都存储有特定含义的数据,标准的 Snowflake 算法包含 1 位符号位、41 位时间戳、10 位机器 id、12 位序列号,最终拼接生成全局唯一的有序 id。
通常来说,对 Snowflake 的改造是保持前面 42 位生成方式不变,调整后面的 22 位比特位,在其中加入业务相关的信息。
分布式 ID 生成器的算法确定后,我们可以将其作为一个 jar 包提供给业务方使用,或者也可以将其独立封装成一个基础服务对外提供 API。具体可以根据自己项目的实际情况确定。
关于分布式 ID 生成器更详细介绍可以参考极客时间的这篇文章:10 | 发号器:如何保证分库分表后ID的全局唯一性?。
版权声明: 本文为 InfoQ 作者【面试官问】的原创文章。
原文链接:【http://xie.infoq.cn/article/58cee287a1cdb3ee7c833b2fc】。文章转载请联系作者。

公众号:面试官问 2017.10.20 加入
还未添加个人简介









评论