如何用时序数据库 CTSDB 与 TARS 结合,解决海量监控数据难题

序言:9 月 4 日,阅文集团技术专家俞慧涛在 TARS 基金会召开的线上研讨会(中国站)上进行了题为“CTSDB 与 TARS 结合,解决海量监控数据的难题”的分享,对如何通过时序数据库 CTSDB 与 TARS 的结合解决海量监控数据难题的应用实践进行了深度诠释。腾源会将本演讲内容进行了整编,以飨读者:)
一、TARS 框架是什么?
TARS 是腾讯于 2017 年开源的一套微服务框架,涉及包括开发、运维、以及测试在内的一整套微服务架构系统开发和运维的解决方案。随着目前很多企业在业务体量数量以及微服务应用个数的规模化增长,监控数据也在呈现指数级增长态势。TARS 中包含的发布监控、日志统计等服务和工具,能帮助用户很好地解决服务健康程度监控、上报等问题。
但在实践过程中,我们也发现,TARS 的源生存储 MySQL 在查询大数据量时会有无法及时输出、多纬度聚合查询无法展示等问题。基于这一痛点,我们通过将腾讯时序数据库 CTSDB 与 TARS 结合的方式,解决了海量服务、海量监控以及监控输出相对较慢等问题。
在讲解我们的具体实践前,先和大家简单介绍下 TARS 这套框架 :
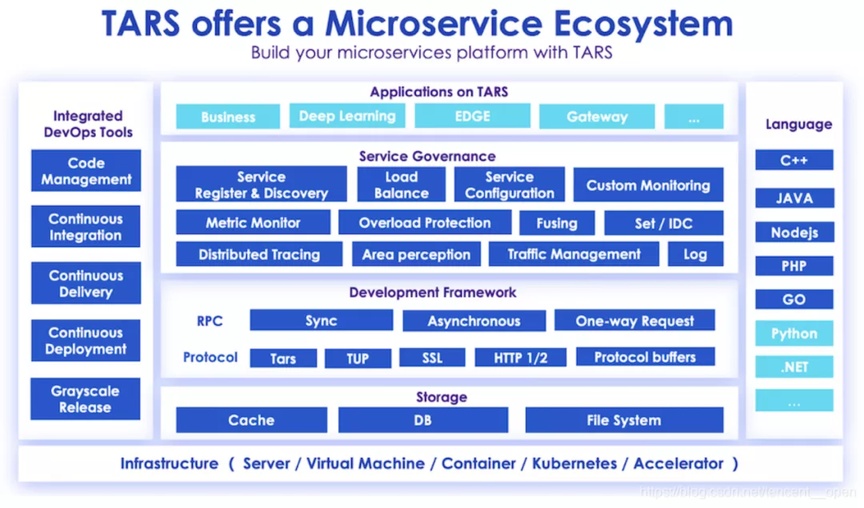
图 1:TARS 项目的微服务开源生态系统
TARS 提供的生态支持了多种编程语言,包括 C++、Golang、Java、Node.js、PHP 和 Python 等。在上层提供了深度学习和 API 网关等一些功能,下层服务包含了服务发现、服务负载、Set/IDC 、Traffic 和日志等功能。开发框架上有同步、异步、 TARS 协议、TUP 协议、SSL 协议、HTTP 协议和 Protocal buffers 协议,同时也支持 Cache 、DB、File System 等多种存储的功能。
二、TARS 框架中监控系统现在是怎么样的?
TARS 平台提供了多维度、多样化的服务监控及特性监控。从下方的服务监控页面可以看出,TARS 平台的服务监控选项包含了流量、平均耗时、异常率、超时率等,可以自由选择时间范围、主调方业务名、主调方 IP、被调方 IP、接口名,从而缩小监控范围,方便定位问题。
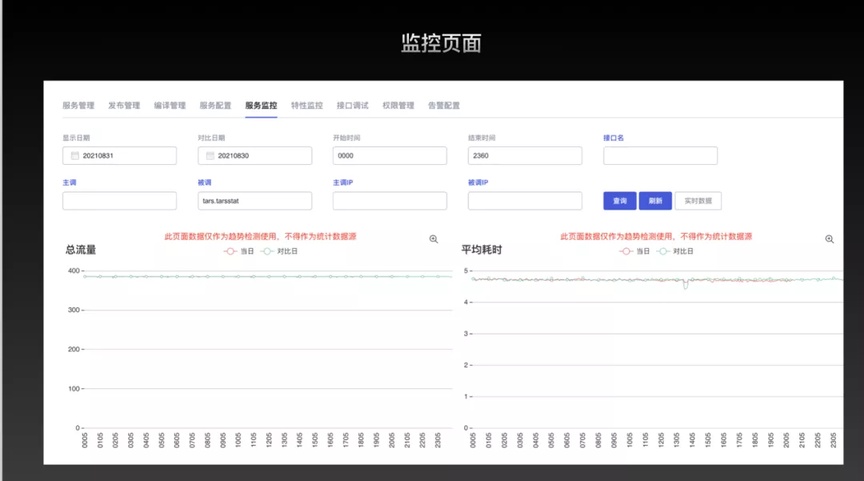
图 2:TARS 平台的服务监控页面
目前各个语言都提供了 Docker 部署(除此之外也支持物理机部署、Docker 部署、物理机和 Docker 混合部署),只需把代码仓库地址配置到 TARS 平台,就可以选择分支、选择编译器、编译、打包、分批发布部署到 TARS 平台上。
当 TARS 客户端收集完成所有数据后,会聚合写入本地内存中,最终上报到服务器,然后聚集写入到 MySQL 。所以在简洁清晰的流程和操作下,开发人员可以快速上手并维护这部分数据。
三、TARS 监控随规模增长,数据量成指数级增加
如果把微服务比喻成中国的大小河流,那么监控就是给各个河流的进出口,按每 5 分钟记录一次速度与水质数据 ,这数据随着河流的交错以相乘的方式几何级增长。传统的 MySQL 架构就像是所有的河流流向了一个小河一样,无法承载这样大的数据流量,最终会溢出 。
普通拆库拆表流程下还面临巨大的分析数据所产生的代码和运维维护成本高的问题,因为数据库扩容需要对表做拆解或者拆分到不同的服务上,难度较大、抗风险能力也比较低,处理起来十分复杂,所以目前暂时只支持一个数据库的写入。
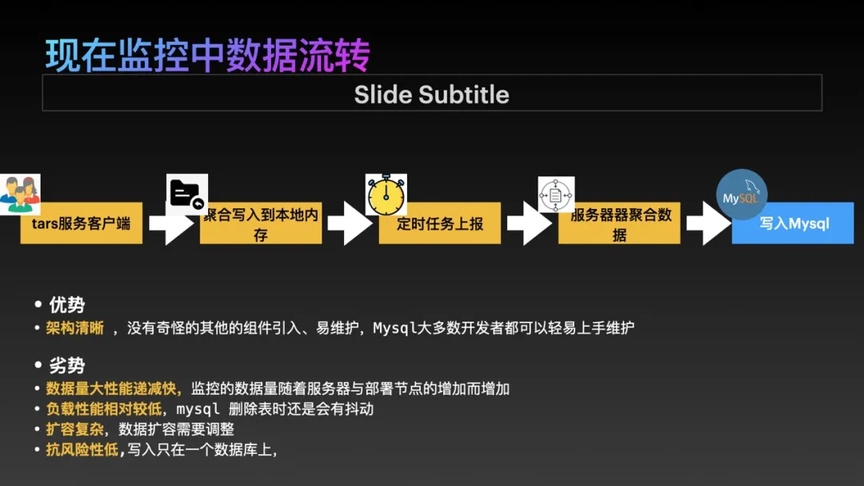
图 3:TARS 平台的监控数据流转
传统 MySQL 第二个问题是在大数据量下为了更快的多纬度查询更高效,会构建更多的索引来“ 加速”。主调被调与接口数量成乘积关系,数据量成倍数据增加且带上了主调被调的基础系数。
我们从下方的监控表 SQL 中就能发现这个问题:当索引使用 15~16 个维度的时候,插入速度会非常慢,索引占用磁盘空间也非常大。例如在现在的生产过程中,如果有超过了 1G 的监控数据,索引就需要占用将近 2~3 个 G 的内存,消耗了大量的内存,而且在数据和索引量都非常多的情况下,它的写入也会变得非常慢,这个时候在当前的服务特别多的情况下,我们从监控服务上就可以很清楚的看得到相关的信息。

图 4:TARS 监控 MySQL 数据库中监控表的索引定义
四、那有没有更好的办法可以去解决这些问题?
我们考虑过使用一些相对比较成熟的方案来解决现在我们的问题,其中就包括了 Elasticsearch 和 PostgreSQL 集群版本,但是很快就发现它们都存在一些问题而不能完全满足我们的需求:
Elasticsearch :不支持平台监控服务希望具备的冷热的概念,例如我们的大多数的需求都是希望请求当前 7 天的数据而很少有人会超过 7 天。
PostgreSQL:同样不支持冷热的概念,且当分析量较大时也会存在索引量特别大的问题。
所以在层层筛选和对比下,我们最终还是选择了腾讯云提供的具有时序功能的 CTSDB。
CTSDB 是基于 Elasticsearch 改造的版本,拥有多维度的数据分析和时序的功能,不仅能帮助我们自动淘汰相对时间比较久的一些数据,还能查询到最近 7 天到 10 天的热的数据库,也能顺利支持多个维度的分析。
4.1 CTSDB 的特点及优势
高并发写入:数据先写入内存,对于线上的批量写入比较友好。
低成本存储:通过数据上卷(Rollup),相比 MySQL 而言,能够更好的对历史数据做聚合,节省存储空间。不仅能支持 avg、min、max 等常用聚合方式,还支持 Group By、区间、Geo、嵌套等复杂聚合分析。
运维成本趋向于 0 :不需人工消耗大量时间处理数据。
4.2 CTSDB 的架构存储的亮点
高可用:专有主节点负责维护保障整个集群的健康状态,最大程度的保证了数据不会丢失。
高扩展性:随着业务发展和数据增长,节点的数量在 30 个节点保持最高状态。
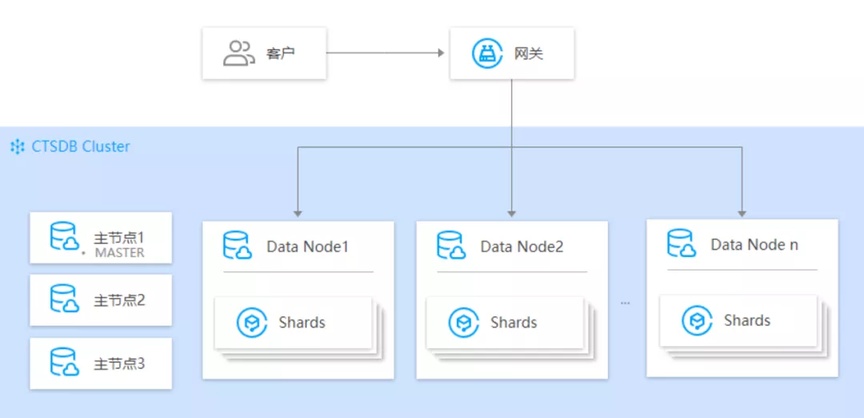
图 5:腾讯云 CTSDB 的架构图
五、在确认使用 CTSDB 后,我们如何去进行操作和替换呢?
我们选择了 TarsJava 重构了 Tars-QueryStat(查询) 与 Tars-querystat(写入)服务。目标是非常快速地替换这个服务并降低后续的查询维护的成本。目前 TarsStat 服务和 Tars-QueryStat 服务都是使用的 C++ 使用的 TARS 流做的数据的接入。新增加功能维护成本相对较高。
第二个非常重要的的原因是 Java 和 Elasticsearch 的协作非常的友好 。Java 语言 ElasticSearch 客户端可以直接连接到 CTSDB, 此客户端在商业应用上和开源的历史上拥有大量的成功的使用案例 。 所以以选择 TarsJava 重构 TarsStat 对我们而言就是一个非常好的选择。
六、如何实现一个连接到 CTSDB 的 TarsJava 服务
我们使用原 TarsStat 服务的 TARS IDL 文件生成 querystat 与 tarsstat 两个服务 Java 版本的接口与项目文件, 增加 tars.tarsstat.consumer 把原本请示的节点做 Hash 划分上报。这样做的好处是可以实现多点部署,避免单节点宕机而影响服务正常运营。同时,运算服务多节点部署可以帮助我们在数据量大且运算特别消耗 CPU 的情况下,实现快速扩容并不丢失监控数据。
当多个服务进行数据运算时可分担一部分数据写入和 CPU 的压力,而且能更快进行功能迭代(在之前部署时,使用原架构可能会存在一部分丢失,而目前最差情况也只是丢失其中的一部分)。
当然,我们目标也并不是为了替换掉原本 C++ 的服务,而是我们希望在查询和处理以及需求的产出能够得到相对比较好的平衡。
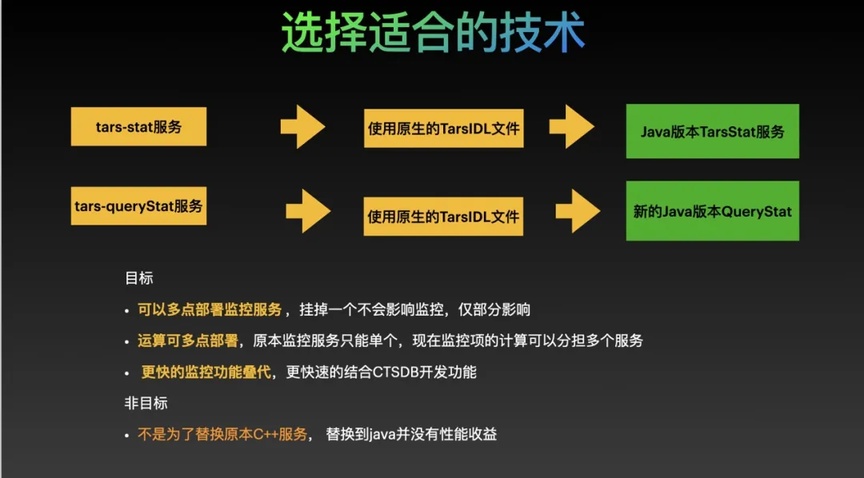
图 6:从原 TarsCpp 语言服务改造成 TarsJava 服务的流程
从下图中 ,原 TarsStat 的服务的数据结构已经设计的非常完美,实现自定义监控上报非常的容易。我们可以看到 TarsStat 的核心数据库和数据结构 StatMicMsgHead 和 StatMicMsgBody,它的接口是 reportMicMsg,最核心的结构体是 StatMicMsgBody 结构 , 它表示了聚合 5 分钟的数据统计结果 。接收上报报的数据接口仅一个。
查看 StatMicMsgHead 数据结构,数据结构中的核心字段有 MasterName(主调的服务名),SlaveName (被调的服务名)InterfaceName(被调的服务接口)等。
结构体 StatMicMsgBody 负责了数据图表展示与收集的工作。字段 count 是所有成功的调用量,字段 timeoutCount 是超时调用量,字段 execCount 是异常调用量。 在最终图表展现时,是以这样的模式去展现当前监控的数据的:count =成功调用量;超时量=timeoutCount/总 count+ timeoutCount 数。
这些数据结构非常的简单,StatMicMsgHead 也负责了主健 Key 的作用。由 10 个值组成的 1 个 key 和 7 个值来组成的 1 个 body 的数据统计。我们目前的所有的数据都是聚合的状态,而不是单个上报,因为如果监控和数据都用单点的方式上报,当它的数据有 100 个接口去请求时,对整个服务的消耗非常大,所以我们在框架设计时不会实时地上报所有的数据到监控的服务。

图 7:TarsStat 服务的数据结构与 IDL 描述文件
七、我们该如何实现多点 Hash 负载?
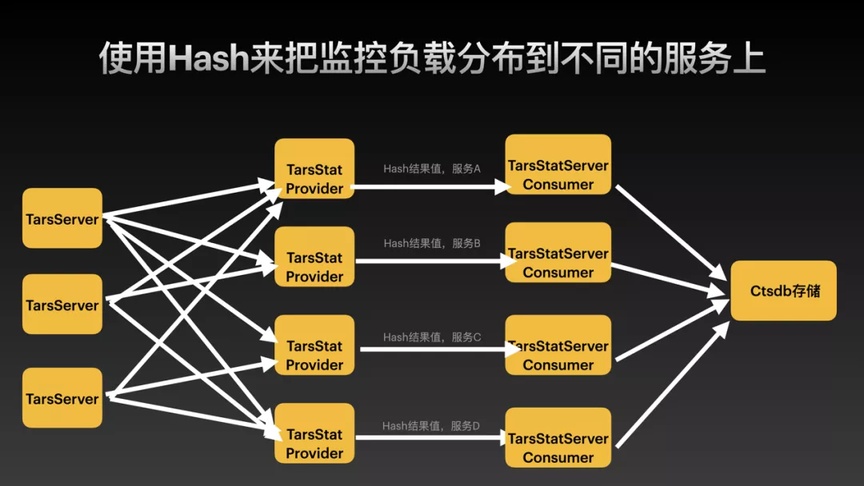
图 8:TarsJava Stat 服务 Hash 负载的设计
我们目前使用的框架自带 Hash 模式来请求目标的服务,原本整个请求到当前的服务,但是它宕机了服务也会受到影响。所以目前改造的方法是:
日志上报服务 tarsstat 增加一个 Provider Servant,Provider 使用 Hash 的方式 再去请求当前的服务新增加的 Consumer,Consumer 接收到 Hash 后的上报结果后,在内存中做累加统计表,并按 5 分钟任务周期存储到 CTSDB 。这种情况下最大的好处就是 consumer 只会收到一个服务的数据, 并不用加锁非常的高效,且在当前统计完结束以后就直接可以存入到 CTSDB, 不需要在 CTSDB 再做一层聚合,所以说 CTSDB 永远都只有写入没有聚合查询处理操作,另外在 consumer 里面去做聚合以后结束,也最大程度地保证了写入的效率和服务上报不会存在较大的延迟。
在核心方法上报的时候,我们使用是异步,增加了一个对应的数据分组上报到当前的服务。所以在最终处理好以后就有 3 个服务 stat(原本的话就只有一个),可以最大程度的保证即使其中一个出现问题,也可以马上回传所有监控信息,因为如果节点宕机了,它会继续重试,所以数据会自动快速恢复。
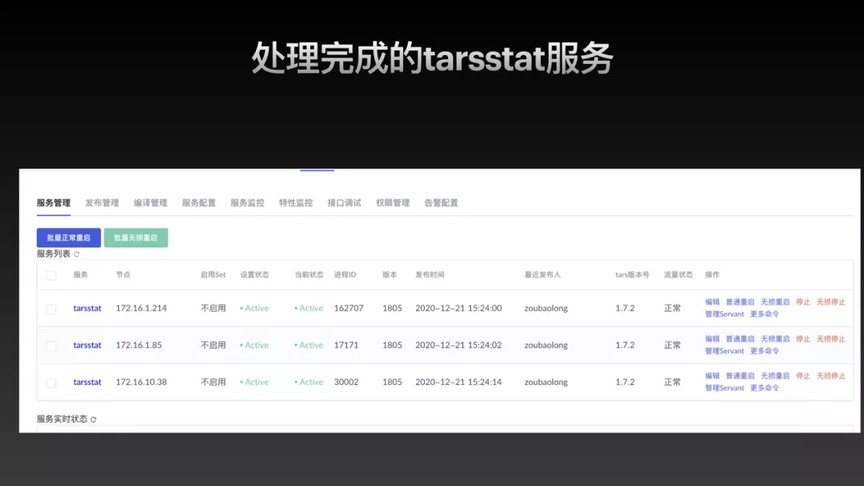
图 9:新上线的 TarsStat 服务部署到生产环境
从下图中可以看到之前我们所处理的其中一个 StateConsumer、StatObj。在 300 多个监控下,三秒不到就可以把所有的结果和排序全部都给找出来,不管你选择哪个维度,都能够非常快速的去展现所有的监控的一个结果。
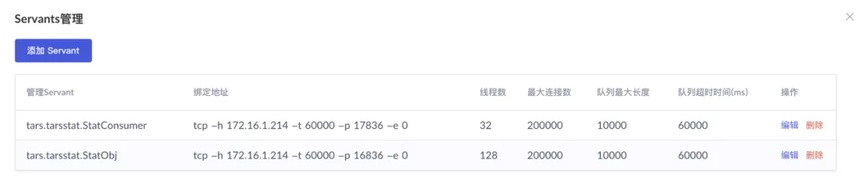
图 10:实际部署好的 Servant 名称
我的分享内容就是这些,如果有对 TARS 感兴趣或者希望更深的去了解和学习 TARS 的朋友,可以前往 TARS 的 B 站官方账号搜索包含 C++、Golang、Java、PHP 的入门部署以及 Demo 项目从 0~1 上手实践到发布等上手课程:https://space.bilibili.com/358991052 ,谢谢大家。


Believe in Open Source 2021.08.04 加入
腾源会是腾讯云成立的汇聚开源项目、开源爱好者、开源领导者的开放社区,致力于帮助开源项目健康成长、开源爱好者能交流协助、开源领导者能发挥领袖价值,让全球开源生态变得更加繁荣。









评论