5 年码农的我整理了 MyBatis 从入门到实战,想精通看这一篇就够了!

今日分享开始啦,请大家多多指教~
mybatis 简介
1 mybatis 是什么
MyBatis 是一款优秀的持久层框架
MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集的过程
MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 实体类 【Plain Old Java Objects,普通的 Java 对象】映射成数据库中的记录。
2 持久化和持久层
持久化
将原本存储在内存的临时数据保存到可永久化的存储设备中。
JDBC 就是一种持久化机制。文件 IO 也是一种持久化机制。
持久化的需要是因为内存的缺陷引起的
持久层
完成持久化工作的代码块 . ----> dao 层 【DAO (Data Access Object) 数据访问对象】
3 Mybatis 的优点
使 sql 与程序代码解耦合
灵活,不会对应用程序产生影响
mybatis 快速构建
为了方便使用可以安装 lombox 插件和 Free Mybatis plugn 插件
流程:pom 环境–>mybatis-configxml 配置文件–>工具类–>实体类–>接口–>接口实现类–>测试类
1.pom.xml
2.mybatis-config.xml
3.SqlSessionUtil 工具类(用于获取 session)

4.实体类 UserInf

5.接口 UserMapper
6.List<UserInf> selectUser();
接口实现 UserMapper.xml

别忘了在 Mybatis-config.xml 中注册

7.测试

mybatis 的增删改查
session.commit(); //提交事务,重点!不写的话不会提交到数据库
1 namespace 说明
namespace 命名空间作为在 mapper 中的属性之一,是 Mapper 接口与 xml 实现的唯一依据。
2 select
UserMapper 接口增加方法
//根据 id 查询用户
UserInf selectUserById(@Param("id")int id);
UserMapper.xml 增加方法对应映射

测试

3 insert
UserMapper 接口增加方法
//增加用户信息
int addUserInf(UserInf userInf);
UserMapper.xml 增加方法对应映射

测试

4 update
UserMapper 接口增加方法
//修改用户信息
int updateUserInf(UserInf userInf);
UserMapper.xml 增加方法对应映射

测试

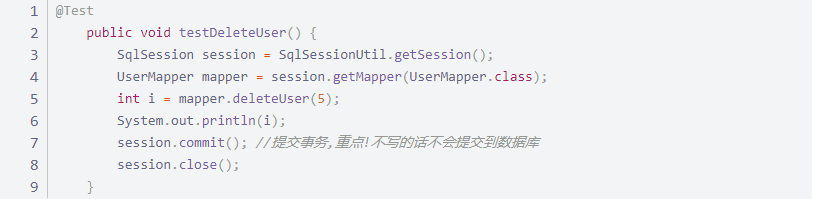
5 delete
UserMapper 接口增加方法
//根据 id 删除用户
int deleteUser(@Param("id")int id);
UserMapper.xml 增加方法对应映射

测试
6 模糊查询
第 1 种:在 Java 代码中添加 sql 通配符。

第 2 种:在 sql 语句中拼接通配符,会引起 sql 注入

7 注意点
所有的增删改操作都需要提交事务!
接口所有的普通参数,尽量都写上 @Param 参数,尤其是多个参数时,必须写上!
有时候根据业务的需求,可以考虑使用 map 传递参数!
为了规范操作,在 SQL 的配置文件中,我们尽量将 Parameter 参数和 resultType 都写上!
mybatis 配置详解
1 核心配置文件
mybatis-confifig.xml 系统核心配置文件
MyBatis 的配置文件包含了会深深影响 MyBatis 行为的设置和属性信息
一些属性和配置内容说明:
configuration(配置)
properties(属性)
settings(设置)
typeAliases(类型别名)
typeHandlers(类型处理器)
objectFactory(对象工厂)
plugins(插件)
environments(环境配置)
environment(环境变量)
transactionManager(事务管理器)
dataSource(数据源)
databaseIdProvider(数据库厂商标识)
mappers(映射器)
2 environments(环境配置)

根据生产上的要求,不同部门可能需要不同环境,可以配置多套环境,但是只能同时使用一个,且必须指定其中一个为默认运行环境(通过 default 指定)
子元素节点:environment
具体的一套环境,通过设置 id 进行区别,id 保证唯一!
子元素节点:transactionManager - [ 事务管理器 ]
MyBatis 中有两种类型的事务管理器(也就是 type="[JDBC|MANAGED]")在单独的 mybatis 中不需要进行额外配置
子元素节点:dataSource(数据源)
dataSource 元素使用标准的 JDBC 数据源接口来配置 JDBC 连接对象的资源。
有三种内建的数据源类型(type=“[UNPOOLED|POOLED|JNDI]"))
3 mappers(映射器)
映射器 : 定义映射 SQL 语句文件
3.1 引入资源的不同方式



3.2 Mapper 文件模板

4 properties(属性)
properties 属性可以利用配置文件或者 java 代码来动态更改
在多处中配置了属性时,propertie 中的值会被 resouce 中的覆盖,会被 java 代码中的方法传参覆盖。
可以采用占位符的形式来配置属性默认值官方文档
4.1 使用配置文件优化
新建 config.properties
导入配置文件并占位符显示属性值

5 typeAliases(别名)
为解决包名过长问题的代码冗余。
第一种方式

在所有使用 com.lyj.entity.UserInf 的地方都可以用 User 代替
第二种方式

在 com.lyj.entity 包下的所有实体类都可以使用类名首字母小写的方式引用(如 com.lyj.entity.UserInf 用 userInf 代替)
也可以在实体类加上注解的方式自定义别名
@Alias("user")
public class UserInf { ... }
6 settings(设置)
可以为 mybatis 增加设置
数据库驼峰名转换设置

log 日志设置显示
<setting name="logImpl" value="STDOUT_LOGGING"/>
ResultMap(结果集映射)
为了解决数据映射问题而生
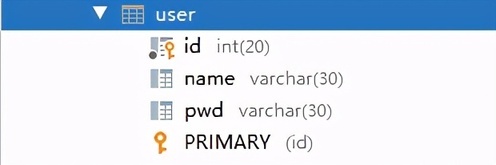
1 解决数据库与实体类属性名不一致问题
解决的问题:属性名和字段名不一致
因为各种原因,数据库的属性字段无法和实体类的属性字段一一对应。
举例:
现在数据库表属性为:
实体类属性值为:

查询语句:

这样查询,因为 pwd 在实体类中并不存在,在注入值时无法注入。出现 password 属性为空的情况。
解决方案
使用别名(可简写 pwd password)

使用结果集映射->ResultMap 【推荐】

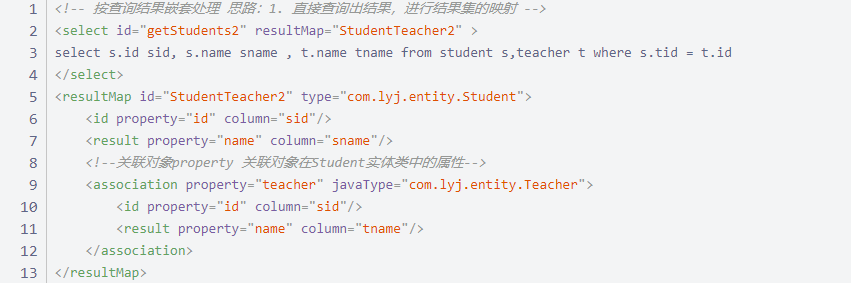
2 解决多对一结果集映射(association 关联属性)
多对一理解:
多个学生对应一个老师。
数据库概念理解:学生拥有一个 tid 与教师 id 对应。
实体类概念理解:学生拥有一个教师对象。
2.1 按查询嵌套处理
实体类 student 和 teacher

StudentMapper 增加接口
//查询所有学生
public List<Student> queryAllStudents();
StudentMapper.xml 增加对应方法(对于对象属性 teacher 采用关联属性)

测试(对于对象属性 teacher 的属性采用关联属性)

2.2 按结果嵌套处理。
3 解决一对多结果集映射(collection 集合)
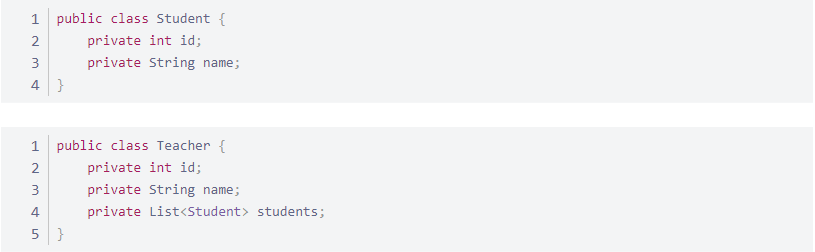
一对多理解:
一个老师有多个学生
数据库概念理解:教师拥有一个 id 与学生 tid 对应。
实体类概念理解:教师拥有一个学生对象 List 集合。
3.1 按查询嵌套处理。
实体类 Student 和 Teacher
TeacherMapper 增加方法
public Teacher getTeacher(int id);
TeacherMapper.xml 增加实现

测试
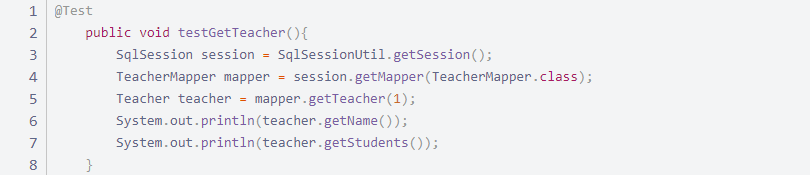
3.2 按结果嵌套处理

动态 SQL
动态 SQL 指的是根据不同的查询条件 , 生成不同的 Sql 语句。
1 环境
utils 工具类:随机生成 id

entity 实体类

其他正常布置,数据库添加数据。
2 if 语句
需求:根据作者名字和博客名字来查询博客!如果作者名字为空,那么只根据博客名字查询,反之,则根据作者名来查询
xml 文件实现
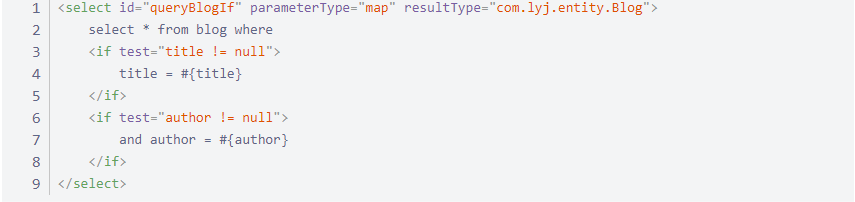
注意:在依次执行所有的 if 语句,因此当 title 为空,author 不为空时,产生错误。引入 where
3 where 语句
xml 文件实现
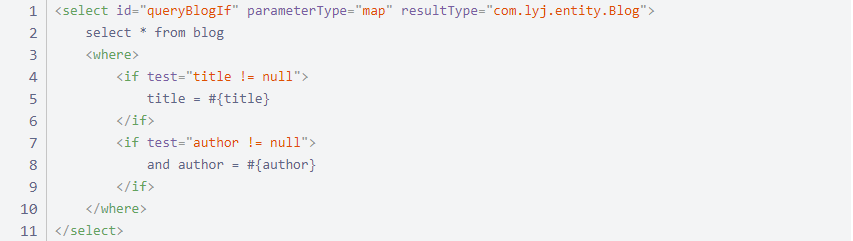
注意:当 where 包含的标签有返回值时能够自动加上 where 字符,同时当检测标签开头含有 AND 或 OR 字符时,会将字符除去。
4 choose 语句
利用 if 和 where 搭配已经能够解决大部分的 SQL 查询拼接,但是有时候我们需要某一个条件不为空时立即跳出不在接受参数。这个时候我们可以利用 choose 实现,相当于编程语言中的 switch。
xml 实现:

读起来十分有 switch-case-otherwise 的既视感。
5 foreach 语句
foreach 相当于 for 循环,当我们需要一次性查询多个内容时,可以用 foreach 来实现这一功能。

测试:

相当于 SQL 语句:select * from blog where (id=1 or id=2 or id=3)
6 set 语句
当我们需要进行修改操作时,set 的操作配合 if 使用会现之前查询出现的问题。
不用 set 标签之前,当 author 为空时,名=SQL 语句拼接就会出错,这个时候使用 set 标签可以很好的解决这个问题。

使用 set 标签后

**set 标签的功能和 where 类似,先是内部标签有返回值时会自动补充 set 字符,当内部标签结尾含有,字符时,会自动去除 **
7 SQL 片段
在正常的数据查询流程中,直接使用 select *对数据安全来说无疑是十分危险的,我们会使用字段的形式来代替这种方式,但是字段过多的情况下,每次重复的复制代码过于麻烦且不容易维护。这个时候自定义 SQL 片段可以很好的解决这个问题。

sql 标签和 incloud 标签配合使用很好的实现了这个功能。
日志工厂与分页
1 日志工厂
mybatis 可以通过配置日志的方式来过程信息,可以采用自带的日志工厂,也可以用第三方包。
Mybatis 内置的日志工厂提供日志功能,具体的日志实现有以下几种工具:
SLF4J
Apache Commons Logging
Log4j 2
Log4j
JDK logging
标准日志实现:

2 Log4j
通过使用 Log4j,我们可以控制日志信息输送的目的地:控制台,文本,GUI 组件…
我们也可以控制每一条日志的输出格式;
使用:
导包

更改日志工厂设置

新建配置文件 log4j.properties

使用

**注意:**log4j 导包使用的是 apache 的包,会自动在当前目录生成一个 log 文件夹,可以显示 log 记录。
3 limit 实现分页
**分页:**记得以前一个 javaweb 项目当中,老师要求使用 java 代码来实习分页查询。那个时候是使用了一个工具类来专门处理分页逻辑,现在回顾过去,也不是十分困难。
主要有两个方法,一是在 MySQL 层次上处理,另一个是在 java 代码层次上。
3.1 分页实现
mysql 语法:

步骤:
SQL 语句

如果我们有很多种不同的分页类型,为每一个不同的类型写不同的工具类就会让代码十分的冗余,用泛型可以解决这一问题。
blog 实体类

PageModel 泛型类,来实现一个基本的分页数据。

如果想要在 PageModel 的基础上加上具有不同分页特色的数据,那么可以用继承来实现。

工具类处理
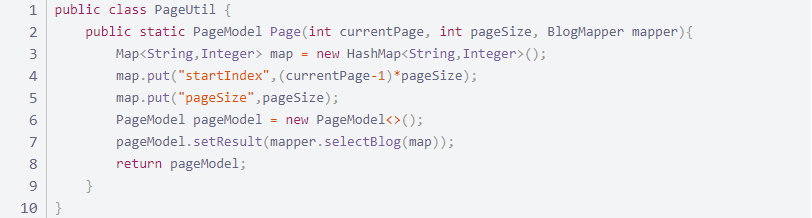
测试类

之前以为这样就完成了分页,没想到始终无法将 Mapper 抽象出来,这个分页是不合格的。
3.2 RowBounds 分页
使用方法
3.3 PageHelper
使用方法
mybatis 缓存
1 简介
什么是缓存 [ Cache ]?
存在内存中的临时数据。
将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。
为什么使用缓存?
减少和数据库的交互次数,减少系统开销,提高系统效率。
什么样的数据能使用缓存?
经常查询并且不经常改变的数据。
2 Mybatis 缓存
MyBatis 包含一个非常强大的查询缓存特性,它可以非常方便地定制和配置缓存。缓存可以极大地提升查询效率。
MyBatis 系统中默认定义了两级缓存:一级缓存和二级缓存
默认情况下,只有一级缓存开启。(SqlSession 级别的缓存,也称为本地缓存)
二级缓存需要手动开启和配置,它是基于 namespace 级别的缓存。
为了提高扩展性,MyBatis 定义了缓存接口 Cache。我们可以通过实现 Cache 接口来自定义二级缓存
3 一级缓存
一级缓存也称为本地缓存。
默认开启的。
SqlSession 级别的缓存。
在同一个 session 中我们执行同一个查询,将不会重复的去 sql 读取,而是从缓存中去读取。
3.1 一级缓存失效的四种情况
sqlSession 不同
sqlSession 相同,查询条件不同
sqlSession 相同,两次查询之间执行了增删改操作!
sqlSession 相同,手动清除一级缓存。
session.clearCache();//手动清除缓存
4 二级缓存
二级缓存也叫全局缓存,一级缓存作用域太低了,所以诞生了二级缓存
基于 namespace 级别的缓存,一个名称空间,对应一个二级缓存;
工作机制
一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中;
如果当前会话关闭了,这个会话对应的一级缓存就没了;但是我们想要的是,会话关闭了,一 级缓存中的数据被保存到二级缓存中;
新的会话查询信息,就可以从二级缓存中获取内容。
不同的 mapper 查出的数据会放在自己对应的缓存(map)中;
4.1 二级缓存的使用
mybatis-config.xml 开启全局缓存

在要开启缓存的 namespace 缓存配置官方文档
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
#这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
测试
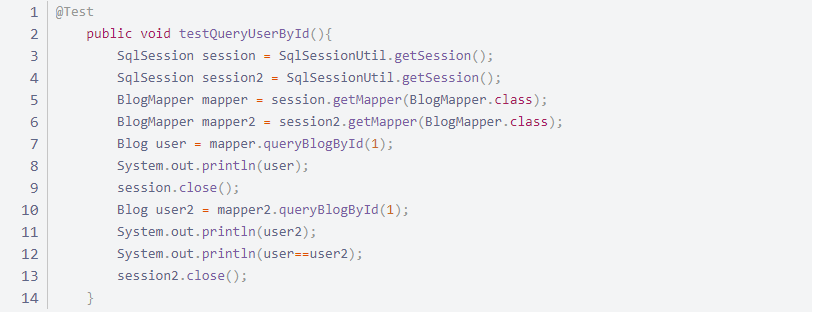
只有 session 结束之后,数据才会从一级缓存中存放到二级缓存中去。
5 第三方缓存 EhCache
导入相应依赖

在对应的 mapper 配置文件中开启 EhCache。
<cache type = "org.mybatis.caches.ehcache.EhcacheCache" />
新建一个 ehcache.xml 文件
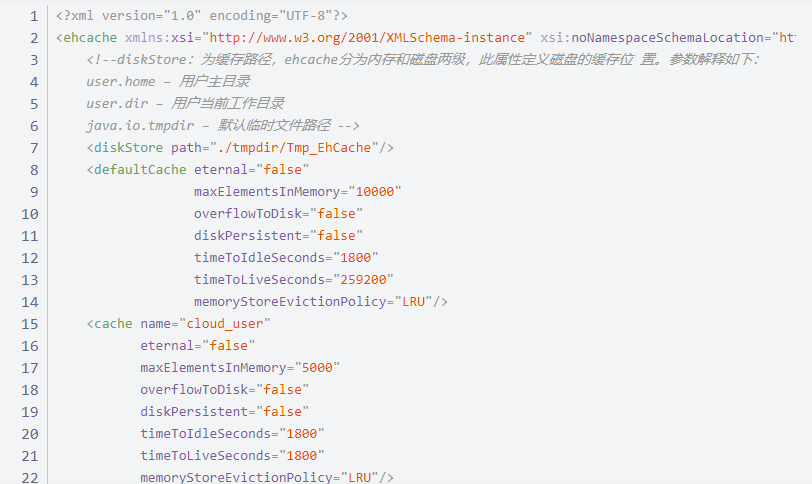
今日份分享已结束,请大家多多包涵和指点!

还未添加个人签名 2021.04.20 加入
Java工具与相关资料获取等WX: gsh950924(备注来源)









评论