原来
Amazon Karpenter 是亚马逊云科技 2021 re:Invent 大会上正式发布的针对 Kubernetes 集群一直以来不断扩展的组件中。在 Kubernetes 集群中的组件可以针对 Unscheduleable Pod 的需求,自动创建节点的新节点并加入。由于在 Kubernetes 集群中会使用 Cluster AutoScaler (CA) 组件来进行节点的弹性缩放,通过对节点组(节点组,即在亚马逊云科技上的实现为 EC2 Auto Scaling Group)的大小进行动态调整来确定相对而言,亚马逊更倾向于选择彻底抛弃了节点的实现,EC2 Fleet API 直接进行节点管理,因此可以灵活地选择合适的 Amazon EC2 型号、可用区域和选项组。 (如需求或 SPOT)等,在集群中的卡彭特。
Amazon Karpenter 目前已经可以生产了,已经有用户开始利用 Amazon Karpenter 这个亚马逊云科技的 EKS 集群在一个 GPU 上进行节点管理。在博客中我们会以 GPU 推理的场景为示例,详细说明 Amazon Karpenter 的工作原理、配置过程以及测试效果。
架构描述
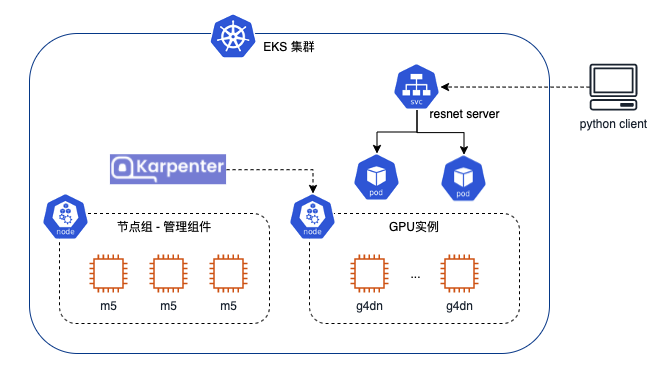
在这个博客里我们会使用 EKS 构建一个 Kubernetes 集群:
可以看到在 Kubernetes 组和中,我们会先创建一个节点部署管理组件,部署 CoreDNS,Amazon Load Balancer Controller Amazon Karpenter 等管理组件。一般来说管理组件所需要的资源比较固定,我们可以提前设置预想好相关组件所需要的资源,并考虑跨可用区、高可用等因素后,该确定节点组的类型和数量。
我们会自动管理这些直播服务所需要的这些主要实例。Amazon Karer 的任务为 Unsh Amazon Pod 创建的节点,将在这些 Pod EC 使用 Amazon EC 调度节点的时候使用 Pod 节点 Amazon Karpent 将根据需要的资源请求(如 Pod 的资源请求)、亲和性设置(如 Pod Affinity 等)计算出符合要求的节点类型和、数量在这个示例工作组中,提前进行组节点类型计划由我们为 GPU 实例创建单独的组和配置 C 组资源自动缩放器来进行,Karpenter 来自动完成。
我们会部署一个推理服务(resnet 服务器),最后由多个 Pod 组成,每个 Pod 都可以独立进行工作,通过服务暴露到 EKS 外部。通过一个 Python 客户端,我们可以提交一张图片到结合自动生成服务器部署的时间,可以配置前端的变化,HPA Po 的自动对大小的变化进行了缩放真正实现节点的弹性缩微。
考虑,考虑到我们会以负载均衡器提前暴露服务,因此在示例中会部署亚马逊负载均衡器控制器,来根据服务创建网络负载均衡器。
部署与测试
我们会按照上述架构进行部署,整体指挥的部署过程如下:
1、创建 EKS GPU 推理协会
使用 eksctl 工具来进行指挥 EKS 的创建。
首先将类别名称、区域、变量等信息配置到环境时,可用于各种 ID 名称、区域、变量等信息配置时使用:
export CLUSTER_NAME="karpenter-cluster"export AWS_REGION="us-west-2"export AWS_ACCOUNT_ID="$(aws sts get-caller-identity --query Account --output text)"
复制代码
左滑查看更多
准备组的配置文件以供 eksctl 使用工具:
cat << EOF > cluster.yamlapiVersion: eksctl.io/v1alpha5kind: ClusterConfig
metadata: name: ${CLUSTER_NAME} region: ${AWS_REGION} version: "1.21" tags: karpenter.sh/discovery: ${CLUSTER_NAME}
iam: withOIDC: true
managedNodeGroups: - name: ng-1 privateNetworking: true instanceType: m5.large desiredCapacity: 3EOF
复制代码
左滑查看更多
通过以上配置文件创建 EKS 集群:
eksctl 创建集群 -f cluster.yaml
eksct 能够按设置设备组和设备组,在 5 个作为部分配置并创建了控制器组与使用组,Amazon 负载均衡器的部署节点,以便 GPU 任务组。
Endpoint 环境变量以供配置使用 Amazon Karpenter
export CLUSTER_ENDPOINT="$(aws eks describe-cluster --name ${CLUSTER_NAME} --query "cluster.endpoint" --output text)"
复制代码
左滑查看更多
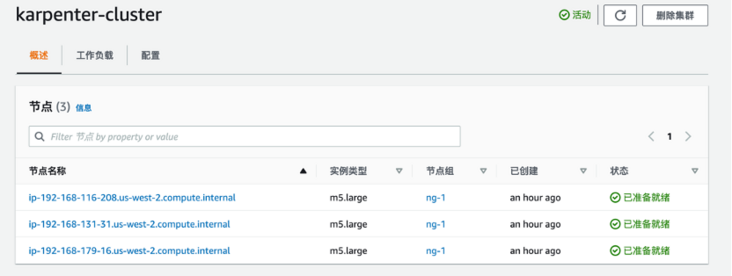
节点状态是否都已经准备好查看状态:
2、安装 Amazon Karpenter
博客写作时,Karpenter 版本为最新版本 6.3,在此部署 Amazon Karpenter 版本的安装过程进行整理,读者可以根据需要在 Amazon Karpenter 官网操作的安装过程指南:
首先需要创建配置文件,配置相应的权限,以便 Amazon Karpenter 启动的实例可以有可能的权限进行网络配置和进行镜像拉取等动作:
TEMPOUT=$(mktemp)curl -fsSL https://karpenter.sh/v0.6.3/getting-started/cloudformation.yaml > $TEMPOUT \&& aws cloudformation deploy \ --stack-name "Karpenter-${CLUSTER_NAME}" \ --template-file "${TEMPOUT}" \ --capabilities CAPABILITY_NAMED_IAM \ --parameter-overrides "ClusterName=${CLUSTER_NAME}"
复制代码
左滑查看更多
有权配置访问权限,以便 Amazon Karpenter 创建的实例可以有权限连接到 EKS 集群:
eksctl create iamidentitymapping \ --username system:node:{{EC2PrivateDNSName}} \ --cluster "${CLUSTER_NAME}" \ --arn "arn:aws:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}" \ --group system:bootstrappers \ --group system:nodes
复制代码
左滑查看更多
为 Karpenter 控制器创建 IAM 角色和服务帐户:
eksctl utils associate-iam-oidc-provider --cluster ${CLUSTER_NAME} –approveeksctl create iamserviceaccount \ --cluster "${CLUSTER_NAME}" --name karpenter --namespace karpenter \ --role-name "${CLUSTER_NAME}-karpenter" \ --attach-policy-arn "arn:aws:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerPolicy-${CLUSTER_NAME}" \ --role-only \ --approve
复制代码
左滑查看更多
配置环境变量以供安装 Amazon Karpenter 使用:
export KARPENTER_IAM_ROLE_ARN="arn:aws:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"
复制代码
左滑查看更多
最后通过 Helm 来安装 karpenter:
helm repo add karpenter https://charts.karpenter.sh/helm repo updatehelm upgrade --install --namespace karpenter --create-namespace \ karpenter karpenter/karpenter \ --version v0.6.3 \ --set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"=${KARPENTER_IAM_ROLE_ARN} \ --set clusterName=${CLUSTER_NAME} \ --set clusterEndpoint=${CLUSTER_ENDPOINT} \ --set aws.defaultInstanceProfile=KarpenterNodeInstanceProfile-${CLUSTER_NAME} \ --set logLevel=debug \ --wait
复制代码
左滑查看更多
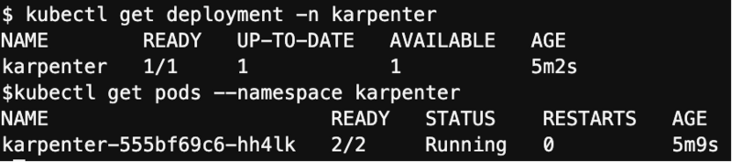
检查 Karenter Controller 是否已经正常运行:
3、配置 Karpenter Provisioner
当 Kubernetes 需要在中出现 Unscheduleable Pod 的时候,Amazon Karpenter 通过 visioner 来确定所创建的 EC2 实例和大小。Amazon Karpenter 安装的时间会定义一个命名 Provisioner 的自定义资源。因为 Karpenter Provisioner 处理多个 Pod Amazon Karpent 根据 Pod 和置备布点等不同属性调度器组,使用 Amazon Karpent 额外管理多个节点。
创建 Provisioner 的配置文件:
cat << EOF > provisioner.yamlapiVersion: karpenter.sh/v1alpha5kind: Provisionermetadata: name: gpuspec: requirements: - key: karpenter.sh/capacity-type operator: In values: ["on-demand"] - key: node.kubernetes.io/instance-type operator: In values: ["g4dn.xlarge", "g4dn.2xlarge"] taints: - key: nvidia.com/gpu effect: "NoSchedule" limits: resources: gpu: 100 provider: subnetSelector: karpenter.sh/discovery: karpenter-cluster securityGroupSelector: kubernetes.io/cluster/karpenter-cluster: owned ttlSecondsAfterEmpty: 30EOF
复制代码
左滑查看更多
在这个配置文件里,我们在规范中指定了我们创建的购买选项和实例类型。我们在spec.requirements中将 karpenter.sh/capacity-type 中指定为 on-demand。 同时,由于这是一个机器学习的推理应用,我们也将这里的实例类型定义为 G4,我们选择 g4dn.xlarge 和g4dn .2x大大小。另外我们也设置了 taints nvidia.com/gpu可以看到,Pod 2 可能无法部署这些 Pod 的推断,也需要在这个 Provisioner 提供一个实例的实例。会创建出 GPU 实例。
另外,我们也可以通过这个环境部署的资源配置器,在这个环境中设置我们的 gpu 设置。同时可以创建 100 子网选择器和安全组选择器的标签来找到 Povisioner 如何去设置新的实例。的 VPC 子网和安全组。
在 Emp tttSecondsAfterEmpty 来告诉 Provisioner 来最后清理一下 Amazon2 的备用闲置实例 30,通过这个当创建的 Amazon EC2 实例去掉配置 30 秒后 EC 运行时没有任何成本,Provisioner 会要求 EC 运行时没有任何成本资源并直接进行回收,也就是终止 EC2 实例。
关于 Provisioners 的详细配置可以参考官网上的文档。
我们就使用这个配置文件创建授权 Provisioner:
kubectl apply -f provisioner.yaml
4、安装 Amazon Loadbalancer Controller
在这个演示中我们会使用 Amazon Loadbalancer Controller 来自动为服务创建 NLB,可以参考亚马逊云科技官网查看详细的安装步骤,这里简要记录下 2.4.0 版本的安装过程:
curl -o iam_policy.json https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/v2.4.0/docs/install/iam_policy.json
aws iam create-policy \ --policy-name AWSLoadBalancerControllerIAMPolicy \ --policy-document file://iam_policy.json
eksctl create iamserviceaccount \ --cluster=${CLUSTER_NAME} \ --namespace=kube-system \ --name=aws-load-balancer-controller \ --attach-policy-arn=arn:aws:iam::${AWS_ACCOUNT_ID}:policy/AWSLoadBalancerControllerIAMPolicy \ --override-existing-serviceaccounts \ --approve
helm repo add eks https://aws.github.io/eks-charts helm repo update helm install aws-load-balancer-controller eks/aws-load-balancer-controller \ -n kube-system \ --set clusterName=${CLUSTER_NAME} \ --set serviceAccount.create=false \ --set serviceAccount.name=aws-load-balancer-controller
复制代码
左滑查看更多
5、部署机器学习推理应用
该示例将部署一个学习推理应用我们作为示例。这个示例来自一个 EKS 上进行 vGPU 部署的示例。该示例会部署一个基于 ResNet 的博客的图片推理服务并通过负载均衡发布一个服务地址,使用一个 Python 编写的客户端将上传给这个推理服务获得推理结果。这里并进行了图片配置,而不是讨论 vGPU 的 GPU,直接让这个推理服务使用 G4 实例的 GPU。
这里是修改后的推理服务的部署/服务的部署文件:
cat << EOF > resnet.yamlapiVersion: apps/v1kind: Deploymentmetadata: name: resnetspec: replicas: 1 selector: matchLabels: app: resnet-server template: metadata: labels: app: resnet-server spec: # hostIPC is required for MPS communication hostIPC: true containers: - name: resnet-container image: seedjeffwan/tensorflow-serving-gpu:resnet args: - --per_process_gpu_memory_fraction=0.2 env: - name: MODEL_NAME value: resnet ports: - containerPort: 8501 # Use gpu resource here resources: requests: nvidia.com/gpu: 1 limits: nvidia.com/gpu: 1 volumeMounts: - name: nvidia-mps mountPath: /tmp/nvidia-mps volumes: - name: nvidia-mps hostPath: path: /tmp/nvidia-mps tolerations: - key: nvidia.com/gpu effect: "NoSchedule"---apiVersion: v1kind: Servicemetadata: name: resnet-service annotations: service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing service.beta.kubernetes.io/aws-load-balancer-type: external service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ipspec: type: LoadBalancer selector: app: resnet-server ports: - port: 8501 targetPort: 8501EOF
复制代码
左滑查看更多
可以看到在部署中设置了推理服务所的 GPU 资源,以及对污点 nvidia.com/gpu 的 Gpu 的我们需要根据这些信息来进行实例 4 的创建。另外在服务中也定义了相应的的注解,以便使用 Amazon Load Balancer Controller 来自动创建一个公网可访问的 Network Load Balancer 。
部署完成后,可以检查相应资源是否都运行正常:
检查自动生成的 NLB,该地址可以供客户端访问:
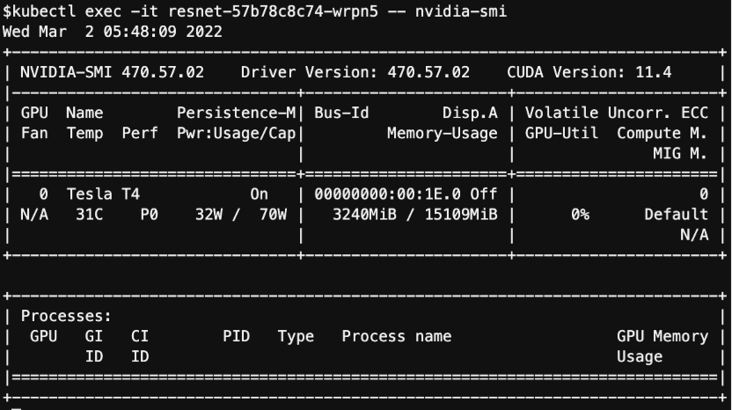
通过kubectl exec -it <podname> -- nvidia-smi查看 GPU 容器状态
我们部署一个代码客户端,如下是相应的 Python 输出,保存为: resnet_client.py
from __future__ import print_function
import base64import requestsimport sys
assert (len(sys.argv) == 2), "Usage: resnet_client.py SERVER_URL"# The server URL specifies the endpoint of your server running the ResNet# model with the name "resnet" and using the predict interface.SERVER_URL = f'http://{sys.argv[1]}:8501/v1/models/resnet:predict'# The image URL is the location of the image we should send to the serverIMAGE_URL = 'https://tensorflow.org/images/blogs/serving/cat.jpg'
def main(): # Download the image dl_request = requests.get(IMAGE_URL, stream=True) dl_request.raise_for_status()
# Compose a JSON Predict request (send JPEG image in base64). jpeg_bytes = base64.b64encode(dl_request.content).decode('utf-8') predict_request = '{"instances" : [{"b64": "%s"}]}' % jpeg_bytes
# Send few requests to warm-up the model. for _ in range(3): response = requests.post(SERVER_URL, data=predict_request) response.raise_for_status()
# Send few actual requests and report average latency. total_time = 0 num_requests = 10 for _ in range(num_requests): response = requests.post(SERVER_URL, data=predict_request) response.raise_for_status() total_time += response.elapsed.total_seconds() prediction = response.json()['predictions'][0]
print('Prediction class: {}, avg latency: {} ms'.format( prediction['classes'], (total_time*1000)/num_requests))
if __name__ == '__main__': main()
复制代码
左滑查看更多
这个 Python 客户端图片输出结果是否通过运行参数获取到服务端的自动执行,下载示例并上传至进行推理,最后推理端。
py $(kubectl get svc resnet-service -o=jsonpath='{.status.loadBalancer.ingress[0].hostname}')
复制代码
可以看到推理结果以及相应的演讲:
6、Karpenter 节点扩张收缩容测试
Karpenter Controller 会在后台调度不可调度 Pods 的信息,并安排 Pod 需求和不同的 Tag 持续监控/Taints 等信息,生成符合的实例类型和数量。 ,用户无需提前进行组节点的实例类型匹配,由 Karpenter 来根据需要的资源自动节点类型和数量,更加灵活。因此规划也需要减少额外的集群 AutoScaler 组件来进行节点扩展容。
我们增加 Pod 以便触发节点扩容:
kubectl 规模部署 resnet --replicas 6
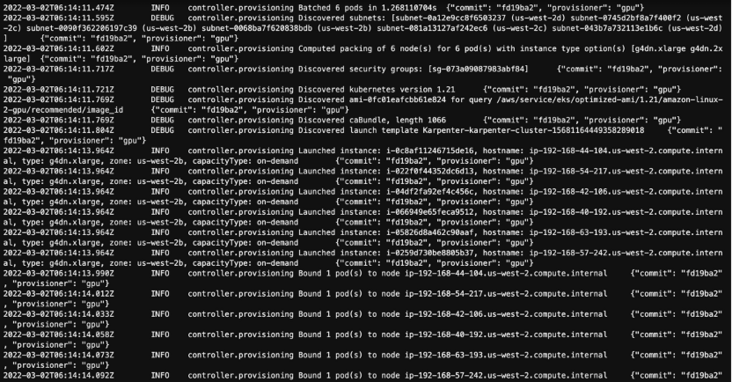
通过 Karpenter Controller 的查询日志,我们可以查看扩容时的具体运行逻辑:
kubectl 日志 -f -n karpenter -l app.kubernetes.io/name=karpenter -c 控制器
复制代码
每个 Pod 的需求状态,因此,5 个 Pod 并没有在 G4 实例上创建 GPU 而正在等待亚马逊 。这时候 Karpenter 汇总了这 5 个 Pod 的资源需求,并据此判断使用的需求或状态(或多种)类型的实例适合。结合我们前面的 Provisioner 的配置,Amazon Karpenter 会自动额外创建 5g4.xlarge 的按需实例来运行这 5 个 Pod。针对按需实例,Provisioner 会选择自动最低价格的可以满足需求的实例。
AutoScaler 的创建方式会立即将 Pod 的出现,然后在节点开始绑定拉取等模式。 准备就绪后 Kubernetes Scheduler 状态将节点调度并开始创建活动,Amazon Karpenter 会更加高效。
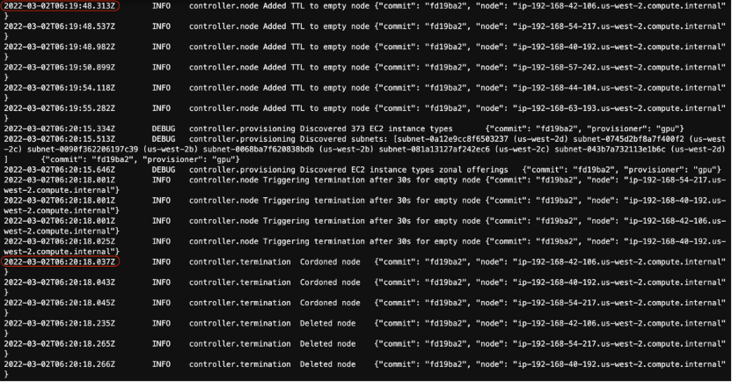
删除所有的 Pod,观察 Amazon Karpenter 如何处理节点缩小容的场景:
kubectl 规模部署 resnet --replicas 0
从前面的配置可以看到,在我们 Karpenter 的配置后,亚马逊 会自动消除前面的异常。
小结
在这个博客里里,我们学习了一个机器管理的应用部署器,这样 EKS 中如何介绍了 Karpenter 来进行使用亚马逊 的不同类型的弹性放大缩小。 Amazon Karpenter 是完全开源的组件,目前支持在亚马逊云上对 EKS 和用户自建的 Kubernetes 集群进行一个节点扩容管理,通过其开放的云提供商插件功能,可以对非亚马逊云科技云的支持。
在关注的博客上进一步探讨利用 Amazon Karpenter 实体进行管理会如何对我们进行现场讨论
本文作者
邱萌
亚马逊云科技解决方案架构师
负责基于亚马逊云科技方案架构的咨询和设计,推广亚马逊云科技平台技术和解决方案。在加入亚马逊云科技之前,曾在企业上云、互联网娱乐、媒体等行业挖掘业务,对公有云和架构业务有很深的理解。
林俊
亚马逊云科技解决方案架构师
主要负责企业客户的解决方案咨询与架构设计优化。





















评论