后起之秀 -network policy 之 eBPF 实现
这篇是 Network Policy 最后一篇,主题是关于 eBPF。前面两篇,我们聊完了 Network Policy 的意义和 iptables 实现,今天我们聊聊如何借助 eBPF 来摆脱对 iptables 的依赖,并实现 Network Policy。
文章正常是周四更,今年中秋已过去,提前祝大家国庆快乐,来年中秋更快乐!
前世
eBPF 的前世是 BPF。1992 年,Steven McCanne 和 Van Jacobson 写了一篇论文“The BSD Packet Filter:A New Architecture for User-Level Packet Capture”。在这篇文章里,作者描述了他们在 Unix Kernel 里是如何利用 BPF 来过滤网络包的,他们的实现比当时主流的方法快 20 倍。
新方法主要包含了两个创新:
一个工作在内核态的轻量级虚拟机,它可以与 CPU 寄存器完美契合工作。
为每个 application 引入了一个专属的 buffer,应用只需要关心与自己相关的 package 即可。
这个令人惊叹的效率提升使得所有的 Unix 系统都采用了 BPF 来过滤网络包,并弃用了传统的既耗内存效率又低效的方法。BPF 至今仍活跃在各类 Unix 的后继者身上,包含 Linux Kernel。后文将这部分的 BPF 叫做 cBPF(classic BPF)。
今生
时间来到 2014 年。Alexei Starovoitov 介绍了一种叫 extended BPF(eBPF)的设计。新的设计为匹配最近的硬件做了优化,与 cBPF 相比,它产生的机器码执行效率更快,可供使用的寄存器从 2 个 32-bit 寄存器大幅提升至 10 个 64-bit 的寄存器,这为基于 eBPF 来实现更快、更复杂的功能提供了基础条件。eBPF 的速度比 cBPF 快了 4 倍。
Windows 操作系统上著名的 Sysinternals 套件里包含了一个系统监控的工具 sysmon,它在 Linux 上的实现也是基于 eBPF 的。难怪 Netflix 性能架构师 Gregg 说 BPF 是 OS 内核近 50 年来最基础性的改动。
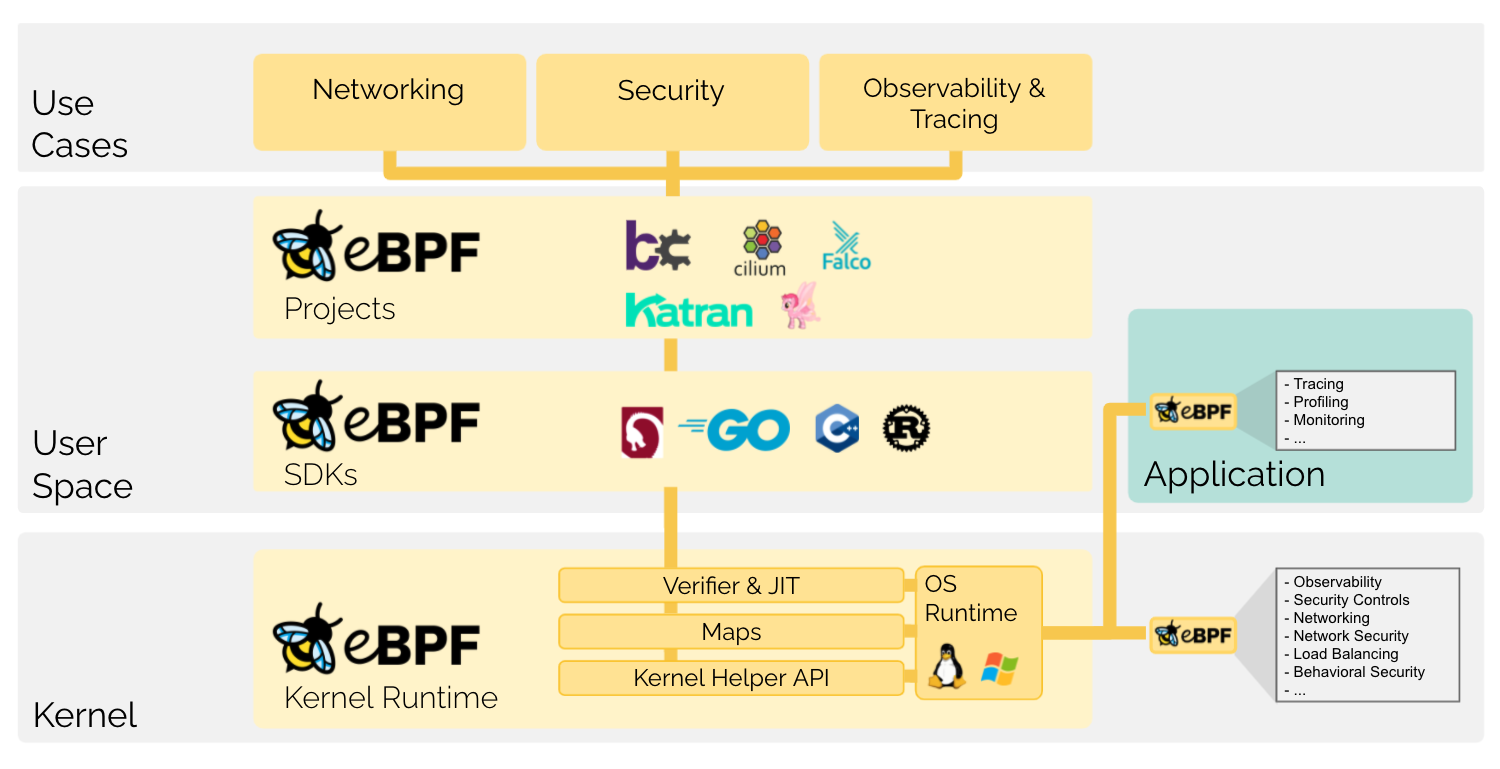
图 1:eBPF 概略图
从这张概略图中,我们大致可以看出来 eBPF 项目的一些特点:
eBPF program(后文叫 eBPF prog)是运行在 Kernel 里面的,可以 hook 到 kernel 里面几乎任何一个函数上,借助 Verifier 和 JIT 的加持,可以安全快速地运行,无需担心会把系统搞崩溃掉。这点可以完胜 kernel module,写过 kernel module 的人都记得写内核驱动时那份如履薄冰的痛苦。
可以用它来实现 seccomp、观测、安全控制、网络流量控制、网路安全、负载均衡、行为监控等各式各样的功能。
通过 Map,可以与 User space 的进程通信。这也就意味着可以通过 Map 实时、动态地控制 eBPF program 的行为,并能及时收集 eBPF prog 产生的数据。传统的检测网络流量的方法不外乎编写内核模块或者从文件系统特定目录(如/sys/class/net/eth0/statistics/rx_packets)定期读取数据。每一次读取意味着一系列文件打开、读取等费时的系统调用。
Linux 社区提供了各式各样的 toolchain,包括 bcc,bpftrace,gobpf,libbpf C/C++ Library,协助你以最小代价方便快捷地编写 eBPF prog。款式各式各样,总有一个适合你。
下面的图 2 展示了基于 gobpf 开发 eBPF prog,通过 Verifier 和 JIT 后 hook 到 system call 的流程。除此之外,图中还展示了一个 eBPF map。
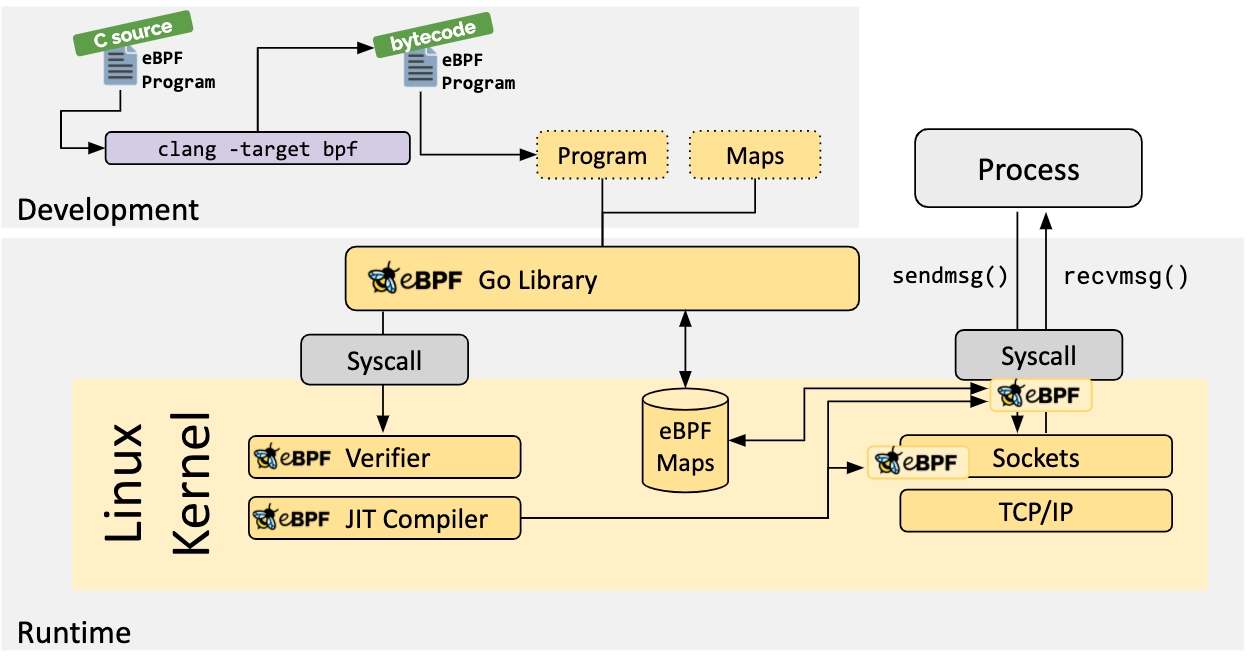
图 2:通过 SDK gobpf 加载 eBPF prog、hook system call、map 示意图
下面是一段简单的 eBPF program 代码。
通过命令clang -O2 -target bpf -c bpf_program.c -o bpf_program.o 即可将其编译成 eBPF prog bpf_program.o。
bpf_program.o是 elf 格式,.text 部分保存的是字节码,加载到内核且通过 Verifier 这一关之后,JIT 负责将其转换成机器码。
通过下面的 c 代码,可将编译好的 eBPF prog bpf_program.o 加载到内核。
如果使用图 2 所示的 gobpf 的话,就更简单了。直接调用 Go 方法func (bpf *Module) AttachTracepoint(name string, fd int) error 加载这段源代码即可。它会自动完成 c 代码转字节码的编译、通过 libbpf 调用 sys_bpf()加载 eBPF prog 进内核的工作。
注意:这里是直接使用 c 源代码的。傻瓜式的操作方便是方便,但也将一些问题延迟暴露了。比如 c 代码如果有编译问题,只有等调用 AttachTracepoint()加载的时候才会发现。编译 Go 代码的时候,是不会进行 c 代码的编译的。
总体来说,eBPF 可以用来做两大类的事情:tracing 和 networking。
Tracing:顾名思义,这类 eBPF prog 可以用来帮助你更好地理解你的系统里发生了什么。如进程资源使用情况,是否有异常的系统调用行为等等。
networking:这类 eBPF prog 用来检查和处理系统里的所有的网络包。比如可以在网络包还没有进入网络栈的时候就进行导流,绕过 iptables 进行流量控制,修改 IP 和端口来实现负载均衡。
具体来说,eBPF 可以被分为大概 22 种的子类别(随着 Kernel 的开发,会越来越多)。限于篇幅,这里就不一一列举了。详细内容可参考https://www.man7.org/linux/man-pages/man2/bpf.2.html。
缘起
eBPF 是个让人兴奋的好东西,而 K8s 是个让人亢奋的巨无霸。它们俩的相遇,在 Network Policy 这个地方擦出了奇妙的火花。
前文我们提到用 iptables 来实现 K8s Network Policy,会使得 iptables rule 的条目迅速膨胀到上万条,这会导致网络包流经网络栈的时候速度变慢。 如果我们将网络栈比作河道,网络包比作水流的话,rule 条目的急速增加就像是在河道里插入了一个又一个拦污网,它们在有效过滤网络包的时候,也显著降低了流水的速度。
通过将 eBPF 替代 iptables,能有效改善这种情况。CNI 插件 Calico 和 Cilium 尤其醉心于此。下面我们以 Calico 来看看它是如何利用 eBPF 来替代 iptables 的。
从网络的角度来看,我们使用 eBPF 主要是为了两个目的:packet capturing 和 filtering。这表示应用程序可以在网络包流经路径上插入各种 eBPF prog 以便来抓取数据包的信息并对特定的网络包进行各种操作。
Networking data path
在谈到 eBPF 如何替代 iptable 之前,先让我们来看下网络数据路径的概念。如图 3 所示,当网络设备驱动收到一个网络包后,XDP 会得到最早的机会来接触这个 package,此时它操作的数据结构是 xdp_md。XDP 全名为 eXpress Data Path。我觉得比较好的翻译应该是“快速数据路径”,此处的“快速”作何解释呢?在图 3 中,我特地画出了一条 XDP_TX 的路径,可以看到当满足特定条件时,它完全避开了 tc 和协议栈,直接将数据快速地处理掉。
当 XDP 决定将数据包送往内核做后续处理后,网络中断处理程序会申请 skb_buff,接下来 traffic control(tc)便开始了它的处理流程,也就是我们听说过的 QoS 和 Queue Descipline。
注意:从这里开始,tc 和内核栈以及其它网络内核模块都会以 skb_buff 为处理对象。
之后,skb_buff 向上流入 Networking stack,如果一路畅通,最终会进入应用层。图中也同样画出了当应用层向外发送一个数据的时候,所流经的 data path。还记得我们上面的河道比喻吗?网络数据包确实如河水一样,在河道里面流淌。
当然这个过程中,iptables 依旧位于 Networking stack 中,我们也没有必要绕开它,只要不设置过多的 iptables rule,便可以快速地穿过 iptables 这道屏障。
接收数据 data path:device driver --> xdp -- >tc(ingress) --> networking stack --> socket --> application
发送数据 data path:application --> socket --> networking stack --> tc(egress) --> device driver
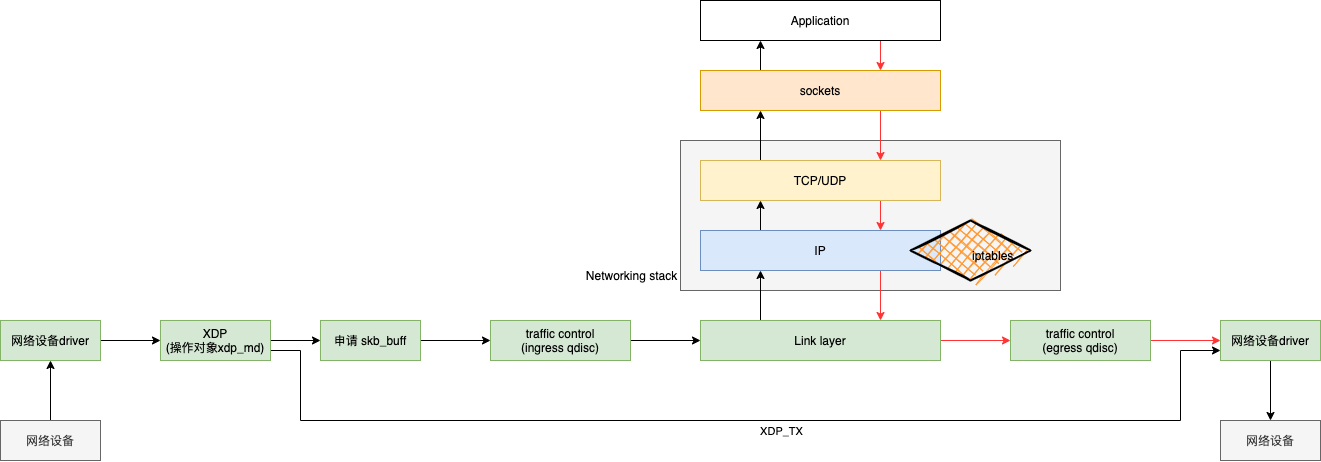
图 3:networking data path 关键节点示意图
介绍完网络数据路径再来看图 4。别忘了 eBPF 里面的字母'F'代表的是 Filter。聪明的内核工程师自然是不忘初心,允许我们在网络数据路径若干个关键节点上 hook eBPF 来过滤网络数据。
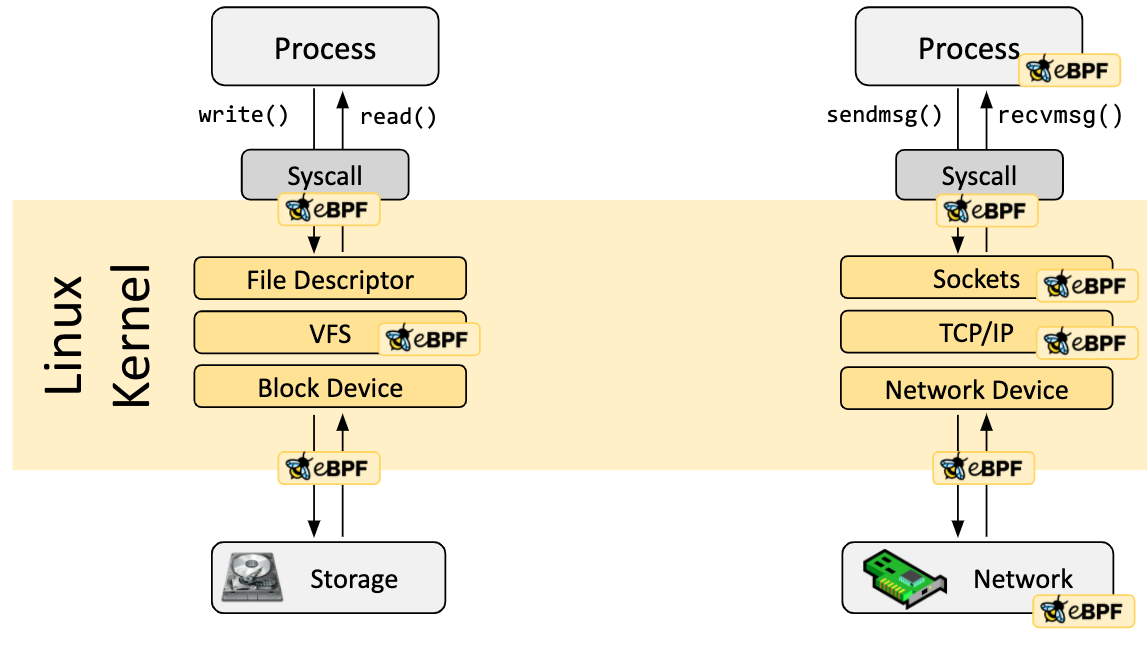
图 4:eBPF 在 data path 上可以 hook 的各个关键节点示意图(重点是右侧部分,暂时忽略左侧)
图 4 右侧部分,从下往上可供 hook 的 eBPF 类型至少有如下几种:
XDP
tc
socket filter
Kprobe
Tracepoint
这些 hook 点可以和图 3 浅绿色的框中所示的关键节点联系起来一起看。实际上,可供 hook 的点还有很多。嗯,老规矩,以后慢慢聊,好吧,我承认,其实是好多我也不会,等我学完一阵子后再来卖。
calico tc eBPF 示例
铺垫了这么多,终于到了介绍该如何利用 eBPF 来实现 Network Policy 的时候了。
下图是一张利用 eBPF hook 到 tc 来实现 Network Policy 的架构图。图中 eBPF prog hook 在与 Pod 相连的 veth 上,它包括 3 大主要的子 program:main prog, policy prog 和 epilogue prog。利用 eBPF 的 tail call 功能,这 3 个 prog 依次被调用。
图中 eBPF prog 会接收到来自物理网卡和节点上其它虚拟设备发过来的 traffic。而我们看到 policy prog 自然地会想到 Network Policy。没错,通过将 Network Policy 转译成这里需要的命令,即可方便、快速地控制 traffic 是否可以流向 Pod,而这个过程中我们可以看到 iptables 被完美地避开了。
强调一下,这里所说的避开不是说流量不通过 iptables(实际上节点上其它虚拟设备发过来的 traffic 可能不可避免地还是会通过 iptables 过滤一次),而是说因为有了 tc eBPF 的存在,我们便可以不再依赖 iptables,不需要创建巨量的 iptables rule,从而显著减低 iptables 带来的性能影响。
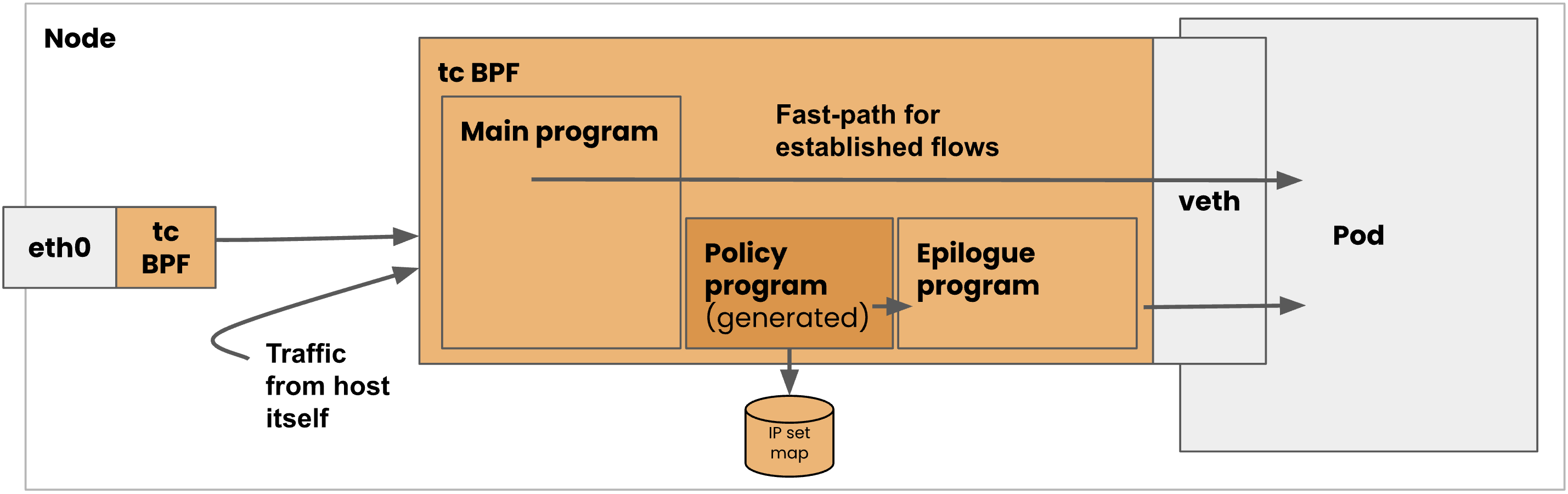
图 5:CNI calico 利用 eBPF 来控制 traffic 示意图
这张图里面的 policy prog 会引用到一个 IP set map。聪明的你一定会想到可以从 user space 把允许访问这个 Pod 的 IP 和拒绝访问的 IP 做成 allow list 和 deny list,然后塞到这个 map 里,而 policy prog 可以根据你的设置来决定是否对 traffic 放行。
完美的实现!
以上就是本文的全部内容。码字不易,更多内容请关注二哥的微信公众号。您的举手之劳是对二哥莫大的鼓励。感谢有你!

版权声明: 本文为 InfoQ 作者【Lance】的原创文章。
原文链接:【http://xie.infoq.cn/article/447b9276c4cd279075c256e4c】。文章转载请联系作者。

码海茫茫 2018.03.18 加入
软件行业从业多年,焊过电路、干过驱动、写过内核的代码、砌过业务的砖,人生转角处偶遇云原生。









评论